
트위터 텍스트 정제하기
정규 표현식과 re 모듈을 사용해서 내가 정한 '의미없는 문자열'의 조건에 부합하는 문자열들은 제거하거나 공백 등으로 변환함
import re
reg1 = re.compile(r'https?://[a-zA-Z0-9_/:%#\$&\?\(\)~\.=+-]*') # url
reg2 = re.compile(r'(@)[a-zA-Z0-9_]*:*') # 계정 태그(@아이디)
reg3 = re.compile(r'(\d)([,.])(\d+)') # 숫자.숫자 (ex. 날짜)
reg4 = re.compile(r'\d+') # 숫자 여러개
reg5 = re.compile(r'[\r\n\t]+') # 줄바꿈, 탭 등의 공란
reg6 = re.compile(r'[\.・…,]+') # 물음표/느낌표 제외 문장부호들
reg7 = re.compile(r'[?]+') # 물음표 여러개
reg8 = re.compile(r'[!]+') # 느낌표 여러개
reg9 = re.compile(r'[\[{「〈【[≪《〔<{『]+') # 이렇게 생긴 문장부호들
reg10 = re.compile(r'[\]}」〉】]≫》〕>}』]+') # 이렇게 생긴 문장부호들
def parge_tweet(tweet):
t = tweet
t = reg1.sub('', t) # url -> 삭제
t = reg2.sub('', t) # 계정 태그(@아이디) -> 삭제
t = reg3.sub(r'\1\3', t) # 숫자.숫자 -> 1.1로 변환
t = reg4.sub('1', t) # 숫자 여러개 -> 1 하나로 줄임
t = reg5.sub(' ', t) # 줄바꿈, 탭 -> 공백으로 변환
t = reg6.sub('.',t) # 물음표/느낌표 제외 문장부호들 -> .으로 통일
t = reg7.sub('?', t) # 물음표 여러개 -> 물음표 1개로 줄임
t = reg8.sub('!', t) # 느낌표 여러개 -> 느낌표 1개로 줄임
t = reg9.sub('<',t) # 이렇게 생긴 문장부호들 -> <으로 통일
t = reg10.sub('>',t) # 이렇게 생긴 문장부호들 -> >으로 통일
return t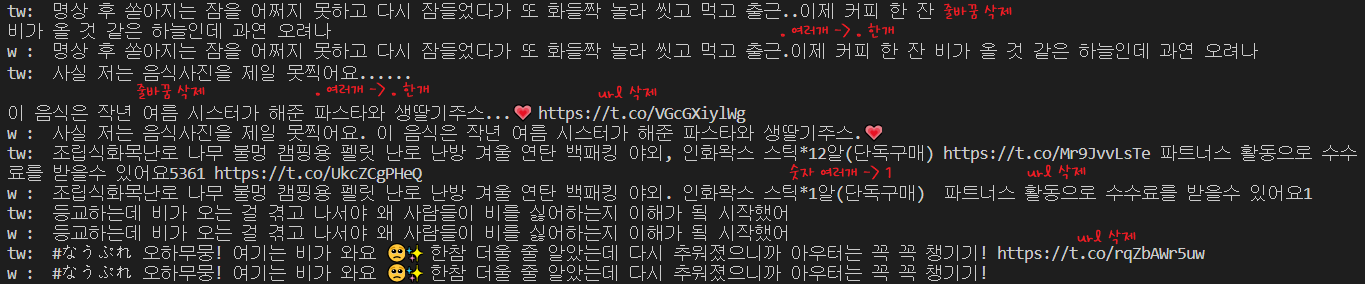
이런식으로 트윗이 정제된다. (tw이 본트윗, w이 정제한 트윗)
형태소로 분류하기 (mecab 사용하기)
1. mecab 설치하기
(1) eunjeon 라이브러리 사용하기
python에서 eunjeon 라이브러리 설치하기
pip install eunjeoneunjeon은 은전한닢 프로젝트와 mecab 기반의 한국어 형태소 분석기의 독립형 python 인터페이스이다. 위와 같이 pip를 이용해서 eunjeon을 설치하기만 하면
from eunjeon import Mecab
mecab = Mecab()
mecab.pos("은전한닢 프로젝트에서 나온 mecab을 사용하는 중이다.")이런식으로 mecab을 간편하게 사용할 수 있다.
(2) wheel 파일로 설치하기
위 방식이 되게 간편한데 구글링을 하다보면 Mecab 이 아니라 MeCab (❗C가 소문자가 아니라 대문자임)을 사용하는 코드들도 많이 볼 수 있었는데, 이거는 자기 컴퓨터의 환경과 파이썬 버전과 일치하는 mecab wheel 파일을 받아서 지난번에 GDAL과 마찬가지로 pip install wheel파일명.whl 으로 설치하면 된다. 근데 나는 python 3.10을 사용하고 있는데 mecab wheel 파일은 python 3.7 까지만 지원을 해서 python 3.7을 또 깔았다.
import MeCab
m = MeCab.Tagger()
a = m.parse("이번에는 wheel 파일로 설치한 mecab을 사용하는 중이다.")사용자 사전을 사용하기 위해서는 이게 꼭 필요한 줄 알고 굳이굳이 따로 받았는데 필요 없는 것 같다. eunjeon 에서 제공하는 mecab에도 dicpath라는 인자를 통해 사용자 사전을 더 편하게 등록해줄 수 있다.
이런식으로 뒤에 .Tagger() 메소드를 붙여서 사용할 수 있다.
2. 사용자 사전 커스텀하기
(1) 사전 설치하고 파일 세팅하기
mecab-ko-dic-msvc와 mecab-ko-msvc를 설치해야 한다. 말이 설치지 그냥 다운받아서 압축해제만 해주면 된다. mecab-ko-dic-msvc는 mecab-ko 기본 사전이고, mecab-ko-msvc는 mecab을 윈도우에서 실행될 수 있게 컴파일하는 역할이라고 한다.
다운을 받았으면 C:\ 에 mecab 이라는 폴더를 만들어준다.
그리고 압축해제한 파일들을 모두 C:\mecab 안으로 옮긴다. 이 폴더 내부에는 다음과 같은 파일들이 위치하게 된다.
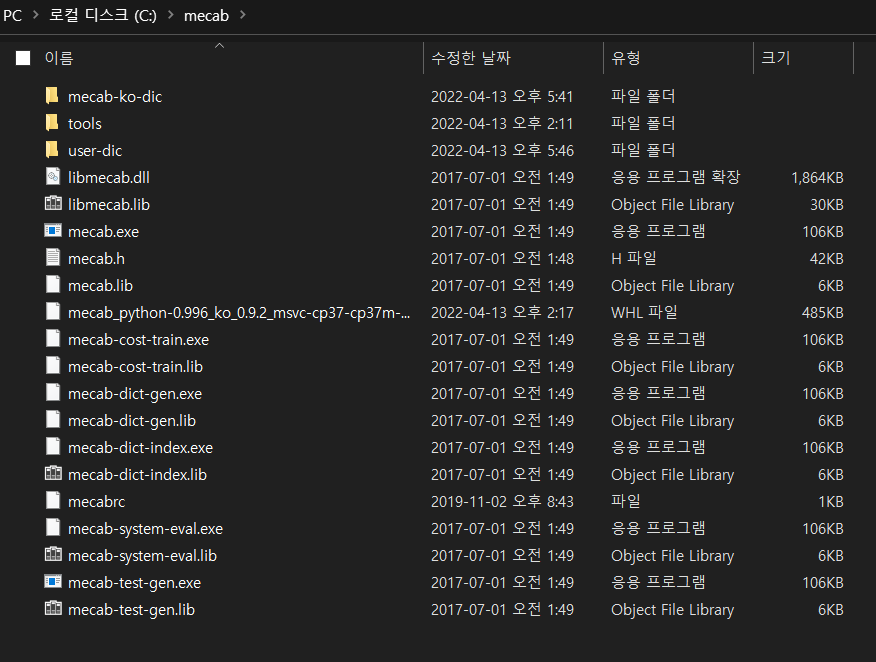
mecab-ko-dic : mecab의 단어 사전
tools : 단어 사전에 단어를 추가시킨 후 컴파일 및 적용을 시켜주는 프로그램들 존재
user-dic : 사용자가 추가적으로 추가한 단어에 대한 단어 사전
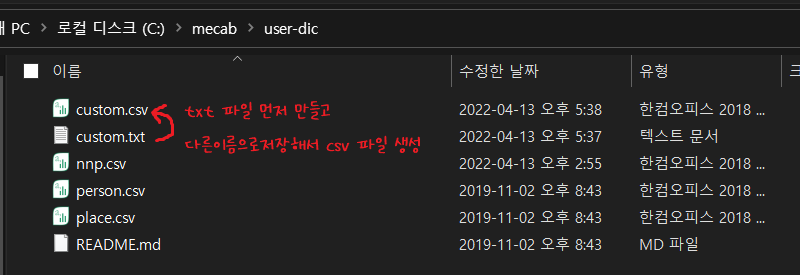
(2) 커스텀 사전 파일(custom.csv) 만들기
그럼 이제 C:\mecab\user-dic 에서 custom.csv 를 만들어야 한다. 근데 여기서 주의할 점은 바로 .csv 파일을 만드는 것이 아니라 custom.txt 파일을 만들어서 메모장에서 내용을 써준 다음에 다른 이름으로 저장 -> .csv로 확장자 바꾸기 -> 인코딩 UTF-8 변환 으로 custom.csv 파일을 만들어야 커스텀 단어 등록이 제대로 먹혔다.
# custom.txt (custom.csv)
비타500,,,,NNP,*,T,비타500,*,*,*,*,*
싹쓰리,,,,NNP,*,F,싹쓰리,*,*,*,*,*
미세먼지,,,,NNP,*,F,미세먼지,*,*,*,*,*
(3) 커스텀 사전 반영시키기
powershell을 관리자 권한으로 실행한다.

별다른 에러 없이 done!이 뜨면 커스텀 사전이 반영된 것. 권한이 없다는 오류가 뜨면 powershell을 관리자 권한으로 실행한게 맞는지 확인한다.
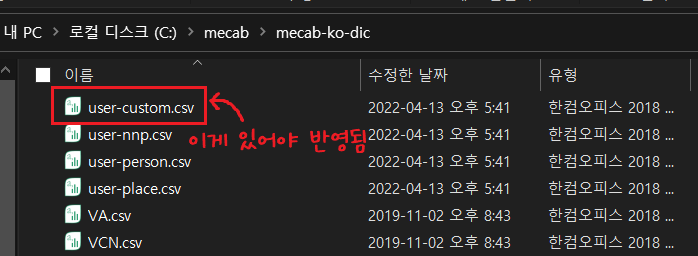
(4) 커스텀 사전 반영됐는지 확인하기
VSCode에서 다음 코드 실행
- 사전 반영 X
사전 반영 안하고 그냥 형태소로 나눴을 때
from eunjeon import Mecab
m = Mecab() # 사전 반영 X
text = "비타500 싹쓰리 미세먼지"
print("===================")
print(text)
print(m.pos(text))
print("===================")
비타-500, 싹-쓰리, 미세-먼지
다 끊어져서 나온다.
- 사전 반영 O
from eunjeon import Mecab
m = Mecab(dicpath='C:/mecab/mecab-ko-dic') # 사전 반영 O
text = "비타500 싹쓰리 미세먼지"
print("===================")
print(text)
print(m.pos(text))
print("===================")dicpath에 사전 경로를 써주면 되는데, 여기서 사전이 위 경로에 없다는 에러가 떴었다. 그러면 에러가 발생한 파일인 venv\Lib\site-packages\eunjeon\_mecab.py 을 열어서
def __init__(self, dicpath=os.path.abspath(os.path.join(installpath, 'data/mecabrc'))):
self.tagset = TAGSET
try:
self.tagger = Tagger('--rcfile %s' % dicpath)
except RuntimeError:
try: # Sometimes it works when we try twice.
# self.tagger = Tagger('--rcfile %s' % dicpath)
self.tagger = Tagger('-d %s' % dicpath)
except RuntimeError:
raise Exception('The MeCab dictionary does not exist at "%s". ~ ' % dicpath)
except NameError:
raise Exception('Install MeCab in order to use it: https://github.com/koshort/pyeunjeon/')라고 바꿔주면
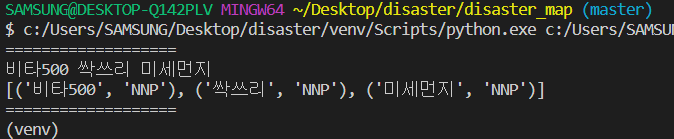
비타500, 싹쓰리, 미세먼지
붙어서 나온다.
Reference
윈도우 환경에서 mecab 설치 후 파이참(PyCharm) 에서 사용하기
