mecab 커스텀 사전을 사용한 이유
쓰읍.. 뭔가 잘못 돌아가고 있는거 같다.
불필요한 부분을 굳이굳이 어렵게 하는거 같아.....
근데 그렇다고 이미 한 걸 지우기는 좀 그러니까 냅두긴 하는데 바보짓 한거 같아서 우울하다. ㅠ^ㅠ
💡 (2022.04.21) 이후에 하면서 필요한 절차였다는걸 알았음.
지금 트윗을 불러오는게
GetStreamFilter()메소드를 이용해서 실시간으로 스트리밍하고 있는데, 이거를 키워드별로 따로따로 부르면 '산불' 키워드로 몇분 스트리밍하고, '지진' 키워드로 몇분 스트리밍하고 ... 반복이다. 동시에 실행하는 법도 있겠지만 지금 내 수준에서는 조금 어렵고, 모든 쿼리 키워드를 모아서 한번에 스트리밍을 해야한다. 근데 하나 받고 분류하고 하나 받고 분류하고 .. 이것도 비효율적이라 한번에 불러온 다음에 한번에 분류하는게 좋을거라고 생각된다.그래서 지금 방식도 한번에 모아온 다음에(retrieve.py) 한번에 분류하는건데(classify.py), 재해 키워드별로 '폭염'-'덥다', '지진'-'땅이 흔들'과 같이 명확하게 재해를 가리키는 단어가 아닌 키워드로도 트윗을 받아왔기 때문에 스트리밍된 트윗이 어느 키워드에 걸려 들어온 건지를 판단해야 한다. 근데 한국어 특성상 트윗마다 같은 말이라도 띄어쓰기나 문장부호가 다를 수 있기 때문에 형태소로 쪼개는게 정확하다. 따라서 mecab을 사용해서 트윗 텍스트를 형태소로 쪼개야 했던 것이고, 적어도 내가 스트리밍을 해온 키워드는 한 묶음으로 인식해서 걸러낼 수 있게 해줘야 했던 것이다. 그래서 사용자 사전을 사용해야 하는 것이었다.
스트리밍 키워드 커스텀 사전에 등록하기
오늘은 일단 쿼리 키워드를 하나로 묶어서 커스텀 사전을 등록했다. '덥다'같은 게 '덥/다'로 나오는데 '덥다'로 붙어나오도록.
내가 커스텀 사전을 잘 이해를 못했던게 문제다..
# user-dic/custom.csv
비 많,,,,NNP,*,T,비 많,*,*,*,*,*
비가,,,,NNP,*,F,비가,*,*,*,*,*
눈 많이,,,,NNP,*,F,눈 많이,*,*,*,*,*
눈 쌓여,,,,NNP,*,F,눈 쌓여,*,*,*,*,*
바람 강해,,,,NNP,*,F,바람 강해,*,*,*,*,*
땅이 흔들,,,,NNP,*,T,땅이 흔들,*,*,*,*,*
춥다,,,,NNP,*,F,춥다,*,*,*,*,*
얼었,,,,NNP,*,T,얼었,*,*,*,*,*
기온이 낮,,,,NNP,*,T,기온이 낮,*,*,*,*,*
온도가 낮,,,,NNP,*,T,온도가 낮,*,*,*,*,*
덥다,,,,NNP,*,F,덥다,*,*,*,*,*
이상고온,,,,NNP,*,T,이상고온,*,*,*,*,*
기온이 높,,,,NNP,*,T,기온이 높,*,*,*,*,*
온도가 높,,,,NNP,*,T,온도가 높,*,*,*,*,*
혹서기,,,,NNP,*,F,혹서기,*,*,*,*,*
초미세먼지,,,,NNP,*,F,초미세먼지,*,*,*,*,*
대기오염,,,,NNP,*,T,대기오염,*,*,*,*,*
공기가 탁,,,,NNP,*,T,공기가 탁,*,*,*,*,*
대기질,,,,NNP,*,T,대기질,*,*,*,*,*나는 첫번째 단어가 읽어들일 단어고 뒷부분이 대체될 단어라고 생각해서 '덥다, 더운, 더워' 이런거를 다 '폭염' 으로 바꾸려고 했는데 말그대로 사전에 한 형태소로 인식할 '새로운 형태소'를 등록하는 거였다. 말그대로 잘못짚어도 한~~참 잘못짚었다는 거.. 쨌든 저렇게 등록하면 '초미세'하고 '먼지'로 띄어서 나오는걸 '초미세먼지'로 붙여서 가져온다.
우선순위 바꾸기
바꿨는데 반영이 안돼서 우선순위도 바꿔줬다.
# mecab-ko-dic/user-custom.csv
비 많,1786,3546,0,NNP,*,T,비 많,*,*,*,*,*
비가,1786,3545,0,NNP,*,F,비가,*,*,*,*,*
눈 많이,1786,3545,0,NNP,*,F,눈 많이,*,*,*,*,*
눈 쌓여,1786,3545,0,NNP,*,F,눈 쌓여,*,*,*,*,*
바람 강해,1786,3545,0,NNP,*,F,바람 강해,*,*,*,*,*
땅이 흔들,1786,3546,0,NNP,*,T,땅이 흔들,*,*,*,*,*
춥다,1786,3545,0,NNP,*,F,춥다,*,*,*,*,*
얼었,1786,3546,0,NNP,*,T,얼었,*,*,*,*,*
기온이 낮,1786,3546,0,NNP,*,T,기온이 낮,*,*,*,*,*
온도가 낮,1786,3546,0,NNP,*,T,온도가 낮,*,*,*,*,*
덥다,1786,3545,0,NNP,*,F,덥다,*,*,*,*,*
이상고온,1786,3546,0,NNP,*,T,이상고온,*,*,*,*,*
기온이 높,1786,3546,0,NNP,*,T,기온이 높,*,*,*,*,*
온도가 높,1786,3546,0,NNP,*,T,온도가 높,*,*,*,*,*
혹서기,1786,3545,0,NNP,*,F,혹서기,*,*,*,*,*
초미세먼지,1786,3545,0,NNP,*,F,초미세먼지,*,*,*,*,*
대기오염,1786,3546,0,NNP,*,T,대기오염,*,*,*,*,*
공기가 탁,1786,3546,0,NNP,*,T,공기가 탁,*,*,*,*,*
대기질,1786,3546,0,NNP,*,T,대기질,*,*,*,*,*이것도 지난번에 csv 파일 생성과 똑같이 txt 파일로 열어서 수정해줬다. NNP 앞에 숫자 0이 우선선위를 0번째로 둔다는 뜻이다. 다 몇천번대였는데 모두 0번째로 올려줬다. 이렇게 바꾸고 powershell에서 .\tools\compile-win.ps1 실행해주면 반영된다.
텍스트 분석하기 (pandas 사용하기)
그럼 분류는 여기까지 하고 데이터를 분석해야되는데 작년에 고급소프트웨어실습에서 주피터노트북으로 실습했던게 간간히 나온다.
분류한 데이터로 pandas를 이용해 dataframe을 만들어주면 value_counts() 로 빈도수도 바로 나오고, plot() 으로 그래프도 그릴 수 있다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def make_dataframe(data):
for d in data:
if d in queries_typhoon:
typhoon_array.append(d)
elif d in queries_downpour:
downpour_array.append(d)
elif d in queries_snow:
snow_array.append(d)
elif d in queries_gale:
gale_array.append(d)
elif d in queries_drought:
drought_array.append(d)
elif d in queries_forestfire:
forestfire_array.append(d)
elif d in queries_earthquake:
earthquake_array.append(d)
elif d in queries_coldwave:
coldwave_array.append(d)
elif d in queries_heatwave:
heatwave_array.append(d)
elif d in queries_dust:
dust_array.append(d)
else:
pass
disaster = dict(typhoon = np.array(typhoon_array),
downpour = np.array(downpour_array),
snow = np.array(snow_array),
gale = np.array(gale_array),
drought = np.array(drought_array),
forestfire = np.array(forestfire_array),
earthquake = np.array(earthquake_array),
coldwave = np.array(coldwave_array),
heatwave = np.array(heatwave_array),
dust = np.array(dust_array),
)
# print(disaster)
df = pd.DataFrame(dict([ (k,pd.Series(v)) for k,v in disaster.items() ]))
# print(df)
print("태풍 관련 단어 빈도수: ", sum(df['typhoon'].value_counts()))
print("호우 관련 단어 빈도수: ", sum(df['downpour'].value_counts()))
print("폭설 관련 단어 빈도수: ", sum(df['snow'].value_counts()))
print("강풍 관련 단어 빈도수: ", sum(df['gale'].value_counts()))
print("가뭄 관련 단어 빈도수: ", sum(df['drought'].value_counts()))
print("산불 관련 단어 빈도수: ", sum(df['forestfire'].value_counts()))
print("지진 관련 단어 빈도수: ", sum(df['earthquake'].value_counts()))
print("한파 관련 단어 빈도수: ", sum(df['coldwave'].value_counts()))
print("폭염 관련 단어 빈도수: ", sum(df['heatwave'].value_counts()))
print("미세먼지 관련 단어 빈도수: ", sum(df['dust'].value_counts()))
np.random.seed(0)
#print(np.random.randn(100,10))
all_freq = {}
typhoon_freq = []
downpour_freq = []
snow_freq = []
gale_freq = []
drought_freq = []
forestfire_freq = []
earthquake_freq = []
coldwave_freq = []
heatwave_freq = []
dust_freq = []
# 이전 빈도수 기록
typhoon_freq = [1,2,3,4]
downpour_freq = [0,3,5,7]
snow_freq = [3,7,4,2]
gale_freq = [8,4,0,2]
drought_freq = [3,6,9,2]
forestfire_freq = [2,5,7,9]
earthquake_freq = [3,7,9,1]
coldwave_freq = [3,0,8,1]
heatwave_freq = [2,8,5,0]
dust_freq = [2,5,7,3]
# 이번에 불러온 트윗에서의 빈도수 추가
typhoon_freq.append(sum(df['typhoon'].value_counts()))
downpour_freq.append(sum(df['downpour'].value_counts()))
snow_freq.append(sum(df['snow'].value_counts()))
gale_freq.append(sum(df['gale'].value_counts()))
drought_freq.append(sum(df['drought'].value_counts()))
forestfire_freq.append(sum(df['forestfire'].value_counts()))
earthquake_freq.append(sum(df['earthquake'].value_counts()))
coldwave_freq.append(sum(df['coldwave'].value_counts()))
heatwave_freq.append(sum(df['heatwave'].value_counts()))
dust_freq.append(sum(df['dust'].value_counts()))
all_freq["typhoon"] = typhoon_freq
all_freq["downpour"] = downpour_freq
all_freq["snow"] = snow_freq
all_freq["gale"] = gale_freq
all_freq["drought"] = drought_freq
all_freq["forestfire"] = forestfire_freq
all_freq["earthquake"] = earthquake_freq
all_freq["coldwave"] = coldwave_freq
all_freq["heatwave"] = heatwave_freq
all_freq["dust"] = dust_freq
df1 = pd.DataFrame(all_freq,
index=pd.date_range('1/1/2018', periods=5),
columns=['typhoon', 'downpour', 'snow', 'gale', 'drought', 'forestfire', 'earthquake', 'coldwave', 'heatwave', 'dust'])
print(df1.tail())
df1.plot()
plt.title("disaster word frequency")
plt.xlabel("time")
plt.ylabel("frequency")
plt.show()periods를 5일이라고 했기 때문에 데이터는 딱 5개씩 들어있어야 한다. 코드 흐름상 방금 분류해온 트윗 기준의 빈도수를 한번 추가하니까 이전까지의 기록은 4일치가 들어가있어야 한다. columns도 10개를 넣었기 때문에 데이터를 넣는 all_freq에도 총 10개의 key값이 있어야 한다.
이러고 실행하면
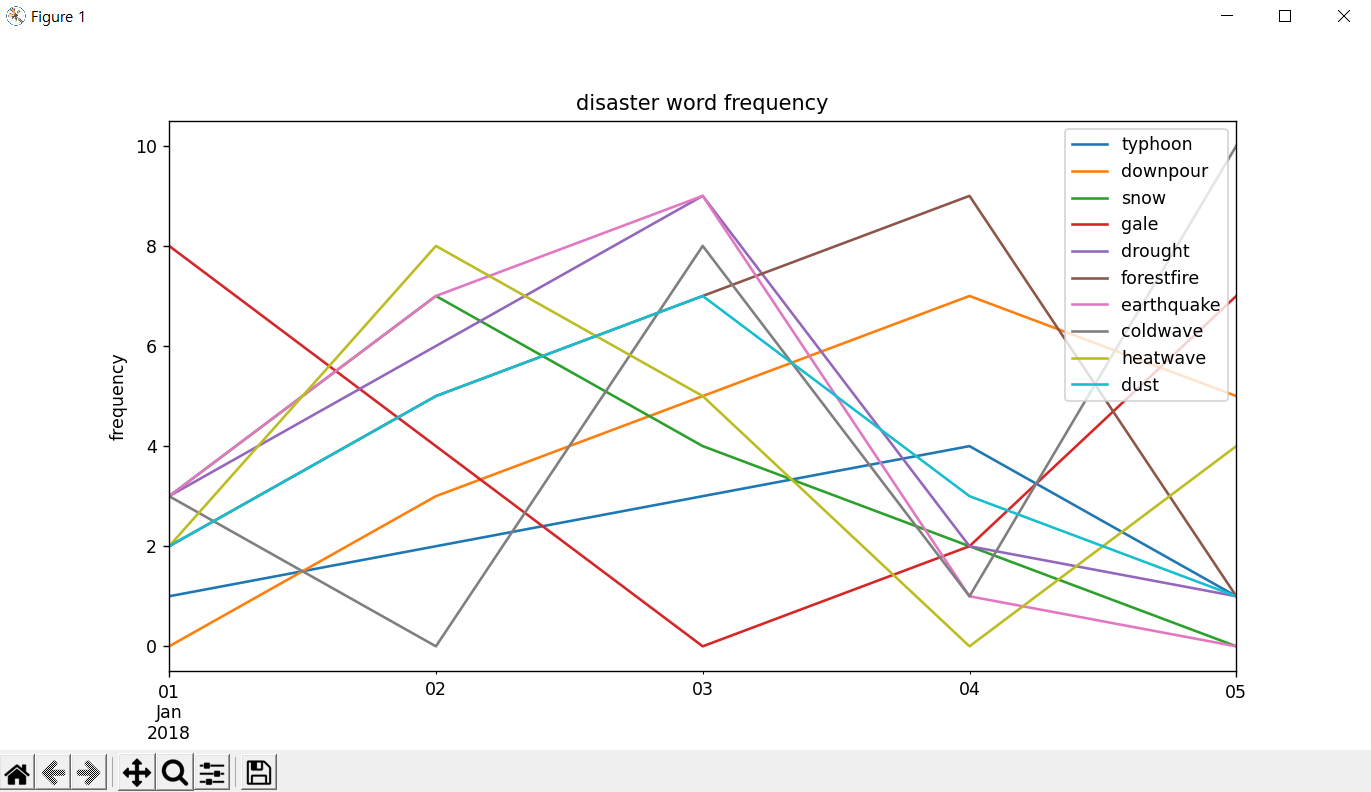
이렇게 그래프가 뜬다. 이거를 웹페이지로 옮기는거는 여기를 참고해서 나중에 해봐야겠다.
