와탭 쿠버네티스 GPU 모니터링 사용하기
메이플 할때만 쓰이는 놀고있는 GPU가 있어서, 재밋는걸 한번 해봤습니다.
윈도우에서 wsl 을 설치하고 minikube 를 설치하고 어쩌구 저쩌구 하고 와탭 쿠버네티스 모니터링 제품을 깔아서 gpu 모니터링 까지 해봤습니다.
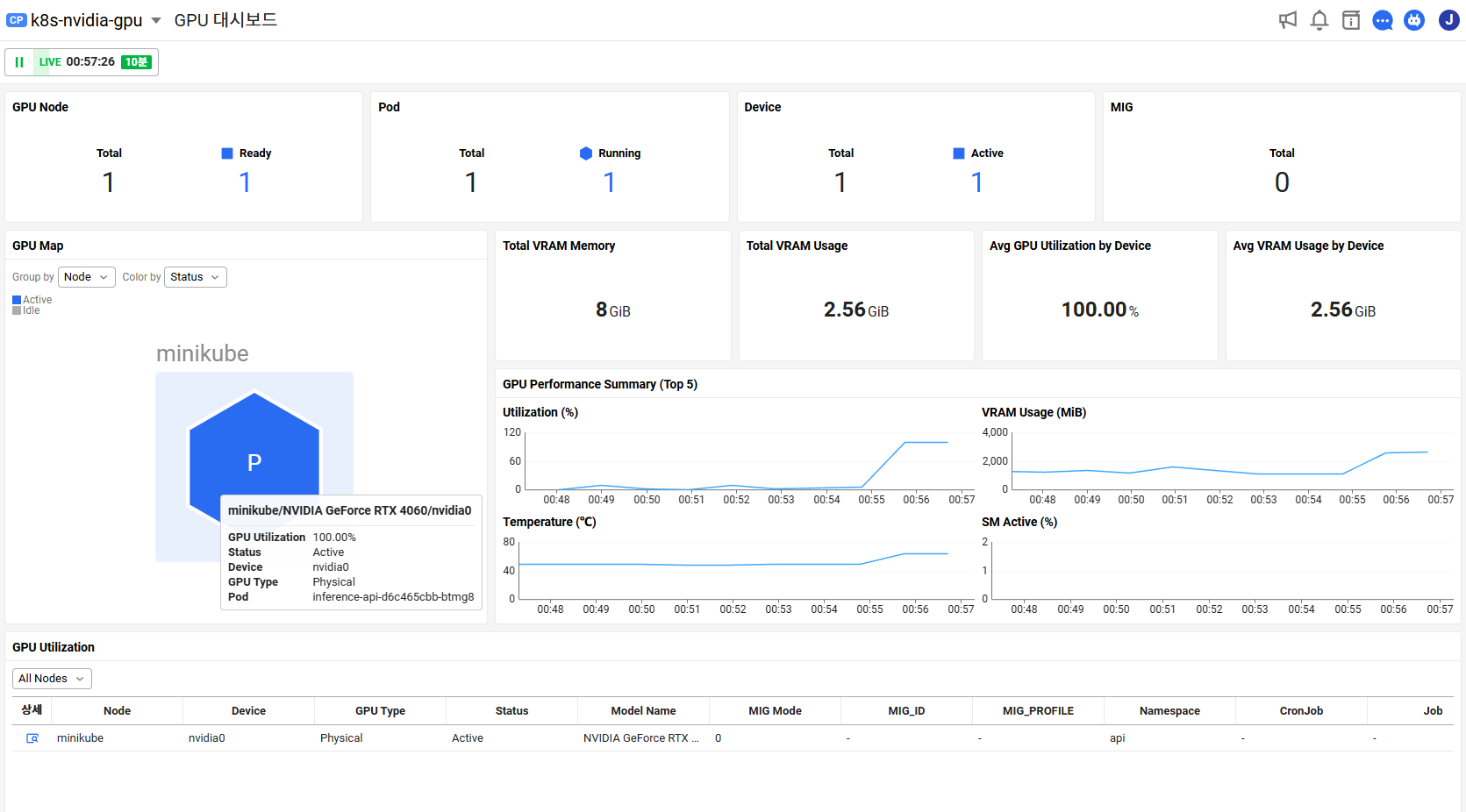
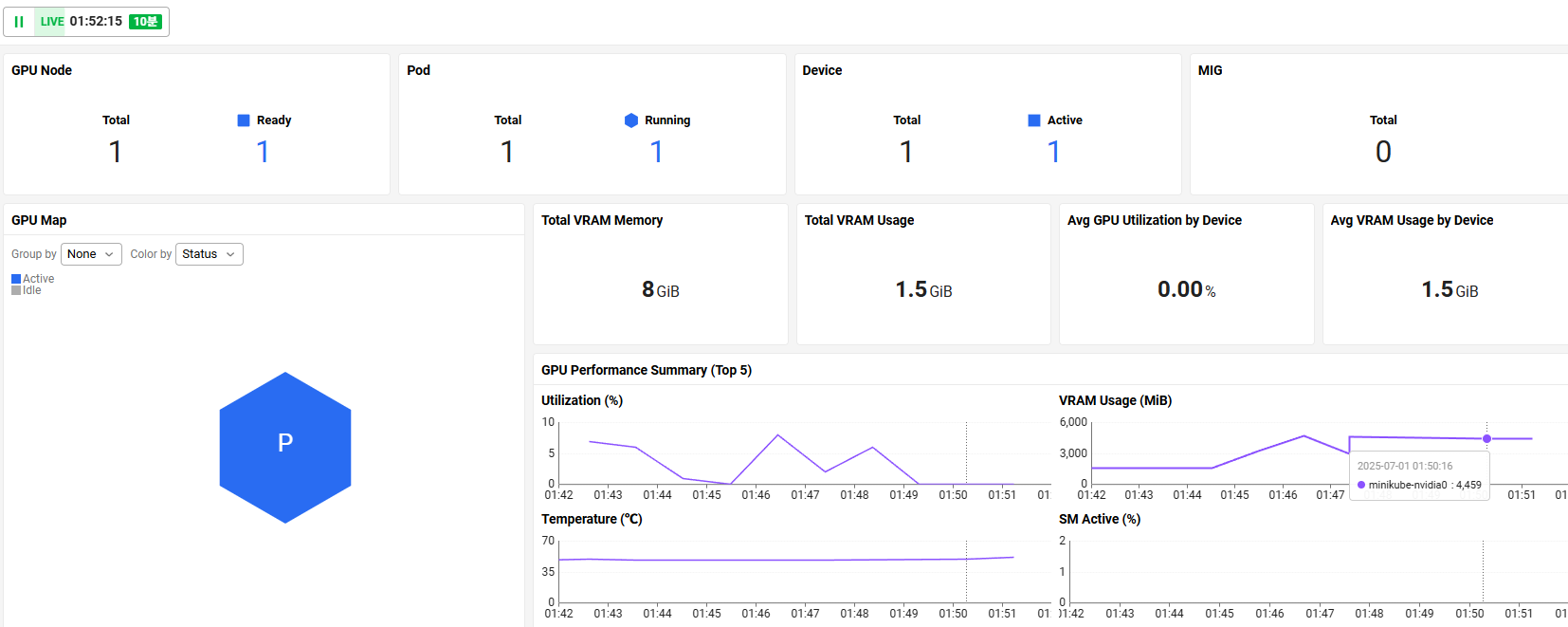
제모델은 NVIDIA Geforce RTX 4060이고, GPU 상태와 파드 할당 정보와 같은것도 알수있습니다.
GPU Utilization, VRAM 사용량, 온도와 같은 기본적인 성능데이터도 보입니다. status 는 Active 나 idle 로 표시돼서 놀고있는지 잘쓰고있는지 확인할수있습니다.

설치 환경
윈도우11(wsl 깔아야함)
CUDA Version: 12.6
GPU Model: NVIDIA Geforce RTX 4060
Driver Version: 560.94
사전 환경 셋팅
wsl 은 마이크로소프트 스토어에서 설치함(Ubuntu 22.04.5 LTS)
minikube 설치
curl -LO https://github.com/kubernetes/minikube/releases/latest/download/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube && rm minikube-linux-amd64
### 이거 매우 중요함, 이렇게 깔아야 노드가 gpu를 인식함
minikube start --driver docker --gpus all와탭설치
와탭은 쿠버네티스 제품은 오퍼레이터로 설치할 수 있습니다. 오퍼레이터설치 -> CR 설치(표준적인 오퍼레이터 설치방법으로 진행됩니다.)
- 와탭 헬름 레포지터리 등록
helm repo add whatap https://whatap.github.io/helm/
helm repo update확인해보면 아래와 같이 레포가 등록된것을 확인할 수 있습니다.

- 설정정보 입력 및 secret 생성
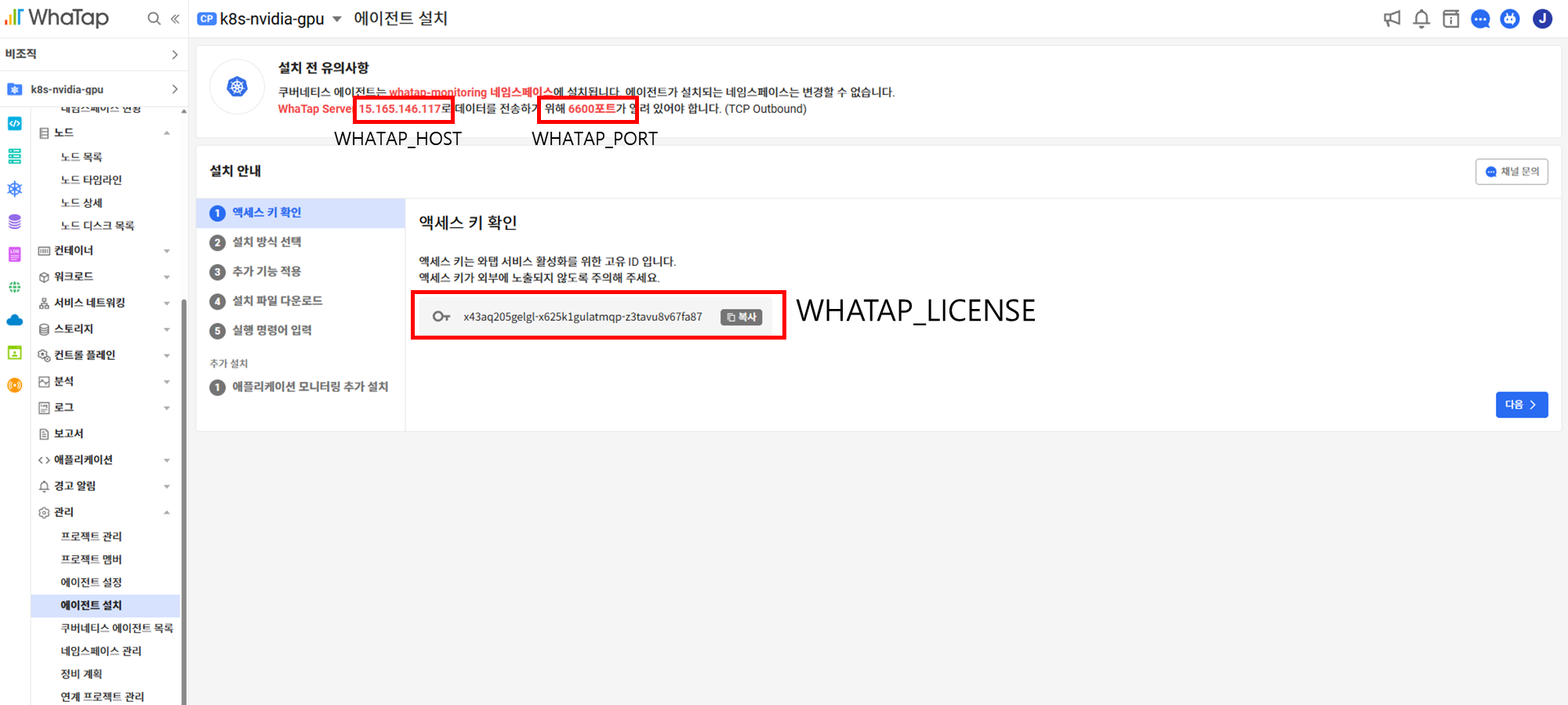
export WHATAP_HOST=<수집서버 IP>
export WHATAP_LICENSE=<와탭 라이센스>
export WHATAP_PORT=<와탭 포트>
kubectl create ns whatap-monitoring
kubectl create secret generic whatap-credentials --namespace whatap-monitoring --from-literal WHATAP_LICENSE=$WHATAP_LICENSE --from-literal WHATAP_HOST=$WHATAP_HOST --from-literal WHATAP_PORT=$WHATAP_PORT- 헬름으로 오퍼레이터 설치
helm install whatap-operator whatap/whatap-operator -n whatap-monitoring
- CR 설치
values.yaml
apiVersion: monitoring.whatap.com/v2alpha1
kind: WhatapAgent
metadata:
name: whatap
spec:
features:
### 쿠버네티스 에이전트 설치
k8sAgent:
masterAgent:
enabled: true
nodeAgent:
enabled: true
### gpu 모니터링 설치
gpuMonitoring:
enabled: true
### DCGM 메트릭 수집을 위한 오픈메트릭 에이전트
openAgent:
enabled: truekubectl apply -f values.yaml 설치 명령어 입력후에 정상적으로 작동하는 모습입니다.

이후 테스트용 gpu 파드를 설정해주시면 됩니다.
저는 Job 으로 생성했습니다.
gpu-test.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: gpu-job-1h
spec:
# 이 Job이 완료된 후 Pod와 Job을 자동으로 삭제하기 위한 설정 (초 단위)
# 예를 들어 300초(5분) 후에 정리됩니다.
ttlSecondsAfterFinished: 300
# Job의 최대 실행 시간을 3660초(1시간 1분)으로 제한합니다.
# Pod 생성 시간 등을 고려하여 1시간보다 약간 길게 설정하는 것이 안전합니다.
# 이 시간이 지나면 Job은 실패 처리되며 강제 종료됩니다.
activeDeadlineSeconds: 3660
template:
spec:
containers:
- name: cuda-container
image: nvidia/cuda:12.2.2-base-ubuntu20.04
# command를 사용하여 1시간(3600초) 동안 루프를 실행합니다.
# 루프 내에서 nvidia-smi를 주기적으로 호출하여 GPU를 사용하고 상태를 확인합니다.
command: ["/bin/bash", "-c"]
args:
- |
echo "Starting GPU job for 1 hour...";
end=$((SECONDS+3600));
while [ $SECONDS -lt $end ]; do
echo "Running nvidia-smi...";
nvidia-smi;
sleep 10;
done;
echo "Finished 1-hour GPU job.";
resources:
limits:
# 쿠버네티스 클러스터에 있는 NVIDIA GPU 1개를 요청합니다.
nvidia.com/gpu: 1
# Job의 특성상 Pod이 실패했을 때 재시작하지 않도록 설정합니다.
# Job 컨트롤러가 새로운 Pod를 생성하여 재시도를 관리합니다.
restartPolicy: Never화면
대시보드 > 컨테이너맵
(대시보드 구성필요없이 기본템플릿이 제공)
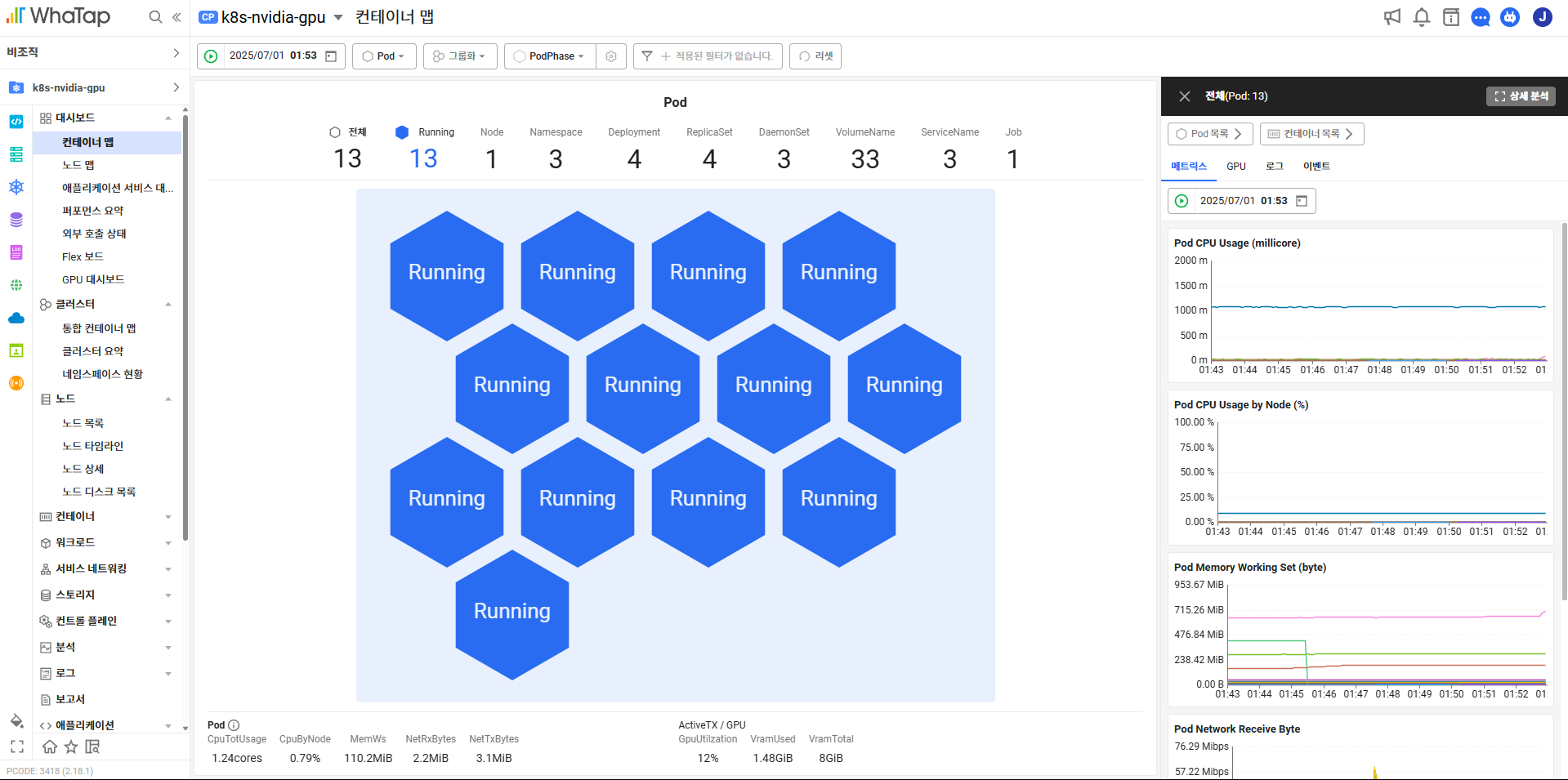
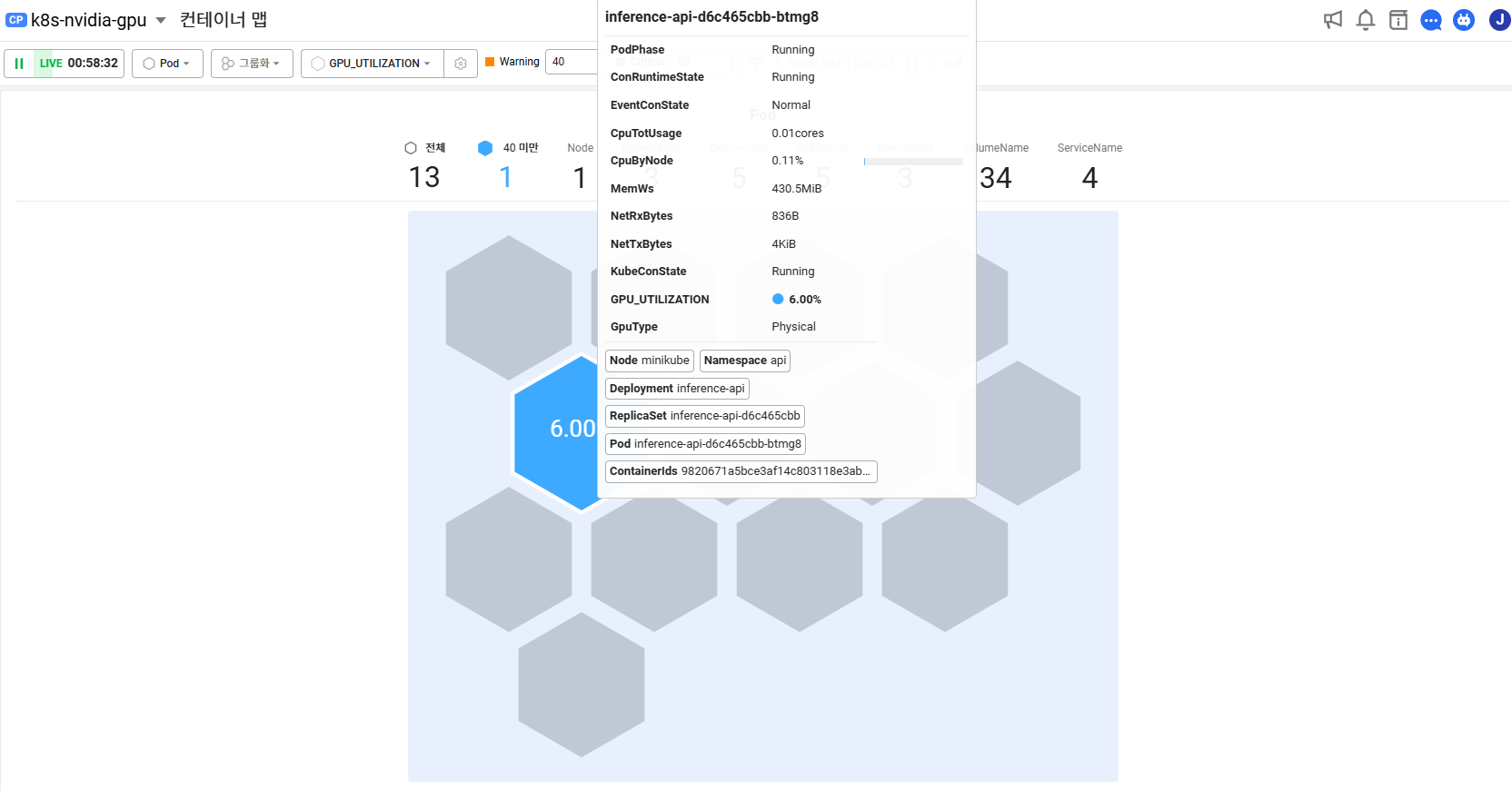
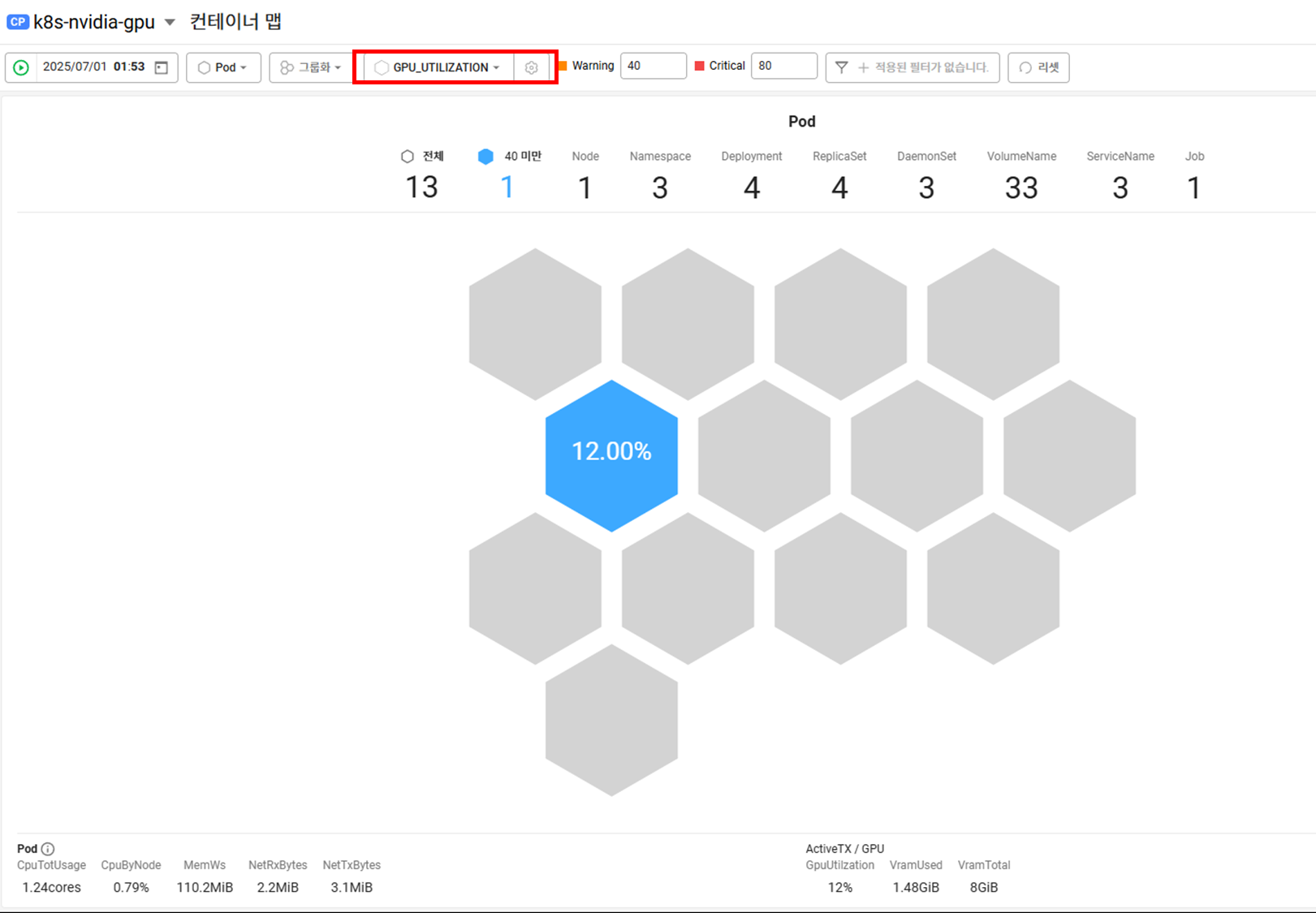
지표를 선택해서 보면 GPU 사용하는 것만 색깔표시가 됩니다.
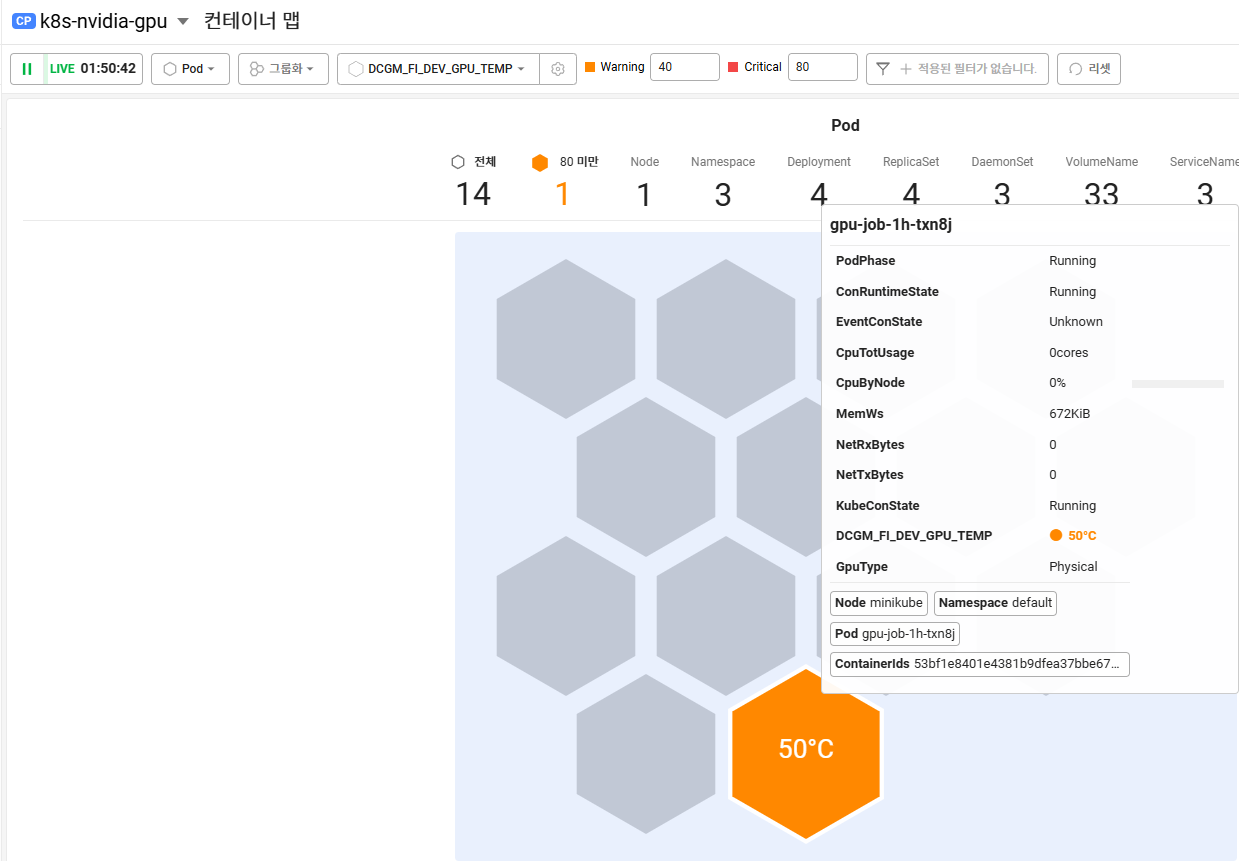
온도 체크
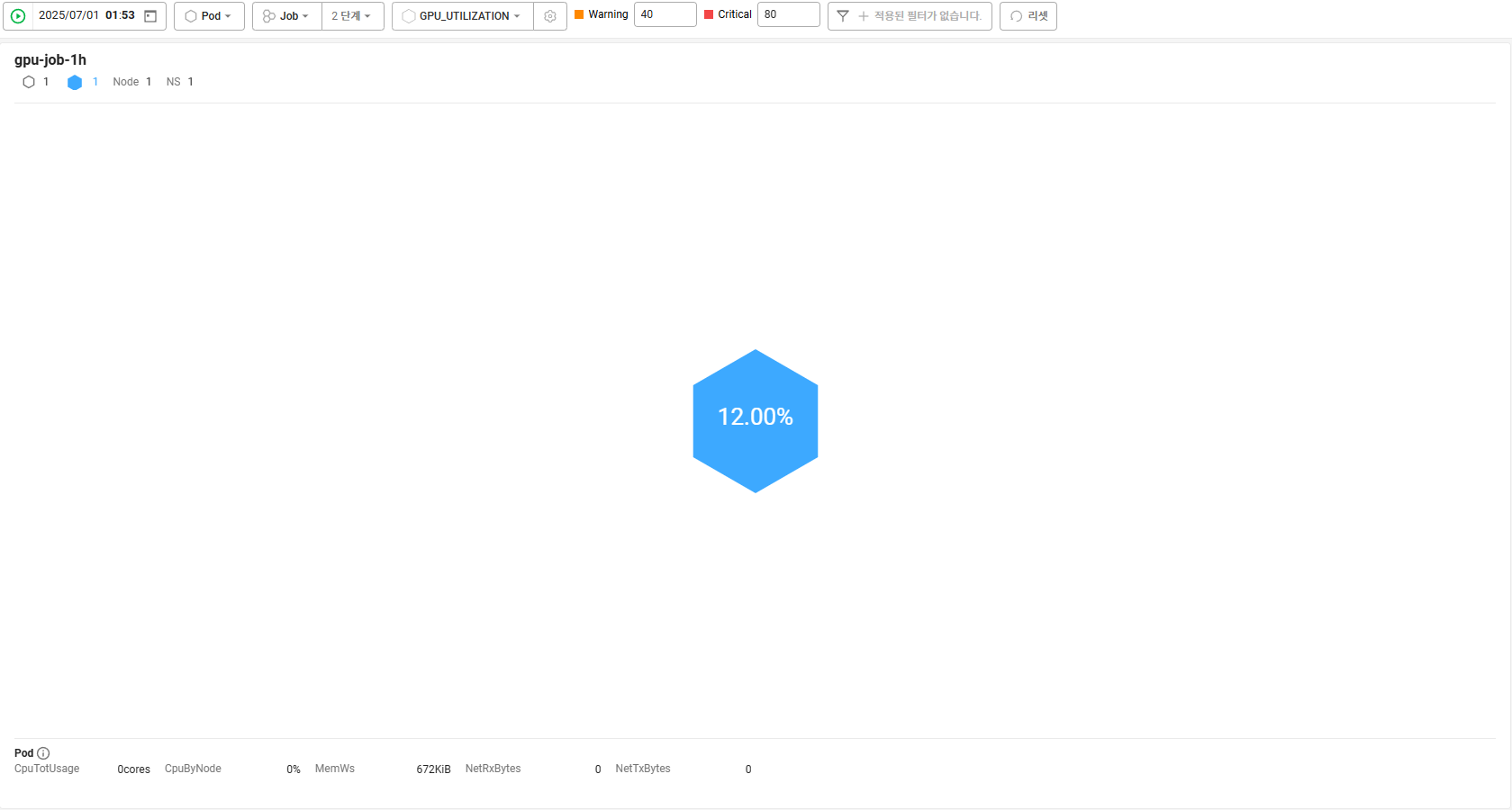
그룹화 (잡으로 그룹화 가능)
대시보드 > GPU 대시보드 (대시보드 구성필요없이 기본템플릿이 제공되어있음)
VRAM 은 많이잡아먹는데 utilization 은 낮음.
프로메테우스 , 데이터독도 설치해보고 후기를 쓰도록 하겟습니다.
