논문: https://arxiv.org/abs/2408.16967?utm_source=substack&utm_medium=email
코드:https://github.com/Bui1dMySea/MemLong
요약
이 논문은 MemLong이라는 모델을 소개하고 있습니다. 이 모델은 대형 언어 모델(LLM)이 긴 문맥을 효과적으로 처리할 수 있도록 개선된 방식입니다. 기존 LLM은 긴 문맥을 처리할 때 계산량이 급격히 증가하는 문제가 있었으나, MemLong은 외부 검색(retrieval) 시스템을 활용해 과거 정보를 저장하고 검색하여 이를 해결하려고 합니다. MemLong의 주요 특징은 다음과 같습니다:
-
메모리 확장: MemLong은 모델의 메모리 뱅크에 과거의 문맥을 저장하고, 필요한 경우 검색하여 해당 정보를 다시 활용합니다. 이를 통해 긴 문맥을 효과적으로 처리할 수 있으며, GPU 한 대에서 80k 토큰까지 처리할 수 있습니다.
-
부분 학습: 기존의 모델들과 달리, MemLong은 모델의 하위 계층을 동결(freeze)하고 상위 계층만 미세 조정하여 학습 효율성을 높였습니다. 이로 인해 학습에 필요한 자원이 대폭 줄어들었습니다.
-
성능 향상: 다양한 긴 문맥을 필요로 하는 태스크에서 기존 모델(OpenLLaMA 등)보다 더 우수한 성능을 보였으며, 검색-기반 학습 태스크에서도 최대 10.2%의 성능 향상을 기록했습니다.
-
동적 메모리 관리: 메모리가 가득 차면 가장 오래된 정보를 삭제하고 최근에 자주 검색된 정보를 유지하는 방식으로 메모리를 관리합니다. 이를 통해 중요한 정보를 유지하면서 메모리 사용량을 줄입니다.
실험 결과 MemLong은 다양한 긴 문맥 처리 및 검색-강화 학습 태스크에서 우수한 성능을 보여주었으며, 기존의 다른 방법들과 비교했을 때 적은 자원으로도 더 긴 문맥을 효과적으로 처리할 수 있었습니다.
1. Introduction (서론)
기존 limitation: 대형 언어 모델(LLM)은 다양한 분야에서 탁월한 성과를 거두었지만, 긴 문맥을 처리하는 데 어려움이 있습니다. 주로 주의 메커니즘(attention)의 시간 복잡도가 기하급수적으로 증가하고, 키-값 캐시 메모리 사용량이 커지기 때문입니다. 이에 따라 긴 문서 요약이나 다중 대화와 같은 긴 문맥을 요구하는 작업에서 문제가 발생합니다.
새로운 방법: 이를 해결하기 위해 MemLong이라는 새로운 방법을 제안합니다. MemLong은 외부 검색 모듈을 사용하여 과거 정보를 검색하고, 이를 바탕으로 보다 긴 문맥을 처리할 수 있도록 설계되었습니다. 이를 통해 MemLong은 대형 언어 모델의 문맥 처리 능력을 크게 향상시킬 수 있습니다.
2. Method (방법론)
MemLong은 두 가지 주요 모듈로 구성됩니다:
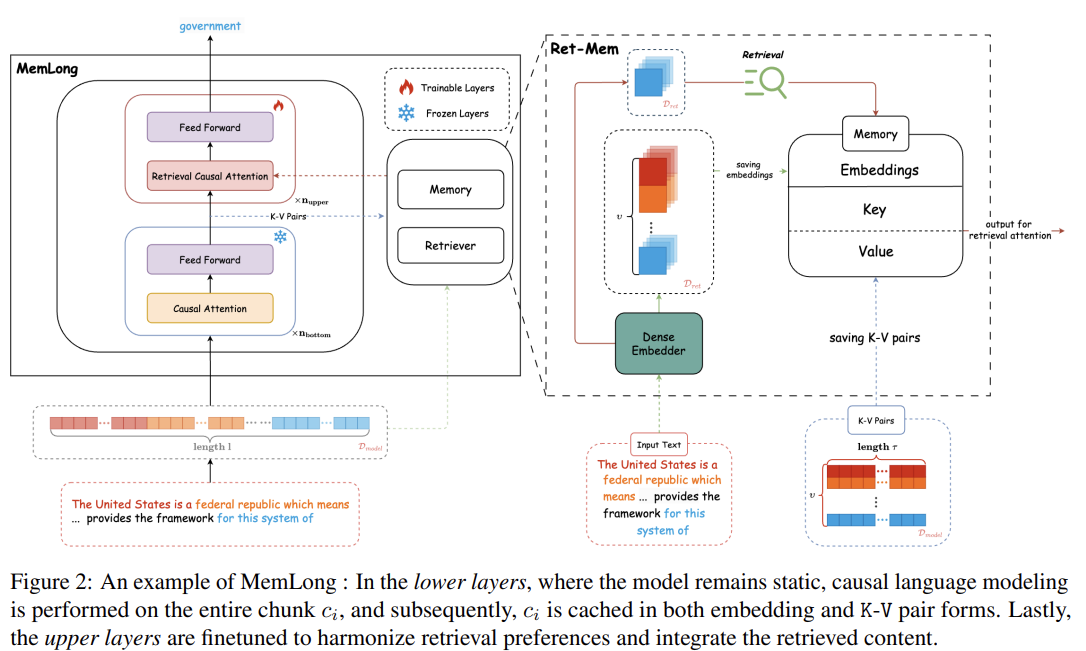
메모리 뱅크: 모델이 과거에 생성한 문맥 정보를 저장하는 역할을 하며, 이를 검색에 사용할 수 있습니다. 이는 훈련되지 않는 비차별적 모듈로, 모델의 파라미터에 영향을 미치지 않습니다.
검색-기반 인과주의(attention): 텍스트의 문맥을 부분적으로 처리하고, 필요한 경우 검색 모듈을 통해 과거의 정보를 가져와 이를 통합해 사용하는 방식입니다. 이 과정에서 문맥과 검색된 정보의 세밀한 연관성을 유지할 수 있도록 설계되었습니다.
MemLong은 또한 모델의 상위 계층에서만 미세 조정이 이루어지며, 하위 계층은 동결되어 있어 계산 복잡도를 줄이고 효율성을 높입니다. 이를 통해 MemLong은 기존 LLM의 한계를 극복하며, GPU 하나로 최대 80k 토큰까지 처리할 수 있습니다.
3. Experiment (실험)
MemLong의 성능을 평가하기 위해 여러 가지 실험이 진행되었습니다. 주요 실험은 다음과 같습니다:
긴 문맥 언어 모델링(Long-Context Language Modeling): 긴 텍스트를 효과적으로 처리할 수 있는지를 평가하기 위해 다양한 데이터셋에서 실험이 진행되었습니다. 그 결과 MemLong은 기존의 OpenLLaMA 및 다른 최신 모델보다 우수한 성능을 보였습니다.
검색-강화 언어 모델링(Retrieval-Augmented Language Modeling): 검색 메커니즘을 사용하여 추가적인 문맥 정보를 통합하는 작업에서도 MemLong은 탁월한 성과



모델의 상위 계층에서는 검색된 K-V 쌍을 현재 입력 문맥과 통합하여, 검색 참조를 조정하도록 모델의 매개변수를 튜닝합니다. 이


캐싱: 자주 사용되는 데이터를 임시로 저장해 두고 필요할 때 빠르게 불러오는 작업을 의미
이 논문에서 캐싱은 MemLong 모델이 K-V(Key-Value) 쌍과 청크 표현을 임시로 저장하는 과정을 의미
Cq와 Ci의 의미
Cq (쿼리 블록): 쿼리 블록은 모델이 현재 처리 중인 청크를 의미합니다. 즉, Cq는 현재 입력된 텍스트에서 처리되고 있는 하나의 작은 블록(청크)을 나타냅니다.
Ci (i번째 청크): Ci는 해당 입력 시퀀스에서 i번째 위치한 청크를 나타냅니다.
따라서, Cq = Ci는 현재 처리 중인 쿼리 블록(Cq)이 i번째 청크(Ci)라는 의미
tq = ti의 의미
tq는 쿼리 블록(Cq)에 대응하는 텍스트 블록을 의미합니다. ti는 i번째 청크에 해당하는 텍스트를 나타냅니다. 따라서 tq = ti는 현재 쿼리 블록(Cq)에 해당하는 텍스트가 i번째 청크의 텍스트와 동일하다는 의미입니다.
rq = R(tq)의 의미
여기서 rq는 쿼리 블록 tq를 R(·)이라는 검색기(Retriever)에 통과시켜 얻은 표현 임베딩(Representation Embedding)입니다. 즉, 검색기 R은 텍스트 tq를 입력으로 받아 해당 텍스트를 rq라는 벡터(임베딩)로 변환합니다. 이 벡터는 나중에 검색 과정에서 사용되며, 메모리에 저장된 다른 벡터들과 비교하여 관련된 정보를 검색합니다.

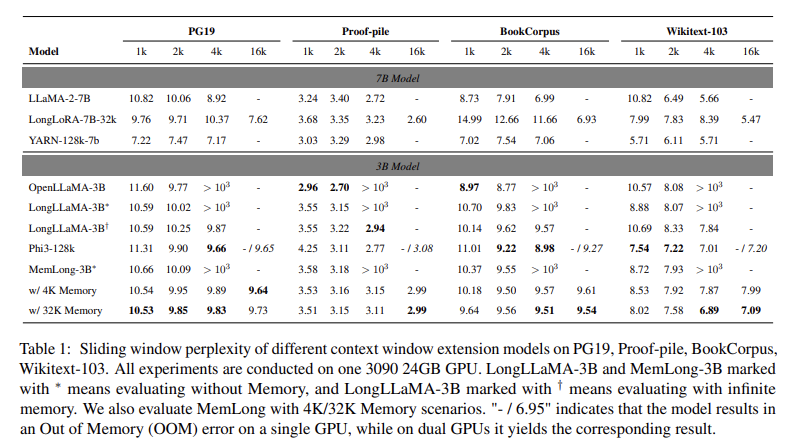
이미지에 나온 테이블은 PG19, Proof-pile, BookCorpus, Wikitext-103와 같은 다양한 데이터셋에서 여러 모델의 슬라이딩 윈도우 퍼플렉서티(Perplexity)를 비교한 것입니다. 퍼플렉서티는 언어 모델이 텍스트를 얼마나 잘 예측하는지를 나타내는 지표로, 값이 낮을수록 모델의 성능이 좋음을 의미합니다. 이 테이블은 7B 모델과 3B 모델에서 문맥 창 확장 능력을 테스트한 결과를 보여줍니다. 실험은 3090 24GB GPU를 사용하여 진행되었습니다.
테이블 설명
- 모델: 첫 번째 열은 실험에 사용된 모델을 나타냅니다. 7B 모델과 3B 모델로 나뉘며, 각각 다른 크기의 모델입니다.
- 1k, 2k, 4k, 16k: 각 열은 모델이 처리할 수 있는 문맥 창의 길이를 나타냅니다. 예를 들어, 1k는 1,000개의 토큰을 처리할 때의 퍼플렉서티, 2k는 2,000개의 토큰을 처리할 때의 퍼플렉서티입니다.
- PG19, Proof-pile, BookCorpus, Wikitext-103: 각각 다른 데이터셋에서 모델이 얼마나 잘 예측하는지를 나타냅니다.
Baselines (기준 모델)
- LLaMA-2-7B, LongLoRA-7B-32k, YARN-128k-7b: 7B 모델 기준에서 평가된 여러 최신 모델입니다.
- OpenLLaMA-3B, LongLLaMA-3B, Phi3-128k: 3B 모델 기준에서 평가된 여러 모델입니다. LongLLaMA-3B와 MemLong-3B는 각각 메모리 없이(*) 또는 무한 메모리(†)로 평가되었습니다.
Results (결과)
- 퍼플렉서티 비교: 퍼플렉서티(Perplexity)는 낮을수록 좋은 성능을 나타냅니다. 예를 들어, PG19 데이터셋에서 7B 모델인 LLaMA-2-7B는 1k 토큰에서 퍼플렉서티가 10.82인 반면, MemLong-3B는 10.66으로 성능이 비슷합니다. 그러나 메모리 없이(* 표기) 실행했을 때는 성능이 조금 낮아집니다.
- 메모리 크기: 3B 모델에서 MemLong-3B는 4K 및 32K 메모리를 사용했을 때 16k 토큰을 처리할 수 있는 성능을 보이며, 특히 Proof-pile 데이터셋에서 32K 메모리를 사용하면 퍼플렉서티가 2.99로 개선되었습니다. 이는 메모리 크기를 늘림으로써 더 긴 문맥을 처리할 수 있음을 보여줍니다.
- Out of Memory (OOM): 퍼플렉서티 수치 옆에 " > 10^3" 또는 "- / 6.95"와 같은 표시는 메모리 부족(OOM)으로 인해 실험이 중단된 것을 의미합니다. 즉, 특정 문맥 창 크기에서 모델이 GPU 메모리 용량을 초과하여 실행되지 않았습니다.
결론
이 테이블은 MemLong 모델이 다양한 문맥 길이를 처리할 때의 성능을 다른 모델들과 비교한 것입니다. MemLong은 긴 문맥에서도 메모리를 효율적으로 사용하여 높은 성능을 유지하며, 특히 4K 및 32K 메모리로 설정했을 때 성능이 눈에 띄게 개선됨을 보여줍니다.
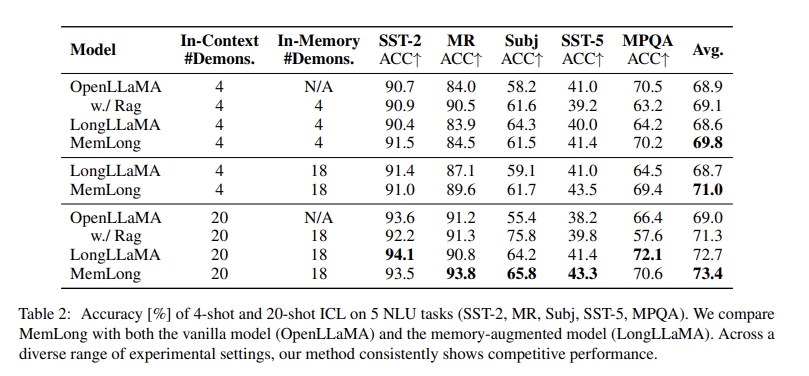
이 테이블은 논문에서 In-Context Learning(ICL) 실험을 통해 여러 모델의 성능을 비교한 결과를 나타냅니다. 해당 실험은 SST-2, MR, Subj, SST-5, MPQA와 같은 5개의 자연어 이해(NLU) 태스크에서 수행되었으며, 4-shot과 20-shot 학습 설정에서 모델이 얼마나 잘 성능을 발휘하는지를 평가합니다.
테이블 설명
-Model: 실험에 사용된 모델을 나타냅니다. OpenLLaMA와 메모리-증강된 모델인 LongLLaMA 및 MemLong이 비교 대상입니다.
- In-Context #Demons.: In-context 학습에서 사용된 샘플 수를 나타냅니다. 예를 들어, 4-shot 학습 설정에서는 4개의 샘플이 모델에 주어졌으며, 20-shot 설정에서는 20개의 샘플이 주어졌습니다.
- In-Memory #Demons.: 메모리-증강 학습에서 모델의 메모리에 저장된 샘플 수를 나타냅니다. LongLLaMA와 MemLong은 18개의 샘플을 메모리에 저장하여 학습에 활용했습니다.
- SST-2, MR, Subj, SST-5, MPQA: 각각의 열은 특정 자연어 처리 태스크에서 모델의 정확도(ACC%)를 나타냅니다.
SST-2: 감정 분석 태스크
MR: 영화 리뷰 감정 분석
Subj: 주관성/객관성 분류
SST-5: 다중 감정 분류
MPQA: 의견 분석 태스크
Avg.: 모든 태스크에서의 평균 성능을 나타냅니다.
이 테이블은 논문에서 In-Context Learning(ICL) 실험을 통해 여러 모델의 성능을 비교한 결과를 나타냅니다. 해당 실험은 SST-2, MR, Subj, SST-5, MPQA와 같은 5개의 자연어 이해(NLU) 태스크에서 수행되었으며, 4-shot과 20-shot 학습 설정에서 모델이 얼마나 잘 성능을 발휘하는지를 평가합니다.
테이블 설명
Model: 실험에 사용된 모델을 나타냅니다. OpenLLaMA와 메모리-증강된 모델인 LongLLaMA 및 MemLong이 비교 대상입니다.
In-Context #Demons.: In-context 학습에서 사용된 샘플 수를 나타냅니다. 예를 들어, 4-shot 학습 설정에서는 4개의 샘플이 모델에 주어졌으며, 20-shot 설정에서는 20개의 샘플이 주어졌습니다.
In-Memory #Demons.: 메모리-증강 학습에서 모델의 메모리에 저장된 샘플 수를 나타냅니다. LongLLaMA와 MemLong은 18개의 샘플을 메모리에 저장하여 학습에 활용했습니다.
SST-2, MR, Subj, SST-5, MPQA: 각각의 열은 특정 자연어 처리 태스크에서 모델의 정확도(ACC%)를 나타냅니다.
SST-2: 감정 분석 태스크
MR: 영화 리뷰 감정 분석
Subj: 주관성/객관성 분류
SST-5: 다중 감정 분류
MPQA: 의견 분석 태스크
Avg.: 모든 태스크에서의 평균 성능을 나타냅니다.
4-shot ICL 결과:
- OpenLLaMA: 4개의 샘플을 사용한 In-Context 학습에서 68.9%의 평균 정확도를 보였습니다.
- MemLong: 메모리를 활용한 MemLong 모델은 69.8%로, OpenLLaMA보다 약간 더 나은 성능을 보였습니다.
- LongLLaMA: In-Memory 학습을 통해 평균 정확도 71.0%를 기록했으며, MemLong보다 더 높은 성능을 보였습니다.
20-shot ICL 결과:
- OpenLLaMA: 20개의 샘플을 사용한 In-Context 학습에서 69.0%의 평균 정확도를 보였습니다.
- MemLong: MemLong은 이 설정에서 73.4%로 가장 높은 성능을 기록했으며, 특히 MR(93.8%)과 SST-2(93.5%)에서 뛰어난 성과를 보였습니다.
- LongLLaMA: 72.7%의 평균 성능을 기록했으며, MemLong과 비교할 때 전반적으로 약간 낮은 성능을 보였습니다.
결론
이 실험은 MemLong이 메모리-증강 학습을 통해 더 높은 정확도를 달성할 수 있음을 보여줍니다. 특히, 20-shot 설정에서 MemLong이 모든 모델 중 최고 성능을 기록했습니다. 이는 메모리에서 샘플을 저장하고 이를 효과적으로 활용함으로써 성능을 크게 개선할 수 있음을 시사합니다.
추가적으로, MemLong 모델은 다른 모델과 비교할 때 높은 정확도와 효율성을 보여주며, 특히 긴 문맥을 다룰 때 우수한 성능을 발휘합니다.
