
해당 강의는 미래연구소 15기에서 진행한 내용입니다 :)
https://futurelab.creatorlink.net/
Week 3 Assignment
https://github.com/jjaekkaemi/deeplearning/blob/main/Week3%20Assignment.ipynb
python의 기본 indexing, slicing
- numpy의
,사용 - 파이썬 기본 indexing, slicing 한계를 극복
- 빠르고, 편하다
fancy indexing
- 대괄호 안에 또 대괄호를 넣는 방식
- 내가 indexing한 부분들만 뽑아서 다시 이어주는 것
a[[1,3,4]]-> 1행 3행 4행 가져오기
overfitting
- 데이터가 많을수록 좋다.
- computation 능력으로 커버
- algorithm 사용
ex) 이미지내에서는 이슈가 있다 고양이 정면 사진으로만 학습 -> 다른 사진에서는 성능이 안나올 가능성이 있다. 이때 대표적으로 CNN 알고리즘이 필요 !
Vectorization
- sample vectorization
- node vectorization
activation
- 신경망 만들때 필요한 많은 선택 사항 중 하나는 숨겨진 레이어나 출력레이어에 적용되는 activation function을 무엇으로 할지이다.
sigmoid
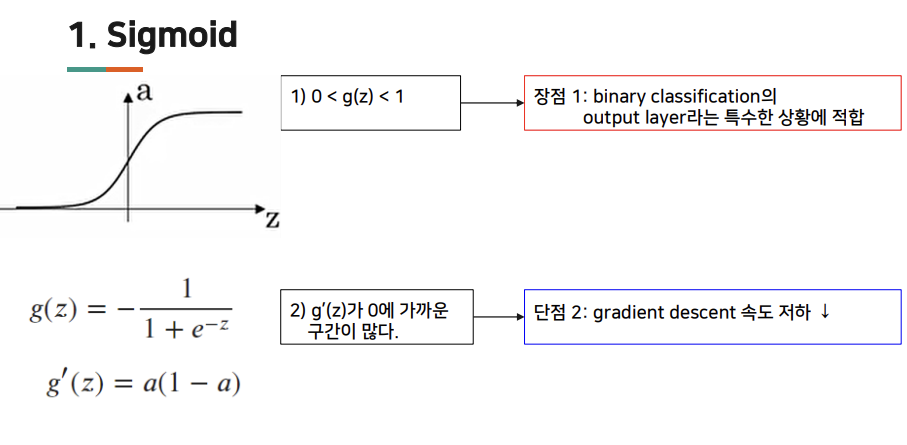
- 0과 1 사이, binary classification 에서 사용
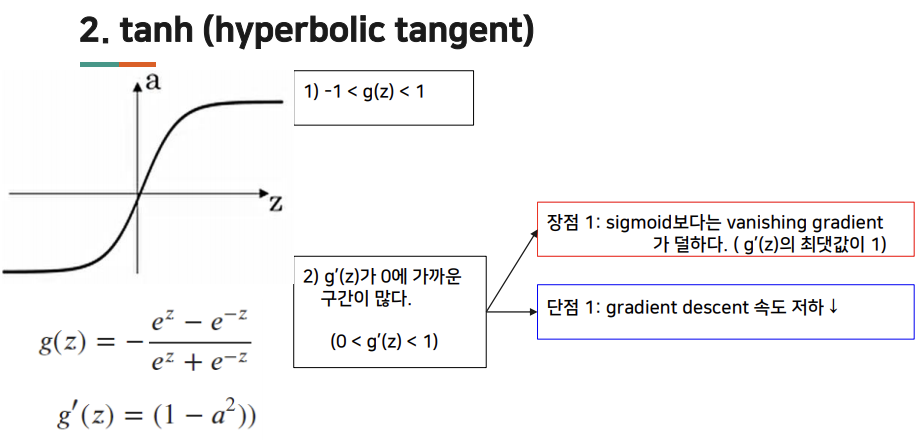
tanh
-
hyperbolic tangent 함수 : -1과 1 사이 -> 평균 값이 0에 가까워짐. -> hidden layer 활성화 함수 출력의 평균 값이 0에 가까워짐 -> 학습 알고리즘을 훈련시킬때 centering 효과를 가짐.
-
sigmoid, tanh 함수 단점 : z 값이 매우 크거나 매우 작은 경우, 미분의 기울기 또는 경사가 매우 작아짐. 함수의 기울기가 0에 가까워지기 때문에 gradient 속도가 느려짐.
ReLU
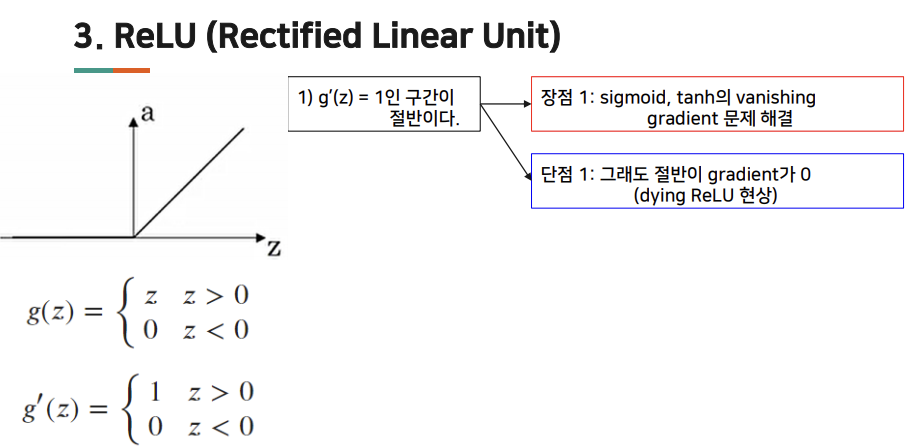
- ReLU 함수 : a=0과 z중 큰 값과 같다. z가 양수이면 미분 값은 1. 한편 z가 음수 이면, 기울기 또는 미분값은 0. z의 값이 정확히 0인 지점이없다. 단점 중 하나는 z가 음수 일때 미분 값이 0 -> leak relu 사용
Leak ReLU
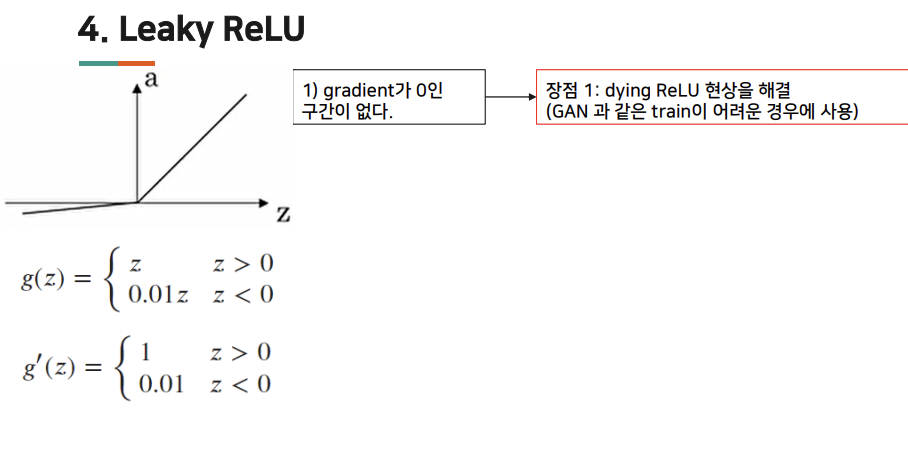
- 동일 layer에서는 같은 activation사용, 다른 layer끼리는 다른 activiation 사용 가능 activation 함수 사용하는 몇가지 규칙이 더 있다.
activation의 non-linear

- linear 연산을 하게 되면 최종결과도 linear 하게 되는 것.
- linear activation을 사용한다면 layer를 무수히 쌓아도 결과는 linear 하게 되는 것.
- 많은 데이터는 linear 하지 않은 경우가 많음. -> linear activateion 사용 -> 예측 ❌
output layer activation
supervised learning에 대한 범주.

- regression : 범위가 마이너스 무한대에서 무한대사이에 값 예측이 되기 때문.
- binary classification : 최종적으로 미분 계수를 계산하면 시그모이드로 계산된 값에 영향을 덜 미침.
- ReLU/Leaky ReLU : Leaky ReLU에서는 선형적인 모습이 더 많이 보이기도 함. 그러나 ReLU의 다잉 ReLU를 피하기 위해 Leaky ReLU를 쓰기도 한다.
vanishing gradient
vanishing gradient 라는 건 gradient가 사라지는 것을 의미한다. activation은 존재하는데 그 전에 NN 같은 경우, back propagation 뒤에서부터 미분계수를 곱한다.
gradient가 0에 가까운 것이 생기면 0이 되는데 w = w-알파*dw gradient 하는데 0에 가까워지면 update가 안 일어나거나 느려질 수 있다.
이 현상은 중간에 그래디언트가 0에 가까운게 있다면 최종적으로 계산했을 때 0에 가까운 현상이 나타나고 그래디언트 디센트가 잘 일어나지 않는다.
이러한 NN에서 초반의 그래디언트가 계산 되는데, 0에 가깝고 이런식으로 존재할경우 gradient 가 다 죽어버리는 것 layer의 미분계수가 0에 가까운 것.

Random Initialization
- 파라미터 값들을 0으로 initialization 하는 것의 단점
- 문제점 :
1. row symmetric 문제 - w 각 element가 같고, 0이기 때문에 node를 늘리는 것에 대한 의미가 없다.
2. vanising gradient 문제 - w 각 element 가 0이기 때문에 gradient descent가 일어나지 않을 수 있다.
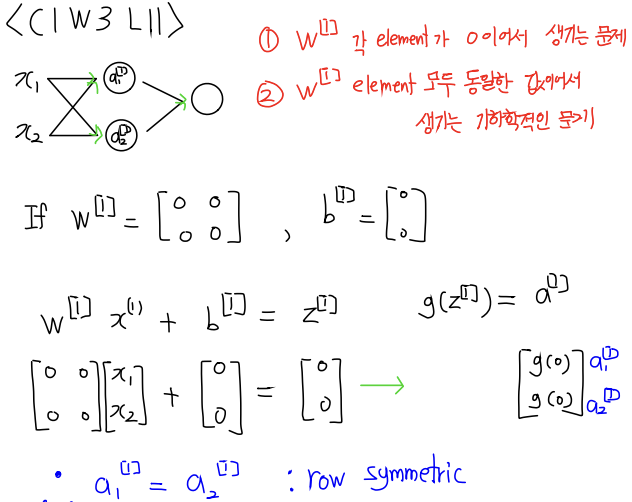
row symmetric
node를 여러개 두는 이유는 다양한 특징을 뽑기 위해서. 근데 zero initilazation 은 다양한 특징을 뽑지 못한다.
모든 행들이 같아 버리면 특징을 동일한걸 뽑아버리고 gradient descent도 동일하게 일어나버림. activation이 non linear 해야 하는 이유와 같은 것.
vanishing gradient
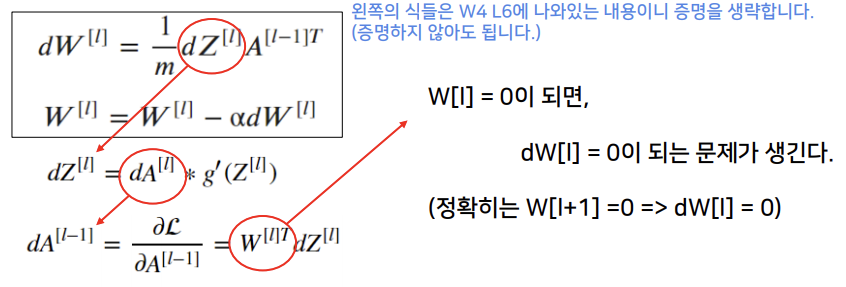
Random Initialization
대책 : random한 값을 주는 것.
np.random.randn(shape)을 사용하여 random 한 값으로 행렬을 만들기. 또한, 0인 수가 나오는 것을 방지하기 위해 0보다 큰 수를 곱해야 하고, 또 너무 작게 초기화 하면 안된다. 경험적으로 나온 수 0.01 곱하기.
0.01 * np.random.randn(shape)
Numpy
np.sum
axis 라는 개념에 대해 안내.
axis란 기존에 앞에 오는 게 행을 의미 다 훑어서 더하는 데 np.sum(a, axis=0)라고 하면 다른 방식으로 더함 0이 행을 의미, 1은 열을 의미.
행을 고정한채 행만 다 더해버림 열을 고정한채 열만 다 더해버림. 행으로 더하면 행이 0으로 바뀜, 열로 더하면 열이 0으로 바뀜.
ndim
- 대괄호의 개수를 알려줌
- sum을 하면 차원이 줄어드는 현상이 발생한다.
- ndarray를 더하면
[[ , , , ]]이렇게 나와야 하는데[ , , , ]이렇게 나와버림 - 차원을 유지하는 것 -> keepdims !
np.sum(keepdims = True)
Hyperparameter, parameter
- parameter
- 예시 : W,b
- 최적의 값을 찾는 방법 : gradient descent update 한다.
- hyperparameter
- 예시 : node 개수(=hidden layer size)
- 직접해본다.
- activation
hyperparmater 예시
layer의 개수, hypterparameter 는 tunning을 하는 것 !
