오늘은 Google의 AlphaGo에 대해서 설명하려고한다.
Google의 AlphaGo가 남긴 업적중 가장 대중적이게 알려진 일화는 프로바둑기사 이세돌씨를 이긴것이라고 할수있다. 최근 바둑을 배우는사람들, 심지어 세계적인 프로기사들마저 인공지능에게 바둑을 배우고있는 상황이다.
세계적인 프로선수들의 스승이 된 AlphaGo의 원리로는
경우의 수 줄이기가 대표적이다
인공지능으로 게임을 구현하면 주로 게임 트리를 구성하고 최적의 경로를 예측하는 게임 트리 탐색 알고리즘을 사용한다.
체스나 장기, tic-tac-toe 와 같이 두 플레이어가 번갈아가며 수를 두는 게임에 주로 사용되는 알고리즘이다.
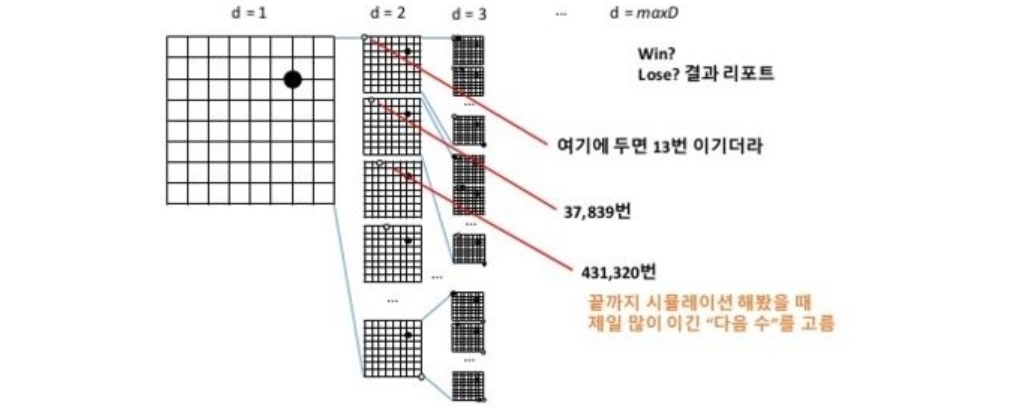

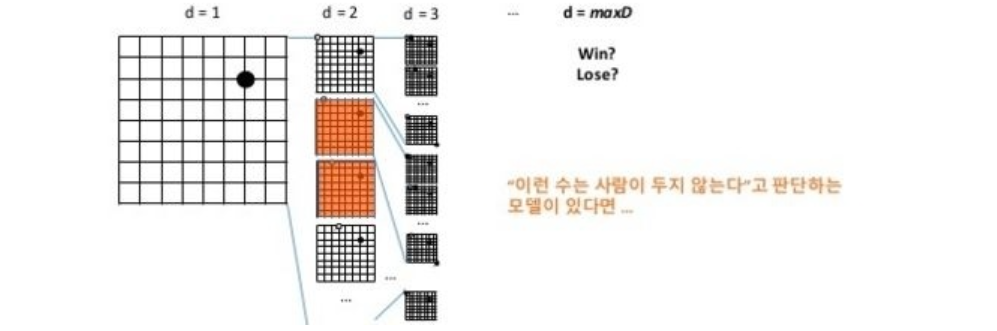

하지만 게임에서 시작부터 끝까지 모든 상태에 대한 완전한 탐색은 단순한 게임을 제외하고 현실적으로 불가능에 가깝다. 그렇기에 알파고는 사람이 잘 두지 않는 착점을 제외한다. 경우의 수를 줄이기 위함이다. 이를 지도학습이라 한다.


그렇기에 처음에는 지도학습의 결과를 그대로 이용하여 경기를 진행하지만 학습이 진행되면서 여러 버전의 네트워크가 생성되며 이들 간의 강화학습을 통해 실제로 승리하는 빈도가 높은 쪽으로 가중치가 학습된다.

강화학습의 개념으로는 지도학습의 결과로 구해진 정책네트워크는 사람의 착수 선호도를 표현하지만 이 정책이 반드시 승리로 가는 최적의 선택이라고 볼 수 없다. 이것을 보완하기 위해 지도학습 으로 구현된 정책 네트워크와 자체대결을 통해 결과적으로 승리하는 선택을 “강화” 학습하게된다.
이외에도 판세를 평가하여 게임에서의 신의한수를 놓을수도 있으며, 상대방에게서 자신이 배우지 못한 신의 한수가 나오더라도 순식간에 초기값으로 리턴하여 다시금 최적의 수를 놓을수 있다.
향후 몇일동안은 시험 기간이여서 이전처럼만큼 블로그를 자주 관리할수 없겠지만, 그래도 최선을 다해서 포스팅을 해볼 생각이다..!!
출처 : https://www.getnews.co.kr/news/articleView.html?idxno=4256
