
Overview
이번 프로그래머스 데브코스 2차 팀 프로젝트로 빙봉 팀에서는 “인터파크 티켓”의 클론 코딩을 진행하였습니다.
검색 기능을 엘라스틱 서치를 통해 구현하고, RDB만을 사용했을 때 보다 성능을 개선한 사례를 공유하겠습니다.
검색 기능 분석
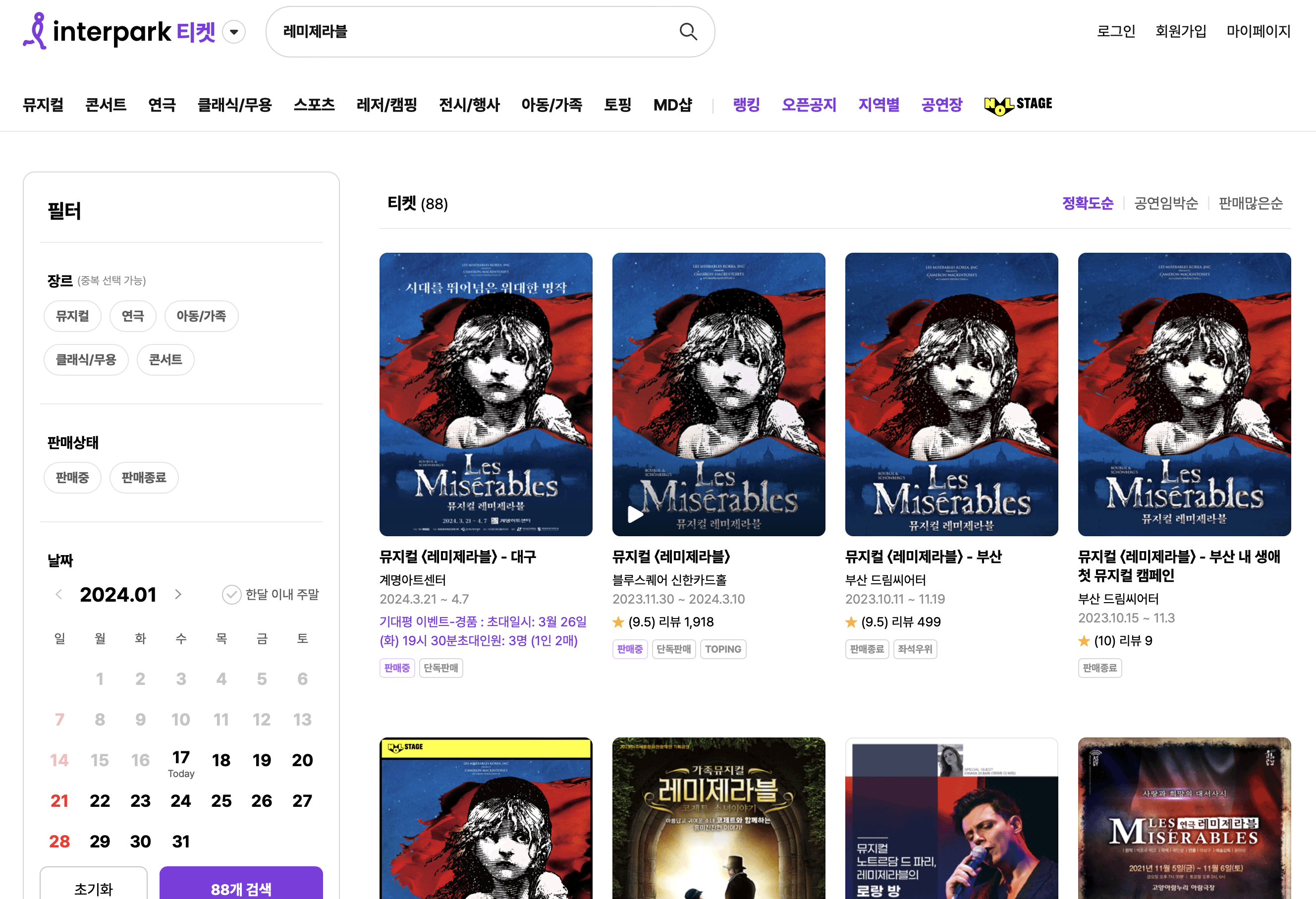
먼저 저희는 “인터파크 티켓” 검색 기능을 분석하였습니다.
- 키워드로 검색하면 공연의 제목 뿐만 아니라 내용, 장르까지 함께 검색됩니다.
- 부가적으로 유사어나 초성으로도 검색할 수 있습니다.
- 지연시간은 300ms 이내 였습니다.
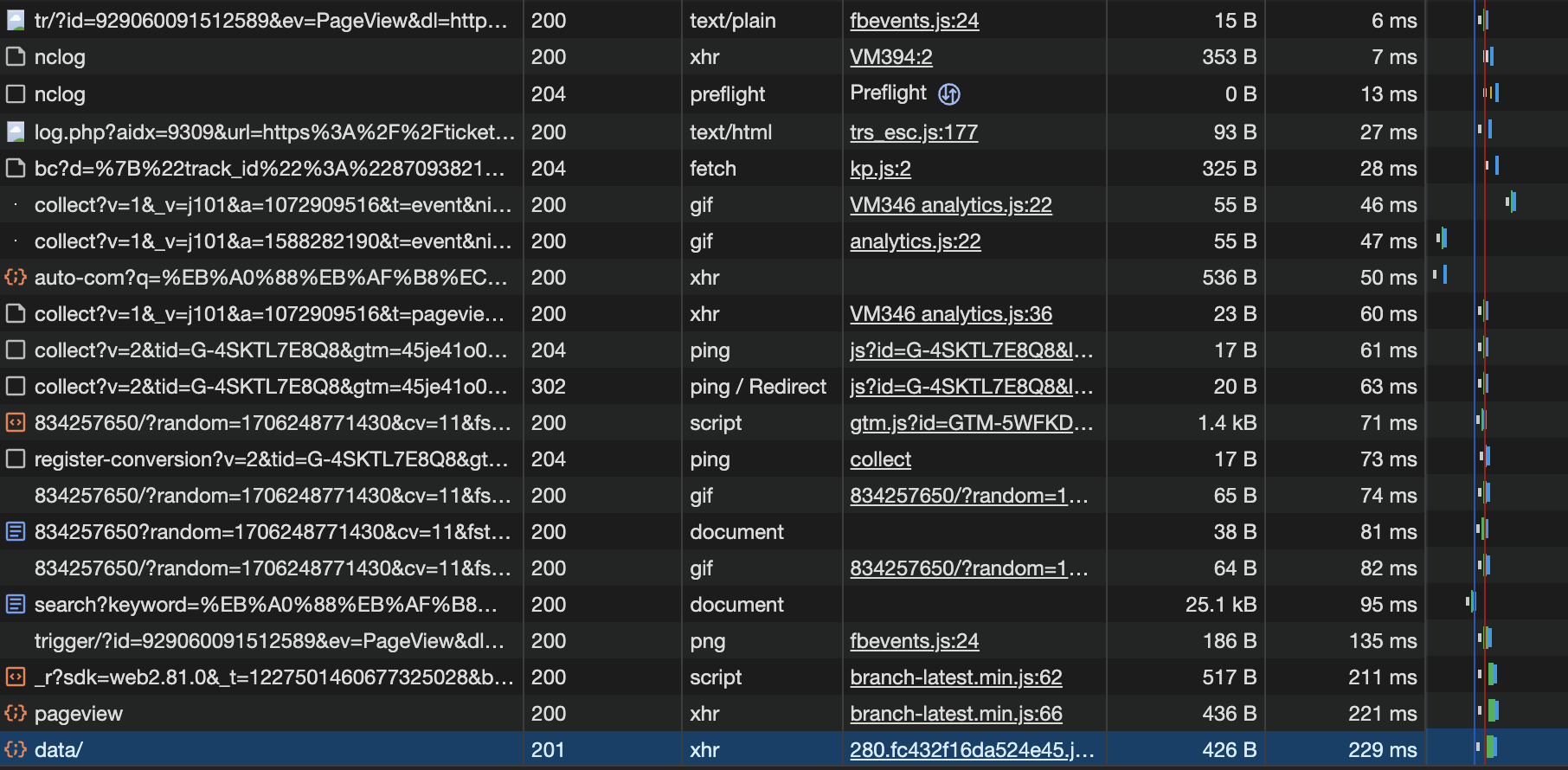
기능적으로나, 성능적으로 RDB와 JPA만을 사용하여 검색기능을 구현한다는 것은 꽤나 까다로웠습니다.
특히 유사어, 초성 관련 검색 기능은 JPA만으로 구현하기가 매우 어려웠습니다.
또 Like문을 이용해 검색 기능을 구현할 경우, 그 특성 상 Full Scan 방식으로 동작하기 때문에 데이터가 많거나 한 공연 내의 공연 내용이 100줄이 넘어가게 된다면 굉장한 시간을 초래하여 성능 저하가 발생할 것입니다.
따라서 검색 기능 구현에 "제목+내용+장르"안에 포함되는 검색 키워드를 빠른 시간안에 찾을 수 있는 기술로 Elasticsearch를 적용하게 되었습니다.
엘라스틱 서치가 왜 더 빠를까?

전통적인 RDB 에서 like 검색을 사용하면 데이터가 늘어날수록 검색해야 할 대상이 늘어나 시간도 오래 걸리고, row 안의 내용을 모두 읽어야 하기 때문에 기본적으로 속도가 느립니다.
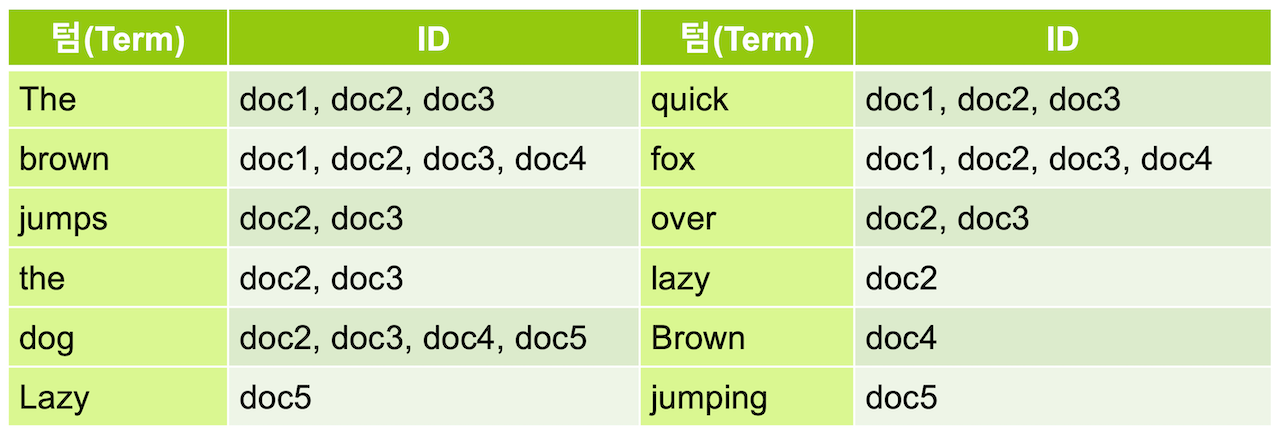
하지만 엘라스틱 서치는 역 인덱스(inverted index) 구조로 데이터를 저장하기 때문에 특정 단어가 어떤 인덱스(문서)에 저장되었는지 바로 확인할 수 있습니다.
출처 : 엘라스틱 서치 가이드북
검색 쿼리
1. JPA
- 코드 💻
@Override public Page<EventResponse> getEventsByKeyword(EventKeywordSearchDto eventKeywordSearchDto) { Pageable pageable = eventKeywordSearchDto.pageable(); int offset = pageable.getPageNumber() * pageable.getPageSize(); List<EventResponse> content = jpaQueryFactory.selectFrom(event) .where( containsKeyword(eventKeywordSearchDto.keyword()), // 키워드 검사 isGenreType(eventKeywordSearchDto.genreType()) // 장르 필터 ) .offset(offset) .limit(pageable.getPageSize()) .fetch() .stream() .map(EventResponse::of) .toList(); JPAQuery<Long> countQuery = jpaQueryFactory.select(event.count()) .from(event) .where( containsKeyword(eventKeywordSearchDto.keyword()), isGenreType(eventKeywordSearchDto.genreType()) ); return PageableExecutionUtils.getPage(content, pageable, countQuery::fetchOne); } private BooleanBuilder containsKeyword(String keyword){ BooleanBuilder booleanBuilder = new BooleanBuilder(); if(keyword == null) { return null; } booleanBuilder.or(event.title.contains(keyword)); booleanBuilder.or(event.description.contains(keyword)); return booleanBuilder; } // 생략
먼저 JPA, queryDsl와 like문으로 제목, 장르에서 키워드를 검색할 수 있는 기본적인 쿼리를 작성해주었습니다.
2. 엘라스틱 서치 (Spring Data ElasticSearch)
- 코드 💻
public Page<EventDocumentResponse> findByKeyword(EventKeywordSearchDto eventKeywordSearchDto) { Pageable pageable = eventKeywordSearchDto.pageable(); NativeQuery query = getKeywordSearchNativeQuery(eventKeywordSearchDto).setPageable(pageable); SearchHits<EventDocument> searchHits = elasticsearchOperations.search(query, EventDocument.class); log.info("event-keyword-search, {}", eventKeywordSearchDto.keyword()); return SearchHitSupport.searchPageFor(searchHits, query.getPageable()).map(s -> { EventDocument eventDocument = s.getContent(); return EventDocumentResponse.of(eventDocument); }); } private NativeQuery getKeywordSearchNativeQuery(EventKeywordSearchDto eventKeywordSearchDto) { NativeQueryBuilder queryBuilder = new NativeQueryBuilder(); Query query = QueryBuilders.match() .query(eventKeywordSearchDto.keyword()) .field("keyword_text") .build()._toQuery(); List<Query> filterList = new ArrayList<>(); if (eventKeywordSearchDto.genreType() != null) { List<FieldValue> fieldValues = eventKeywordSearchDto.genreType().stream() .map(FieldValue::of) .toList(); TermsQueryField termsQueryField = new TermsQueryField.Builder() .value(fieldValues) .build(); Query genreFilterQuery = QueryBuilders .terms() .field("genreType") .terms(termsQueryField) .build()._toQuery(); filterList.add(genreFilterQuery); } if (eventKeywordSearchDto.startedAt() != null) { Query startedAtFilterQuery = QueryBuilders .range() .field("startedAt") .gte(JsonData.of(eventKeywordSearchDto.startedAt())) .build()._toQuery(); filterList.add(startedAtFilterQuery); } if (eventKeywordSearchDto.endedAt() != null) { Query endedAtFilterQuery = QueryBuilders .range() .field("endedAt") .gte(JsonData.of(eventKeywordSearchDto.endedAt())) .build()._toQuery(); filterList.add(endedAtFilterQuery); } Query boolQuery = QueryBuilders.bool() .filter(filterList) .must(query) .build()._toQuery(); return queryBuilder.withQuery(boolQuery) .build(); }
엘라스틱 서치도 마찬가지로 제목, 장르, 설명에서 키워드를 검색할 수 있는 쿼리를 작성해주었습니다.
이때 음절 단위의 검색을 위해 ngram 분석기를 적용하고, 초성검색을 위해 추가 플러그인을 적용해주었습니다.
트러블 슈팅
엘라스틱 서치 timeout 에러
십만 건 정도의 데이터를 넣었을 때의 상황에서 테스트를 위해 공공 데이터 포털의 공연 데이터를 넣어주었습니다.
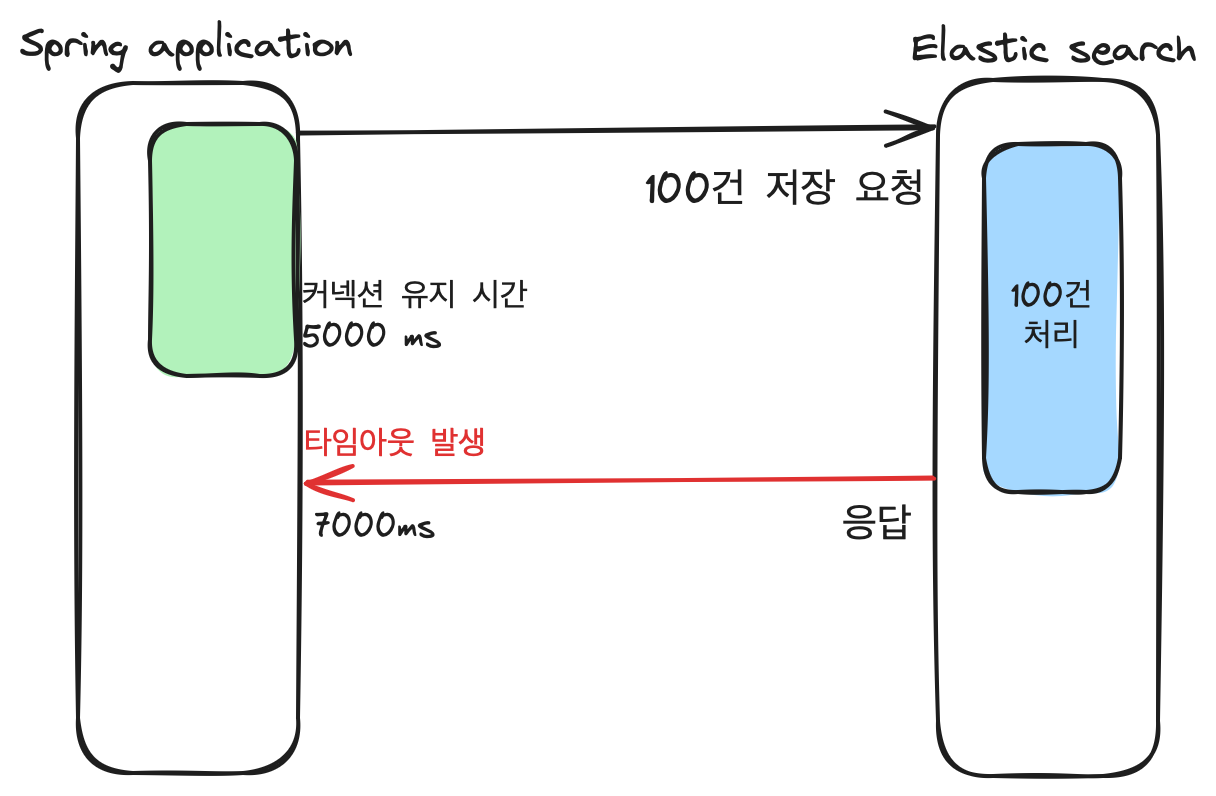
이 때 데이터를 빠르게 넣어주기 위해 bulk insert를 사용하였습니다.
어플리케이션에서 엘라스틱 서치로 요청을 보내는데, 그 특성 상 한번의 요청에 몇 백건의 데이터(도큐먼트)를 엘라스틱 서치에 저장하게 됩니다.
org.springframework.dao.DataAccessResourceFailureException:
5,000 milliseconds timeout on connection http-outgoing-0 [ACTIVE];그런데 일정 시간 안에 응답을 받지 못하면 timeout 오류가 발생하였습니다.
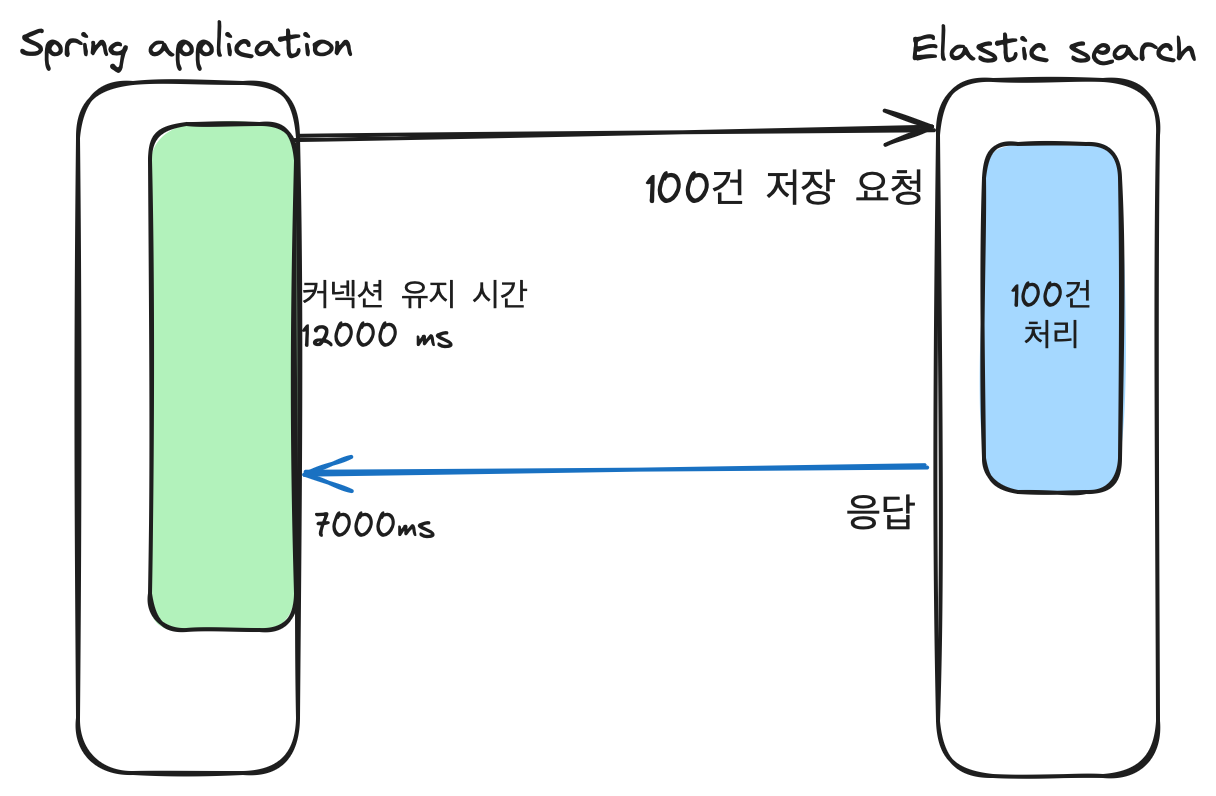
처음엔 엘라스틱 서치의 설정이 잘못되었다고 판단했으나,
결과적으로 Spring Data Elasticsearch Config 파일에서 커넥션 유지시간을 조정하여 해결할 수 있었습니다.
- config 파일
@Configuration
public class ElasticSearchConfig extends ElasticsearchConfiguration {
@Override
public ClientConfiguration clientConfiguration() {
return ClientConfiguration.builder()
.connectedTo("localhost:9200")
.withConnectTimeout(120000) // 커넥션 유지 시간
.withSocketTimeout(120000)
.build();
}
}성능 측정 - 더미 데이터 삽입
💡 우선 성능 측정에 앞서, “공공데이터포털” 사이트에서 공연 관련 “전국공연행사정보표준데이터”를 다운 받아 MySQL과 Elasticsearch에 각각 10만건 정도씩 데이터를 넣어 주었습니다.[ MySQL ]
@Service
@RequiredArgsConstructor
@Transactional
public class CsvReader {
private final EventRepository eventRepository;
private final EventSearchQueryRepository eventSearchQueryRepository;
private final EventHallRepository eventHallRepository;
private final JdbcTemplateEventRepository jdbcTemplateEventRepository;
public void saveEventCsv(String filepath) {
try {
String filePath = Paths.get(filepath).toString();
EventHall eventHall = eventHallRepository.findById(1L)
.orElseThrow(() -> new EventException(EVENT_HALL_NOT_FOUND));
try (BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream(filePath), "EUC-KR"))) {
List<Event> events = br.lines()
.skip(1)
.map(line -> line.split(","))
.map(data -> new EventCreateRequest(
data[0], data[2], 100,
LocalDateTime.now(), LocalDateTime.now().plusDays(10),
null, GenreType.MUSICAL,
LocalDateTime.now(), LocalDateTime.now().plusDays(10), 1L)
.toEntity(eventHall))
.collect(Collectors.toList());
jdbcTemplateEventRepository.bulkSave(events);
} catch (IOException e) {
throw new RuntimeException("Failed to load file", e);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}- 기존 JPA의 saveAll() 메서드를 통해 저장했지만 저장속도가 매우 느리고 쿼리 수가 굉장히 많았습니다.
- JdbcTemplate을 이용하여 쿼리가 한 번에 나가도록 Bulk Insert를 구현하여 진행했습니다.
[ Elasticsearch ]
public void saveAllDocument() {
int batchSize = 100;
List<Event> events = eventRepository.findAll();
List<EventDocument> documents = new ArrayList<>();
for (int i = 0; i < events.size(); i += batchSize) {
List<Event> batchEvents = events.subList(i, Math.min(i + batchSize, events.size()));
batchEvents.forEach(e -> documents.add(EventDocument.from(e)));
eventSearchQueryRepository.bulkInsert(documents);
documents.clear();
}
}
// elasticSearchQueryRepository
public <T> void bulkInsert(List<T> documents) {
try {
int chunkSize = 50;
List<IndexQuery> insertQueries = new ArrayList<>();
for (int i = 0; i < documents.size(); i += chunkSize) {
List<T> chunk = documents.subList(i, Math.min(i + chunkSize, documents.size()));
for (T document : chunk) {
IndexQuery indexQuery = new IndexQueryBuilder()
.withObject(document)
.build();
insertQueries.add(indexQuery);
}
elasticsearchOperations.bulkIndex(insertQueries, IndexCoordinates.of("events"));
insertQueries.clear();
}
} catch (Exception e) {
throw e;
}
}- 엘라스틱서치 메모리 부족, 네트워크 지연 등을 피하고자 chunkSize로 나누어 인덱싱을 진행했습니다.
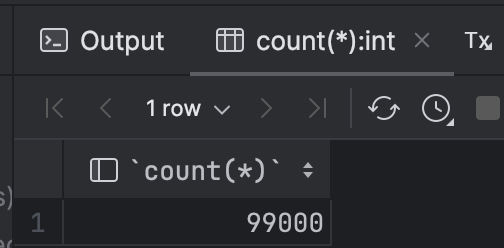
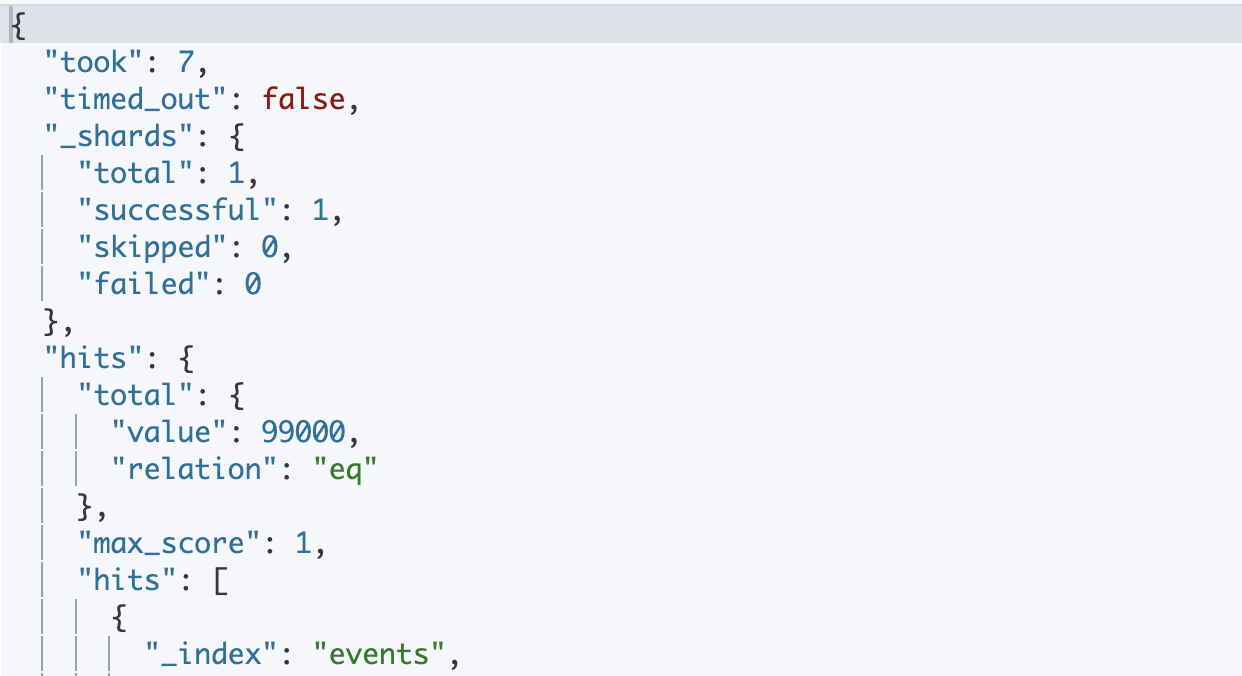
이렇게 데이터가 약 10만개의 데이터가 MySQL과 Elasticsearch에 들어간것을 확인할 수 있었습니다.
성능 측정 - JPA vs Elasticsearch
💡 데이터도 다 넣어주었기 때문에 마지막으로 JPA와 Elasticsearch의 검색 성능을 비교해보도록 하겠습니다. 검색 성능 측정은 각각 ExecutionTime을 비교할 수 있도록 AOP 어노테이션을 이용하여 진행하였습니다.[ 키워드 - 스프링 ]
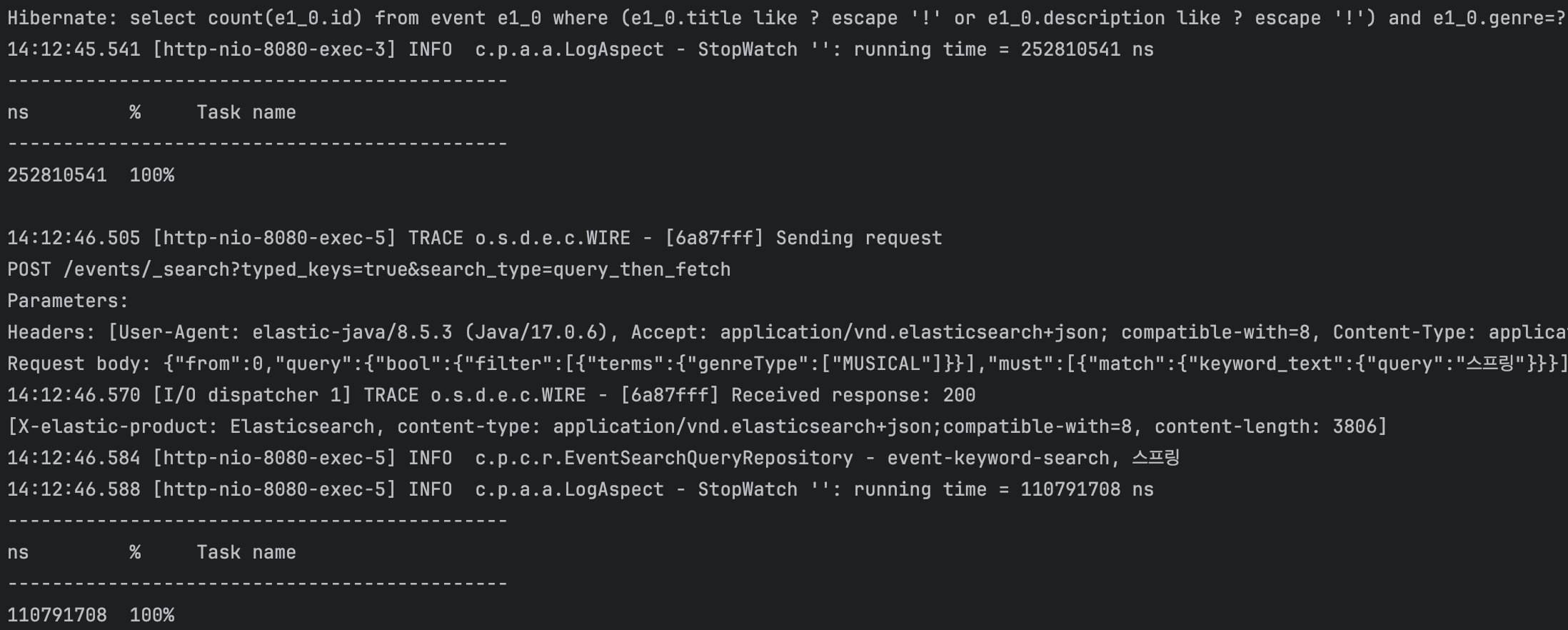
- JPA 측정 시간 (ms): 252810541ns ÷ 1,000,000 = 252ms
- Elasticsearch 측정 시간 (ms): 110791708ns ÷ 1,000,000 = 110ms
- 약 129% 성능 향상
[ 키워드 - 클래식 ]
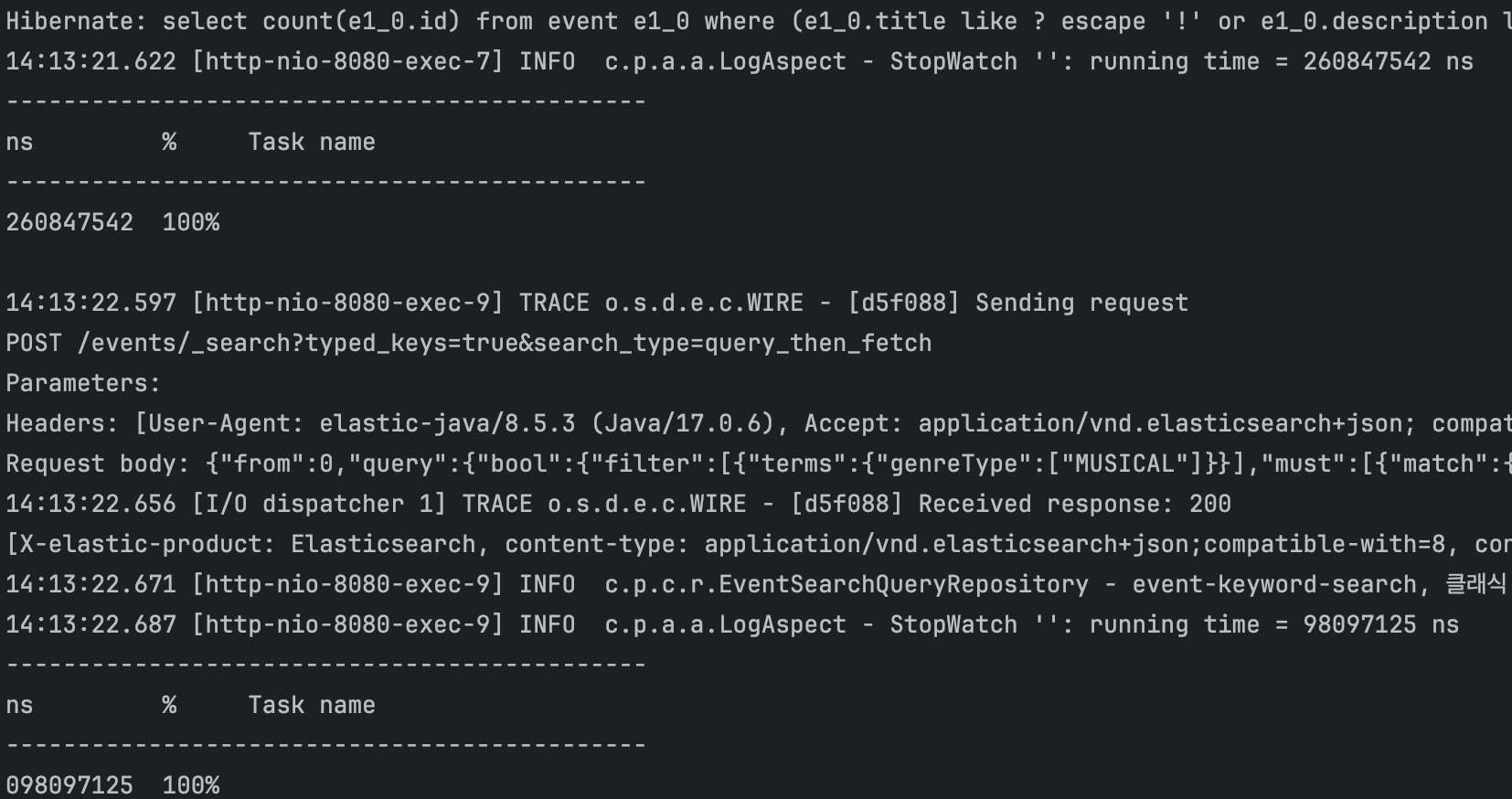
- JPA 측정 시간 (ms): 260847542 ns ÷ 1,000,000 = 260 ms
- Elasticsearch 측정 시간 (ms): 98097125 ns ÷ 1,000,000 = 98 ms
- 약 165% 성능 향상
→ 전반적으로 엘라스틱서치 키워드 검색이 검색 성능이 JPA에 비하여 좋은 것을 확인할 수 있었습니다.
마치며
도커를 통해 ELK 스택을 구성하거나, Spring Data ElasticSearch로 쿼리 코드를 작성할때
버전 마다 사용법이 상이하고, 관련 자료가 많이 없어 어려웠던 것 같습니다.
그럼에도 엘라스틱서치를 도입해 기능적, 성능적으로 보다 개선점을 도출해낼 수 있었습니다.
10만개의 데이터가 결코 적은 수의 데이터는 아니지만 훨씬 더 많은 데이터를 넣었을 때 그 차이는 분명 더 확실하게 확인할 수 있을 것 같습니다.
마지막으로 프로젝트나 엘라스틱 서치에 대해 관심이 있으시다면 아티클과 깃허브를 참고해주시면 좋을 것 같습니다. 🙇🏻♂️
< 깃허브 >
< 작성 아티클 >
< 참고 영상 >
