
서론
14기 CMC 개발 컨퍼런스에서 메시지 큐에 대해 발표하였다.
발표 내용과 함께 도커 스웜 환경에서 카프카를 활용해 대용량 트래픽에 대응할 수 있는 구조를 구축하는 법을 다루고자 한다.
가상 시나리오
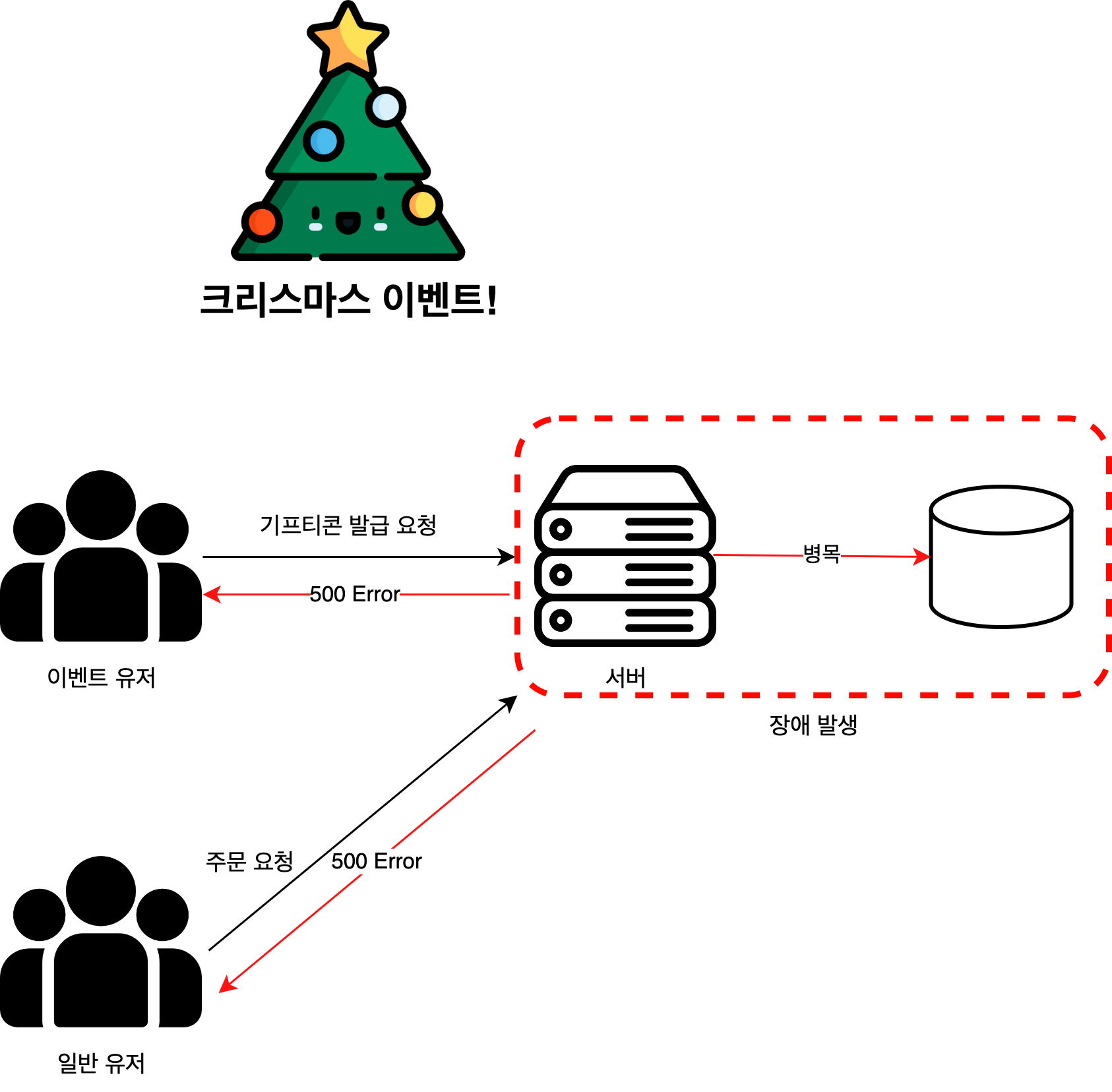
크리스마스 당일, 커머스 서비스에서 기프티콘 발급 이벤트를 진행한다.
이때 이벤트에 참여하는 유저가 많아, 요청량이 몰릴 경우 DB 서버에서 병목이 발생하여 시스템 장애로 이어질 수 있다.
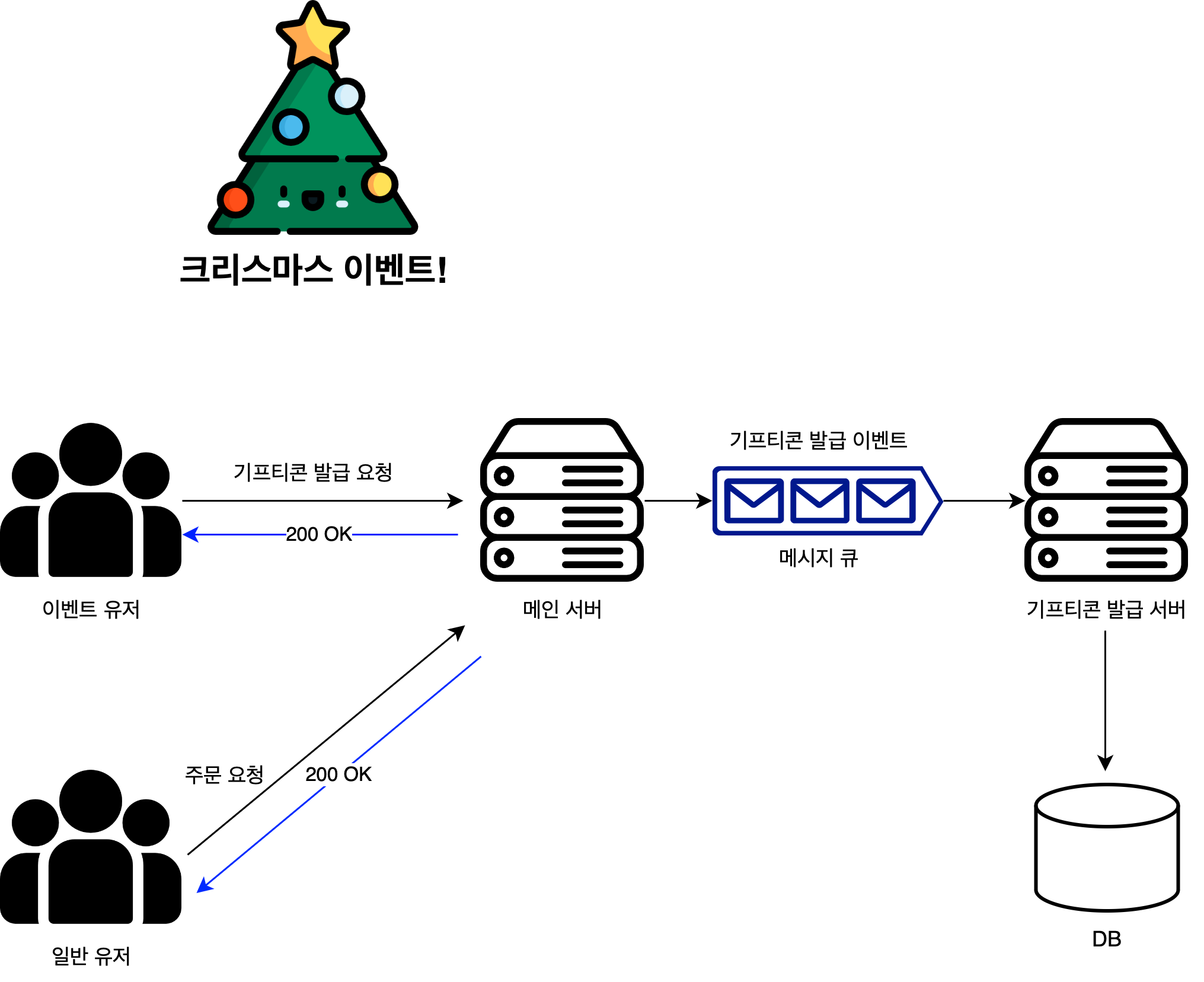
이를 해결하기 위해 메인 서버와 기프티콘 발급 서버를 분리하고, 이를 메시지 큐로 비동기적으로 연결한다.
- 메인 서버는 기프티콘 발급 요청 이외 요청은 처리하고, 기프티콘 요청은 메시지큐로 그대로 던진다.
- 기프티콘 발급 서버는 메시지 큐에서 메시지를 수신하여 요청을 지연하여 처리할 수 있다.
서버 구축
- 사용한 서버
기존에 구축한 도커 스웜 클러스터를 이용해주었다.
매니저 노드 1대, 워커 노드 6대(5대 + 카프카 서버 1대)로 구성하였다.
카프카 서버 배포
워커 노드 추가
# 매니저 노드
docker swarm join-token worker# 워커 노드
docker swarm join --token <스웜 토큰> <매니저 노드 ip>:2377 --advertise-addr <워커 노드 ip>서버 라벨 등록
docker node update --label-add kafka_server=true swarm-worker1카프카의 경우, t3.micro 서버에서 구동하기에 무리가 있다.
따라서 카프카는 특정 서버를 라벨로 지정해 배포해준다.
도커 스택 배포
version: '3'
services:
zookeeper:
restart: always
image: wurstmeister/zookeeper
container_name: zookeeper
deploy:
replicas: 1
placement:
constraints:
- node.labels.kafka_server == true # 라벨로 노드 제한
ports:
- "2181:2181"
kafka:
restart: always
image: wurstmeister/kafka:2.12-2.5.0
container_name: kafka
deploy:
replicas: 1
placement:
constraints:
- node.labels.kafka_server == true # 라벨로 노드 제한
ports:
- "9092:9092"
environment:
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka:19092,EXTERNAL://<서버 ip>:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_LISTENERS: INTERNAL://0.0.0.0:19092,EXTERNAL://0.0.0.0:9092
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_ADVERTISED_HOST_NAME: <서버 ip> # 외부 서버 ip 주소
KAFKA_ADVERTISED_PORT: 9092
KAFKA_CREATE_TOPICS: "coupon_create:1:1"
volumes:
- /var/run/docker.sock:/var/run/docker.sockdocker-compose.yml 파일을 매니저 노드에 작성해준다.
docker stack deploy -c docker-compose.yml kafka작성한 도커 컴포즈 파일로 도커 스택을 배포해준다.
스프링 어플리케이션 연동
컨슈머 어플리케이션 (기프티콘 발급 서버) 설정
@Configuration
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory<String, Long> consumerFactory(){
Map<String, Object> config = new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"<서버 ip>:9092");
config.put(ConsumerConfig.GROUP_ID_CONFIG, "group_1");
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
LongDeserializer.class);
return new DefaultKafkaConsumerFactory<>(config);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Long>
kafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory<String, Long> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}프로듀서 어플리케이션 (메인 api 서버) 설정
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, Long> producerFactory(){
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "<서버 ip>:9092");
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, LongSerializer.class);
return new DefaultKafkaProducerFactory<>(config);
}
@Bean
public KafkaTemplate<String, Long> kafkaTemplate(){
return new KafkaTemplate<>(producerFactory());
}
}스프링 어플리케이션 배포

- 싱글 브로커 카프카 서버 1대
- 프로듀서 (메인 api) 서버 4대
- 컨슈머 (기프티콘 발급) 서버 1대
를 구축해주었다.
RDS를 t3.micro 서버로 구축하여 커넥션 갯수에 제한이 있어 api 서버를 더 늘려줄 수 없었다.
Ngrinder 테스트
Ngrinder는 다음 블로그를 참고하여 구축해주었다.
https://velog.io/@poepoe117/nGrinder을-이용한-Spring-Boot-부하-테스트
참고사항
- Mac, Ec2 Ami 환경에서 오류가 발생하여 Ec2 t3.xl ubuntu 서버에 구축해주었다.
- 정밀한 결과를 위해서는 Controller, Agent 서버를 따로 구축해주어야 하나,
자본과 시간 관계 상 한대의 서버에 구축해주었다. - 버전은 3.4를 사용했다. (latest 버전은 오류가 발생한다!)
Ngrinder 테스트
Kafka 없이, 동시 접속자 6000명
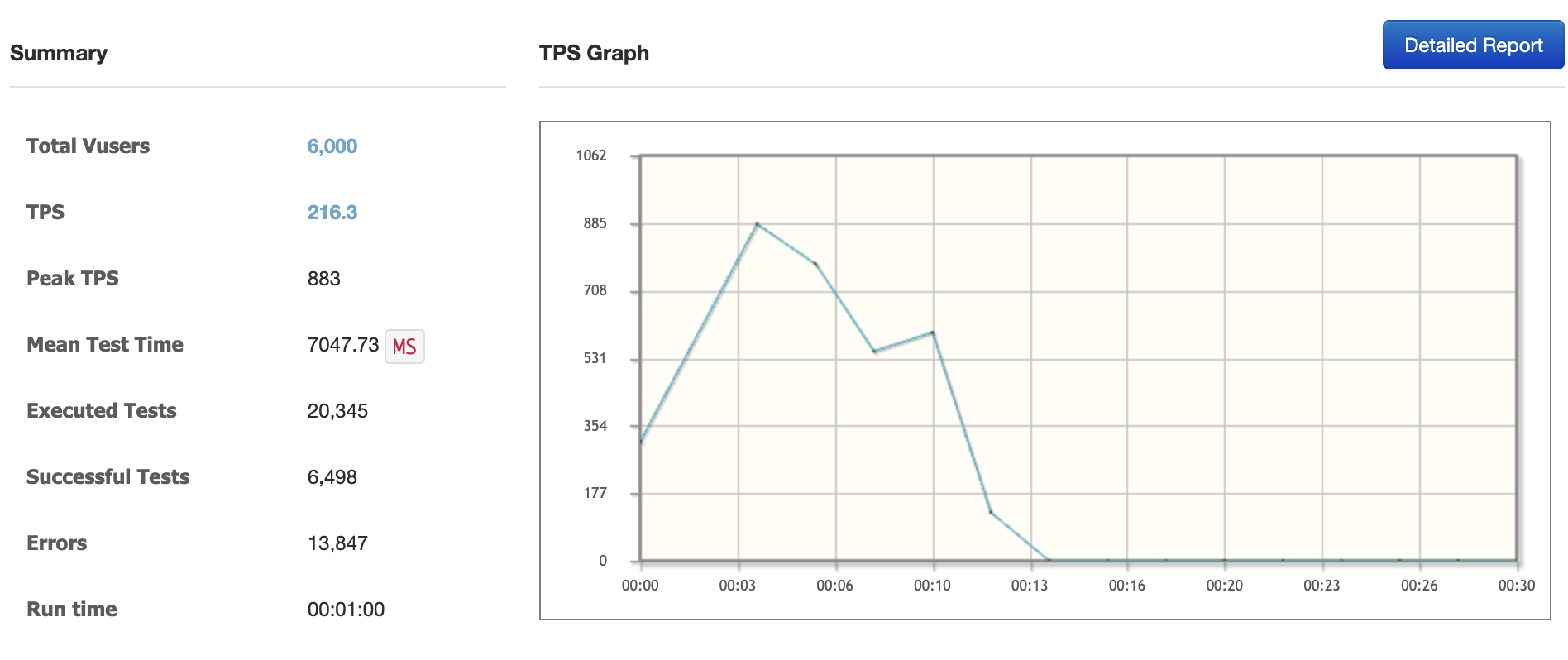
- Err rate 68.06%
Kafka, 동시 접속자 6000명
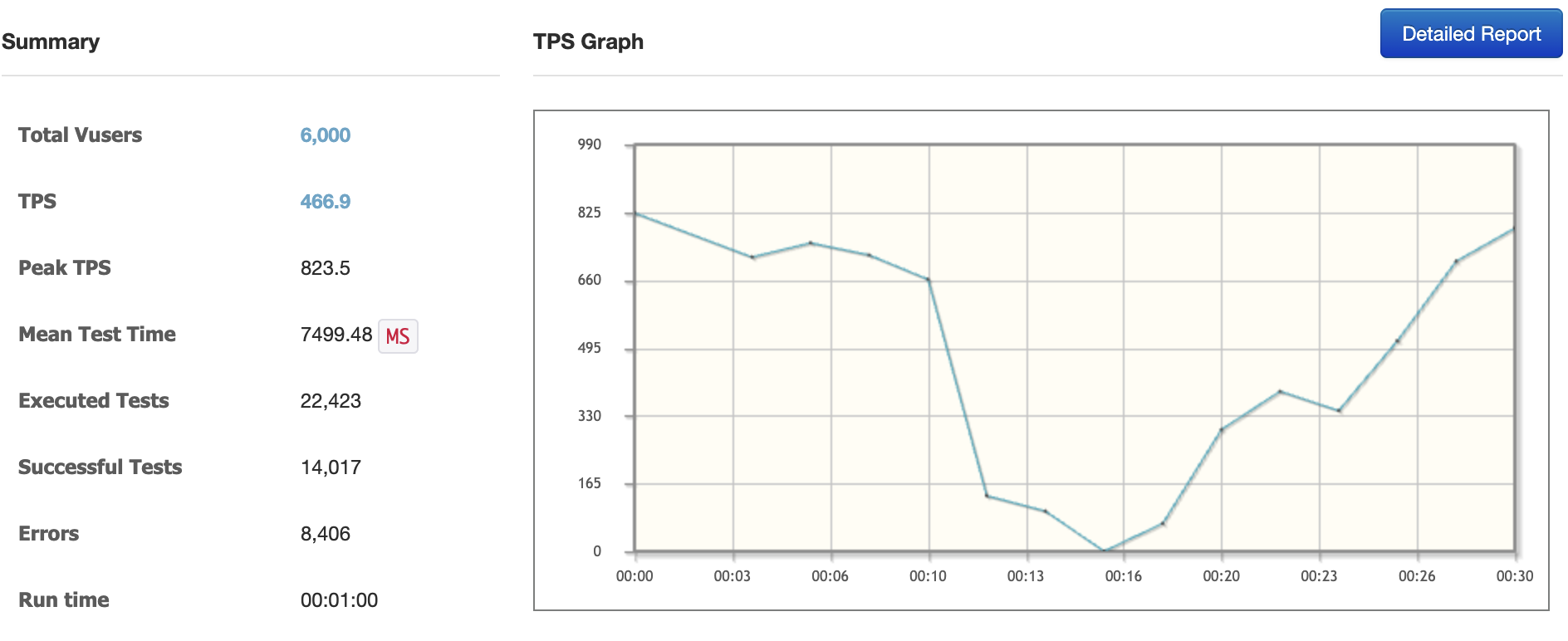
- Err rate 37.49%
카프카를 사용했을 때, 에러 발생율에서 약 44퍼센트의 개선사항이 있었다.
결론
카프카를 사용했을 때, 유의미한 개선사항이 있는 것을 확인할 수 있었다.
DB 서버를 스케일업 해주고 api 서버 댓수를 늘려준다면 더 극적인 결과를 만들 수 있을 것이다.
똑같은 EC2 서버를 여러 대 구축하는 과정에서 TerraForm의 필요성을 인지했다..
여러 대의 서버를 구축할 경우, TerraForm을 도입하면 좋을 것 같다.
