오늘은 우아한테크코스 멘토분들과 함께 한 용감한 겁쟁이 프로젝트 발표 내용을 공유하려고 합니다. 해당 프로젝트는 백엔드 4명이서 진행한 프로젝트로, 우리가 작업한 프로젝트를 기반으로 100만 데이터가 들어온다는 가정 하에 이를 어떻게 처리하면 좋을지 공부하고 적용해본 프로젝트입니다.
1. 프로젝트 소개
진행한 프로젝트는 대학생 개발자를 위한 협업 일정 공유 서비스로 바쁜 일정 속에서도 효과적인 협업이 필요한 대학생 개발자를 대상으로 한 서비스이다. 주요 기능은 일정 등록, 간트 차트를 통한 Plan-Do 비교 및 작업 관리이다.
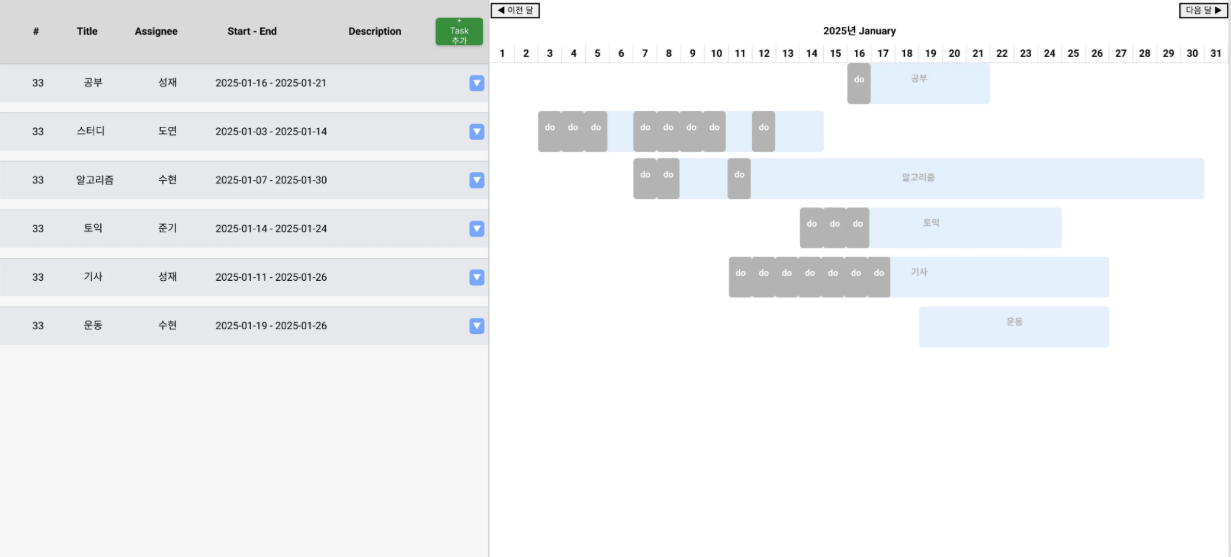
여기서 Plan&Do란?
Plan은 오른쪽 하늘색 bar를 의미하고 기간을 정해 해야할 일들을 등록할 수 있다.
Do는 오른쪽 회색 bar로, 하루씩 체크리스트 개념으로 찍히며 Plan을 달성하기 위해 실제로 어떻게 이루어지는지 직관적으로 확인을 할 수 있게 한다.
2. 동시성 처리
제일 처음으로 한 작업은 동시성 처리이다.
동시성(concurrency)은 여러 작업이 동시에 실행되는 것처럼 보이도록 처리하는 개념이다.
락은 동시성 문제를 해결하기 위해 공유 자원에 대한 접근을 제어하는 메커니즘이다.
우리 서비스에 적용해본 락은 총 세 가지다.
1) Pessimistic(비관적) 락
- 충돌 가능성이 높다고 가정하고 트랜잭션 시작 시점에 락을 걸어 다른 접근을 차단한다.
2) Named 락 - MySQL 'GET_LOCK()'을 활용한 락으로, 트랜잭션과 별도로 관리된다.
3) Redisson 락 - Redis를 활용한 분산 락으로, 멀티 서버 환경에서도 동작이 가능하다.
초당 요청 수 설정 근거
카카오 초기 가입자 증가를 분석하여 이를 적용하였다. 카카오는 초기에 하루 10만 명이 가입하여 이를 바탕으로 초당 평균 1~2명이 요청된다고 가정하고 피크 타임(3시간 기준) 초당 3개 이상 요청이 발생 가능하다고 가정하였다. 즉, 최대 부하를 고려해 초당 10개 요청을 기준으로 테스트를 진행하였다.
테스트 방법 및 환경
- ApacheBench 활용
- 각 락 방식별 1000개의 요청을 동시 처리하며 응답 속도를 측정하였다.
락 방식별 성능 비교 결과
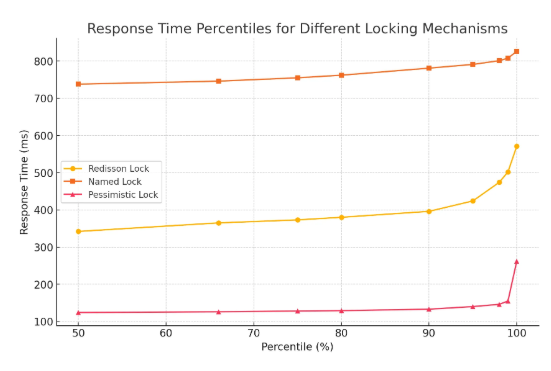
위와 같은 결과가 나왔고 이를 정리해보면,
1) Pessimistic Lock (비관적 락)
- 가장 빠름 (평균 124ms)
- DB 부하 및 Deadlock 가능성 존재
✔ 소규모 서비스 또는 단일 서버 환경에 적합
2) Named Lock (DB 락)
- 가장 느림 (평균 738ms)
- 트랜잭션 정합성 보장 강력
✔ 소규모 서비스에서 데이터 정합성이 중요한 경우 적합
3) Redisson Lock (Redis 기반 분산 락)
- 멀티 서버 확장 가능
- DB 부하 없이 동시성 제어 가능
✔ 대규모 트래픽 처리 및 분산 시스템 환경에 적합
성능 최우선: Pessimistic Lock
데이터 정합성 최우선: Named Lock
확장성 & 분산 환경: Redisson Lock
상황에 맞는 락을 선택하는 것이 중요하기 때문에, 우리는 확장성과 멀티 서버에서도 동작이 가능한 Redisson lock으로 서비스를 관리하기로 하였다. 최종적으로 Redisson을 적용하여 동시성 문제를 효과적으로 해결했으며, 기존 방식 대비 더 안정적이고 성능이 향상된 결과를 얻을 수 있었다!
3. Batch insert + JDBC를 이용한 데이터 100만개 넣기
Jdbc의 batchUpdate()를 사용하여
Team : User : Project : Team_Member : Plan : Do
1 : 6 : 1 : 6 : 80 : 480
와 같은 비율로 100만 데이터를 삽입하였다.
처음 코드를 실행할 때에는 2~3분 정도가 소요되어 찾아 본 결과, rewriteBatchedStatements라는 요소를 발견했다!
1) rewriteBatchedStatements 값이 false 일 경우
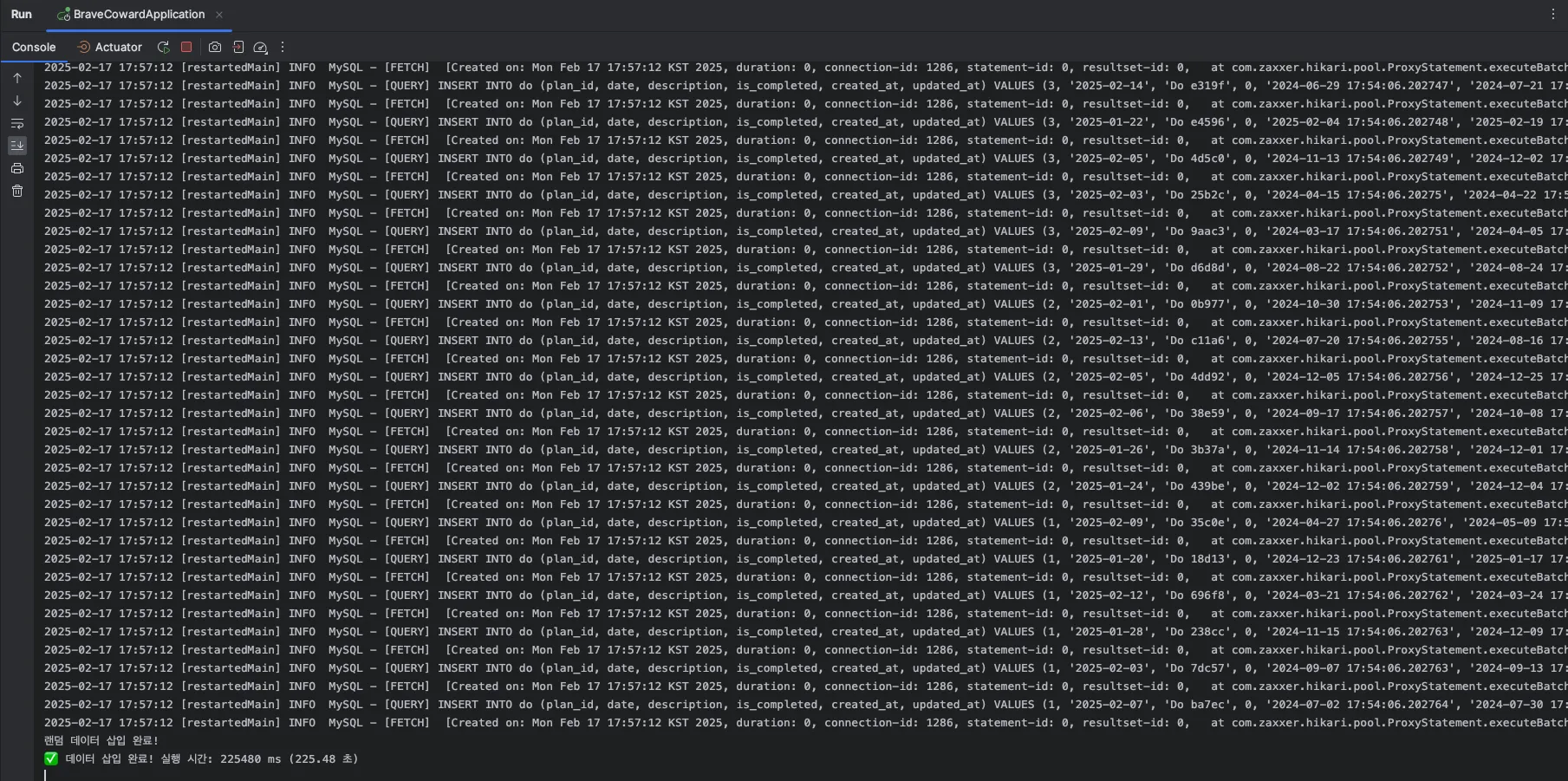

로그를 찍어보니 insert 쿼리가 개별적으로 실행되는 것을 볼 수 있다!
2) rewriteBatchedStatements 값이 true 일 경우

로그를 확인해보니 insert 쿼리가 bulk insert로 합쳐져서 실행되는 것을 볼 수 있다.
시간도 133s -> 18s로 개선되었다!
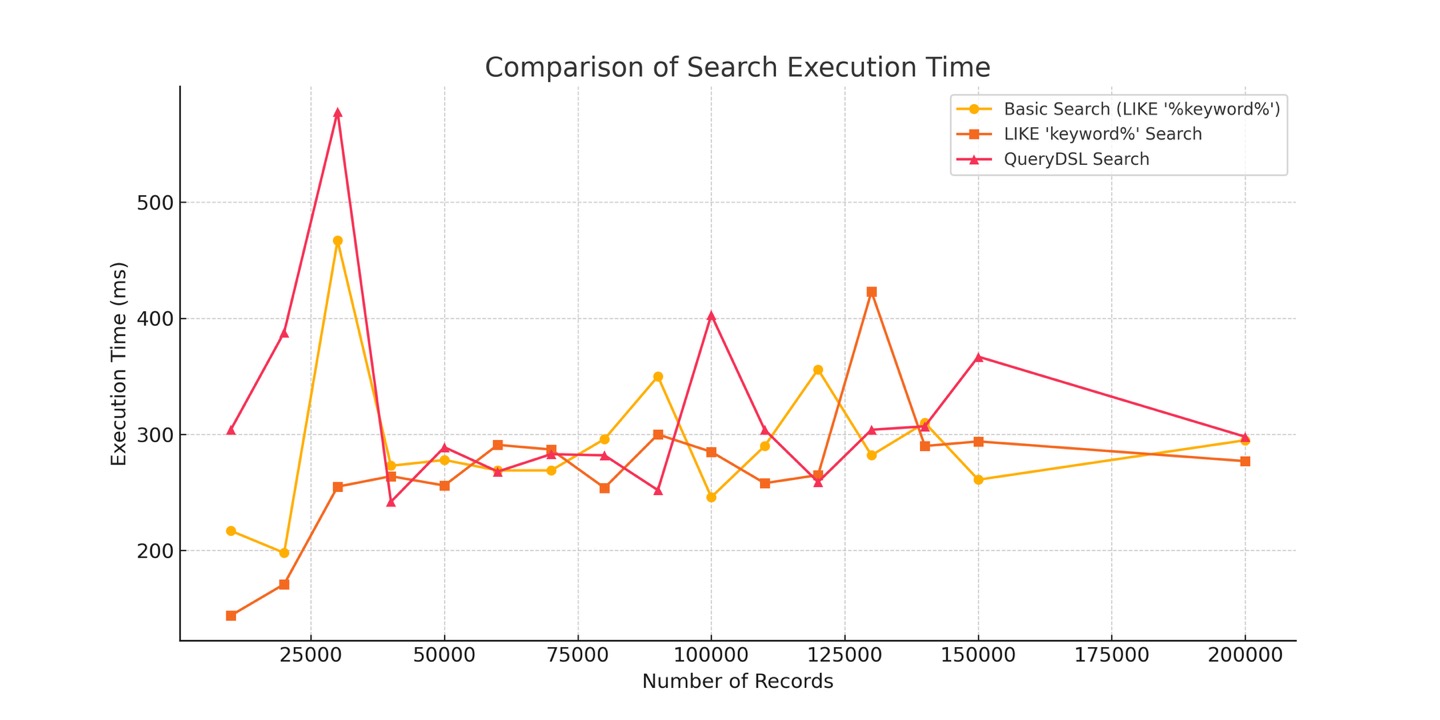
4. Do 검색 최적화
1) Full-Text 인덱스 vs 인덱스 LIKE
(1) 기존 LIKE 검색 (LIKE '%keyword%')
EXPLAIN SELECT * FROM do WHERE description LIKE '%keyword%';
- rows가 21,462개로, 모든 row를 검색하는 Full Table Scan 발생
- 인덱스를 활용하지 못해서 비효율적일 것으로 예상됨.
(2) Full-Text 검색 (MATCH ... AGAINST)
EXPLAIN SELECT * FROM do WHERE MATCH(description) AGAINST('keyword');
- rows가 1개로 대폭 감소
- 검색 대상이 줄었으니 더 빠를 거라고 예상함.
하지만!!!! 실제로 검색 실행해봤을 때
(1) 단순 검색(인덱스 LIKE) : 59ms
(2) Full-Text 인덱스 개선 전 : 7000ms
ORDER BY를 제거 → 이미 full-text 차원에서 정렬이 되기 때문에 추가 정렬을 하지 않게 되면서 속도 개선
(3) Full-Text 인덱스 개선 후 : 1100ms
즉, 예상과 달리 단순 검색이 더 빨랐다!
이유를 분석해본 결과, 생각보다 full-text index 연산이 무거웠고 projectId = 2와 같이 숫자나 고정된 값을 기준으로 데이터를 필터링하려면 성능이 저하될 수 있다는 부분이 있었다. 또한, 예시 데이터가 description 내용이 do + 랜덤숫자로 단순하게 구성돼있어서, full-text index를 적용하려면 실제 회의록 내용처럼 글 구성이 복잡하고 길어서 찾기가 더 어려워야 더 적용하기 좋을 것 같다라는 결론이 나왔다.
2) LIKE '%keyword%' vs LIKE 'keyword%' 속도 비교
=> LIKE '%keyword%' 보다 LIKE 'keyword%' 가 훨씬 빠르다.
%keyword%형태는 문자열 전체를 탐색해야 해서 인덱스를 활용할 수 없음keyword%형태는 B-Tree 인덱스 활용 가능, 성능 향상
3) QueryDSL 적용 효과
=> QueryDSL 변환 후 LIKE '%keyword%' 형태의 검색 속도가 개선되었다.
실행 속도가 개선된 이유:
- QueryDSL이 내부적으로 최적화된 실행 플랜을 생성할 가능성이 큼
- JPQL 변환 과정에서 MySQL이 추가적인 최적화를 수행할 수 있음
orderBy(d.id.desc())를 활용한 정렬 최적화가 적용될 수 있음- QueryDSL이 동적 검색을 최적화할 수 있음
5. 이메일 전송 최적화
마감기한이 임박한 일정을 가진 사용자에게 이메일을 전송하는 기능으로, 총 13500개의 이메일을 전송해야한다.
하지만, gmail의 smtp는 1회에 100회, 하루에 500회까지 제한되어 있어서 따로 이메일 전송 시간을 측정해서 sleep을 걸고 이메일을 보냈다고 가정하고 최적화하였다!
이메일을 직접 전송해본 결과, 이메일 10개씩 전송할 때, 평균 약 45초가 걸려서 이메일 1개 전송 당 4.5초의 sleep()이 필요하다고 가정하였다.
우리가 보내야하는 메일의 개수는 plan 개수에 9213개였고, 이를 sleep()과 계산해보면 대략 11시간동안 메일을 보내야했다.. 그래서 이 부분을 최적화하기로 했다!
Spring Batch 도입
@Async 와 Spring Batch 의 차이
(1) @Async 를 사용하는 경우
sendMockEmail비동기적 실행- 별도의 스레드에서 수행되지만 비동기 실행을 예약하는 방식이라 병렬 처리와는 다르다
(2) Spring Batch 를 사용하는 경우
chunk()가 실행될 때, 여러개의chunk를 병렬로 실행- taskExecutor이 여러 개의 스레드를 통해
step을 동시에 여러 개 실행 가능 @Async없이 병렬 처리 가능
결론: 마감 이메일 전송에 대해서, 보내야 할 메일이 적을때는 1개의 스레드에서 동기적으로 보내도 무리가 없었는데 수많은 메일 전송을 가정해보니 여러개의 스레드를 통해 병렬적으로 처리해주게 되었다!
8개월동안 진행한 프로젝트고 100만 데이터 처리까지 공부할 수 있어서 정말 뜻깊었습니다! 나중에는 redis를 이용해서 해당 작업을 보완해보려고 합니다.
진행한 ppt 자료를 첨부하며 글 마무리합니다!!🎯💯✨
