📓 N+1 문제란?
요청이 1개의 쿼리로 처리 되길 기대했는데 N개의 추가 쿼리가 발생하는 현상
1개의 쿼리를 실행하려고 했는데 N개의 쿼리가 추가로 실행되는 것이기 때문에
1+N이라고 이해하면 더 직관적이다
📓 @OneToMany에서 발생할 때
N+1 문제는 많이 상황에서 발생한다.
@ManyToOne, @OneToOne, @ManyToMany, @OneToMany, 양방향, 단방향 ...
이번 게시물에서는 @OneToMany에서 N+1 문제가 발생하는 상황에 대해서 알아보려고 한다.
📓 지연(Lazy) 로딩이란?
@OneToMany(mappedBy="크루", fetch=FetchType.LAZY)
List<할 일> 목록- 기본적으로 객체의 연관된 데이터를 즉시 불러오지 않고, 필요한 순간에 조회하는 방식
- 데이터가 필요할 때 쿼리를 실행하여 메모리 사용을 최적화할 수 있음
📓 지연로딩일 때, N+1 문제 상황
크루_Repository.findAll()로 크루 목록들을 조회해본다고 가정하자
이를 쿼리문으로 바꾸면 select * from crew가 된다.
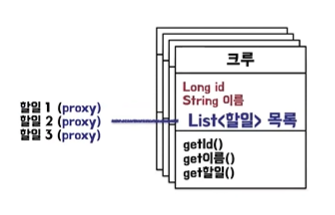
- 할 일 목록 리스트는 지연 로딩으로 설정했기 때문에 지금 사용하지 않아서 사용하는 시점에 가져오기 위해 proxy 객체로 설정해놓았다.
🖋️ proxy 객체란?
- Hibernate가 제공하는 가짜 객체
- 실제 데이터를 즉시 로딩하는 것이 아니라, 필요할 때 데이터베이스에서 가져오는 방식
// 크루 엔티티 조회 (할 일 목록은 지연 로딩) Crew crew = entityManager.find(Crew.class, 1L); // 이 시점에서는 '할 일 목록'을 조회하지 않음 System.out.println("크루 이름: " + crew.getName()); // 할 일 목록을 조회하는 순간 쿼리 실행됨 (지연 로딩 발생) System.out.println("할 일 개수: " + crew.get목록().size());
- 지연 로딩된 프록시 객체는 트랜잭션이 끝난 후 접근하면 오류 발생
Crew crew = crewRepository.findById(1L).get(); // 할 일 목록은 아직 프록시 상태 em.close(); // 영속성 컨텍스트 종료 // 여기서 할 일 목록을 조회하면 LazyInitializationException 발생 System.out.println(crew.get목록().size());
이때까지는 쿼리가 하나만 나가는데, 크루당 할 일이 많아보여서 크루 한 명당 몇개의 할 일을 하는지 알아보고 싶어짐.
for (크루 크루: 크루들) {
크루1.목록(proxy).getSize()
}첫번째 크루를 확인해보니까 proxy라서 jpa가 1차 캐시 저장소에서 크루1 목록이 있는지 확인해본다. 여기서 해당되는 데이터가 없기 때문에 select * from 할일 where 크루_id = 1이라는 쿼리를 날려서 데이터를 가져오게 된다. 이게 모든 크루에서 반복된다.

실제로 실행되는 쿼리를 보면 위와 같다.
2개의 데이터만 조회한다면 큰 문제가 없겠지만, 100만 데이터를 조회해야한다면 성능에 큰 부하가 생길 것이다.
📓 지연 로딩일 때, 해결 방법(fetch join)
해결 방법에는 fetch join를 활용하거나 @EntityGraph를 사용해서 해결하는 방법이 있다. fetch join을 활용해서 해결하는 방법에 대해 알아보자.
@Query("select c from 크루 c left join fetch c.목록")
List<크루> findAllJPQLFetch();JPQL이란?
Java Persistence Query Language
엔티티를 대상으로 쿼리 작성
이 해결방법을 쿼리문으로 알아보면
select 크루.*, 할일.* from 크루 join fetch 할일 이 된다.
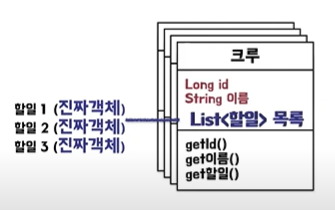
위 쿼리문을 실행시키면 아까와 달리 실제 객체를 가지고 오게 된다.
아까처럼 크루들의 할 일을 조회해보면
for (크루 크루: 크루들) {
크루1.목록(진짜).getSize();
}처럼 진짜 객체들을 꺼내게 된다.
즉, 최초에 관련된 데이터를 한꺼번에 가져와서 객체화 해줬기 때문에
DB를 거치지 않고 데이터를 꺼내서 반환한다.
-> 1개의 쿼리로 문제 해결!
해당 부분을 쿼리로 살펴보면 아래와 같다.

이전에는 크루만 조회했는데 크루와 할 일 목록 모두 전부 조회하게 된다. 추가 쿼리 없이 객체에서 데이터 꺼내쓰기!
📓 지연로딩 쓰지 말고 즉시로딩 쓰면 되지 않나요?
No!! 즉시(Eager) 로딩을 써도 N+1 문제가 발생한다.
JPQL이 즉시 로딩 쿼리를 만들 때를 한번 가정해보자.
크루 entity에서 findAll sql 만들어본다고 가정한다면,
처음 쿼리를 만들 때 크루에 연관관계가 있는 엔티티는 신경 안 쓰고 조회 대상이 되는 Entity 기준으로만 쿼리를 만든다.
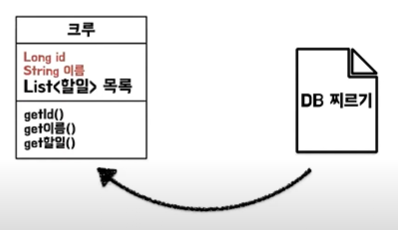
위와 같이 크루만! 가져오게 된다. (연관관계 있는 엔티티만 관심 있음)
그 후, 어? 연관된 엔티티가 있네. 글로벌 패치 전략이 뭐였지?라고 이제서야 관심 갖게 된다.
@OneToMany(mappedBy = "크루", fetch = FetchType.EAGER)이 실행되면서 바로 조회해서 갖고 오게 되고
이때 즉시! N번의 추가 쿼리가 발생하게 된다..

즉, 위와 같은 쿼리문이 발생된다.
결론적으로,
즉시로딩을 최대한 사용하지 말고, 지연로딩 + fetch join 조합을 쓰면 된다.
📓 그렇다고 fetch join이 만능인 건 아니다
대표적인 fetch join 문제 상황으로는
OneToMany 관계에서 페이징 처리할 때이다.
- DB에서 1:N 관계 표현하는 상황을 가정해보자.
크루는 한명이고 크루의 할 일은 여러 개이다. 크루 목록 중에 5명만 가져와달라고 요청한다면?
대부분의 사람들은 DB에서 Limit을 걸어서 데이터를 추출할 것이다. 하지만 이렇게 한다면 문제가 발생한다!
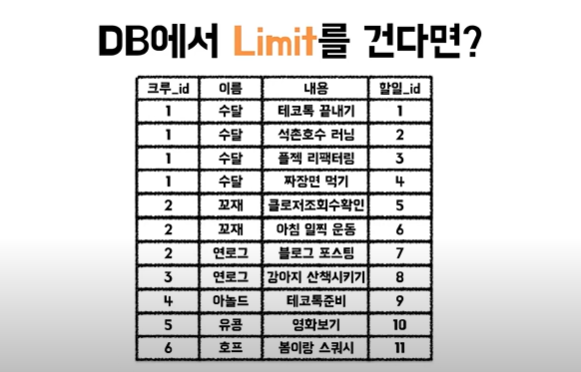
위 데이터에서 offset 1 ~ limit 5로 추출하게 된다면
기대했던 5명의 데이터를 추출하기보다는

위와 같은 데이터가 추출될 것이다. 심지어 꼬재는 할 일이 누락되기도 했다.
=> 이를 해결하려면 일단 데이터를 다 주고 인메모리에서 내가 원하는 대로 가공해야한다. 즉 데이터 전체를 full scan해서 가져오고, 메모리에서 페이지 처리를 해야한다는 뜻이다.
하지만!! 위와 같이 하면 아래와 같은 오류 문구가 뜬다.
firstResult/maxResults specified with collection fetch; applying in memory!
이유는 데이터가 백만 건이라면 백만 건 데이터를 메모리에서 관리하게 되기 때문에 메모리 부하가 일어나기 때문이다.
위 오류는 ManyToOne을 사용하거나 @BatchSize()를 활용해서 해결하면 된다.
🗯️ 다른 상황에서 n+1문제가 일어날 땐 어떻게 해야하는지, @EntityGraph 사용하면 어떻게 n+1 문제를 해결할 수 있는지, 마지막에 메모리 부하가 일어났을 때는 어떻게 해결하면 좋을 지 추가로 공부하면 좋을 듯하다!
