![]()
1. LightGBM 개요
Tree 자료 구조를 기초로 한 gradient boosting framework이다. Leaf-wise (Best-first) Tree Growth 구조를 택하기 때문에 Level-wise Tree Growth 구조인 XGBoost보다 속도가 빠르다. 단, 10,000건 이하의 데이터로 학습할 경우 Overgitting 가능성이 높으므로 10,000건 이상의 데이터에서 사용할 것을 권장한다.
■ Tree data structure
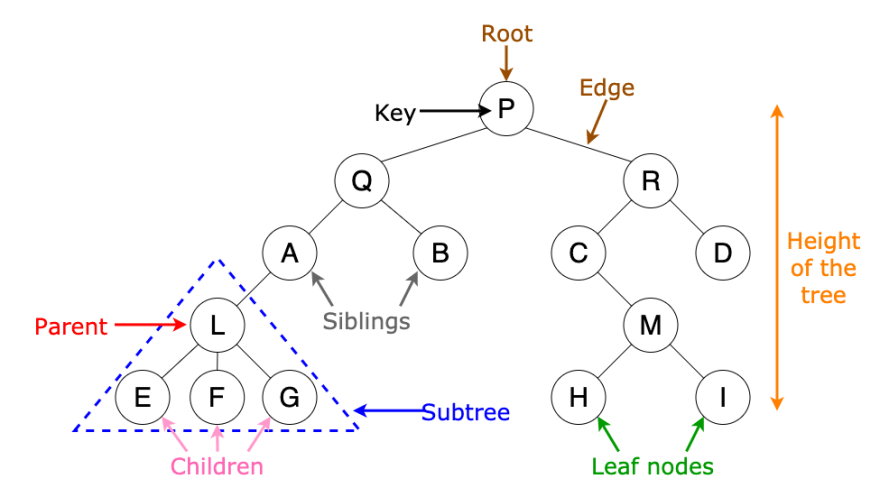
■ Leaf-wise | Level-wise Tree Growth
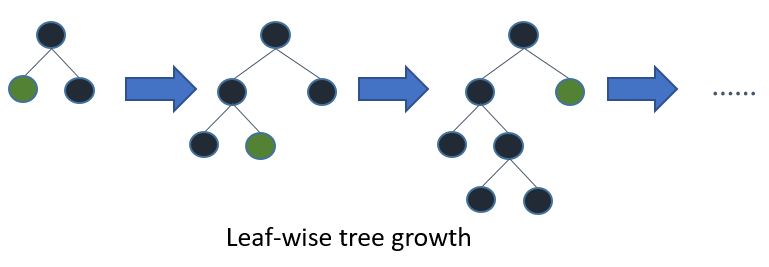
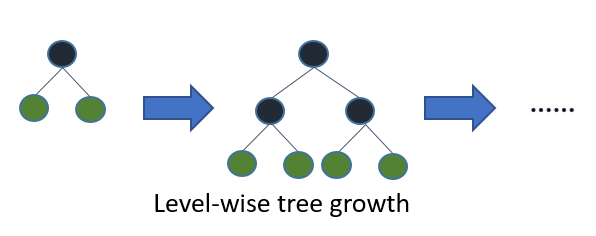
Level(균등, 수평) wise(분할) 방식은 tree를 수평적으로 키운다. 따라서 tree를 균형적으로 만들기 위한 추가 연산이 필요하기 때문에 상대적으로 속도가 느리다.
반면 Leaf wise 방식은 delta loss가 가장 큰 값을 선택하여 다시 subtree로 분할하는 것이다. 즉 성능을 가장 낮추는(loss가 가장 큰) node를 선택해 loss를 줄여나가는 방식이다. 따라서 상대적으로 속도가 빠르고 예측 오류를 최소화할 수 있다.
2. 주요 Parameters
2.1. Core Parameters
■ objective
목적(손실)함수로 이 함수의 결과값이 최소화되는 방향으로 학습한다.
회귀인지, 분류인지 등에 따라 옵션을 다르게 선택해야 한다.
default="regression"- regression application options
regression: L2 loss를 의미한다.- aliases:
regression_l2, l2, mean_squared_error, mse, l2_root, root_mean_squared_error, rmse
- aliases:
regression_l1: L1 loss를 의미한다.- aliases:
l1, mean_absolute_error, mae
- aliases:
mape: mean_absolute_percentage_error- 기타:
huber,fair,poisson,quantile,gamma,tweedie
- binary classification application options
binary
- multi-class classification application
multiclass: softmax objective functionmulticlassova
- cross-entropy application options
cross_entropycross_entropy_lambda
- ranking application options
lambdarankrank_xendcg
■ boosting_type(boosting)
default="gbdt"- options
- gbdt: traditional Gradient Boosting Decision Tree
- rf: Random Forest
- dart: Dropouts meet Multiple Additive Regression Trees
- goss: Gradient-based One-Side Sampling
■ n_estimators(num_iterations)
boosting을 반복할 횟수를 의미한다. 즉 손실함수의 가중치를 몇 번이나 조정할 것인지를 뜻한다.
따라서 값이 클수록 정확도가 증가하나, overfitting의 가능성 또한 증가한다.
일반적으로 n_estimators를 크게하고 모델을 fit할 때 early_stopping_rounds를 설정하여 early_stopping_rounds 횟수보다 개선되지 않으면 학습을 종료한다.
default=100
■ metric
eval_set을 평가할 지표이다.
기본값은 비어있으며, objective에서 정의한 것을 사용한다.
default=""- options:
l1,l2,rmse,mape,auc...
2.2. Overfitting(과적합) 조정 parameters
■ learning_rate
boosting을 반복할 때 업데이트되는 학습률 값을 의미한다.
일반적으로 하이퍼 파라미터 튜닝 시에는 0.1~0.3를 사용하여 빠른 속도로 최적의 파라미터를 찾아내며, 최종 모형 학습 시에는 0.05 이하로 설정하여 성능 향상에 중점을 둔다. 그러나, learning_rate에 따라 하이퍼 파라미터가 달라지게 되므로 최종 learning_rate와 차이가 크면 최적의 성능을 이끌어낼 수 없다.
learning_rate는 작게, n_estimators는 크게 하는 것이 바람직하다.
default=0.1
■ max_depth
tree의 최대 깊이다. 값을 줄이면 overfitting를 해결할 수 있다.
기본값은 -1로 깊이의 제한이 없다.
최대 개의 leaf node가 생길 수 있다.
default=-1
■ num_leaves
tree의 최대 leaf node의 개수이다.
공식 문서에 따르면 max_depth가 7일 경우 num_leaves을 127로 설정하면 overfitting 가능성이 상승하므로, 70~80의 값을 설정하는게 적절하다고 언급한다.
1 < num_leaves <= 131072
■ subsample(bagging_fraction)
boosting 단계마다 데이터를 랜덤으로 선택하는 비율이다. 즉 매 번 subsample 비율만큼 데이터를 랜덤으로 선택해서 학습을 진행한다.
값이 작으면 속도를 향상할 수 있고, overfitting을 방지할 수 있다.
default=10.0 < subsample <= 1.0
■ colsample_bytree(feature_fraction)
boosting 단계마다 feature를 선택하는 비율이다. feature가 많거나, 소수의 feature에 의존적일 때 사용하여 overfitting을 해결할 수 있다.
_bytree: 각 boosting 단계마다 사용할 Feature의 비율
_bynode: 각 node의 depth 마다 사용할 Feature의 비율
colsample_bytree(feature_fraction)와 colsample_bynode(feature_fraction_bynode)를 같이 사용하면 각 노드를 분할할 때 사용하는 feature의 비율은colsample_bytree * colsample_bynode이다.
default=10.0 < colsample_bytree <= 1.0
■ min_child_samples(min_data_in_leaf)
leaf node에 포함되어야 할 최소한의 데이터 개수를 의미한다. 따라서 분할을 조정하여 overfitting을 제어한다.
default=20
■ min_child_weight(min_sum_hessian_in_leaf)
leaf node의 헤시안의 최소값을 의미한다. min_child_samples과 다른 의미다. 단, 차이를 이해하기에는 공학적 지식이 필요하다. min_child_samples와 min_child_weight 모두 leaf 노드의 분할 조건이며 단지 적용 방식이 다르다고 생각하면 될 것 같다. overfitting을 방지하는데 사용한다는 것만 알아두도록 하자.
아래는 공식 문서에서 설명한 내용이다.
Minimum sum of the Hessian (second derivative of the objective function evaluated for each observation) for observations in a leaf. For some regression objectives, this is just the minimum number of records that have to fall into each node. For classification objectives, it represents a sum over a distribution of probabilities. See this Stack Overflow answer for a good description of how to reason about values of this parameter.
헤세 행렬(Hessian Matrix)의 기하학적 의미 by 공돌이의 수학정리노트
default=0.001
■ reg_alpha(lambda_l1)
L1 Regularization parameter로 불필요한 가중치를 0으로 만든다.
feature의 개수가 많을 경우 적용을 검토하나, 최종 파라미터를 구한 뒤 값을 바꿔가며 최적의 값을 찾는 것이 바람직하다.
클수록 overfitting의 방지하나, 너무 크면 underfitting이 발생한다.
default=0
■ reg_lambda(lambda_l2)
L2 Regularization parameter로 불필요한 가중치를 0으로 만든다.
feature의 개수가 많을 경우 적용을 검토하나, 최종 파라미터를 구한 뒤 값을 바꿔가며 최적의 값을 찾는 것이 바람직하다.
클수록 overfitting의 방지하나, 너무 크면 underfitting이 발생한다.
default=0
참고자료
XGBoost와 LightGBM 하이퍼파라미터 튜닝 가이드 by psysta
Light GBM 설명 및 사용법 by Gorio Learning
lightGBM / XGBoost 파라미터 설명 by Go Lab
GRADIENT BOOSTED TREES XGBOOST / LIGHTGBM by Laurae++
