BigData & NoSQL
Scaling
- Vertical Scaling
- Puts more memory and more powerful CPU as well as Disks
- HP Superdome can have 32 Intel Xeon and 48TB RAM
- Horizontal Scaling (Sharding)
Horizontal 스케일링(aka Scaling out)은 새로운 수요에 대응하기 위해 인프라에 노드나 머신을 추가하는 것을 말합니다. 서버에서 애플리케이션을 호스팅하고 있는데 더 이상 트래픽을 처리할 수 있는 용량이나 기능이 없다는 것을 알게 되면 서버를 추가하는 것이 해결책이 될 수 있습니다.
Vertical 스케일링(aka Scaling up)은 수요를 충족시키기 위해 시스템에 추가적인 자원을 추가하는 것을 말합니다. 이것이 수평 스케일링과 어떻게 다를까요?

https://www.cloudzero.com/blog/horizontal-vs-vertical-scaling/
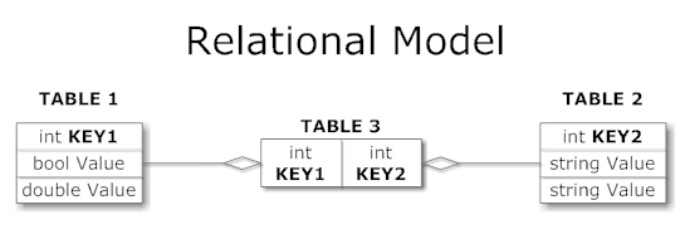
NoSQL vs RDBMS
- 데이터 저장소에 대해서 크게 두 가지 option을 가짐
- 전통의 RDBMS
- 데이터 무결성 지원 (Transaction에 대한 ACID)
- 데이터 중복성 없음
- Strict schema and Join
- No Horizontal Scaling
- Complex Query -> YES
- NoSQL
- Schemaless: no fixed / predefined schema (format or format can evolve)
- Horizontal Scaling -> YES
- Possible 데이터 중복
- 확장이 필요한 경우 (Scalability)
- 전통의 RDBMS
파란색 장점, 빨간색 단점?
RDBMS는 데이터 구조가 명확하며 변경 될 여지가 없으며 명확한 스키마가 중요한 경우 사용하는 것이 좋습니다. 또한 중복된 데이터가 없어(데이터 무결성) 변경이 용이하기 때문에 관계를 맺고 있는 데이터가 자주 변경이 이루어지는 시스템에 적합합니다.
NoSQL은 정확한 데이터 구조를 알 수 없고 데이터가 변경/확장이 될 수 있는 경우에 사용하는 것이 좋습니다. 또한 단점에서도 명확하듯이 데이터 중복이 발생할 수 있으며 중복된 데이터가 변경될 시에는 모든 컬렉션에서 수정을 해야 합니다. 이러한 특징들을 기반으로 Update가 많이 이루어지지 않는 시스템이 좋으며 또한 Scale-out이 가능하다는 장점을 활용해 막대한 데이터를 저장해야 해서 Database를 Scale-Out를 해야 되는 시스템에 적합합니다.
https://khj93.tistory.com/entry/Database-RDBMS%EC%99%80-NOSQL-%EC%B0%A8%EC%9D%B4%EC%A0%90
Local DBMS vs. Cloud database services
- MySQL, Oracle(RAC: real application clusters), CUBRID, PostgreSQL, MariaDB, Microsoft SQL Server, Tibero(Tmax)
- However, there are services on Cloud (In many services, it is transparent to the client in many services whether it uses a specific DB).
- In-memory DB like Redis
- MongoDB Atlas (Document)
- HBase on AWS, Google Cloud, Azure (Column)
- Cassandra on AWS, Google Cloud, Azure
- Elastic Search
- Firebase (Serverless Realtime Databases)
CAP vs. ACID
- ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties of database transactions (Wikipedia)
Atomicity : 분해할 수 없이 원자적이고
Consistency : 일관된 데이터를 유지하고
Isolation : 고립되어 다른 연산이 끼어들 수 없고
Durability : 데이터가 영원히 반영된 상태로 있는
ACID 트랜잭션은 관계형 데이터베이스에서 여러 개의 SQL연산을 하나의 단일 트랜잭션으로 처리하는 것을 의미한다. 여러개의 테이블에 대해서 읽고 쓰고 하는 행동을 하나의 연산처럼 사용하는 것이다.
Atomicity은 여러개의 SQL 연산이 하나의 연산처럼 동작해야 한다. 어느것 하나라도 실패했다면 모든 연산이 실행되지 않아야 한다.
Consistency은 같은 시점에 접속하는 클라이언트들은 항상 같은 데이터를 보고 있어야 한다는 것
Isolation은 트랜잭션이 수행되는 동안에 다른 연산이 끼어들지 못한다는 것
Durability은 트랜잭션이 완료된 이후의 데이터는 업데이트된 상태로 그대로 영원히 반영되어 있다 는 뜻
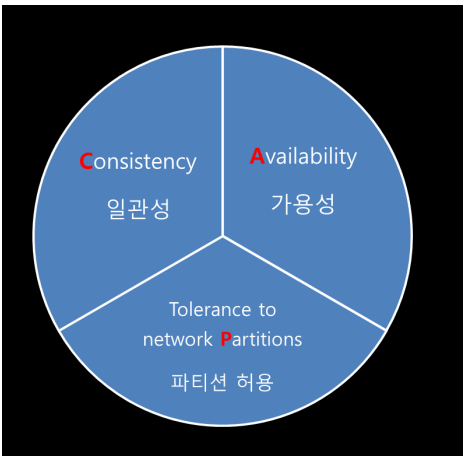
- Eric Brewer proposed CAP in PODC 2000 (For distributed DBMS)
- “Towards Robust Distributed Systems”
- It is impossible for a distributed data store to simultaneously provide more than two out of the three guarantees
Consistency : 데이터를 저장하는 장비가 1대든 100대든 모든 장비에는 동일한 데이터가 저장되어 있어야 한다는 것. ACID 트랜잭션에서 의미하는 것이기도 하다. 어떤 데이터베이스의 속성에 C가 있다면 트랜잭션 기능 혹은 그와 비슷한 매커니즘이 존재한다는 뜻
Availability: 죽지 않은 상태의 모든 서버는 클라이언트에게 항상 정상 처리 응답을 보내주어야 한다는 뜻. 현재 시스템에 문제가 있어서 읽거나 쓸수 없다고 보내면 가용성이 보장되지 않는 것이다.
Partitions : 클러스터가 여러대 동작하고 있을 때 해당 클러스터 사이에 접속이 단절되어 서로 통신을 할 수 없는 상황에서도 시스템이 잘 동작해야한다는 뜻
동시에 3가지 적용하는 것은 매우 어렵다.
상대적인 trade-off를 예상할 수 밖에 없다.
관계형 데이터베이스가 동시에 다량의 서버를 운용하는 클러스터링에 적합하지 않는 이유?
관계형 데이터베이스는 CA 시스템이다. 일관성과 가용성은 보장하되 분단 허용성은 보장하지 않는다. 그 이유는 10대의 서버중에서 5번 서버가 접속이 끊겼다. CA라서 P는 지원하지 않으니까 전체 시스템이 잘 동작하지 않는건 이해한다.
근데 CA를 지원하려면 연결이 끊어진 5번 서버 떄문에 나머지 서버를 중단시켜야 CA를 만족하게 된다. 근데 비효율적이고 거의 불가능하다.
결국 관계형 데이터베이스는 클러스터링으로 만들기가 어렵다.
해결책은?
간단하다 CA를 버리면 된다. 버린다는게 극단적으로 false라는 개념이 아닌 100%지원이라면 60%지원으로 변경한다는 의미다. NoSQL은 대부분 CA가 아닌 CP나 AP시스템이다. C가 들어간다면 하나의 쓰기 작업에 100대가 있다면 100대 모두 lock이 걸리게 된다. 응답속도가 매우 안좋음.
https://namoeye.tistory.com/entry/ACID-%EA%B7%B8%EB%A6%AC%EA%B3%A0-CAP%EA%B0%9C%EB%85%90
Visual Guide to NoSQL Systems (trade-offs)
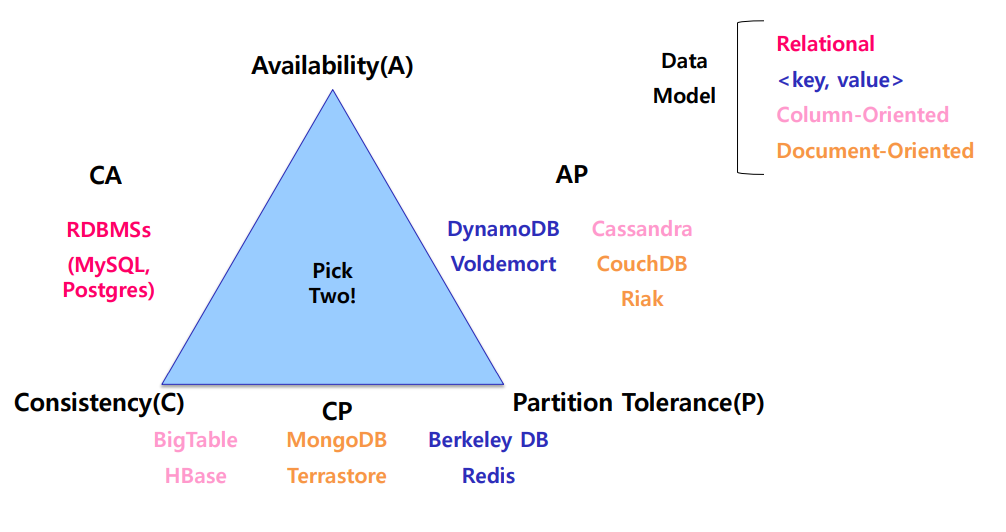
CA systems
먼저 일관성과 가용성을 최적화하는 시스템이 있습니다. 이는 분할 허용성을 희생함으로써 달성됩니다.
다시 말해, 우리는 비교적 적은 다운타임(시스템이 작동하지 않는 시간)으로 높은 일관성을 달성할 수 있지만, 네트워크 문제로 전체 시스템이 다운되거나 적어도 개별 트랜잭션 실패의 위험이 있습니다.
우리가 방금 언급한 것처럼 CA 시스템은 일반적으로 전통적인 관계형 데이터베이스인 SQL, Postgres 또는 Oracle을 기반으로 합니다.
CP systems
다음으로, 일관성과 분할 허용성을 우선시하는 시스템이 있습니다. 이는 가용성을 희생함으로써 달성됩니다.
따라서 우리는 일관성을 유지하고 네트워크 문제에 대처할 수 있지만, 특정 순간에는 일부 데이터가 사용할 수 없어질 가능성이 있습니다.
가장 흔한 CP 시스템의 예는 MongoDB입니다. MongoDB는 인기 있는 ACID(원자성, 일관성, 고립성, 지속성)을 준수하는 NoSQL 데이터베이스입니다.
AP systems
마지막으로, 가용성과 분할 허용성을 중시하는 시스템이 있습니다. 다시 말해, 데이터는 항상 사용 가능하며 장애가 발생해도 계속해서 이용할 수 있습니다. 그러나 이를 달성하기 위해서는 검색된 데이터가 부정확하거나 오래된 상태이거나 일관성이 없을 가능성이 있습니다.
가장 일반적인 AP 시스템의 예로는 CouchDB와 Cassandra가 있습니다.
https://budibase.com/blog/data/cap-vs-acid/
Documents (MongoDB)
-
In MongoDB, databases hold collections of documents.
- Collections are analogous to tables in relational databases
- MongoDB stores data records as BSON documents.
- BSON is a binary representation of JSON documents.
-
The field name
- _id is reserved for use as a primary key; its value must be unique in the collection, is immutable,
- _id: ObjectId("5099803df3f4948bd2f98391")
- Field names cannot contain the null character
- _id is reserved for use as a primary key; its value must be unique in the collection, is immutable,


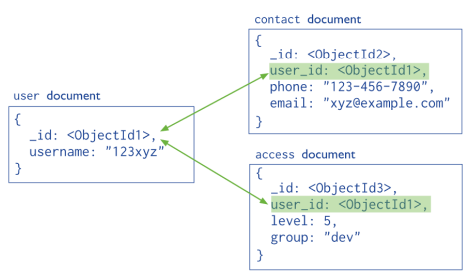
- Document Structure
- The value of a field can be any of the BSON data types, including other documents, arrays, and arrays of documents.
var mydoc = {
_id: ObjectId("5099803df3f4948bd2f98391"), // ObjectId: primary key
name: { first: "Alan", last: "Turing" }, // embedded document
birth: new Date('Jun 23, 1912'), // Date type
death: new Date('Jun 07, 1954'),
contribs: [ "Turing machine", "Turing test", "Turingery" ], // string array
views : NumberLong(1250000) // NumberLong type
}


MongoDB
Installation and Connect
- Installing: https://www.mongodb.org/docs/manual/installation/
- mongod: the primary daemon process for the MongoDB system (MongoDB daemon)
- mongosh: the command-line shell that connects to a specific mongd instance.
- Compass: the graphical view of MongoDB
- Connect (JavaScript)
import {MongoClient} from 'mongodb';
export async function connect() {
const url = "mongodb://localhost:27017/my_database";
let db;
try {
db = await MongoClient.connect(url);
} catch (err) {
// Error Handling
}
return db;
}Databases and Collections
-
Select a DB
- use
<db>// If there is none, create it
- use
-
Use: create DATABASE

-
Create a DB (myNewDB) and the collection (myCollection)
- If a collection does not exist, MongoDB creates the collection when you first store data for that collection

Insert a document
export async function insertDocuments
(db) {
// Get the documents collection
const collection = db.collection('restaurants')
// Insert some documents
const result = await collection.insertMany([ {
name: 'Sun Bakery Trattoria',
stars: 4,
categories: [
'Pizza', 'Pasta', 'Italian', 'Coffee', 'Sandwiches'
]
}, {
name: 'Blue Bagels Grill',
stars: 3,
categories: [
'Bagels', 'Cookies', 'Sandwiches'
]
}
])
return result
}CRUD
- Create: insert one document
db.<collection>.insertOne({<field>:<value>})db.<collection>.insertMany()
- Read: get all documents
db.<collection>.find(query, projection)- find() is the same as select * from
<table>
- find() is the same as select * from
- Update: modify existing document in a collection
db.<collection>.updateOne(filter, update, options)db.<collection>.updateMany(filter, update, options)db.<collection>.replaceOne(filter, update, options)
- Delete: remove documents from a collection
db.<collection>.deleteOne()db.<collection>.deleteMany()
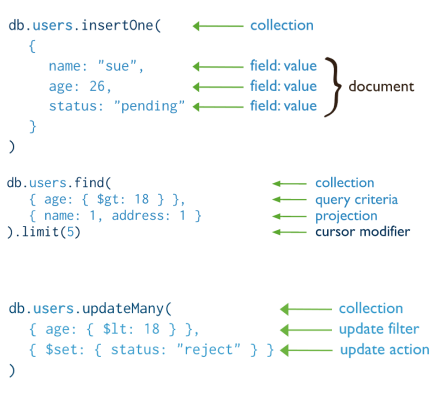
connect, find 할때 await가 기본적으로 붙는다는 것
query document
(<field1>: <value1>, <field2>: { <operator>: <value> },)
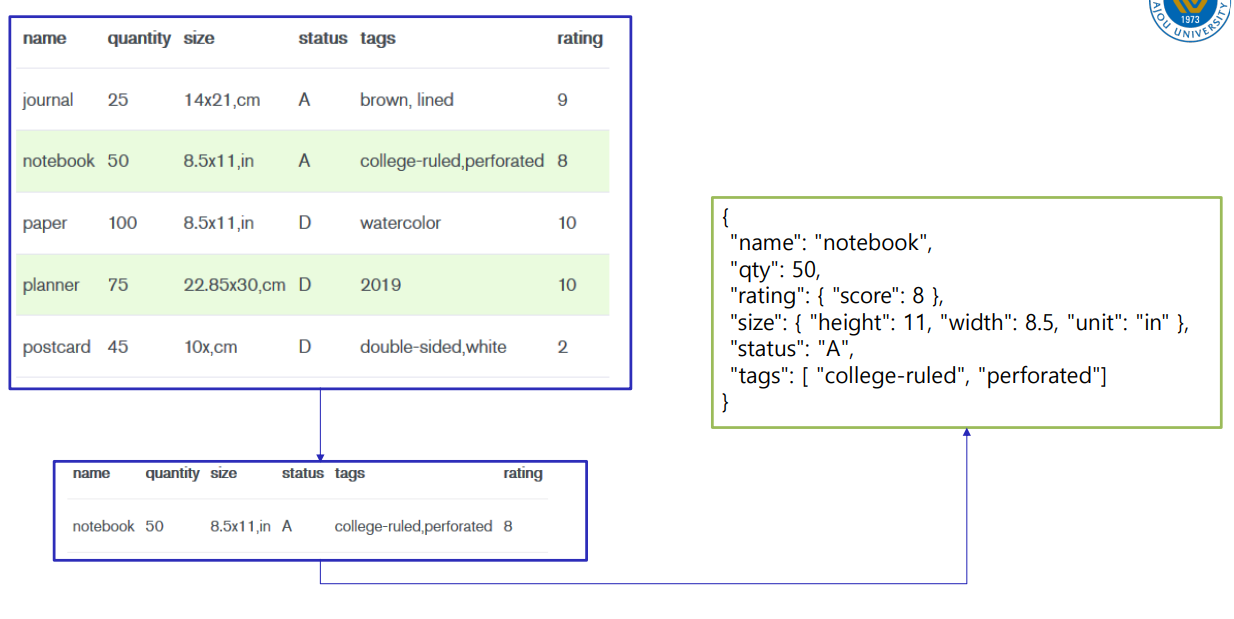
db.inventory.insertMany([
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "A" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" }
]);- db.inventory.find({})
->SELECT * FROM inventory - db.inventory.find( { status: { $in: [ "A", "D" ] } } ) // equality check
->SELECT * FROM inventory WHERE status in ("A", "D") - db.inventory.find( { status: "A", qty: { $lt: 30 } } )
->SELECT * FROM inventory WHERE status = "A" AND qty < 30 - db.inventory.find( { $or: [ { status: "A" }, { qty: { $lt: 30 } } ] } ) // logical
->SELECT * FROM inventory WHERE status = "A" OR qty < 30
설마 쿼리문에서 js 코드로 바꾸라는거 나오지는 않겠지만 알고는 있기
Indexing
index는 도큐먼트를 쿼리해오기 위한 작업량을 줄임
- default _id index: a unique index on the _id field during the creation of a collection
- What does database normally do when we query?
- MongoDB must scan every document
- Inefficient due to large volumes of data <- may need to create index in memory
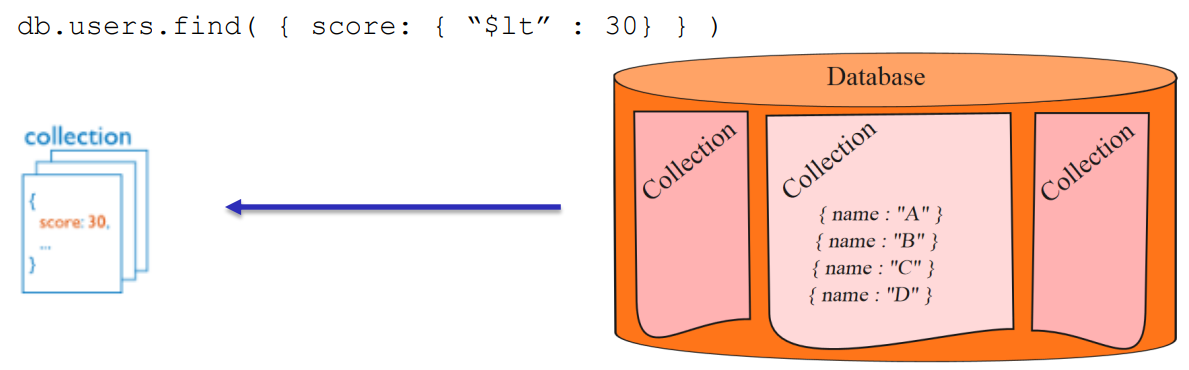
모든 MongoDB의 컬렉션은 기본적으로 _id 필드에 인덱스가 존재
mongodb는 _id 를 기반으로 기본 인덱스 생성
Document의 필드들에 index 를 걸면, 데이터의 설정한 키 값을 가지고 document들을 가리키는 포인터 값으로 이뤄진 B-Tree 데이터 구조를 만듬
B-Tree : Balanced Binary search Tree, Binary Search (이진 검색) 으로 쿼리 속도를 검색 속도 개선
- An index is a map of the collection to make it easier to retrieve your documents
(문서 ID 에 대한 인덱스를 사용하여 O(1) 시간 안에 문서를 조회할 수 있다) - B-Tree for indexes to store a small portion of the collection’s data set (대부분의 document 모델 NoSQL 은 B 트리 인덱스를 사용하여 2 차 인덱스를 생성한다)
collection의 데이터 집합의 일부를 저장하는 인덱스에 대한 B-트리- Like RDBMS
- +) To improve performance for frequent queries by building a lookup index
- -) index building efforts and memory usage
Index 생성하기
db.users.createIndex( { score: -1} )
- 1 for ascending index (오름차순)
- -1 for descending index (내림차순)
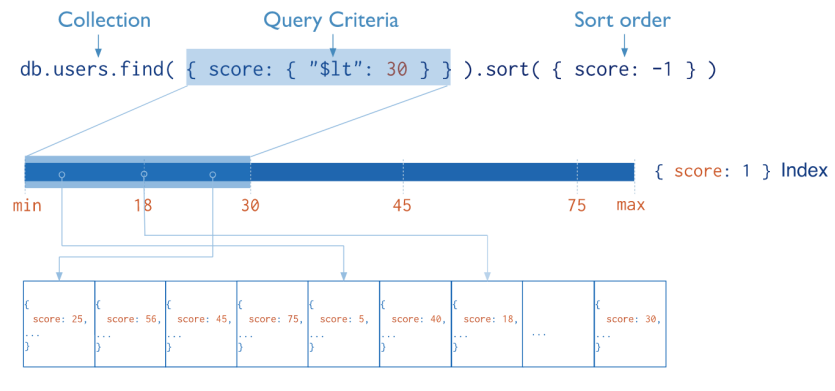
https://eunsour.tistory.com/72
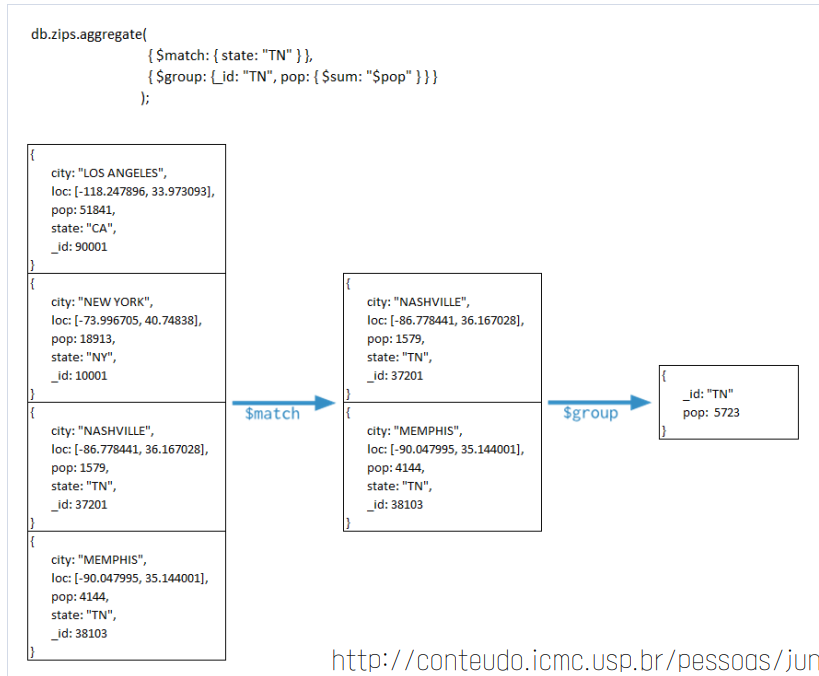
Aggregation
- Aggregation operations process multiple documents and return computed results.
- Aggregation framework is similar to MapReduce
- Based on the concept of data processing pipelines
- Provides
- filters that operate like queries
- Document transformations that modify the form of the output document
- Provides tools for:
- Grouping and sorting by field
- Aggregating the contents of arrays, including arrays of documents
Embedding
- 1:N relationship via Embedding
book = {
title: "MongoDB: The Definitive Guide",
authors: [ "Kristina Chodorow", "Mike Dirolf" ]
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher: {
name: "O’Reilly Media",
founded: "1980",
location: "CA"
}
}Linking
- 1:N relationship via Linking (referencing)
book = {
title: "MongoDB: The Definitive Guide",
authors: [ "Kristina Chodorow", "Mike Dirolf" ]
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "8798486734"
}publisher: {
_id: "8798486734“,
name: "O’Reilly Media",
founded: "1980",
location: "CA"
}Many to many relationship
- Can put relation in either one of the documents (embedding in one of the documents)
- Unavoidable redundancy
- Possible (probable) inconsistency
- It is also possible via linking
- But, in this case, random access is necessary–and joining is necessary in case one needs all the relationships
랜덤한 접근이 필요하며, 모든 관계가 필요한 경우 join이 필요합니다

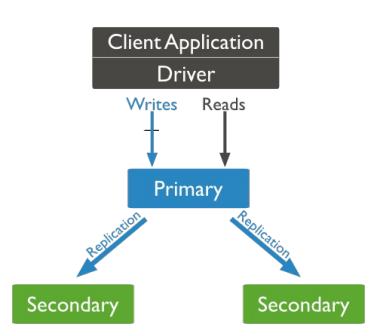
Replication (overview)
- A replica set in MongoDB is a group of mongod processes that maintain the same data set.
- Replication is the process of synchronizing data across multiple servers.
- Replication provides redundancy and increases data availability with multiple copies of data on different database servers.
- A secondary apply the primary’s oplog asynchronously.
주 데이터베이스의 oplog를 비동기적으로 보조 데이터베이스에 적용한다.
이는 주 데이터베이스에서 발생한 변경 사항들을 로그로 남겨두고, 이 로그를 보조 데이터베이스로 전달하여 보조 데이터베이스도 주 데이터베이스와 동일한 상태를 유지할 수 있도록 하는 메커니즘입니다
- A secondary apply the primary’s oplog asynchronously.
- Replication protects a database from the loss of a single server.
- A eligible(자격있는) secondary servers when the primary is not available
- Automatic Failover(자동 장애조치)
Automatic Failover는 주(primary) 노드가 다운되거나 사용할 수 없는 상태로 전환될 때 자동으로 대체(primary로 승격된) 노드를 선출하여 시스템의 가용성을 유지하는 기능을 말합니다.
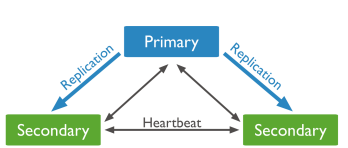
HeartBeat는 두 서버 사이에 Fail-Over를 가능하게 하는 모듈로서 서버 사이의 Fail-Over 기능을 제공하고자 할 때 사용한다.
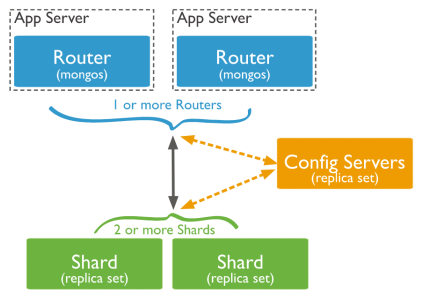
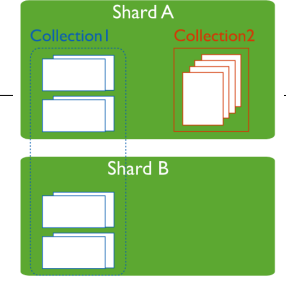
Sharding (overview)
같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법을 의미합니다.
- Sharding solves the problem with horizontal scaling.
- Partition data based on either ranges (Shard key defines range of data) or hash
- MongoDB automatically splits & migrates chunks
- Sharded Cluster consists of
- Shard: contains a subset of the sharded data, can be replicated
Mongodb는 Shard 여러개를 두고, 분산 처리를 할수있는 기능을 지원합니다. - mongos: acts as a query router
Mongodb는 직접 특정 Shard에 접근할 수 없게 되어있다. Query Router에 명령을 하고, Query Router가 Shard에 접근하는 방식(Config Server정보기반으로 data chunk 위치를 찾아가는 것도 이때 수행됨)으로 설계되어 있다 - Config servers: store metadata(shard의 정보) and configuration settings for the cluster
어떤 Shard가 어떤 데이터(data chunk)를 가지고 있는지, data chunk들을 어떻게 분산해서 저장하며 관리할지에 대한 정보를 가지고 있음.
- Shard: contains a subset of the sharded data, can be replicated