Preface
To develop Data-Intensive Applications
- We need both the principles (theory from the textbook) and the practicalities of data systems.
- We need to figure out which tools and which approaches are the most appropriate for the task at hand (architecting / designing).
- Bigger problem lies in: the amount of data, the complexity of data, and the speed where it is changing
This book is for
- who develops applications of server/backend for storing or processing data and/or for whom your applications use the Internet (e.g., web applications, mobile apps, or internetconnected sensors),
- Prerequisite
- Should have some experience building web-based applications or network services,
- Should be familiar with relational databases and SQL.
- A general understanding of common network protocols like TCP and HTTP is helpful.
(Ch. 1) Reliable, Scalable, and Maintainable Application
Recent trend: Data-Intensive Applications
- Recently, many applications have been data-intensive where the problem lies in the amount of data, the complexity of data, and the speed at which it is changing
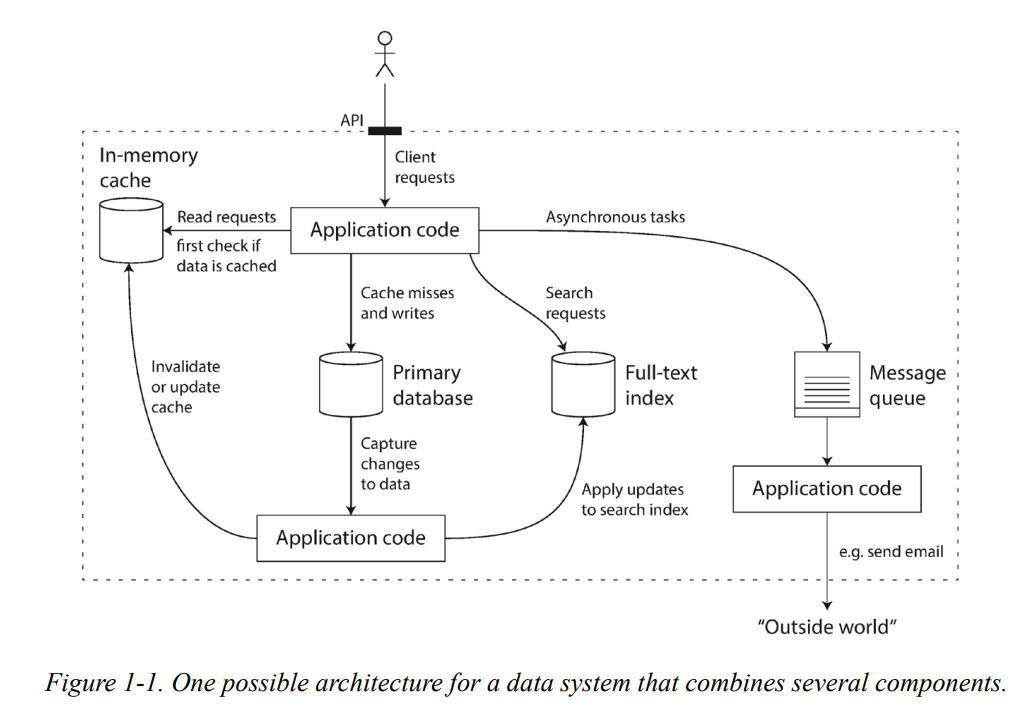
- Standard Building Blocks of Data-Intensive Applications
데이터 집약적 애플리케이션의 표준 구성 요소- Store data so that they, or another application, can find it again later (databases)
나중에 그들이나 다른 애플리케이션이 데이터를 다시 찾을 수 있게 저장 - Remember the result of an expensive operation, to speed up reads (caches)
읽기 속도를 높이기 위해 비용이 많이 드는 연산의 결과를 기억 - Allow users to search data by keyword or filter it in various ways (search indexes)
- Send a message to another process, to be handled asynchronously (messaging/stream processing) <- requires a messaging system such as Kafka
- Periodically crunch(처리하다) a large amount of accumulated data (batch processing)
- Store data so that they, or another application, can find it again later (databases)
- However, the reality is not simple (e.g., characteristics of DBMS are all different & different applications have different requirements)
Messaging System and Kafka
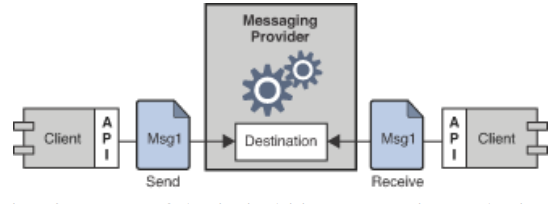
Elements of Message Oriented Middleware system: clients using APIs to exchange messages via a messaging provider.
메시지 공급자를 통해 메시지를 교환하기 위해 API를 사용하는 클라이언트.
Apache Kafka is a distributed event store and stream-processing platform that aims to provide a unified, highthroughput, low-latency platform for handling real-time data feeds.
Apache Kafka는 분산 이벤트 저장소 및 스트림 처리 플랫폼으로, 실시간 데이터 피드를 처리하는 일관된 고처리량, 저지연 플랫폼을 제공하려는 목표를 가지고 있습니다
Thinking about Data Systems
- The boundaries between the categories are becoming blurred.
- Some data stores are also used as message queues (Redis), and there are message queues with database-like durability guarantees (Apache Kafka).
일부 데이터 저장소는 메시지 큐(Redis)로도 사용되며, 데이터베이스와 동일한 내구성이 보장되는 메시지 큐(Apache Kafka)도 있습니다. - The work is broken down into tasks that can be performed efficiently on a single tool.
데이터 저장소와 메시지 큐와 같은 서로 다른 카테고리의 기술 사이에서 경계가 흐려지고 있다
- Some data stores are also used as message queues (Redis), and there are message queues with database-like durability guarantees (Apache Kafka).
- Many applications have requirements that a single tool can no longer meet. Instead, the work is broken down into tasks that can be performed efficiently on a single tool and those different tools are stitched together using application code.
많은 애플리케이션들은 단일 도구로는 더 이상 충족시킬 수 없는 요구사항들을 가지고 있습니다. 대신, 작업은 단일 도구에서 효율적으로 수행될 수 있는 작업들로 분해되며, 그 다양한 도구들은 애플리케이션 코드를 사용하여 연결됩니다."- It is normally the application code’s responsibility to keep caches and indexes in sync with the main database.
캐시 및 인덱스를 주 데이터베이스와 동기화하는 것은 일반적으로 응용 프로그램 코드의 책임입니다.- API usually hides those implementation details from clients. => created a new, special-purpose data system from smaller, general-purpose components.
- It is normally the application code’s responsibility to keep caches and indexes in sync with the main database.
Tricky questions arose when you design a system of a service
- How do you ensure that the data remains correct and complete, even when things go wrong internally?
- How do you provide consistently good performance to clients, even when parts of your system are degraded?
- How do you scale to handle an increase in load?
- What does a good API for the service look like?
There are many factors that may influence the design of a data system
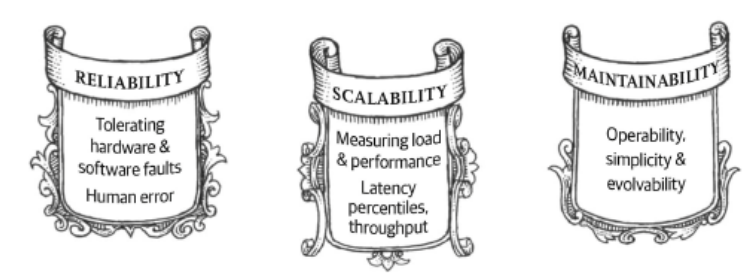
Reliability
- Definition of reliable systems: The system should continue to work correctly (performing the correct function at the desired level of performance) even in the face of adversity (hardware or software faults, and even human error)
Reliability: continue to work correctly, even when things go wrong.
- Faults: things go wrong
- Fault-tolerant/Resilient: anticipating faults and coping with them
내결함성/내구성: 고장을 예측하고 대처 - Failure: when the system as a whole stops providing the required service
- Fault-tolerant/Resilient: anticipating faults and coping with them
- Design a system whose possibility of fault is zero is impossible
- So, the best design the fault-tolerant mechanisms that prevent faults from causing failures
가장 좋은 설계는 결함이 실패를 일으키는 것을 막는 내결함성 메커니즘을 설계하는 것입니다
- So, the best design the fault-tolerant mechanisms that prevent faults from causing failures
- E.g., the Netflix Chaos Monkey
- by randomly killing individual processes (containers) without warning.
- i.e., Many critical bugs are actually due to poor error handling
Netflix의 Chaos Monkey는 이러한 내결함성을 테스트하는 도구의 한 예입니다. Chaos Monkey는 경고 없이 임의로 서버나 서비스를 중단시킴으로써, 시스템이 결함에 어떻게 대응하는지를 확인합니다. 이를 통해 부적절한 오류 처리로 인해 발생할 수 있는 중요한 버그를 발견하고 수정할 수 있습니다.
Scalability
- Definition of scalable systems: As the system grows (in data volume, traffic volume, or complexity), there should be reasonable ways of dealing with that growth
- Strong scalability
- Weak scalability
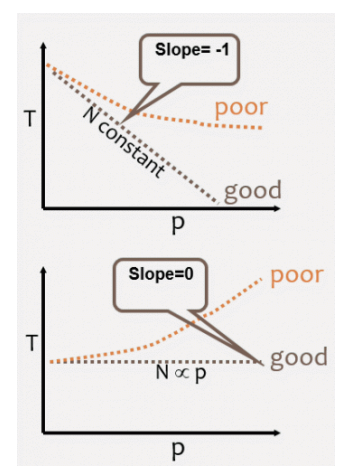
Amdahl's Law (Strong Scaling)
- Speedup = 1 / (1-P), where P is the fraction of code that can be parallelized
여기서 P는 병렬화할 수 있는 코드의 비율입니다. - Or Speedup = 1 / ((P/N)+S), where (S=serial fraction, P=parallel fraction, N= number of processors.
여기서 S는 직렬 분할, P는 병렬 분할, N은 프로세서의 수입니다.- You can spend a lifetime getting 95% of your code to be parallel, and never achieve better than 20x speedup no matter how many processors you throw at it!
당신은 평생을 들여 코드의 95%를 병렬화하게 만들 수 있지만, 얼마나 많은 프로세서를 사용하든 상관없이 20배 이상의 속도 향상을 달성하지 못할 수 있습니다!
- You can spend a lifetime getting 95% of your code to be parallel, and never achieve better than 20x speedup no matter how many processors you throw at it!
- However, if we have increased problem size, performance increase becomes huge.
암달의 법칙은 병렬 컴퓨팅의 성능 향상에 대한 한계를 설명하는 이론입니다. 코드의 일부만 병렬화할 수 있다면, 그 부분을 얼마나 많이 병렬화하더라도 전체 성능 향상에는 한계가 있다는 것입니다. 즉, 병렬화에 들이는 노력에 비해 성능 향상은 비례하지 않는다는 것입니다.
Weak Scaling (Gustafson):
- Goal is to run larger problem in the same amount of time
- Perfect scaling means problem Px runs in same time as single processor run
완벽한 확장성이란, P개의 프로세서로 실행하는 문제 Px가 단일 프로세서로 실행하는 것과 동일한 시간이 걸린다는 것을 의미합니다
Amdahl의 법칙을 사용해 속도 개선을 측정할 때 경성 스케일링(strong scaling)과 연성 스케일링(weak scaling) 방식으로 측정할 수 있다. 경성 스케일링은 문제의 크기를 고정시킨 상태에서 프로세서의 개수를 늘렸을 때 프로세서당 성능의 향상 정도를 측정하는 것이다. 연성 스케일링은 프로세서의 개수에 비례하여 문제의 크기를 증가시켰을 때 프로세서당 성능의 향상 정도를 측정하는 것이다. 보통 연성 스케일링에서 성능 개선이 더 높게 측정되지만 캐시 메모리에 처리해야할 데이터를 모두 담지 못한다면 오히려 성능이 저하되기도 한다고 한다.
Describing “Load” : X (a.k.a. Twitter) case
- Two main operations: Post tweet and Home timeline
- Post tweet: In 2012, a user published a new message to the followers (4.6k req./sec on average over 12k req./sec at peak)
- A user can view tweets posted by the people they follow (300k req./sec).3
"Post tweet"은 사용자가 새로운 트윗을 게시하는 작업이며, 이 트윗은 사용자를 팔로우하는 사람들의 홈 타임라인에 실시간으로 반영됩니다. 반면에 "Home timeline"은 사용자가 팔로우하는 사람들이 게시한 트윗들을 보는 작업이며, 팔로우하는 사람들이 새로운 트윗을 게시할 때마다 홈 타임라인이 업데이트됩니다.
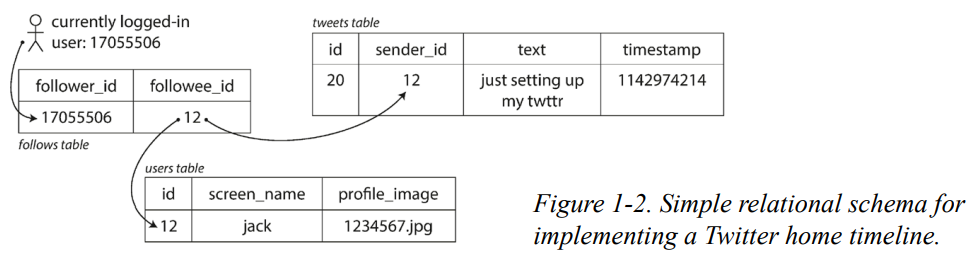
- Approach 1) 트윗이 게시될 때 팔로워들의 홈 타임라인에 실시간으로 분산되는 방식 (Post tweet)
SELECT tweets.*, users.* FROM tweets
JOIN users ON tweets.sender_id= users.id
JOIN follows ON follows.followee_id= users.id
WHERE follows.follower_id= current_user
이 SQL 쿼리는 현재 사용자(current_user)가 팔로우하는 사람들이 게시한 모든 트윗을 검색하는 데 사용됩니다. 사용자는 이 쿼리를 통해 자신이 팔로우하는 사람들이 게시한 트윗을 볼 수 있습니다.
Describing “Load” : X (a.k.a. Twitter) case
Approach 2)
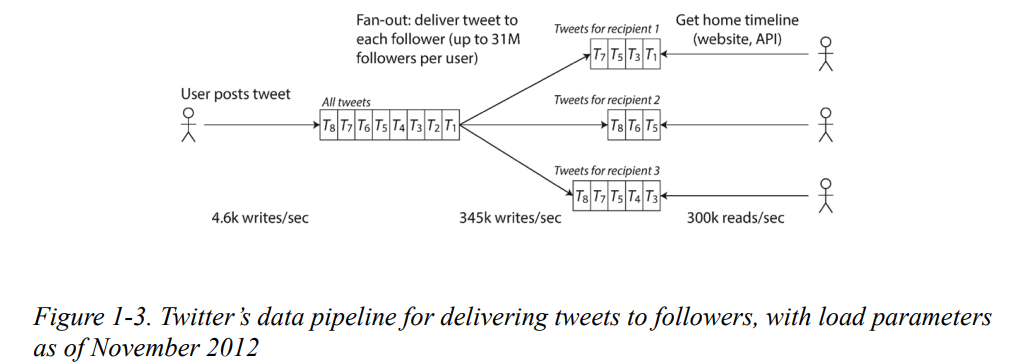
- Maintain a cache for each user’s home timeline—like a mailbox of tweets for each recipient user. When a user posts a tweet, look up all the people who follow that user, and insert the new tweet into each of their home timeline caches.
각 사용자의 홈 타임라인에 대한 캐시를 유지하십시오. 이는 각 수신자 사용자에 대한 트윗의 메일박스와 같습니다. 사용자가 트윗을 게시하면, 그 사용자를 팔로우하는 모든 사람들을 찾아내고, 새 트윗을 각각의 홈 타임라인 캐시에 삽입합니다
- Downside
- posting a tweet now requires a lot of extra work. On average, a tweet is delivered to about 75 followers, so 4.6k tweets per second become 345k writes per second to the home timeline caches.
이제 트윗을 게시하려면 많은 추가 작업이 필요합니다. 평균적으로 트윗은 약 75명의 팔로워에게 전달되므로 초당 4.6k 트윗은 홈 타임라인 캐시에 초당 345k 쓰기가 됩니다. - But this average hides the fact that the number of followers per user varies wildly, and some users have over 30 million followers.
- posting a tweet now requires a lot of extra work. On average, a tweet is delivered to about 75 followers, so 4.6k tweets per second become 345k writes per second to the home timeline caches.
- Solution: a hybrid of both approaches.
- Most users’ tweets continue to be fanned out to home timelines at the time when they are posted.
대부분의 사용자들의 트윗은 게시될 때 홈 타임라인으로 팬 아웃(분산)됩니다. - A small number of users with a very large number of followers (i.e., celebrities) are excepted from this fan-out. Tweets from any celebrities that a user may follow are fetched separately and merged with that user’s home timeline when it is read, like in approach 1.
팔로워 수가 매우 많은 소수의 사용자들(즉, 연예인들)은 이 팬 아웃에서 제외됩니다. 사용자가 팔로우하는 어떤 연예인의 트윗도 별도로 가져와서 읽을 때 그 사용자의 홈 타임라인과 병합됩니다, 이는 첫 번째 접근법과 같습니다.
- Most users’ tweets continue to be fanned out to home timelines at the time when they are posted.
요약하면, 팔로워 수가 많지 않은 일반 사용자의 트윗은 게시와 동시에 팔로워의 홈 타임라인 캐시에 삽입되는 반면, 팔로워 수가 매우 많은 사용자(예: 연예인)의 트윗은 홈 타임라인을 로드할 때 병합되는 방식을 사용합니다.
Describing Performance
- In a batch processing system such as Hadoop, Throughput—the number of records we can process per second, or the total time it takes to run a job on a dataset of a certain size.
특정 크기의 데이터 세트에서 작업을 실행하는 데 걸리는 총 시간. - In online systems, what’s usually more important is the service’s Response time—that is, the time between a client sending a request and receiving a response.
Response Time
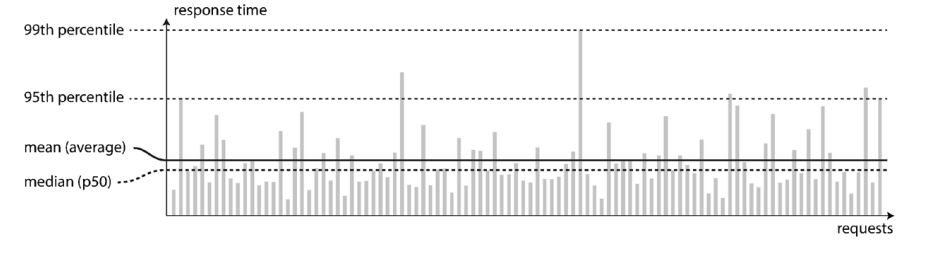
- Tail latencies are important because they directly affect users’ experience of the service.
- Amazon describes response time requirements for internal services in terms of the 99.9th percentile (1 in 1,000 requests) : the customers with the slowest requests are often those who have the most data on their accounts because they have made many purchases—that is, they’re the most valuable customers.
Amazon은 내부 서비스에 대한 응답 시간 요구사항을 99.9퍼센트일(천 번의 요청 중 하나)로 설명합니다 : 가장 느린 요청을 하는 고객들은 대부분 그들의 계정에 많은 데이터가 있기 때문입니다. 그 이유는 많은 구매를 했기 때문인데, 이는 바로 가장 가치 있는 고객들을 의미합니다 - Amazon has also observed that a 100 ms increase in response time reduces sales by 1%, and others report that a 1-second slowdown reduces a customer satisfaction metric by 16%.
- On the other hand, optimizing the 99.99th percentile (the slowest 1 in 10,000 requests) was deemed too expensive and to not yield enough benefit for Amazon’s purposes. Reducing response times at very high percentiles is difficult because they are easily affected by random events outside of your control, and the benefits are diminishing
아마존은 99.99퍼센트일(만 번의 요청 중 하나)에 최적화하는 것이 너무 비용이 많이 들며, 아마존의 목적에 비해 충분히 이익을 가져오지 못한다고 판단했습니다. 매우 높은 백분위수에서 응답 시간을 줄이는 것은 그것들이 당신의 통제 범위를 벗어난 무작위 이벤트에 쉽게 영향을 받기 때문에 어렵습니다. 또한 이점은 점점 줄어듭니다
- Amazon describes response time requirements for internal services in terms of the 99.9th percentile (1 in 1,000 requests) : the customers with the slowest requests are often those who have the most data on their accounts because they have made many purchases—that is, they’re the most valuable customers.
Approaches for Coping with Load
- Scaling Up & Scaling Out
- Scaling up (vertical scaling, moving to a more powerful machine) and scaling out (horizontal scaling, distributing the load across multiple smaller machines).
- Some systems are elastic(flexible) - automatically add computing resources when they detect a load increase. An elastic system can be useful if the load is highly unpredictable.
- Service State
- While distributing stateless services across multiple machines is fairly straightforward, taking stateful data systems from a single node to a distributed setup can introduce a lot of additional complexity.
상태 비저장 서비스를 여러 시스템에 분산하는 것은 매우 간단하지만, 단일 노드에서 분산 설정으로 상태 저장 데이터 시스템을 전환하면 많은 추가 복잡성이 발생할 수 있습니다 - It is common to keep your database on a single node (scale up) until scaling cost or high availability requirements forced you to make it distributed.
데이터베이스를 단일 노드에 유지하는 것이 일반적입니다(확장). 이는 확장 비용이나 고가용성 요구사항이 분산 시스템으로 전환하도록 강제할 때까지입니다
- While distributing stateless services across multiple machines is fairly straightforward, taking stateful data systems from a single node to a distributed setup can introduce a lot of additional complexity.
Maintainability
- Definition of maintainable systems: Over time, many different people will work on the system (engineering and operations, both maintaining current behavior and adapting the system to new use cases), and they should all be able to work on it productively
Three design principles for software systems
- Operability(조작성)
- Make it easy for operations teams to keep the system running smoothly.
운영팀이 시스템을 원활하게 운영할 수 있도록 합니다.
- Make it easy for operations teams to keep the system running smoothly.
- Simplicity
- Make it easy for new engineers to understand the system, by removing as much complexity as possible from the system. (Note this is not the same as the simplicity of the user interface.)
- Evolvability
- Make it easy for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change. Also known as extensibility, modifiability, or plasticity.
요구사항이 변경됨에 따라 예상치 못한 사용 사례에 맞게 조정하여 엔지니어가 향후 시스템을 쉽게 변경할 수 있도록 합니다.
- Make it easy for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change. Also known as extensibility, modifiability, or plasticity.
- The majority of the cost of software is not in its initial development but in its ongoing maintenance—fixing bugs, keeping its systems operational, investigating failures, adapting it to new platforms, modifying it for new use cases, repaying technical debt, and adding new features.
소프트웨어 비용의 대부분은 초기 개발이 아니라 지속적인 유지보수에 있습니다. 버그 수정, 시스템 작동 유지, 장애 조사, 새로운 플랫폼에 적용, 새로운 사용 사례에 맞게 수정, 기술 부채 상환, 새로운 기능 추가 등입니다.
