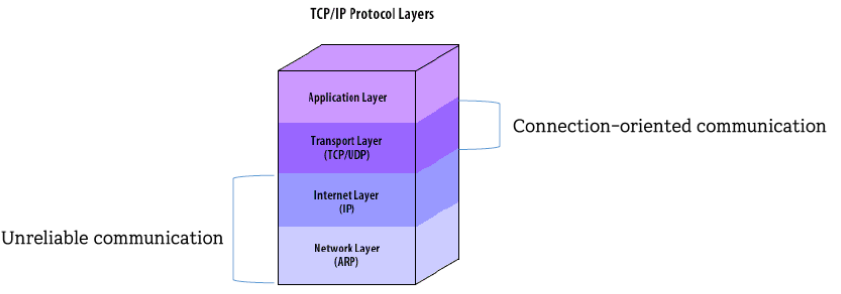
(Ch. 2) Data Models and Query Languages
Data Model
-
Data models are perhaps the most important part of developing software, because it is about not only on how the software is written, but also on how we think about the problem that we are solving.
- As an application developer, you look at the real world (in which there are people, organizations, goods, actions, money flows, sensors, etc.) and model it in terms of objects or data structures, and APIs that manipulate those data structures.
애플리케이션 개발자인 여러분은 (사람, 조직, 상품, 행동, 자금 흐름, 센서 등이 있는) 현실 세계를 보고 사물이나 데이터 구조, 해당 데이터 구조를 조작하는 API 측면에서 모델링합니다.
- When you want to store those data structures, you express them in terms of a general-purpose data model, such as JSON or XML documents, tables in a relational database, or a graph model.
JSON 또는 XML 문서와 같은 범용 데이터 모델, 관계형 데이터베이스의 테이블 또는 그래프 모델로 표현합니다.
- The engineers who built your database software decided on a way of representing that JSON/XML/relational/graph data in terms of bytes in memory, on disk, or on a network. The representation may allow the data to be queried, searched, manipulated, and processed in various ways.
표현은 데이터를 다양한 방식으로 조회, 검색, 조작 및 처리할 수 있도록 할 수 있습니다. - On yet lower levels, hardware engineers have figured out how to represent bytes in terms of electrical currents, pulses of light, magnetic fields, and more.
Relational Model (SQL) vs Document Model (NoSQL)
- Relational Model
- The best-known data model today is probably that of SQL, based on the relational model proposed by Edgar Codd in 1970
- Data is organized into relations (called tables in SQL), where each relation is an unordered collection of tuples (rows in SQL).
- The birth of NoSQL
- A need for greater scalability than relational databases can easily achieve, including very large datasets or very high write throughput.
- However, the name “NoSQL” doesn’t actually refer to any particular technology.
- Document databases target use cases where data comes in self-contained documents
문서 데이터베이스는 데이터가 독립적인 문서 형태로 제공되는 사용 사례를 목표로 합니다.(각 데이터 항목이 독립적인 문서로 존재하는 경우에 최적화된 데이터베이스 유형)
Naïve and Simple Comparison between Relational Versus Document Databases
- The document data model are schema flexible, better performance due to locality, and that for some applications it is closer to the data structures used by the application.
일부 애플리케이션의 경우 애플리케이션이 사용하는 데이터 구조에 더 가깝습니다. - The relational model counters by providing better support for joins, and many-to-one and many-to-many relationships.
관계형 모델은 join, 다대일 및 다대다 관계에 대한 더 나은 지원을 제공함으로써 대응합니다.
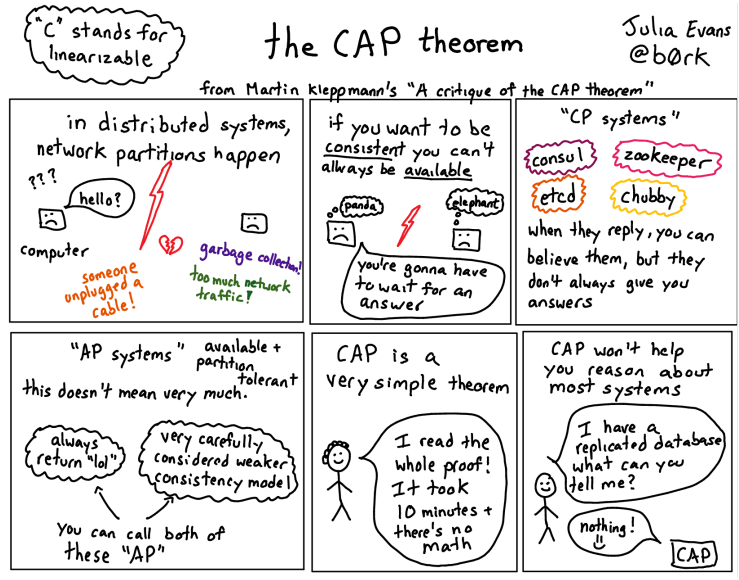
Object-Relational Mismatch
객체 지향 프로그래밍 언어에서는 데이터를 객체라는 단위로 다룹니다. 반면에 관계형 데이터베이스에서는 데이터를 테이블, 행, 열의 형태로 저장합니다. 이 두 모델 사이에는 자연스럽게 변환할 수 있는 직접적인 연결고리가 없습니다.
따라서 객체 지향 언어로 작성된 애플리케이션 코드와 관계형 데이터베이스 사이에서는 '번역 계층'이 필요합니다. 이 계층은 애플리케이션의 객체를 데이터베이스의 테이블 구조로 변환하고, 반대로 데이터베이스의 데이터를 객체로 변환하는 역할을 합니다. 이러한 변환 과정은 복잡하고 번거로울 수 있으며, 이로 인해 발생하는 불일치 문제를 '객체-관계 불일치'라고 부릅니다."
- Most application development today is done in object-oriented programming languages, which leads to a common criticism of the SQL data model: if data is stored in relational tables, an awkward translation layer is required between the objects in the application code and the database model of tables, rows, and columns.
- Object-relational mapping (ORM) frameworks like Hibernate reduce the amount of boilerplate code required for this translation layer, but they can’t completely hide the differences between the two models.
하이버네이트와 같은 ORM(Object-Relational Mapping) 프레임워크는 이 변환 계층에 필요한 보일러 플레이트 코드의 양을 줄이지만 두 모델 간의 차이를 완전히 숨길 수는 없습니다.
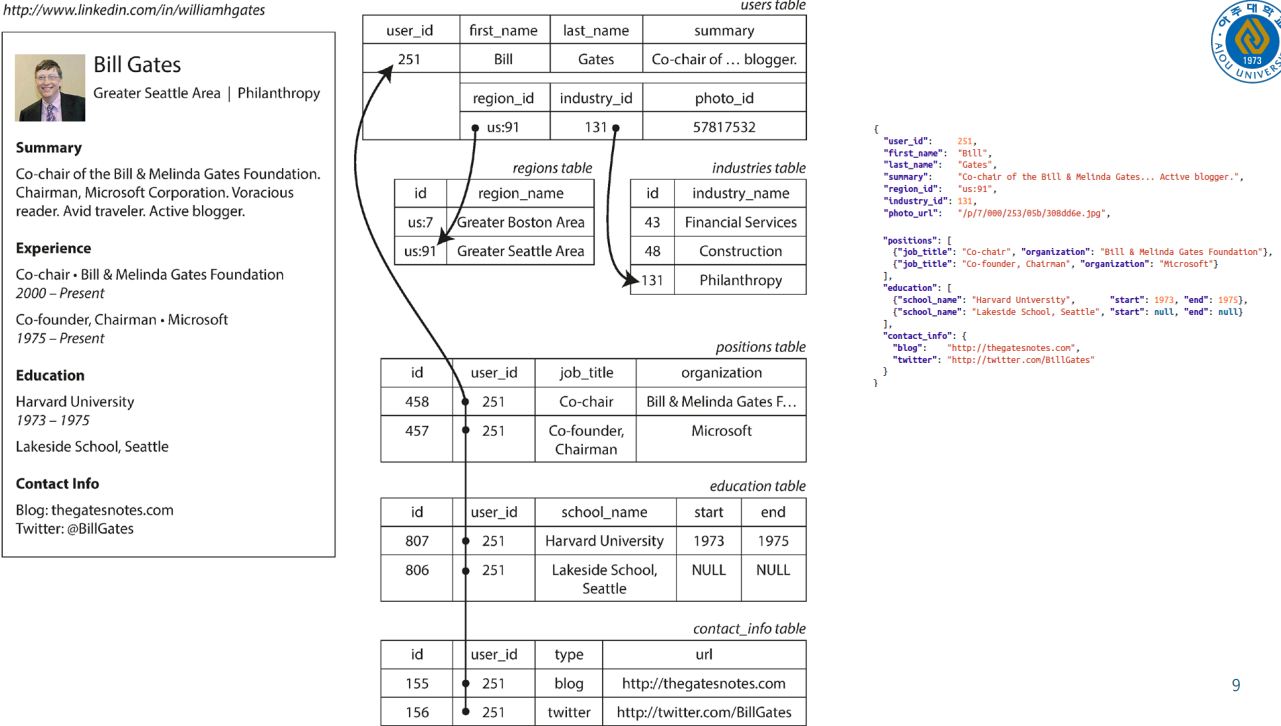
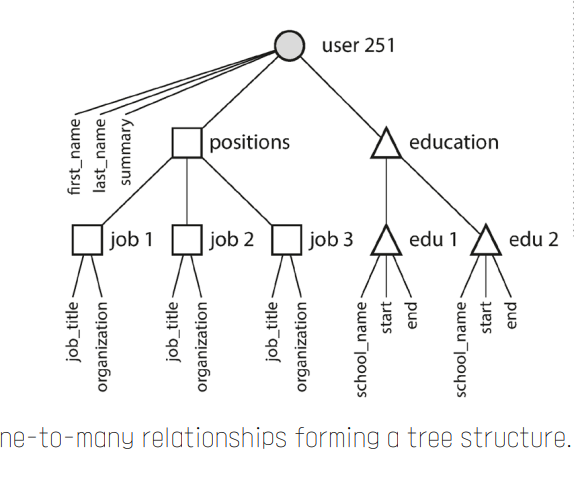
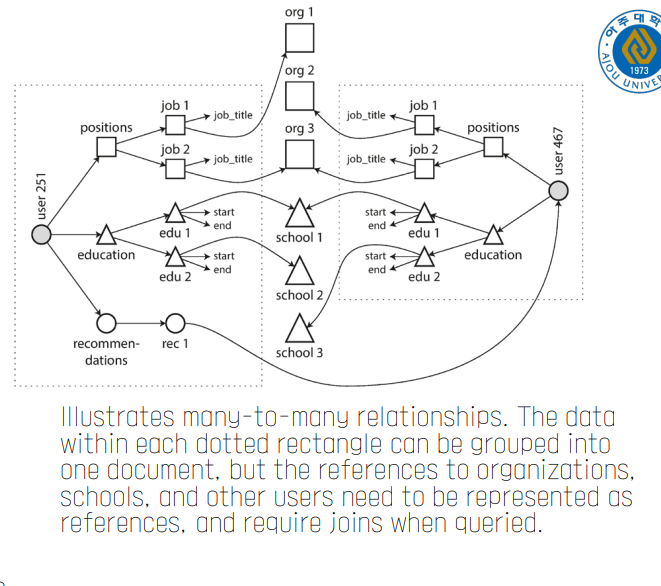
그렇다면 nosql은 불일치가 없나?
예를 들어, 문서 지향형 NoSQL 데이터베이스(예: MongoDB)는 JSON 형식의 문서를 사용하여 데이터를 저장합니다. 이는 객체 지향 프로그래밍에서 사용하는 데이터 구조와 비교적 잘 맞아떨어집니다. 따라서 이런 경우에는 객체-데이터베이스 불일치 문제가 상대적으로 덜 합니다.
그러나 키-값 형식의 NoSQL 데이터베이스(예: Redis)나 칼럼 지향형 NoSQL 데이터베이스(예: Cassandra)는 데이터를 저장하는 방식이 객체 지향 프로그래밍과는 다르므로, 여전히 객체-데이터베이스 불일치 문제가 발생할 수 있습니다.
따라서 NoSQL 데이터베이스를 사용하더라도, 사용하는 데이터베이스의 특성과 자신의 애플리케이션의 요구사항을 잘 이해하고, 적절한 데이터 모델링과 프로그래밍 기법을 적용하는 것이 중요합니다.
The Trouble with Distributed Systems
Faults and Partial Failures
- A program on a single computer behaves in a predictable way
- If everything is normal => the program works
- Else if there is something wrong => the fault & possible program halt.
- In many cases, the problem in a single computer is a bug in the program
- (When HW is in normal state,) the same operation returns the same results => deterministic
- If there is a hardware problem, the consequence is usually a total system failure.
- Characteristics of Distributed Systems => Anything that can go wrong will go wrong.
잘못될 수 있는 것은 무엇이든 잘못될 것입니다.- We can not be optimistic
- Node (H/W) can go wrong
- Network can go wrong
- Process can go wrong
- Partial Failures: In a distributed system, there may well be some parts of the system that are broken in some unpredictable way, even though other parts of the system are working fine.
- A partial failure is hard to predict. Also, the cause of the failure is nondeterministic in most cases*.
Cloud Computing vs Super Computing
-
Cloud Computing
- Multi-tenant datacenters
- Commodity computers
- Connected with an IP network
- Elastic/on-demand resource allocation
탄력적/요청에 따른 리소스 할당 - Measured billing
-
High Performance Computing
- Tightly coupled CPUs (thousands of)
- More like a single computer
Traditional enterprise datacenters lie somewhere between these extremes.
- In HPC, a job typically checkpoints the state of its computation to durable storage. If one node fails, simply stop the entire cluster workload => escalating partial failure into total failure
HPC에서 작업은 일반적으로 내구성이 뛰어난 스토리지에 대한 계산 상태를 확인합니다. 하나의 노드에 장애가 발생하면 전체 클러스터 워크로드를 중지하기만 하면 됩니다 => 부분 장애를 전체 장애로 확대합니다 - This book covers regular applications for Internet services.
- need to be able to serve users with low latency at any time (unavailable is not acceptable)
- HPC’s special HW such as RDMA vs. Commodity HW
- Distributed SW system must be very reliable or fault-tolerant (must accept the possibility of partial failure)
매우 안정적이거나 고장에 강해야 합니다(부분 고장 가능성을 수용해야 함)
Building a Reliable System from Unreliable Components
- Even if the underlying technology is not reliable, the whole system can be made reliable using higher technology
- However, there is always a limit to how much more reliable it can be
- TCP can retransmit missing packets, eliminate duplicates, reassemble packets into the order. BUT cannot remove delays
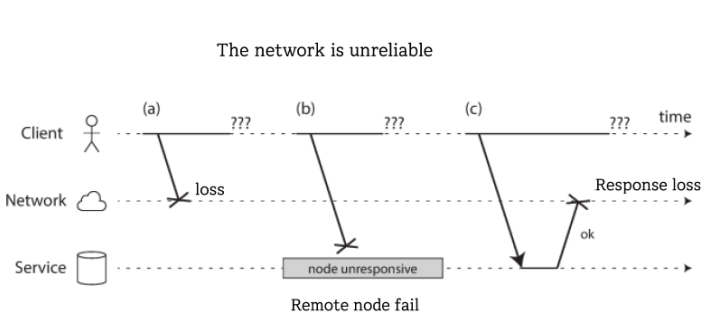
Unreliable Networks
- One node can send a message (a packet) to another node, but the network gives no guarantees
- A client can not distinguish what happened
- If you send a request and don’t get a response, it’s not possible to distinguish whether (a) the request was lost, (b) the remote node is down, or (c) the response was lost
Network faults in practice
- One study in a medium-sized datacenter found about 12 network faults per month, of which half disconnected a single machine, and half disconnected an entire rack [1]
- Adding redundant networking gear doesn’t reduce faults as much as you might hope, since it doesn’t guard against human error (e.g., misconfigured switches), which is a major cause of outages(운영중단) [2]
- Sharks might bite undersea cables and damage them [3]
상어는 해저 케이블을 물어 손상시킬 수 있습니다 - Handling network faults doesn’t necessarily mean tolerating(허용하다) them:
- simply show an error message would help
- However, you do need to know how your software reacts to network problems and ensure that the system can recover from them.
- Chaos Monkey : deliberately trigger network problems and test the system’s response
Detecting Faults
- Faults should be detectable automatically (SW system) so that,
- A load balancer (or any responsible module) needs to stop sending requests to a dead node.
- For a distributed database with a single-leader replication, one of followers needs to be promoted to be the new leader if the leader fails. (Chap. 5 Replication)
단일 리더 복제가 있는 분산 데이터베이스의 경우 리더가 실패할 경우 팔로워 중 한 명이 새로운 리더로 승격되어야 합니다
- Identifying a node failure (Network)
- If the process is dead but the OS is alive, the OS will helpfully close or refuse TCP connections.
프로세스가 종료되었지만 OS가 활성화된 경우 OS는 TCP 연결을 유용하게 닫거나 거부합니다. - If the process is dead but the OS is alive, a script can notify other nodes about the crash.
- If you have access to the management interface of the network switches, you can query them to detect link failures at a HW level.
- If the process is dead but the OS is alive, the OS will helpfully close or refuse TCP connections.
- However, explicit failure detection is not common
- If the node crashed while it was handling your request, you have no way of knowing how much data was actually processed by the remote node.
- If you’re connecting via Internet, you cannot access the network switches.
- In general, you have to assume that you will get no response at all if a node fails
Timeouts and Unbounded Delays
- Timeout is often used as a way to know node failure.
- Then, the problem is how long do we have to wait?
- If you use a long timeout => a long wait until a node is declared dead
- If you use a short timeout => detects faults faster => but carries a higher
risk of incorrectly declaring a node dead- A node may be just suffered from a temporary slowdown
노드가 일시적인 속도 저하로 인해 어려움을 겪을 수 있습니다.
- A node may be just suffered from a temporary slowdown
- Imagine a fictitious system with a network that guaranteed a maximum delay for packets, where
패킷의 최대 지연을 보장하는 네트워크가 있는 가상 시스템을 상상해 보십시오- Every packet is either delivered within some time
dor lost - We assume that a non-failed node always handles a request within some
timer
- Every packet is either delivered within some time
- In this case, you can guarantee that every successful request receives a response within
2d + r - In reality, there are no guarantees like
2d +r - A network can be asynchronous
- Unbounded delays(제한 없는 지연)
- They try to deliver packets as quickly as possible. But there is no upper limit on the time it may take for a packet to arrive.
패킷을 가능한 빠르게 전달하려고 노력합니다. 하지만 패킷이 도착하는 데 걸리는 시간에 대한 상한선은 없습니다.비동기 네트워크에서는 데이터 패킷의 전송이 동시에 발생하지 않고, 각 패킷이 독립적으로 처리되며 그 처리 시간이 일정하지 않습니다
- They try to deliver packets as quickly as possible. But there is no upper limit on the time it may take for a packet to arrive.
- Unbounded delays(제한 없는 지연)
- Most server implementation cannot guarantee that they can handle requests within some maximum time
Unreliable Clocks
- Applications depend on clocks in various ways to answer questions like:
- Duration:(지속성)
- Has this request timed out yet?
- What’s the 99th percentile response time of this service?
- How many queries per second did this service handle on average in the last five minutes?
- How long did the user spend on our site?
- Points in time(시간 관점)
- When was this article published?
- At what date and time should the reminder email be sent?
- When does this cache entry expire?
- What is the timestamp on this error message in the log file?
- Duration:(지속성)
Why clocks are unreliable?
- No global clock
- Each machine has its own clock <- cab be faster or slower (Google assumes a clock drift of 200 ppm (i.e., 17 sec drift for a clock that is re-synchronized once a day)
- Synchronize clocks to some degree is possible (Network Time Protocol: NTP) or GPS
- Monotonic Versus Time-of-Day Clocks
- Time-of-Day Clocks: the current data and time according to some calendar
실세계의 시간을 나타내며, 분산 시스템 내의 각 노드가 동일한 시간을 가지도록 하는 데 사용됩니다. 하지만, 네트워크 지연이나 시계의 오차 등으로 인해 완벽한 동기화는 어렵습니다. - Monotonic Clocks: measuring duration (time interval, difference between two points)
특정 이벤트 간의 시간 간격을 측정하는 데 사용됩니다. 즉, 실세계의 절대 시간대신 이벤트 간의 상대적인 시간을 나타냅니다
- Time-of-Day Clocks: the current data and time according to some calendar
Relying on Synchronized Clocks
- Monotonic clocks don’t need synchronization, but time-of-day clocks need to be set according to an NTP server or other external time source in order to be useful.
- The write by client B is causally later than the write by client A, but B’s write has an earlier timestamp. (Last Write Win used by Cassandra)
클라이언트 B의 쓰기는 클라이언트 A의 쓰기보다 인과적으로 늦지만, B의 쓰기는 타임스탬프가 더 빠릅니다.
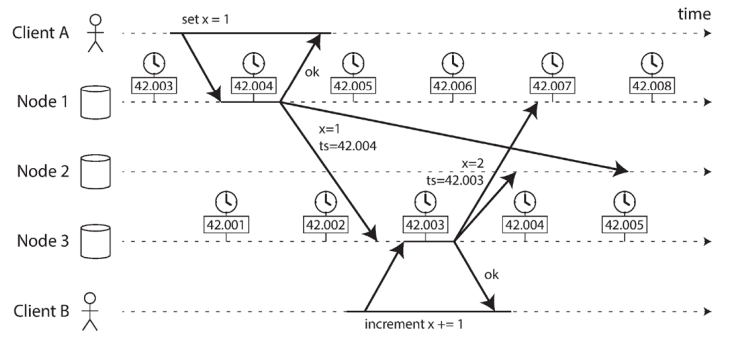
The truth is defined by the majority
- In distributed system, a node cannot trust their own judgement.
- One node claims to be alive, but other nodes may think that the node is dead due to a network problem
- There can be only one majority in the system. Therefore, when the majority reaches an agreement, the agreement does not conflict with other content.
- If a node is declared dead by majority vote, the node that is alive must admit it
투표제도로 가는구나..
The leader and the lock
- Frequently, a system requires there to be only one of something.
- Only one node is allowed to be the leader for a database partition to avoid split brain (split brain example: two nodes both believe that they are the leader).
- Only one transaction or client is allowed to hold the lock for a particular resource to prevent concurrently writing to it.
- Only one user is allowed to register a particular username because a username must uniquely identify a user.
- The following is possible in a distributed system
- One node claims that “I am selected.”
- But the majority say that “You are not.”
- A node may have formerly been the leader, but if the other nodes declared it dead in the meantime.
- It may have been demoted and another leader may have already been elected.
- If the node still act like a leader, it is a problem.
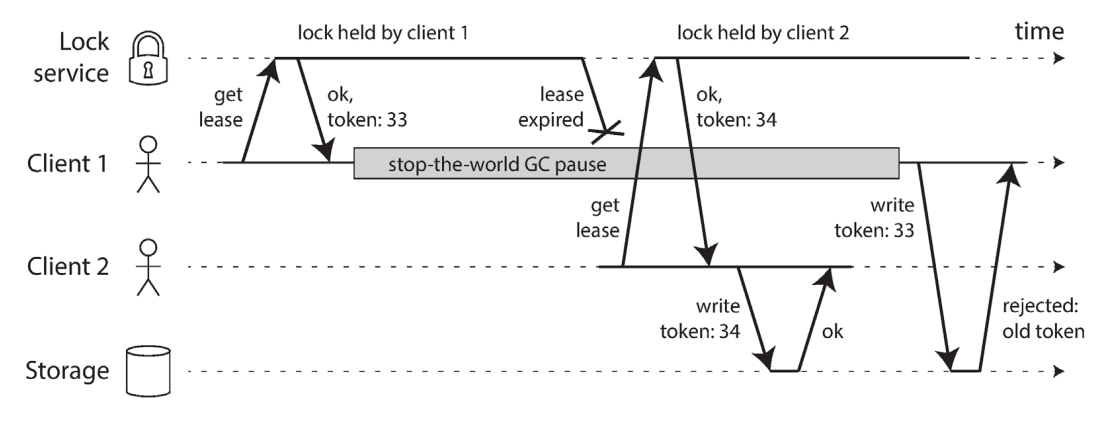
- Hbase used to have this bug in locking
- A data corruption bug due to an incorrect implementation of locking
locking의 잘못된 구현으로 인한 데이터 손상 버그
- A data corruption bug due to an incorrect implementation of locking
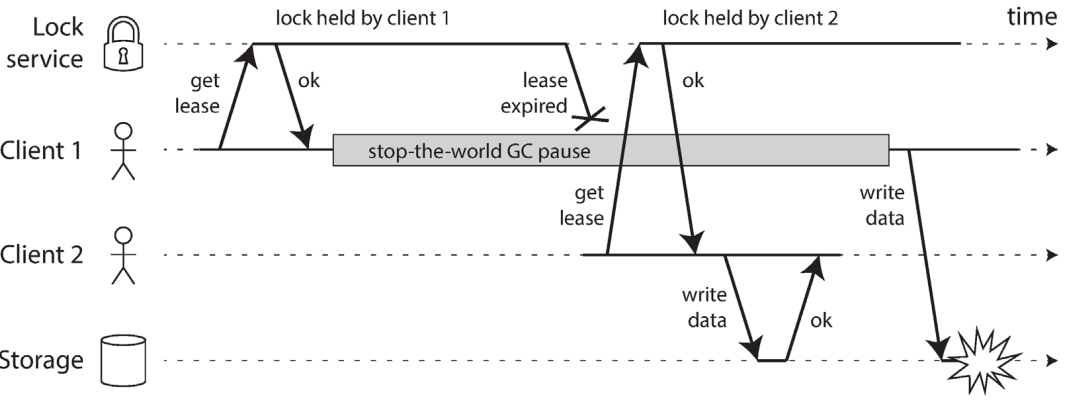
- Hbase used to have this bug in locking
- Solved with fencing token (33, 34 in the figure)
Byzantine Faults
- We may assume that the nodes are unreliable but honest.
- They may be slow or never respond due to a fault.
- Their state may be outdated due to network delays
- BUT we assume that if a node does respond, it is telling the “truth.”
- Distributed systems problem become much harder if there is a risk that nodes may “lie”
- Byzantine Faults
- “lie” means node send arbitrary faulty or corrupted responses
Weak forms of lying
- Although we assume that nodes are generally honest, it can be worth adding mechanism that guard against weak forms of ‘lying’
우리는 노드가 일반적으로 정직하다고 가정하지만, 약한 형태의 '거짓말'을 방지하는 메커니즘을 추가할 가치가 있습니다.- Invalid messages due to HW issues
- SW bugs
- Misconfiguration
- We can use
- Checksums in the application-level protocol to prevent message corruption
- Sanitize(검사하다) any inputs from users
- Checking that a value is within a reasonable range
- Multiple NTP server when clock is synchronized
clock을 동기화할 때 여러 NTP 서버를 사용하기여러 NTP 서버를 사용하면, 하나의 서버에 문제가 생겼을 때 다른 서버를 이용해 시간 동기화를 계속할 수 있으므로, 시스템의 시간 동기화 신뢰성을 높일 수 있습니다.
System Model and Reality
- Many algorithms have been designed to solve distributed systems problems
- Timing assumption
- The synchronous model assumes bounded network delay, bounded process pauses, and bounded clock error (i.e., set the fixed upper bound)
- The partially synchronous model behaves like a synchronous system most of the time, but it sometimes exceeds the bounds. This is a realistic model of many systems
부분 동기식 모델은 대부분의 경우 동기식 시스템처럼 행동하지만 때로는 한계를 초과하기도 합니다. 이것은 많은 시스템의 현실적인 모델입니다 - The asynchronous model is hard to implement. Only some algorithms can be designed for this model.
- Node Failure
- Crash-stop faults
- Crash-recovery faults
- Byzantine (arbitrary) faults: trying to trick and deceive other nodes
Summary
- Problems like:
- A sent (or replied) packet over the network may be lost or arbitrarily delayed. You have no idea whether the message got through.
메시지가 전달되었는지 여부는 알 수 없습니다. - A node’s clock may be significantly out of sync with other nodes (despite your best efforts to set up NTP). Relying on it is dangerous because you most likely don’t have a good measure of your clock’s error interval.
NTP를 설정하기 위해 최선을 다했지만 노드의 클럭이 다른 노드와 동기화되지 않을 수 있습니다. 클럭의 오류 간격을 제대로 측정하지 못할 가능성이 높기 때문에 클럭에 의존하는 것은 위험합니다. - A process may pause for a substantial amount of time at any point in its execution (e.g., garbage collection), be declared dead by other nodes, and then come back to life again without realizing that it was paused.
- A sent (or replied) packet over the network may be lost or arbitrarily delayed. You have no idea whether the message got through.
- SW that tolerates partial failures so that the system as a whole may continue functioning even when some of its parts are broken.
일부 부품이 고장났더라도 시스템 전체가 계속 작동할 수 있도록 부분 고장을 허용하는 SW. - Fault detection
- Rely on timeout => however, timeouts can’t distinguish between a node and network failures, and variable network delay causes a node to be suspected of crashing
타임아웃에 의존 => 그러나 타임아웃은 노드와 네트워크 장애를 구분할 수 없으며 네트워크 지연으로 인해 노드가 충돌하는 것으로 의심됩니다
- Rely on timeout => however, timeouts can’t distinguish between a node and network failures, and variable network delay causes a node to be suspected of crashing
- Fault tolerance
- Shared nothing makes it hard to tolerate the fault
아무것도 공유하지 않는 구조는 오류를 허용하기 어렵게 만듭니다.아무것도 공유하지 않는 구조(Shared nothing architecture)'는 각 시스템 노드가 자신의 데이터와 계산을 독립적으로 수행하는 구조를 말합니다. 이 구조는 확장성이 뛰어나지만, 한 노드가 고장나면 그 노드의 데이터와 계산이 다른 노드에 의해 복구되기 어렵습니다. 따라서 이러한 구조는 고장 허용성을 제공하기 어렵습니다
- Clock synchronization, sending data over unreliable network, try to get a quorum to agree
분산 시스템에서 fault tolerance를 달성하는 데 사용되는 기법들입니다
- Shared nothing makes it hard to tolerate the fault
- May choose not to use distributed system => however, scalability and high performance (low latency) can hardly achieved by a single node
분산 시스템을 사용하지 않을 수도 있음 => 그러나 단일 노드로는 확장성과 고성능(낮은 지연 시간)을 거의 달성할 수 없음
