System SW and Its Machine Dependency
-
System Software의 설계는 컴퓨터 구조에 영향을 받는다. 즉, 어떤 컴퓨터 architecture에서 동작하냐에 따라 세부적인 detail이 바뀔 수 있다. ->
machine dependentAssembler는 mnemonic instruction(어셈블리 언어)을 machine code로 변환한다.Assembler가 어떤 컴퓨터 아키텍쳐를 target으로 하는지에 따라 이 변환 과정의 디테일한 부분이 달라질 것이다.
-
대부분 컴퓨터 구조는 폰노이만 구조를 따르기 때문에 기본적인 내부 컨셉은 동일하다.
->machine independent
따라서 System SW는 컴퓨터 architecture에 따라 machine dependent 한 부분과 independent한 부분 둘 다 존재한다.
Computer Organization and Design
Reminder
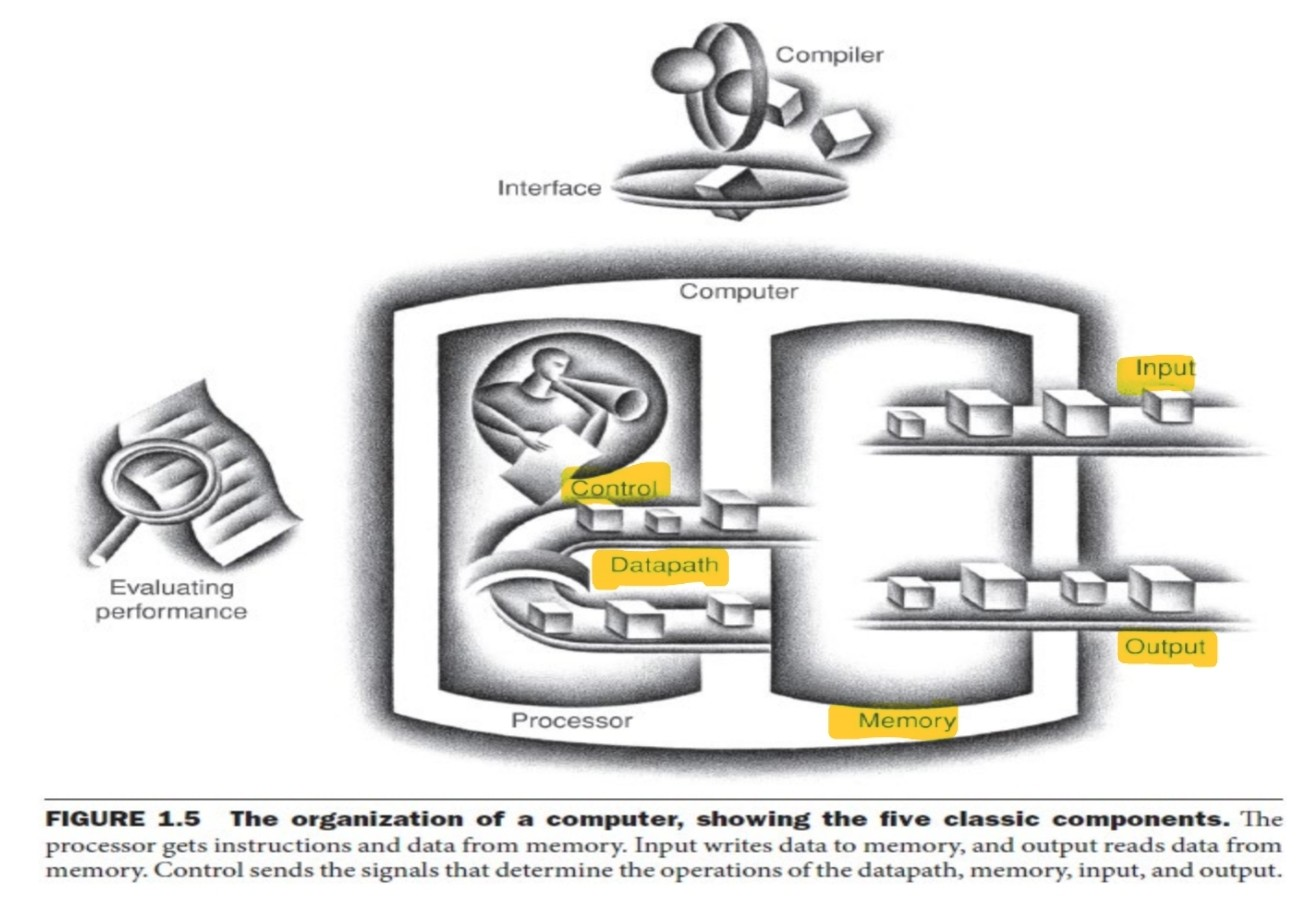
컴퓨터의 5가지 요소 :
Input, Output, Memory, Datapath, Control
Input으로부터 컴퓨터가 데이터를 받으면Memory에 저장이 된다.- 이 데이터는
Datapath를 통해서 CPU로 넘어가게 된다. - CPU 내부에 있는
Control파트가 데이터 연산을 수행하게 되고 - 연산 결과는 다시
Memory로 전달되고Memory에서 연산 결과를Output디바이스로 출력한다.
이것이 폰노이만 구조이다.
Computer Architecture
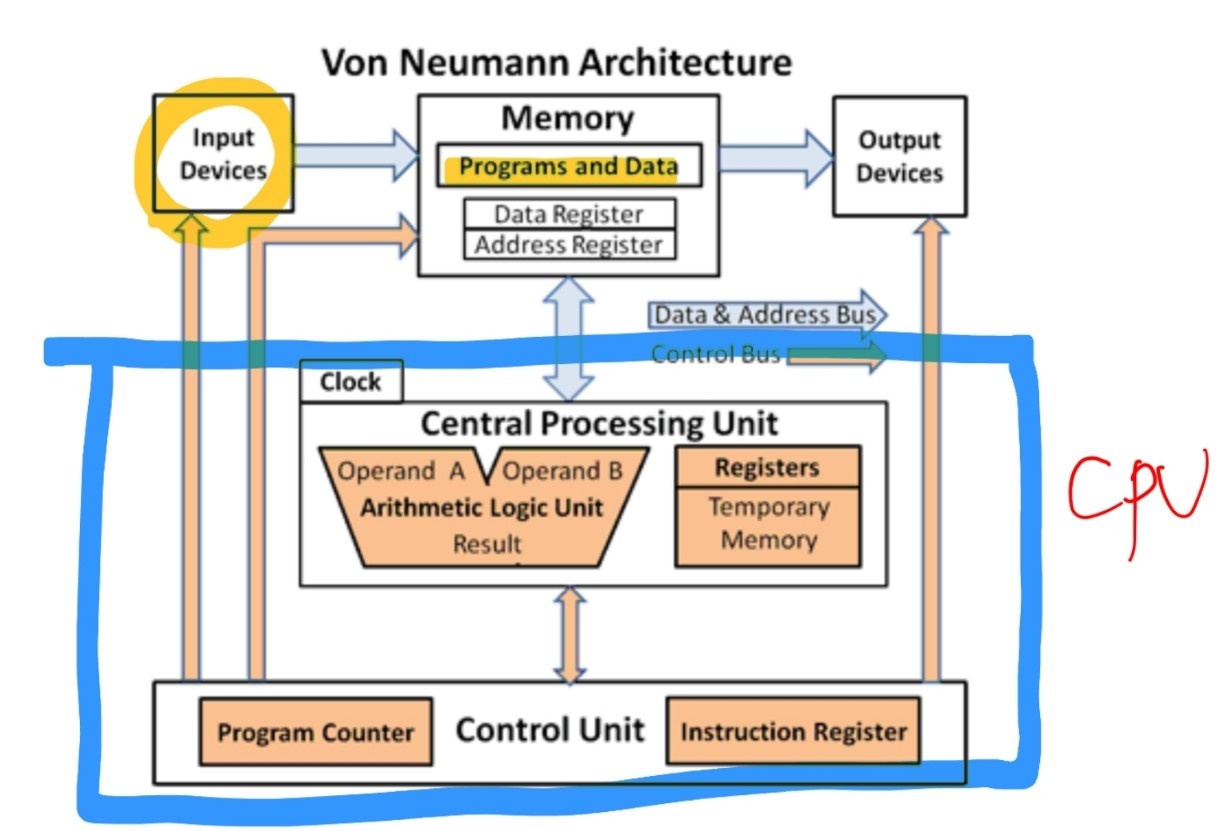
- Memory Unit에는
Pragram(a sequnce of instruction)과Data가 있다. - CPU는 ALU를 통해
Instuction들을 실행한다. - ALU는 산수, 논리적 연산 진행하는 Component이다.
Control Unit은 다른 컴포넌트들이 유기적으로 동작할 수 있도록 조율하는 역할을 한다.
이런 유기적인 동작 방식을 Fetch-Decode-Execute Cycle이라고 한다.
The Fetch-Decode-Execute Cycle
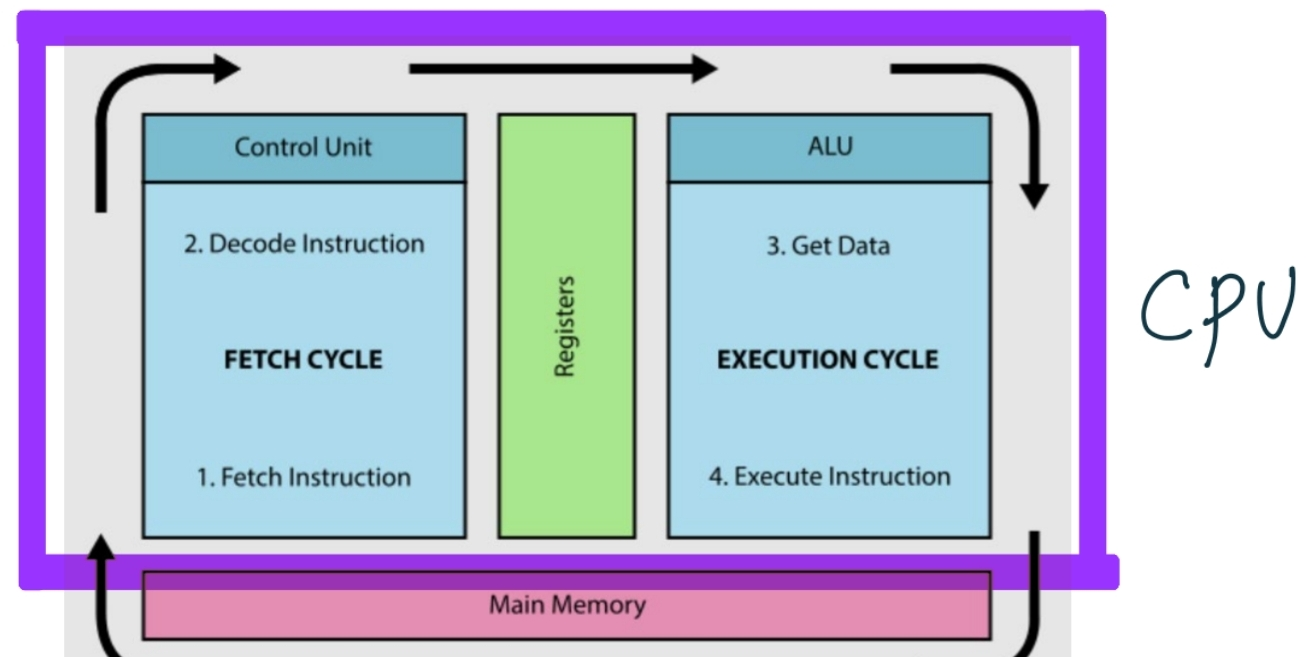
Fetch:Memory에서CPU로 데이터를 가져오는 과정Decode:Fetch된 Instuction을 분석해서 어떤 연산을 수행해야되는 것인지 판단하는 과정Execute: ALU, 메모리 및 I/O 컨트롤러에 적절한 Instruction을 실행하는 과정
이쪽
SIC
- SIC는 가상 컴퓨터이다.
- SIC는 대부분의 Real Device가 가지고 있는 공통적인 특징들을 포함하고 있다. 불필요한 세부적인 feature들은 제거함.
- SIC/XE machine에서도 SIC 프로그램이 동작 가능하다 ->
Upward Compatibility를 지원한다.상위 호환
SIC Machine Architecture

Memory in General
- 1차원
Array형태로 되어있다. 이Array가Index로 사용할 수 있는 주소값을 가진다. 주소는 0으로 시작한다. - 메모리의 가장 작은 저장 단위를
Cell이라고 한다. 이Cell은 각자의 주소를 가지고 있다. - Random access가 가능하기 때문에,
Memory를RAM(Random Access Memory)이라고도 부른다. Instruction과Data가Memory에 올라와야 CPU가 실행 가능하다는 특징을 가진다.- 메모리는
CPU에 연결되어 있고 다른 데이터들을 빠르게 옮길 수 있다는 특징을 가진다.
Memory in SIC
- 위에서 나타낸 일반적인 특징을 포함하고 있다.
- 일반적으로 하나의
Cell은 1byte인데,SIC에서는 3byte word를 지원한다. 1 word를 3byte로 정의하고 있다. - 여기서
Word는CPU가Memory에서 한번에 읽거나 쓸 수 있는 데이터 단위를 말한다. - Maximum memory Available : 32KB( bytes)
이는 15비트로 메모리 주소를 나타낼 수 있다는 의미를 가지고 있다.
이해가 되지 않는다면 아래 그림을 참고하는게 좋겠다.
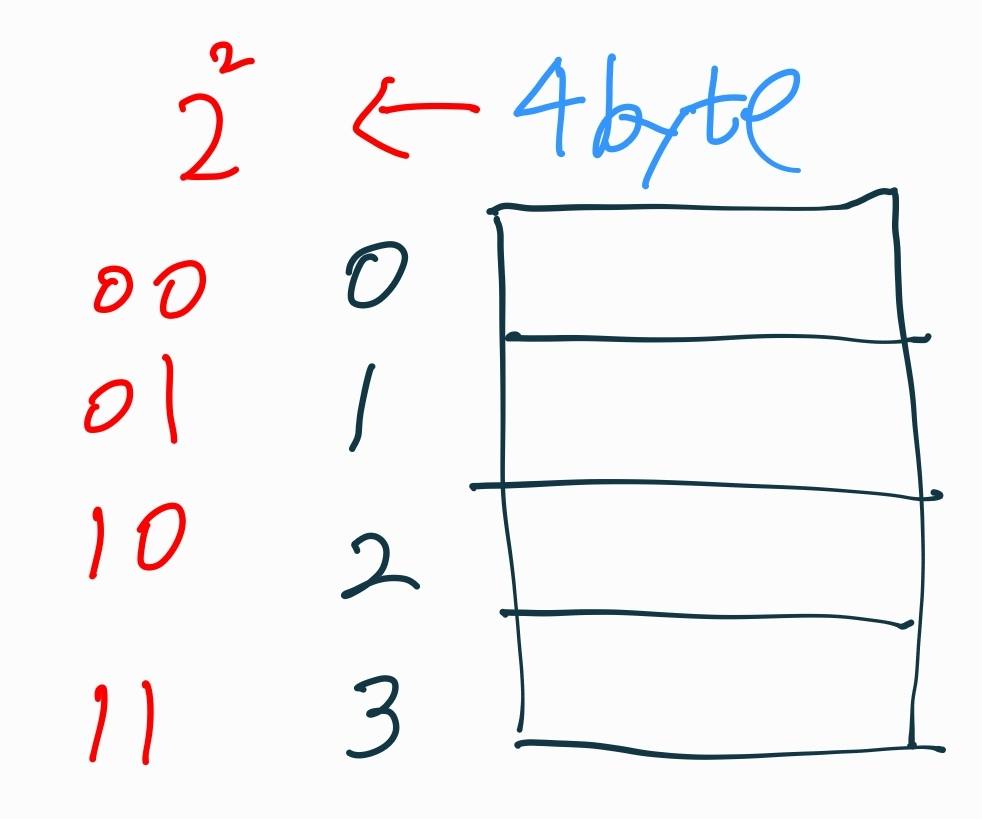
Maximum으로 가능한 메모리의 크기가 4Byte라고 가정하자.
4byte= byte이고 4개의 cell을 2개의 비트로 메모리의 주소를 나타낼 수 있음을 그림으로 확인할 수 있다.
32KB = byte 이므로 15개의 비트로 메모리의 주소를 나타낼 수 있다.
Registers in General
- CPU 내부에 있는 저장공간, 임시적으로 사용하는 데이터를 저장. 메모리에서 데이터를 가져와서 cache하는 용도로 사용
- 특수한 용도, 일반적인 용도로 사용하는 레지스터 존재
Registers in SIC
5개의 레지스터만 존재한다.
레지스터 크기는 1word의 크기로 설정되어야 하므로 3Byte이다.
- A (0): Accumulator : 산술 연산
- X (1): Index register : index value로 사용하는 값을 저장하는 레지스터 ex) 반복문 index의 값
- L (2): Linkage register : 함수가 종료되면 다시 원래의 함수로 돌아가야 하는데 돌아갈 주소를 저장하는 레지스터
- PC (8): Program Counter :
CPU가 다음에 실행해야할Instruction이 위치한 주소를 저장 - SW (9): Status Word : 기타 정보를 저장하는 레지스터. 24비트 중에서 CC 필드만 기억하자.
CC필드는 condition code의 약자로써 Comparison, Condition Jump에 사용된다.

format 기억
Data Format
- Integer : 3바이트로 저장, 음수 사용하기 위해 2의 보수 표현법을 사용
- Character : 1바이트, 아스키 코드
- Floating Point 지원 하지 않음
- 실수를 나타낼 수 없다는 것을 의미함!!
Machine Instruction Formats
모든 instruction은 24비트 형태의 format을 가지고 있다.
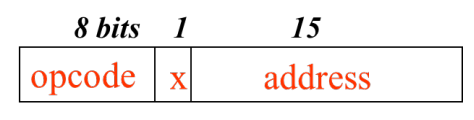
Opcode : 어떤 역할을 하는 instruction인지 나타내주는 코드
Address field : Instruction이 실행되기 위해 필요한 연산자의 위치를 알려주고 있다.
SIC는 의 메모리 크기를 가지고 있고, 메모리 전체의 주소공간을 나타내기 위해서 최소 15비트가 필요하다.
Addressing Modes in General
Instruction이 수행되기 위해서는 피 연산자(Operand)가 필요하다.
Operand가 어디있는지 알아야 하는데 이 Operand 주소를 계산하는 방식을 Addressing이라고 한다.
Addressing Modes in SIC
SIC에서 Operand의 주소를 계산하는 방식은 총 2가지가 있다.
위의 사진을 다시 참고해보자.
- Direct addressing mode : 위의 24비트의 Operand에서 x를 flag bit라고 하는데 이 flag bit가 0일때를 말한다.
- Target Address = address
- Indexed addressing mode : flag bit가 1일때를 말한다.
- Target Address = address + X
여기서 더하는 X 값은 flag bit의 값이 아니라! Register X에 들어있는 값이다.
즉, X 레지스터에 저장된 값+ 15비트의 address를 더한 값이 Target Address가 된다.
Instructions Set in General
CPU가 실행될 수 있는 모든Instruction의 집합을 의미한다.- 각
Instruction을 통해CPU가 어떤 동작을 하는지 알 수 있다. - 어떤 addressing mode, 데이터 타입, 레지스터가 구성 되어있는지 확인할 수 있다.
이를 통틀어
instruction set architecture->ISA라고 한다.
Instructions Set in SIC
-
Load/Store :
LDA,LDX,STA,STX,etc.
LDA m? 메모리 주소 m에 위치한 3바이트의 데이터가 레지스터 A로 저장되는 연산
STA m? 레지스터 A에 들어있는 3바이트의 데이터를 메모리 주소 m에 집어넣는 연산 -
Integer Arithmetic Operations :
ADD,SUB,MUL,DIV
ADD m ? A에 있는 값과 주소 m에 위치한 3바이트 데이터를 더하여 레지스터 A에 다시 저장하는 연산.
SUB m ? A에 있는 값과 주소 m에 위치한 3바이트 데이터를 빼서 레지스터 A에 다시 저장하는 연산.
MUL m ? A에 있는 값과 주소 m에 위치한 3바이트 데이터를 곱하여 레지스터 A에 다시 저장하는 연산.
DIV m ? A에 있는 값과 주소 m에 위치한 3바이트 데이터를 나누어 레지스터 A에 다시 저장하는 연산.
- Comparison:
COMP
COMP m ? 레지스터 A의 값과 메모리 주소 m에 위치한 3바이트 데이터와 대소 관계를 비교한다.
비교 결과를 레지스터 SW의 CC field에 다음과 같이 저장이 된다.
- 레지스터 A 값 메모리 주소 m에 위치한 3바이트 데이터
01로 저장
- 레지스터 A 값 메모리 주소 m에 위치한 3바이트 데이터
00으로 저장
- 레지스터 A 값 메모리 주소 m에 위치한 3바이트 데이터
10으로 저장
- Conditional Jump:
JLT, JEQ, JGT
JLT m ? CC 필드의 값을 확인하고 01비트이면 메모리 주소 m에 위치한 Instruction을 실행하는 것
JEQ m ? CC 필드의 값을 확인하고 00비트이면 메모리 주소 m에 위치한 Instruction을 실행하는 것
JGT m ? CC 필드의 값을 확인하고 10비트이면 메모리 주소 m에 위치한 Instruction을 실행하는 것
마치 if문으로 분기를 나누듯이 사용할 수 있다!
- Subroutine linkage:
JSUB,RSUB
서브루틴을 호출하기 위한 Instruction이다.
메인 루틴을 실행하다가 어느 순간 서브루틴의 로직이 필요해서 서브루틴을 호출해야 할 때가 있다. 이때 호출하는 instruction이 JSUB이다.
JSUB m? 주소가 m인 서브루틴을 호출하는 Instruction
JSUB을 호출할 때 내부적으로는 RegisterL과 RegisterPC의 값이 조정된다.
JSUB을 실행하기 전,PC는 다음 Instruction을 가리키고 있을 것이다. 즉 다음 Instruction의 주소값을 가지고 있을 것이다.
JSUB을 만나게 되면, 서브루틴을 실행하게 된다.
서브루틴이 끝나고 다시 메인으로 돌아올 주소를 알아야 하는데 이것을 Register L에 저장한다.
그리고 PC의 값은 서브루틴이 시작하는 지점으로 바뀐다.
register
L에는 return address(메인루틴에서 JSUB의 다음 Instruction)를 저장하고
registerPC에는 서브루틴의 시작점을 저장하게 된다.
RSUB ? 서브루틴을 종료하고 메인루틴으로 돌아올 때 호출하는 Instruction
RSUB을 만나게 되면 코드 flow가 메인루틴에서 JSUB의 다음 위치로 이동하게 된다.
내부적으로는 Register PC 값을 Register L값으로 바꿔주어 메인 루틴으로 돌아갈 수 있게 하는 역할을 한다.
- I/O (Input and Output)
SIC에서는 기본적으로 I/O instruction을 수행하게 되면 1번에 1Byte만 읽어오거나 전달하게 된다.
Input 연산은 I/O로부터 읽어들인 1Byte의 데이터만 Register A로 가져온다.
Register A의 크기는 3Byte이므로 가장 오른쪽의 1Byte에 저장된다.
Output 연산은 Register A의 가장 오른쪽의 1Byte에서 데이터를 꺼내어 Output Device에게 전달한다.
TD m? I/O 연산 준비가 되었는지 확인하는 Instruction
메모리 주소 m에 해당하는 공간에 유니크한 코드가 저장되어있는데 유니크 코드에 대해 테스트를 한다.
이때 준비상태가 되었다면
레지스터 sw의 cc 필드를 ""(less than symbol)로 세팅하고
준비가 되지 않았다면 "" (equal symbol)로 세팅한다.
참고 : 일반적으로 TD 뒤에 JLP와 같은 분기 instuction이 오게 된다.
-
RD m? 메모리 주소 m에 쓰여진 데이터 코드가 지칭한 디바이스로부터 1바이트 데이터를 읽어오는 Instruction -
WD m? 1바이트 데이터를 output device에 쓰기를 하는 Instruction
SIC 예제
Figure 1.2 - Simple data and character movement operation
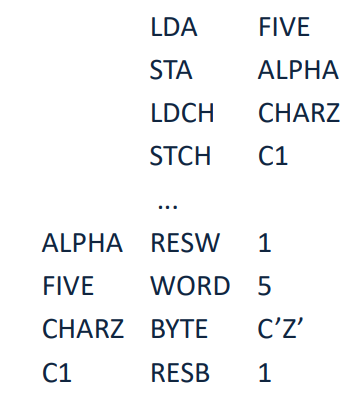
RESW,WORD,BYTE,RESB 와 같은 명령어를 Directive라 한다.
Directive의 역할은 어떤 데이터를 정의를 하거나 메모리 공간을 할당 받는 역할을 한다.
WORD,BYTE: 데이터 크기를 정의하는Directive이다.
RESW,RESB: 메모리 공간을 reservation, 즉 할당받는Directive이다. 바이트 단위로 예약을 받는다. 명령어 뒤에 입력된 숫자 만큼의 크기를 할당받는다.
ALPHA RESW 1
1 word의 크기를 ALPHA에 할당해준다.
FIVE WORD 5
FIVE symbol에 5라는 숫자를 1 word의 크기로 정의한다.
이때 데이터는 Big-Endian 방식으로 저장된다. 아래 그림을 참고하자.
CHARZ BYTE C'Z'
C'Z'에서 C라는 의미는 뒤에 있는 데이터가 Character라는 의미를 갖게 해준다.
CHARZ symbol에 문자 'Z'를 1 Byte의 크기로 정의한다.
C1 RESB 1
1 Byte의 크기를 C1에 할당해준다.
LDA FIVE
3 Byte 데이터 FIVE(5)를 레지스터 A로 가져온다.
STA ALPHA
Register A에 있는 데이터를 ALPHA라는 위치에 저장한다.
LDCH CHARZ
CHARZ 값을 Register A의 가장 오른쪽 Byte에 저장해준다.
STCH C1
Register A의 가장 오른쪽 Byte값을 메모리 주소 C1이라는 위치에 저장한다.
참고 :
SIC에서는 메모리간의 copy가 불가하므로 메모리 -> 레지스터 -> 메모리 순서로
데이터가 이동함을 확인할 수 있다.
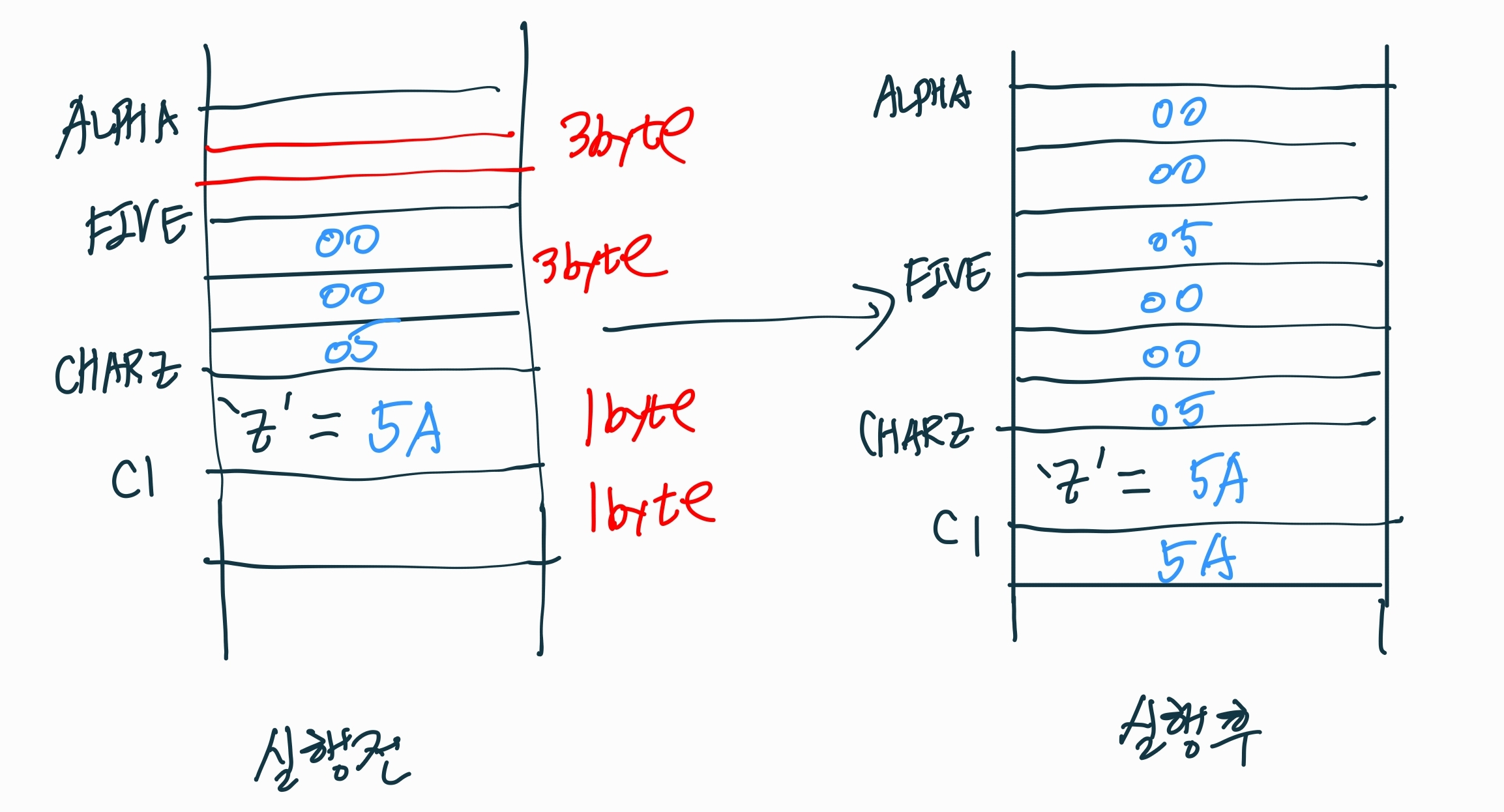
프로그램 실행 전과 후, 메모리의 상태를 다음과 같이 나타내보았다.
이전에 할당만 받은 변수 ALPHA와 C1이 각각 5와 'Z'로 저장된 것을 확인할 수 있다.
Z는 16진수로 변환하면 5A이므로 실제로는 메모리에 5A로 저장이 될 것이다.
Figure 1.3 - Arithmetic operations

ONE WORD 1
ONE이라는 변수에 1이라는 숫자를 1 word의 크기로 정의한다.
ALPHA RESW 1,BETA RESW 1,INCR RESW 1
1 word의 크기를 ALPHA,BETA,INCR에 할당해준다.
실제로 예약한 값을 레지스터에 올리게 된다면 쓰레기 값이 아니라 0이라는 값이 올라가게 된다.
하지만 여기서는 각각 10,20,30이 이전에 할당 되었다고 가정하자.
LDA ALPHA
ALPHA(10)를 레지스터 A로 가져온다.
ADD INCR
INCR(30) 값을 레지스터 A에 저장된 값(10)과 더해준다.
SUB ONE
레지스터 A에 저장된 값(40)에서 ONE(1) 값을 빼준다.
STA BETA
레지스터 A에 저장된 값(39)을 변수 BETA에 저장한다.
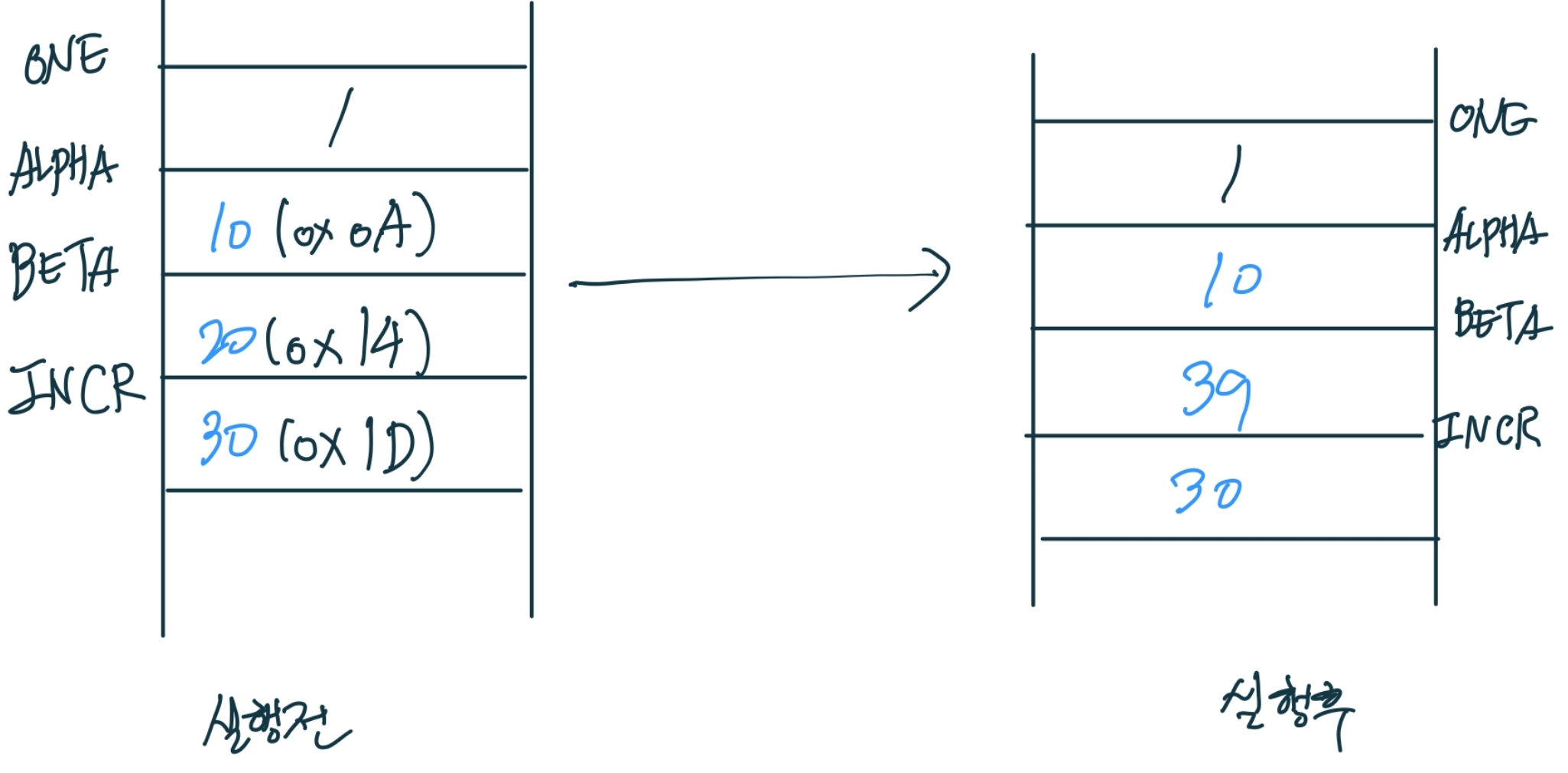
초기에 20으로 저장되있던 변수 BETA가 39로 변경되었음을 확인할 수 있다.
Figure 1.4 - Looping and Indexing operation
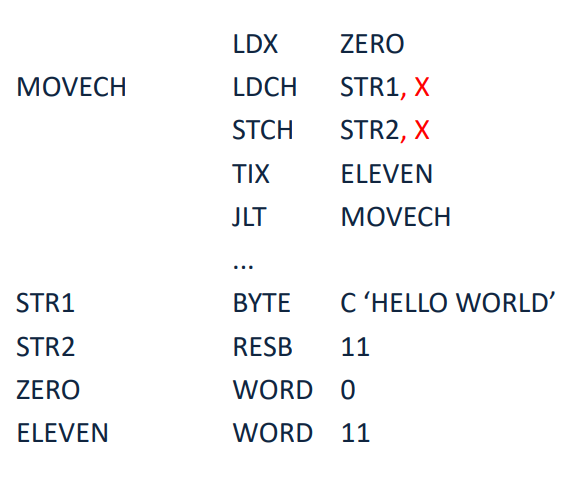
LDX ZERO
ZERO 값을 레지스터 X로 가져온다.
LDCH STR1,X
STR1의 X번째 인덱스 값을 A 레지스터로 가져온다.
STCH STR2,X
A 레지스터의 값을 STR2의 X번째 인덱스에 저장한다.
TIX ELEVEN
X register를 1 증가시키고, X register의 값과 ELEVEN의 값을 비교한 결과를 CC field에 저장한다.
JLT MOVECH
CC field 값이 01 bit이면 MOVECH 매크로로 이동한다.
위의 과정은 STR1에서 STR2로 문자열을 복사하는 과정이다.
예를 들어 초기 X값은 0이고 0번째 인덱스의 값은 H이다.
H가 STR2에 저장되고 현재의 X값이 ELEVEN 값보다 작으므로 MOVECH 매크로로 다시 Jump 할 것이다.
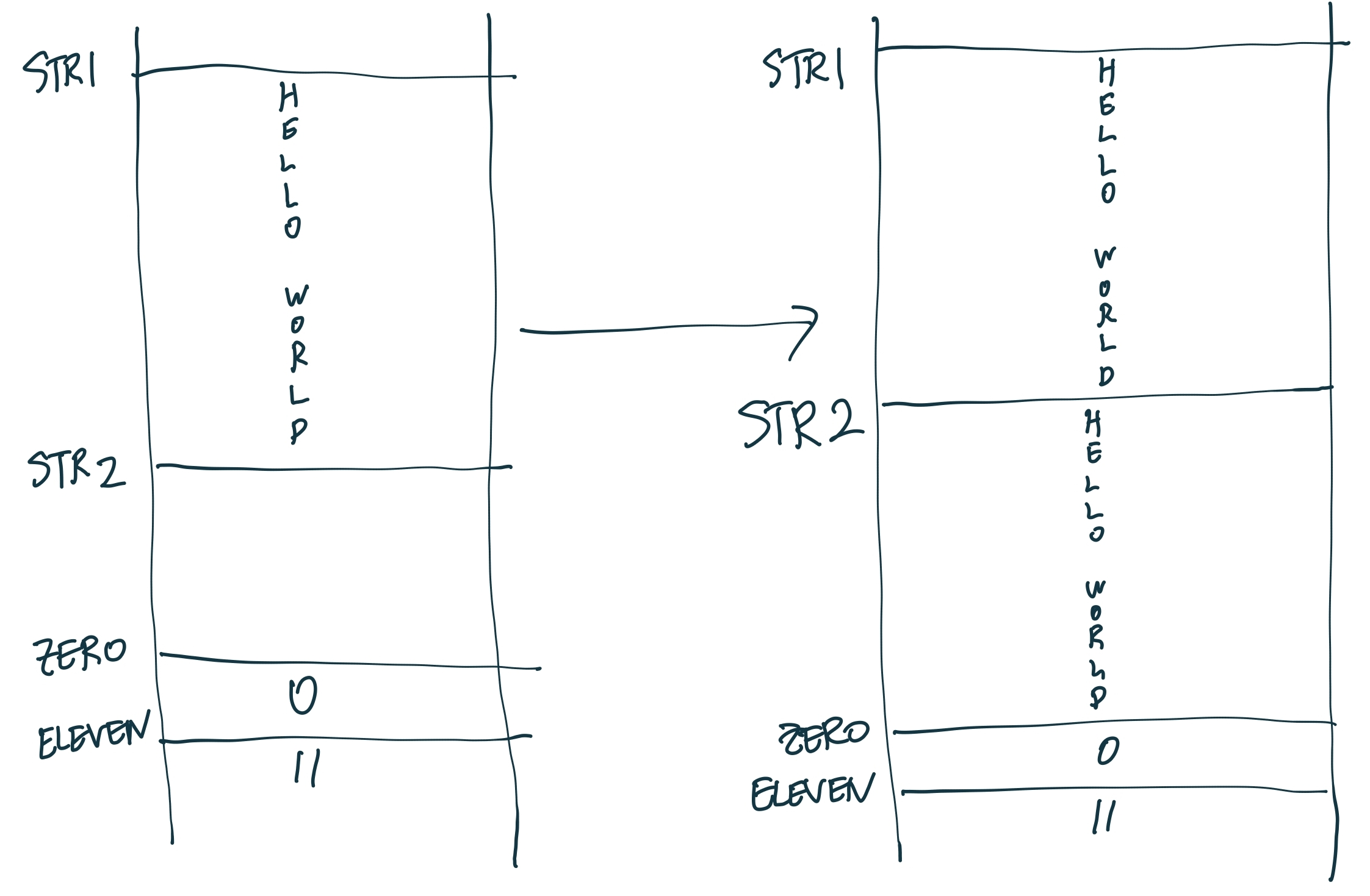
11Byte 할당받은 STR2가 HELLO WORLD로 채워진 것을 확인할 수 있다.
Figure 1.6 - Input and Output operation

TD INDEV
I/O operation을 하기 위해서 TD Instruction으로 현재 I/O device가 연산 준비가 되어있는지 체크를 해야한다.
Input device를 테스트를 해서 준비 상태인지 확인하는 과정
JEQ INLOOP
준비 상태가 되지 않으면 즉, CC field 값이 00 bit 이면 INLOOP 매크로로 다시 이동한다.
준비 상태가 되면 즉 CC field값이 01 bit이면, 아래 instruction을 실행한다.
RD INDEV
1Byte 데이터를 입력받고 레지스터 A의 가장 오른쪽 byte에 저장된다.
STCH DATA
입력받은 데이터를 DATA에 저장한다.
TD OUTDEV
Output device를 테스트를 해서 준비 상태인지 확인하는 과정
JEQ OUTLP
준비 상태가 되지 않으면 즉, CC field 값이 00 bit 이면 OUTLP 매크로로 다시 이동한다.
준비 상태가 되면 즉 CC field값이 01 bit이면, 아래 instruction을 실행한다.
LDCH DATA
변수 DATA 값을 레지스터 A에 올려둔다.
WD OUTDEV
레지스터 A의 가장 오른쪽 1Byte 데이터를 출력한다.
INDEV BYTE X'F5',OUTDEV BYTE X'08'
여기 있는 수(X'F5', X'08')는 unique number를 뜻한다. 특정 device를 가리키는 숫자로 TD,RD,WD로 I/O operation을 수행할 수 있다.
DATA RESB 1
1Byte의 크기를 DATA에 할당해준다.
SIC/XE Architecture
-
Memory
1 MB (2^20 bytes)까지 이용 가능.
전체 메모리 주소 공간을 나타내기 위해서 20비트의 공간이 필요하다. -
Registers
- 기존 5개 레지스터 + 4개의 레지스터가 추가 되었다.
4개의 레지스터 (B,S,T,F)
B :Base relative addressing를 위한 레지스터 (24bit)
S, T: 특별한 용도는 없음, 저장용을 위한 레지스터 (24bit)
F :Floating-point를 위한 레지스터 (48bit)
- 기존 5개 레지스터 + 4개의 레지스터가 추가 되었다.
-
Data Formats
48-bit floating-point data type이 추가 되었다.
Instuction Formats
-
Format 1 : No Memory Reference (1byte)
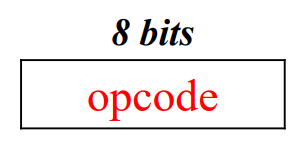
- operand 없이 연산만 수행한다.
- 메모리 접근이 필요 없다.
-
Format 2 : No Memory Reference (2bytes), for register operations
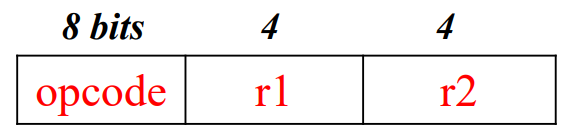
- 레지스터 마다 unique한 넘버를 가지고 있는데
r1,r2자리에 들어간다. - 레지스터에 저장된 값으로 연산 진행한다.
- 레지스터 마다 unique한 넘버를 가지고 있는데
-
Format 3 : Relative addressing (3bytes), e=0 일때
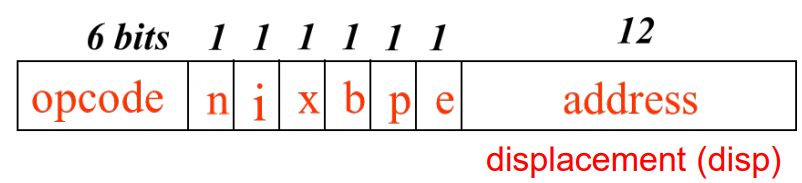
- 6개의
opcode bit, 6개의flag bit, 12개의address field가 존재한다.
- 6개의
참고 : opcode를 8비트가 아닌 6비트를 사용해도 무방한 이유는 SIC나 SIC/XE에서 사용되는 opcode의 마지막 2개의 비트는 0으로 끝난다는 특징을 가지고 있습니다. 따라서 앞의 6비트만 사용해도 무관하다.
-
Format 4 : Address field extension to 20 bits (4bytes) e=1 일때

- SIC/XE 소개에서 20비트의 address field가 필요하다는 것을 확인할 수 있다.
Addressing Modes
-
Relative addressing modesfor Format 3- b=1, p=0일때, Base relative addressing mode이다.
- TA= (B) + disp/addr
- b=0, p=1일때, PC relative addressing mode이다.
- TA= (PC) + disp/addr
- b=1, p=0일때, Base relative addressing mode이다.
-
Direct addressing modefor Format 3 & 4- b = p = 0일때 Direct addressing mode이다.
- TA = disp/addr
- cf) b=p=1일 때는 불가능한 경우이다.
- b = p = 0일때 Direct addressing mode이다.
Relative,Direct addressing mode는indexed addressing와 함께 사용 가능하다.
즉 x=1일때, 기존에 계산한 TA 값에다가 X 레지스터에 저장된 값을 더해주면 된다.
format 3과 4에서 n과 i 비트에 따라 TA의 사용 방식이 달라진다.
- n=0, i=1일때 immediate addressing
- 메모리 참조는 하지 않고 TA는 operand value로 쓰인다.
- n=1, i=0 일때 indirect addressing
- i=0, n=0 일때 simple addressing for SIC.
» It means that b, p, and e are used as address fields (상위호환) - i=1, n=1 일때 simple addressing for SIC/XE
Immediate,Indirect addressing mode는indexed addressing와 함께 사용 할 수 없다.
Instruction Set
SIC 버전의 모든 instructions이 포함되어 있다.
- Load and Store registers:
LDB, STB, etc.- 추가된 4개의 레지스터의 경우에도 Load와 Store이 가능하다.
- Floating-point arithmetic operations:
ADDF, SUBF, MULF, DIVF - Register간 instructions:
RMO, ADDR, SUBR, MULR, DIVR - Supervisor call:
SVC
App이 동작하다 보면OS에서 제공하는 서비스를 이용해야 할 때가 있다.
OS에게 요청하는 행위를 즉 interrupt를 일으키는 행위를SVC라고 한다.
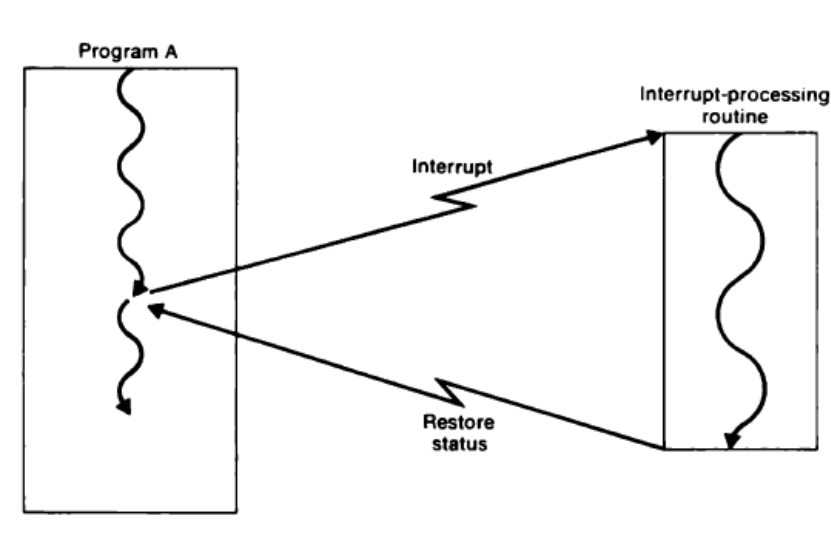
Input and Output
- CPU가 다른 instruction을 수행하더라도 I/O channel은 별도로 사용가능하다.
- I/O channels이란 CPU 대신에 I/O operation을 수행할 simple processor이다.
- computing과 I/O를 동시에 처리함에 따라 효율적이게 된다.
- I/O channel에서 사용하는 Instruction은
SIO(start),TIO(test),HIO(halt) 이 있다.
SIC/XE 예제
Memory
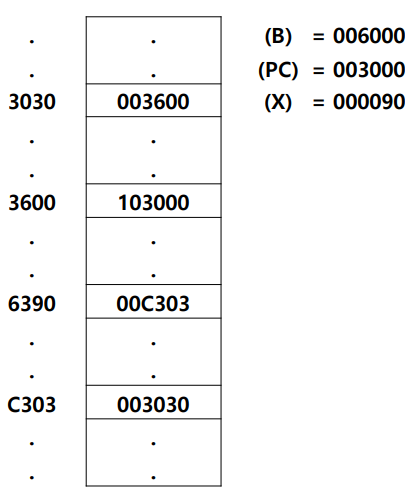
Binary Code

6개의 binary code를 하나씩 살펴보자 위에서 아래까지 1번(032600)부터 6번(0310C303)이라 지칭하겠다.
일단 6개의 binary code의 opcode는 모두 0이므로 LDA instruction 임을 알 수 있다. LDA는 레지스터 A에 어떤 값을 올려놓는 일을 나타내므로 우리가 여기서 확인해야 할 것은 Target Address와 register A에 올라갈 value 값이다.
- 032600
- n=1, i=1 이므로
SIC/XE Simple addressing이다. - b=0, p=1 이므로
PC relative addressingmode이다. - TA = 3000(
PC) + 600(disp/address) = 3600이다. - 메모리 3600에 저장된 값 103000이 A 레지스터에 올라간다.
- 03C300
- n=1, i=1 이므로
SIC/XE Simple addressing이다. - b=1, p=0 이므로
Base relative addressingmode이다. - x=1 이므로
indexed addressing도 같이 병행하여 사용한다. - TA = 6000(
Base) + 300(disp/address) + 90(x) = 6390이다. - 메모리 6390에 저장된 값 C303이 A 레지스터에 올라간다.
- 022030
- n=1, i=0 이므로
Indirect addressing이다. - b=0, p=1 이므로
PC relative addressingmode이다. - TA = 3000(
PC) + 30(disp/address) = 3030이다. - 메모리 3030에 저장된 값은 3600이다. 이때 메모리 3600이 가리키는 값 103000이 A 레지스터에 올라간다. 한번 더 참조 한다. 이것이
Indirect이다.
- 010030
- n=0, i=1 이므로
immediate addressing이다. - 따라서 Target address를 계산할 필요 없이 바로
disp/address의 값인 30이 A 레지스터에 올라간다.
- 003600
- n=0, i=0 이므로
SIC Simple addressing이다. - b=0, p=1 이므로
PC relative addressingmode이다. - TA = 3000(
PC) + 600(disp/address) = 3600이다. - 메모리 3600에 저장된 값 103000이 A 레지스터에 올라간다.
- 0310C303
- n=1, i=1 이므로
SIC/XE Simple addressing이다. - e=1 이므로
Format 4형식인것을 확인할 수 있다. - b=0, p=0 이므로
Direct addressingmode이다. - TA = C303(
disp/address) 이다. - 메모리 C303에 저장된 값 3030이 A 레지스터에 올라간다.
Assembly Language Statements
Instructions: 런타임에 실행되고, 어셈블러로 하나 이상의 바이트의 object 코드로 변환해준다.- 각 instruction은 하나의 operation에 매칭된다.
Directives: 어셈블러에게 제공하는 command- object code를 해석하는 것은 아니다. 영향을 주지 않는다. 해석의 개념이 아니라 정의의 개념이다.
» e.g., WORD directive generat s one-word integer constant.
- object code를 해석하는 것은 아니다. 영향을 주지 않는다. 해석의 개념이 아니라 정의의 개념이다.
Macro: 긴 코드를 짧은 코드로 치환하는 역할.
SIC/XE에서 제공하는 Immediate addressing을 사용하면 장점은?
- 사용하는 메모리 공간을 줄어든다.
- 메모리 접근의 횟수가 줄어든다.
Actual Machine Architecture
CISC (Complex Instruction Set Computers)
- Large and complicated instruction sets provided
- Several different instruction formats and length
- Many different addressing modes
- Implementation in h/w tends to be complex
복잡하고 다양한 instruction이 있어 쉽게 코딩할 수 있다.
RISC (Reduced Instruction Set Computers)
- Small number of machine instructions, instruction formats, and addressing modes
- A standard, fixed instruction length, and single-cycle execution
- Advantages:
- 칩 구현이 쉽다.
- faster and less expensive processor development
- greater reliability, faster instruction execution times
simple한 instruction으로 복잡한 연산을 요구한다는 특징을 가진다.
단점: 사용할 수 있는 instruction 종류가 제한적이라 복잡한 내용을 구현하기 위해서는 여러개의 instruction을 사용해야 한다.
결국 누가 승자인가? RISC
simple한 instruction을 사용하더라도 빠르게 돌리는 것이 이점이다.
SIC는 RISC, SIC/XE는 CISC
SVC 알아야 하고, SIO 채널을 왜 사용하는지 기억하기
instruction, directive, macor 의 의미가 무엇인지!!
cisc, risc 알고 예제 문제 확인
