데이터베이스에는 인덱스라는 것을 통해 테이블 검색속도를 향상시킬 수 있다
그렇다면 인덱스란 뭘까?
Index란?
인덱스란, 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색속도를 향상시키기 위한 자료구조이다.
또한 인덱스는 항상 정렬된 상태를 유지하기 때문에 원하는 값을 탐색하는데는 빠르지만, 새로운 값을 추가하거나 삭제, 수정하는 경우에는 쿼리문 실행 속도가 느려지게 된다. 결론적으로 DBMS에서 인덱스는 데이터의 저장 성능을 희생하고 그 대신 읽기 속도를 높이는 기능이다.
SELECT 쿼리 문장의 WHERE 조건절에 사용되는 칼럼이라고 전부 인덱스로 생성하면 데이터 저장 성능이 떨어지고 인덱스의 크기가 비대해져서 오히려 역효과가 발생할 수 있다.
Index의 성능과 역효과
SELECT 쿼리의 성능을 월등히 향상시킬 수 있는 INDEX는 항상 좋은것인가? 앞에서도 말했듯이 인덱스는 저장성능을 희생하고 읽기속도를 높이는 기능이다. 만약 INSERT를 한다고 가정해보자. INSERT의 경우 INDEX에 대한 데이터도 추가해야 하므로 그만큼 성능의 손실이 발생하게 된다. 또한, DELETE의 경우 INDEX에 존재하는 값은 삭제하지 않고 사용 하지 않는다는 표시로 남게된다. 즉, ROW의 수는 그대로 되게 된다.
DELETE시에 ROW가 그대로 있다는 말은 결국 실제 테이블엔 10만건의 데이터가 존재할 뿐이지만, 인덱스에는 100만건, 1000만건의 데이터가 삭제되지 않고 누적된다는 것을 의미한다. 이렇게 될 경우 인덱스는 제 역할을 하지 못하게 된다. 더군다나 UPDATE의 경우 DELETE되고 새로운 값이 INSERT 되는 것이기 때문에 두가지 문제가 함께 발생하게 된다.
여기서 더 중요한 점은 컬럼을 이루고 있는 데이터의 형식에 따라서도 인덱스의 성능이 차이가 나게 된다. 이름, 나이, 성별 세 가지의 필드를 갖고 있는 테이블을 생각해보자. 이름은 온갖 경우의 수가 존재하게 되며, 나이는 INT 타입을 가질 것. 성별은 남,녀 두가지 경우에서만 데이터가 존재하게 된다는 것을 예상할 수 있음. 이 경우 어떤 컬럼에 인덱스를 생성하는 것이 효율적일까?
세 가지 경우를 확인해보자
1. 이름 필드
- 이름은 다양한 값을 가질 수 있고, 검색이나 정렬이 자주 발생할 수 있다.
- 인덱스를 생성하면 이름을 이용한 검색이 빨라지게 되므로 효율적임
- 나이 필드
- 나이는 일반적으로 연속적인 범위를 갖게 된다. 나이에 대한 인덱스를 생성하면 해당 범위 내에서 검색이 빨라질 수 있다.
- 그러나, 나이의 경우 중복된 값이 많을 수 있기에 인덱스를 통한 선택도가 낮아지는 원인이 됨.
- 성별 필드
- 성별의 경우 두 가지 값을 갖기에 선택도가 낮고 읽기 성능또한 크게 기대하기 어렵다.
Index 자료구조
그렇다면 DBMS는 인덱스를 어떻게 관리하고 있을까?
B-Tree
B-Tree는 데이터의 검색시간을 단축하기 위한 자료구조이다. 루트노드, 내부노드, 리프노드로 구성되어있고 리프노드는 모두 같은 레벨에 존재하는 균형트리이다.
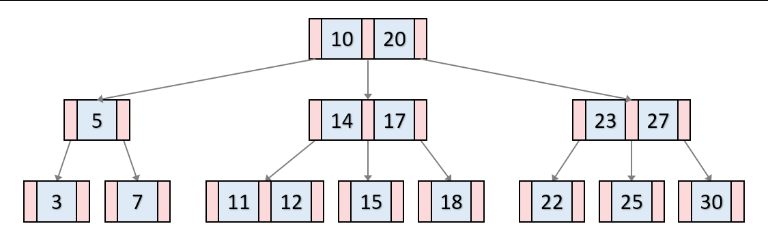
B-tree의 각 노드는 키 값과 포인터를 가진다. 키 값은 오름차순으로 저장되고 키 값 좌우에 있는 포인터는 각각 키 값보다 작은 값을 가진 다음 노드를 가리킨다. 따라서 키 값을 비교하여 다음 단계의 노드를 쉽게 찾기 가능하다.
Hash
컬럼의 값으로 해시 값을 계산해서 인덱싱한다. 매우 빠른 검색을 지원하지만, 값을 변형해서 인덱싱하기 때문에 특정 문자로 시작하는 값으로 검색을 하는 전방 일치와 같이 값의 일부만으로 검색하고자 할 때는 해시 인덱스의 사용이 불가능하다. 주로 메모리 기반의 데이터베이스에서 주로 사용한다.
Primary Index VS. Secondary Index
Primary Index
기본 키를 기반으로 생성되는 인덱스. 기본 키는 해당 테이블의 각 레코드를 고유하게 식별하는 역할을 하는데, 이 기본 키에 대한 인덱스가 Primary Index이다.
특징
- 고유성 보장 : 주 키는 각 레코드를 고유하게 식별하기 때문에, 고유성이 보장된다.
- 빠른 검색 : 해당 테이블에서 특정 기본 키값을 가진 레코드를 빠르게 검색할 수 있음
- 기본 키 정렬 : 테이블의 레코드가 기본 키 값에 따라 물리적으로 정렬될 수 있다. 이를 통해 범위 쿼리나 정렬 작업에 대한 성능 향상을 기대할 수 있음
Secondary Index
기본 키 외의 다른 컬럼에 대한 인덱스.
특징
- 검색 및 정렬 : 해당 인덱스의 컬럼에 대한 검색 및 정렬 작업이 빠르게 수행 가능
- 고유성 보장 X : 기본 키에 대한 인덱스가 아니므로 중복될 수 있음
- 데이터 정렬 : Secondary Index를 사용하면 해당 인덱스의 컬럼을 기준으로 테이블이 물리적으로 정렬될 수 있음
- 복수 생성 가능 : 기본키 Index와 달리 여러개의 Index 생성 가능
Composite Index
하나의 인덱스가 여러 개의 컬럼으로 이뤄져 있는 것
주의점
인덱스로 설정하는 필드의 속성이 중요하다. title, author 이 순서로 인덱스를 설정한다면 title 을 search 하는 경우, index 를 생성한 효과를 볼 수 있지만, author 만으로 search 하는 경우, index 를 생성한 것이 소용이 없어진다. 따라서 SELECT 질의를 어떻게 할 것인가가 인덱스를 어떻게 생성할 것인가에 대해 많은 영향을 끼치게 된다.
References
https://velog.io/@emplam27/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C-%EC%95%8C%EC%95%84%EB%B3%B4%EB%8A%94-B-Tree
https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/main/Database
