Kafka Consumer
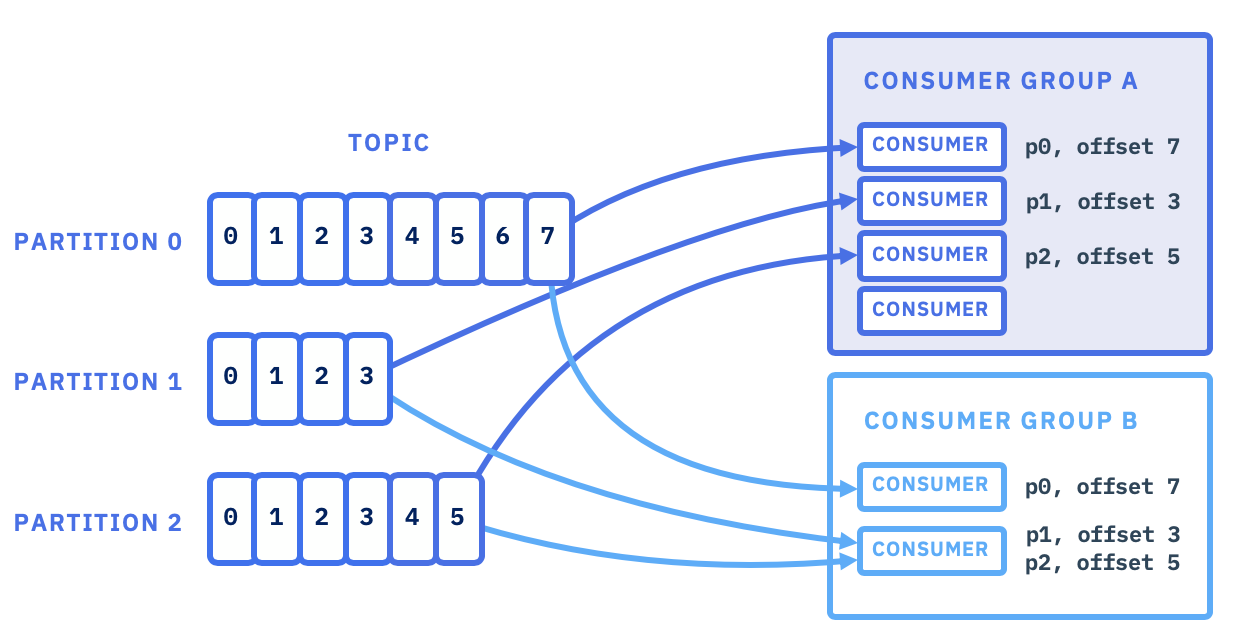
Kafka에서는 데이터가 Topic이라는 단위로 관리되며, Consumer는 Broker에서 해당 Topic에 쌓인 메시지를 읽어와 처리한다.
하지만 모든 Consumer는 Consumer Group이라는 그룹에 속해야 하고, 이 그룹 내에서 파티션을 분배받아 처리하는 방식으로 동작한다.
Consumer Group과 Partition 분배
Consumer Group: Consumer들이 속한 그룹으로 각 Consumer는 그룹 내에서 특정 파티션을 나누어 읽는다.
같은 그룹에 속한 Consumer는 서로 다른 파티션을 할당받는다.
Partition: Topic은 여러 파티션으로 나뉘고, 메시지들은 각 파티션에 저장된다.
Consumer Group 내에서는 각 Consumer가 하나의 파티션을 담당해 중복되지 않도록 메시지를 처리한다.
Consumer 로직
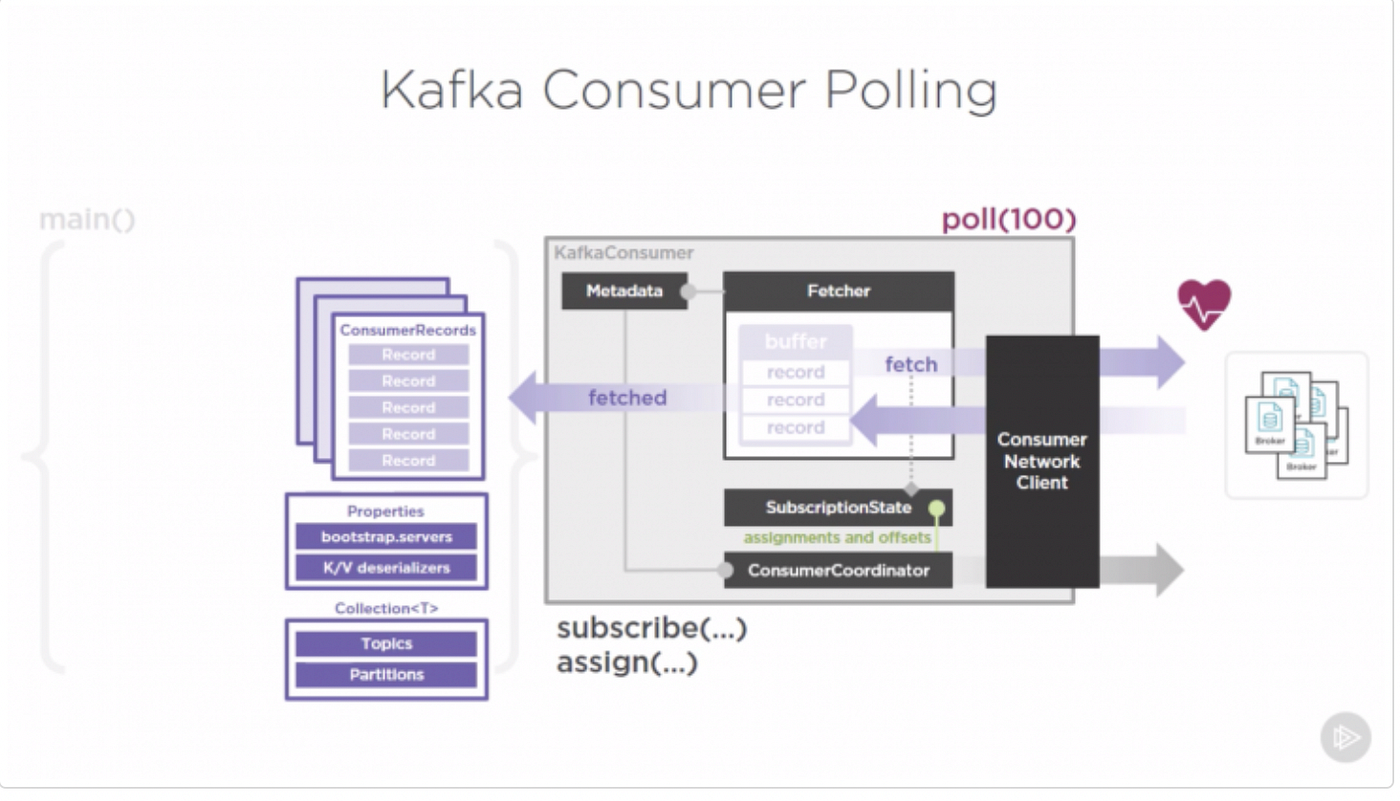
Kafka Consumer는 데이터를 구독하고, 브로커로부터 메시지를 가져와 처리 후 오프셋을 커밋하는 순서로 동작한다.
기본 흐름은 다음과 같다.
subscribe()
Consumer가 구독할 토픽을 지정한다.
Consumer Group 내 여러 Consumer가 있을 경우 파티션은 자동으로 분배된다.
poll()
브로커에서 데이터를 읽어오는 핵심 메서드이다.
Fetcher가 브로커에 데이터를 요청하고, 내부 큐(Linked Queue)에 데이터를 저장한다.
poll()은 이 큐에서 데이터를 가져와 ConsumerRecords 형태로 반환한다.
데이터가 없을 경우 지정된 시간만큼 대기 후 반환한다.
commit()
Consumer가 처리 완료한 오프셋을 __consumer_offsets 토픽에 기록한다.
다음 실행 시 이 오프셋 이후부터 데이터를 읽는다.
Consumer 구성요소
KafkaConsumer는 다음과 같은 주요 내부 컴포넌트로 구성되어 있다.
| 구성요소 | 역할 |
|---|---|
| Fetcher | 브로커로부터 메시지를 가져와 내부 큐에 저장하고, poll() 호출 시 반환 |
| ConsumerNetworkClient | Fetcher가 브로커와 비동기 통신을 수행할 때 사용하는 네트워크 I/O 담당 |
| SubscriptionState | Consumer가 구독 중인 토픽, 파티션, 오프셋 상태 관리 |
| ConsumerCoordinator | Consumer Group의 리밸런싱과 오프셋 커밋 담당 |
| Heartbeat Thread | Group Coordinator에 주기적으로 하트비트를 보내 Consumer의 생존 상태를 보고 |
Heartbeat Thread는 일정 시간 동안 응답이 없으면 Consumer를 그룹에서 제거하고 리밸런싱을 발생시킨다.
poll() & Fetcher
poll()은 Fetcher와 ConsumerNetworkClient가 함께 동작하는 핵심 루프 구조다.
Fetcher는 데이터를 직접 가져오는 역할을 하고, ConsumerNetworkClient는 브로커와의 비동기 통신을 담당한다.
poll() 호출 시 내부 동작은 다음과 같다.
- Fetcher가 Linked Queue에서 데이터를 확인한다.
- 데이터가 존재하면 즉시 반환한다.
- 데이터가 없을 경우, ConsumerNetworkClient에 브로커로부터 Fetch 요청을 위임한다.
- ConsumerNetworkClient는 비동기로 브로커의 데이터를 가져와 Linked Queue에 저장한다.
- Fetcher는 새로 들어온 데이터를 가져와 ConsumerRecords로 반환한다.
- 데이터가 충분하지 않으면 지정된 시간(ms)만큼 대기 후 반환한다.
이 구조는 비동기 I/O 기반의 fetch – poll 파이프라인으로 동작하며,
Fetcher와 ConsumerNetworkClient가 상호 협력하여 Consumer의 처리 지연을 최소화한다.
Fetcher 설정
| 파라미터 | 설명 |
|---|---|
fetch.min.bytes | 브로커가 반환할 최소 데이터 크기. 데이터가 이 크기 이상 쌓일 때만 전송 |
fetch.max.wait.ms | fetch.min.bytes만큼 데이터가 쌓이지 않을 때 최대 대기 시간 |
fetch.max.bytes | 한 번에 가져올 수 있는 전체 데이터의 최대 크기 |
max.partition.fetch.bytes | 파티션별로 가져올 수 있는 최대 데이터 크기 |
max.poll.records | 한 번의 poll() 호출로 반환할 최대 레코드 수 |
Fetch 동작 예시
KafkaConsumer.poll(1000) 수행 시 동작은 다음과 같다.
- 가져올 데이터가 없으면 지정된 1000ms 동안 대기 후 반환
- 과거 데이터를 많이 가져와야 할 경우
max.partition.fetch.bytes단위로 배치 크기를 설정 - 최신 offset 데이터를 가져올 때는
fetch.min.bytes만큼 데이터를 모아 반환- 데이터가 부족하면
fetch.max.wait.ms동안 대기 후 반환
- 데이터가 부족하면
- 오랜 과거 offset 데이터를 읽을 경우 최대
max.partition.fetch.bytes만큼 읽고 반환 - 최신 offset에 도달하면
max.partition.fetch.bytes에 도달하지 않아도 반환 - 전체 데이터량은
fetch.max.bytes로 제한 - Fetcher가 큐에서 반환하는 레코드 수는
max.poll.records로 제한
Fetcher는 이 과정에서 ConsumerNetworkClient를 통해 브로커와 통신하며,
Linked Queue에 데이터를 비동기로 적재하고 poll() 호출 시 이를 반환한다.
auto.offset.reset
Consumer가 처음 토픽에 접근하거나, 기존 오프셋이 손실된 경우 어디서부터 데이터를 읽을지를 지정하는 설정이다.
| 설정값 | 설명 |
|---|---|
earliest | 가장 오래된 offset부터 데이터를 읽는다. |
latest | 가장 최근 offset 이후부터 데이터를 읽는다. |
이미 Consumer Group의 오프셋이 존재할 경우 이 설정은 적용되지 않는다.
__consumer_offsets 토픽에서 오프셋을 찾지 못할 때만 사용된다.
실습
https://github.com/develkkm/kafka-from-0/tree/kafka-core/consumers
