0부터 시작하는 Kafka
1.Kafka란

Kafka는 분산 환경에서 대량의 데이터를 실시간으로 처리하기 위해 만들어진 메시징 플랫폼이다.단순히 메시지를 전달하는 큐를 넘어, 데이터 스트림의 저장소이자 중심 허브 역할을 한다.
2.Kafka - Producer 1
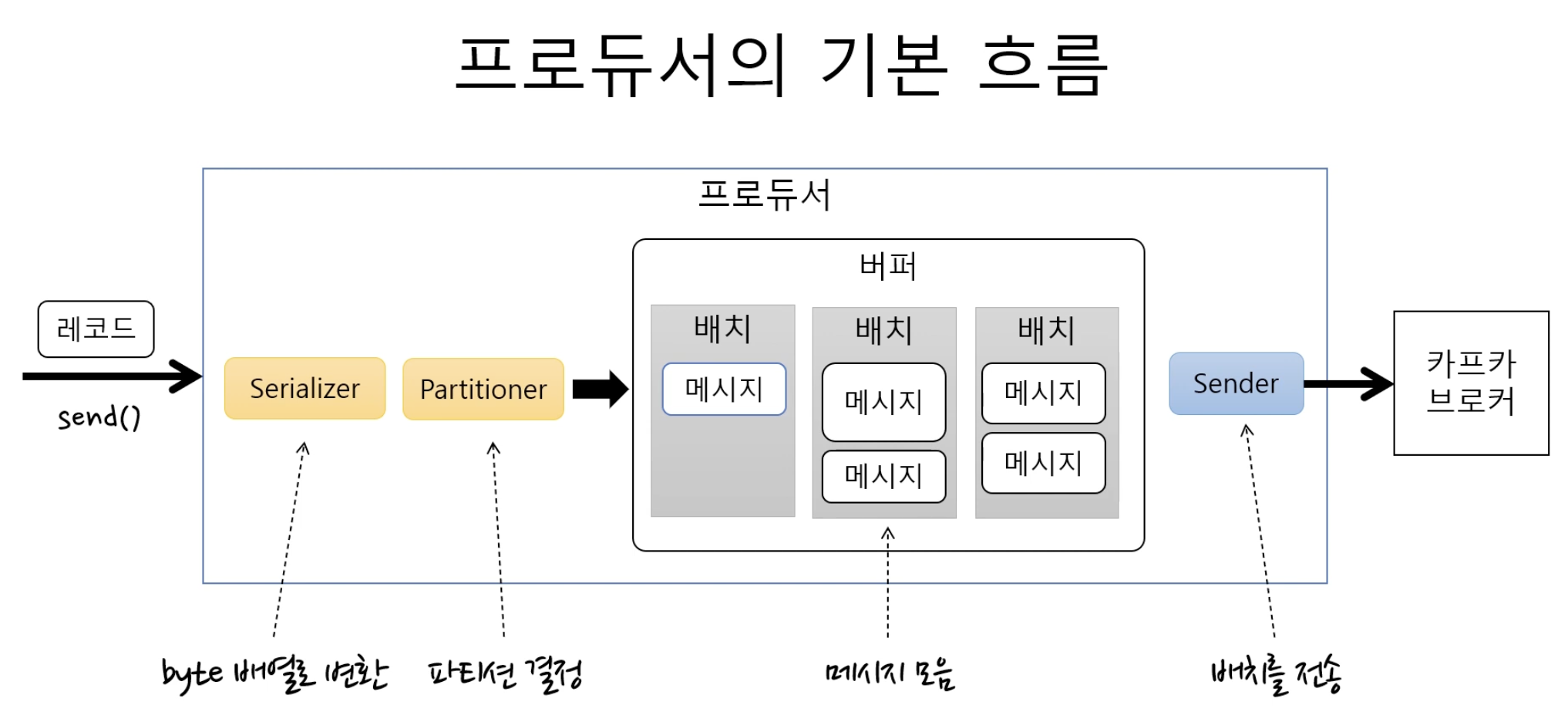
Kafka Producer는 데이터를 브로커로 전송하는 역할을 한다.하지만 단순히 “보낸다” 수준이 아니라, 내부적으로 여러 단계를 거쳐 효율적으로 데이터를 처리한다.
3.Kafka - Producer 2
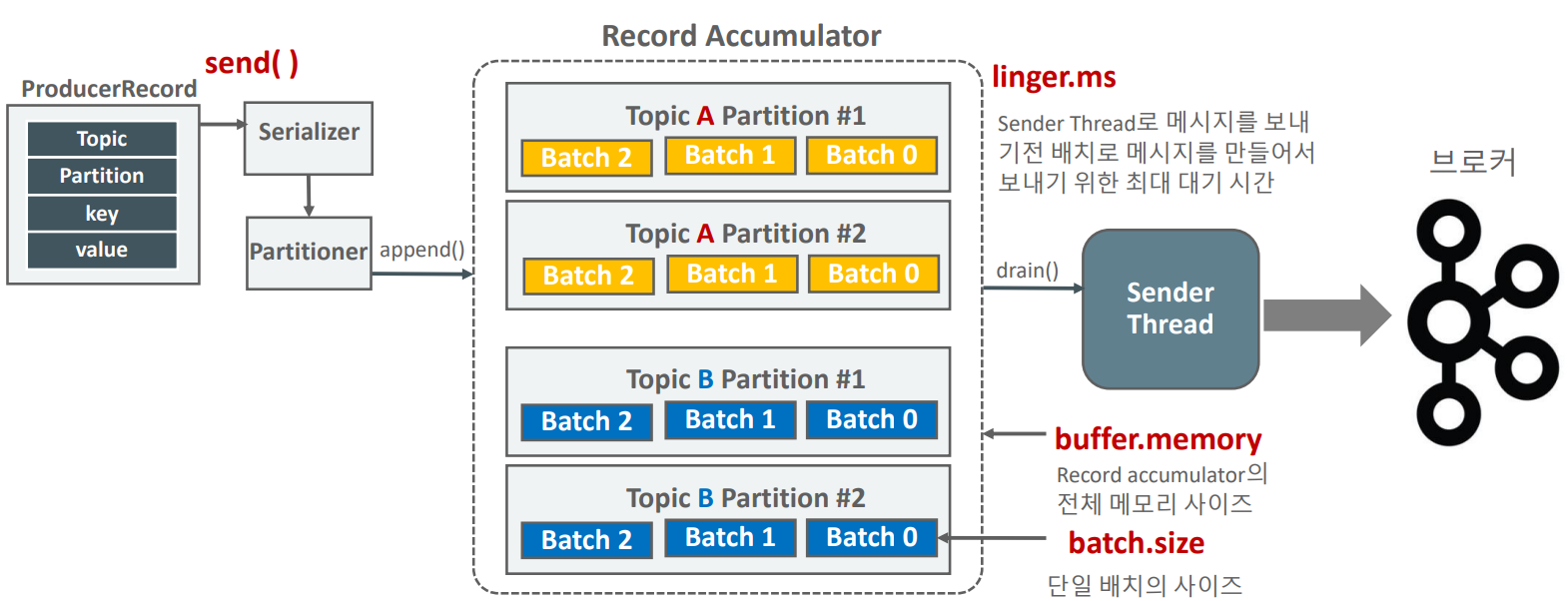
이전 글에서는 Kafka Producer의 동작 원리와 비동기 전송 구조를 살펴봤다.이번 글에서는 Producer가 데이터를 어떻게 안전하게 전송하고, 메시지 손실이나 중복을 방지하는지를 중심으로 정리한다.
4.Kafka - Consumer 1
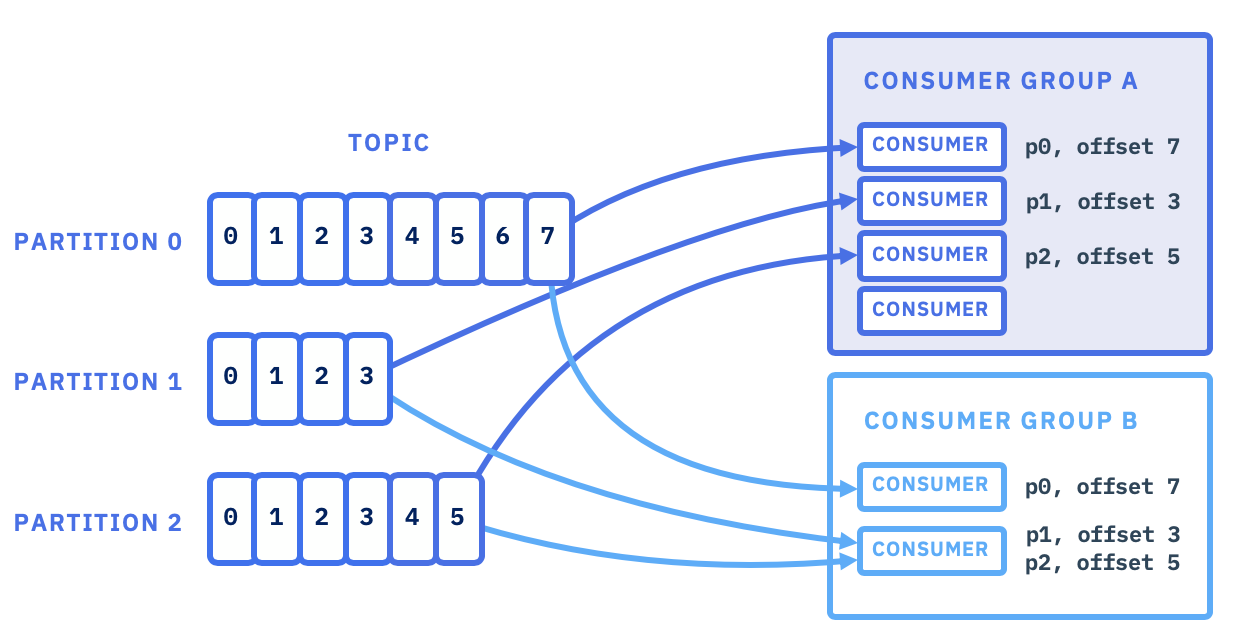
Kafka에서는 데이터가 Topic이라는 단위로 관리되며, Consumer는 Broker에서 해당 Topic에 쌓인 메시지를 읽어와 처리한다.
5.Kafka - Consumer 2
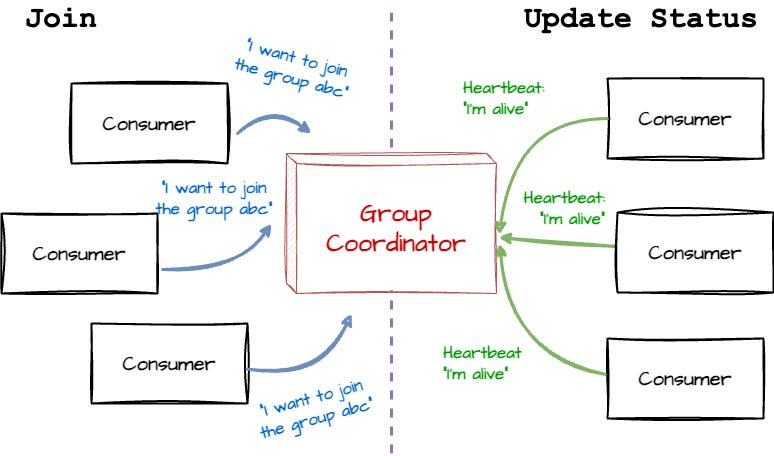
GroupCoordinator는 Consumer Group을 관리하고 그룹 내 Consumer들의 참여·이탈·세션 유지·리밸런싱 등을 담당하는 Broker 단위의 컴포넌트이다.
6.Kafka - Consumer 3
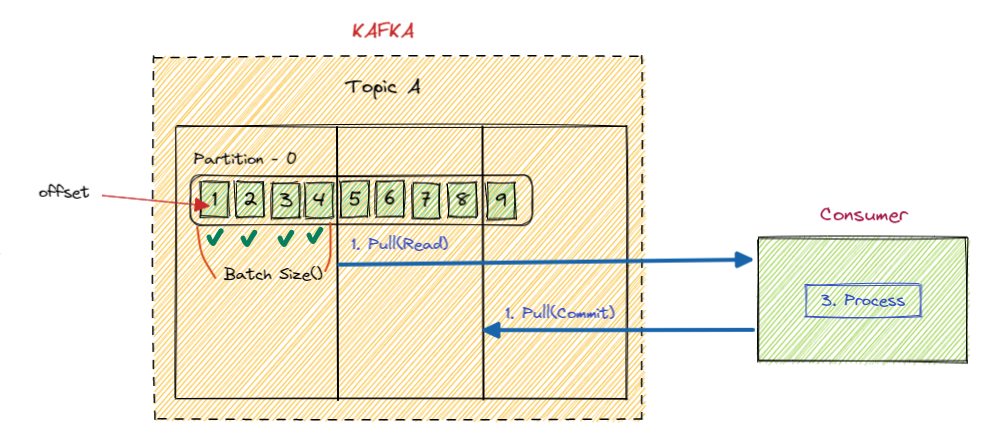
Kafka Consumer는 데이터를 읽은 후, “어디까지 읽었는지”를 표시하기 위해 offset commit을 수행한다.
7.Kafka - Multi Node Cluster
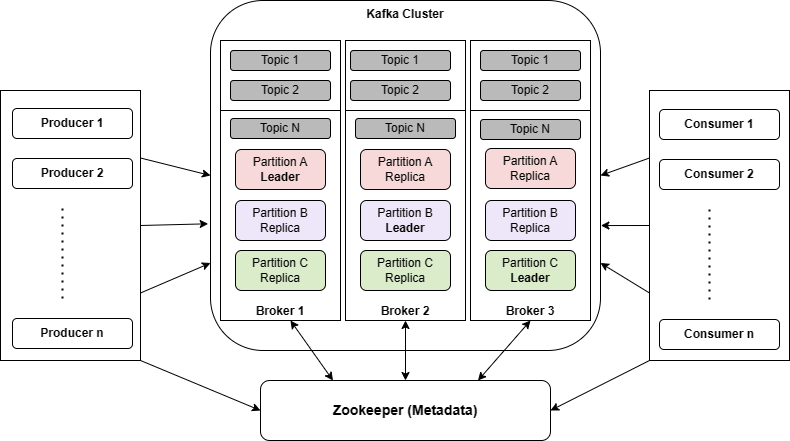
Kafka cluster는 여러 대의 Broker Node로 구성되어 있다.
8.Kafka - Log Segment
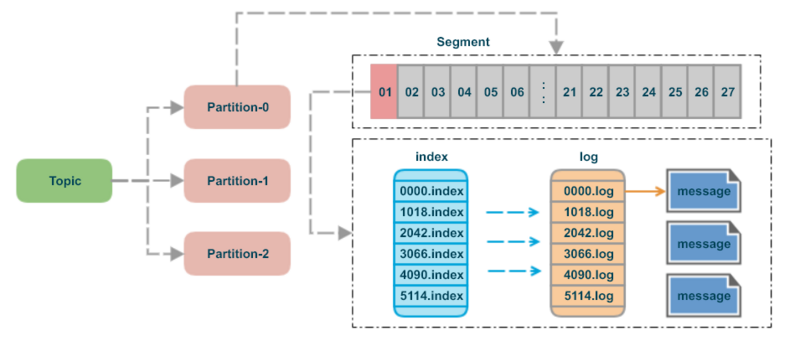
Kafka는 데이터를 파일 시스템에 저장할 때, 각 파티션을 여러 개의 segment로 나누어 관리한다.
9.Kafka - Connect
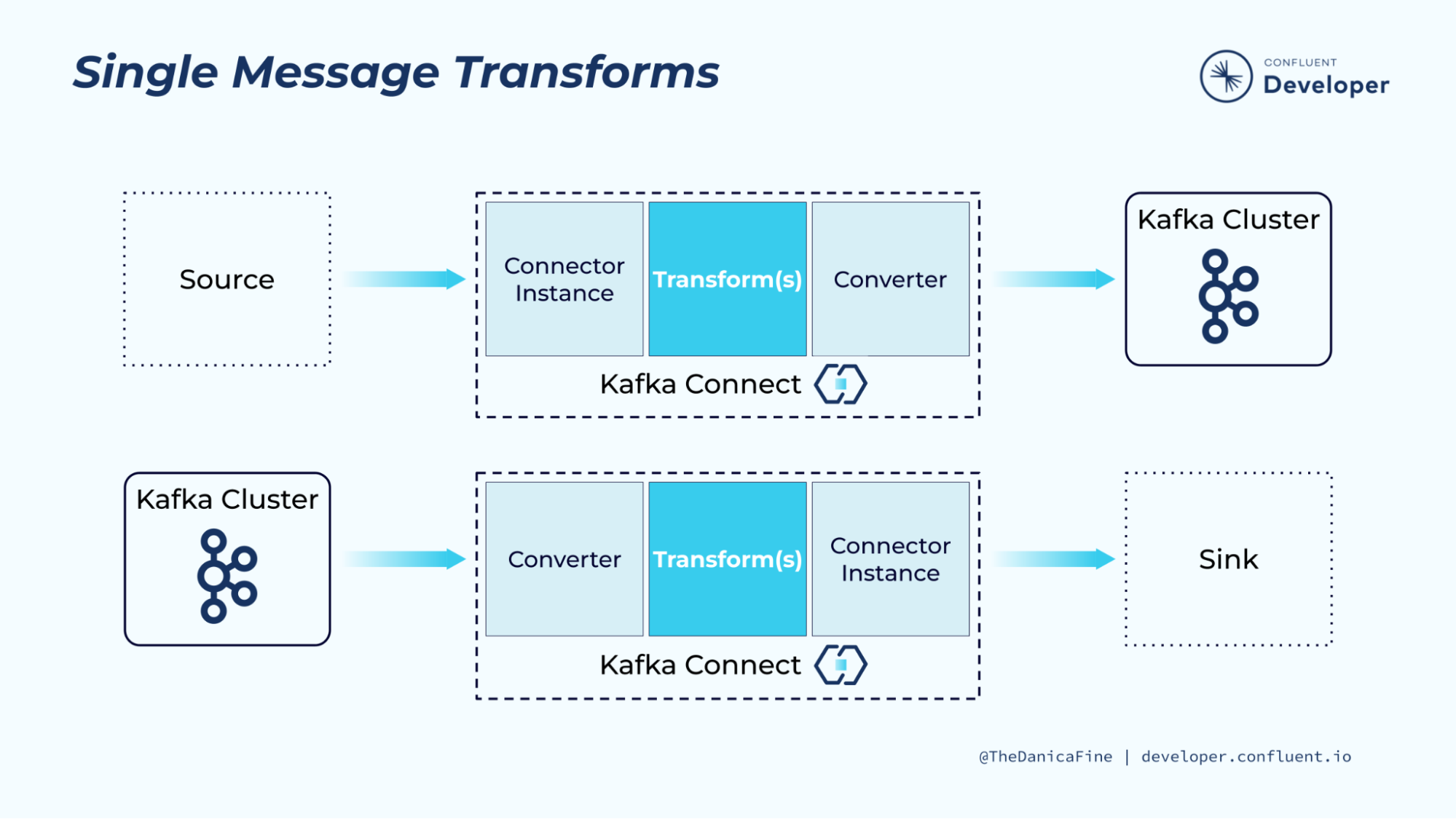
Kafka Connect는 Kafka와 외부 시스템 간의 데이터를 실시간으로 연동하기 위한 표준화된 프레임워크다.
10.Kafka - JDBC Source Connector
JDBC Source Connector는 RDBMS의 데이터를 Kafka로 전송하기 위해 JDBC Driver를 활용하여 DB에 접속하고 데이터를 추출한 뒤 Kafka로 메시지를 생성하는 Source Connector다.
11.Kafka - JDBC Sink Connector
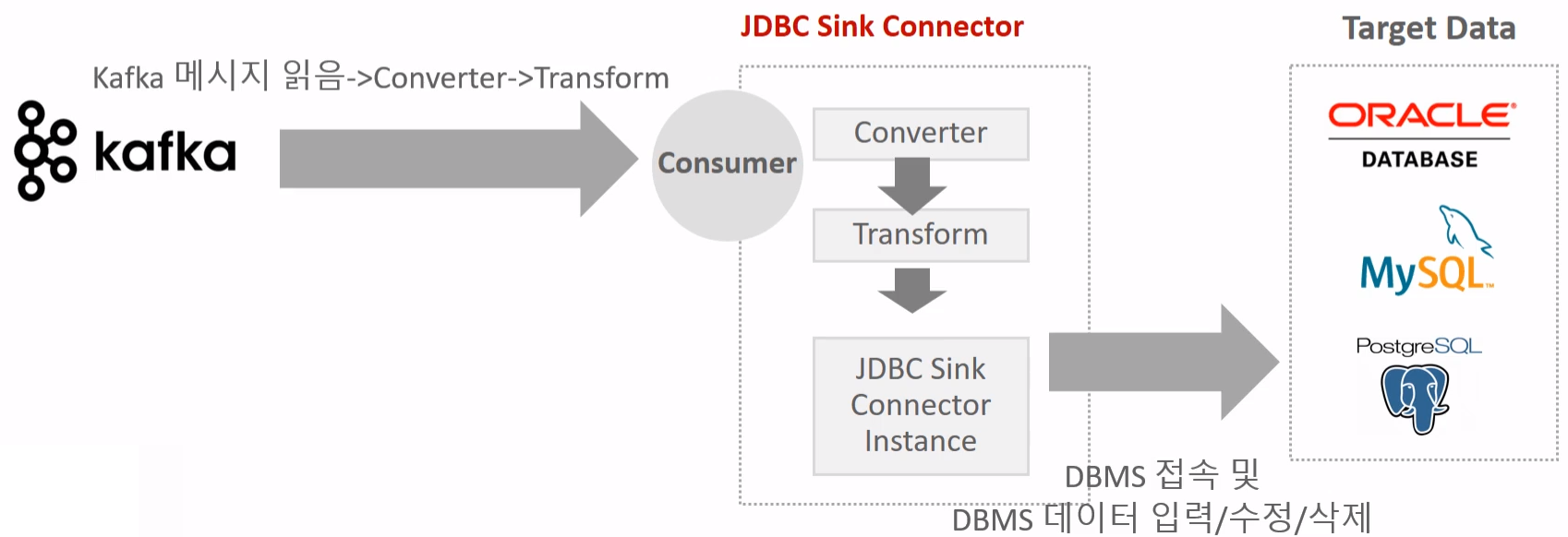
JDBC Sink Connector는 Kafka의 메시지를 RDBMS에 적재하기 위한 Sink Connector다.
12.Kafka - Debezium CDC Connector
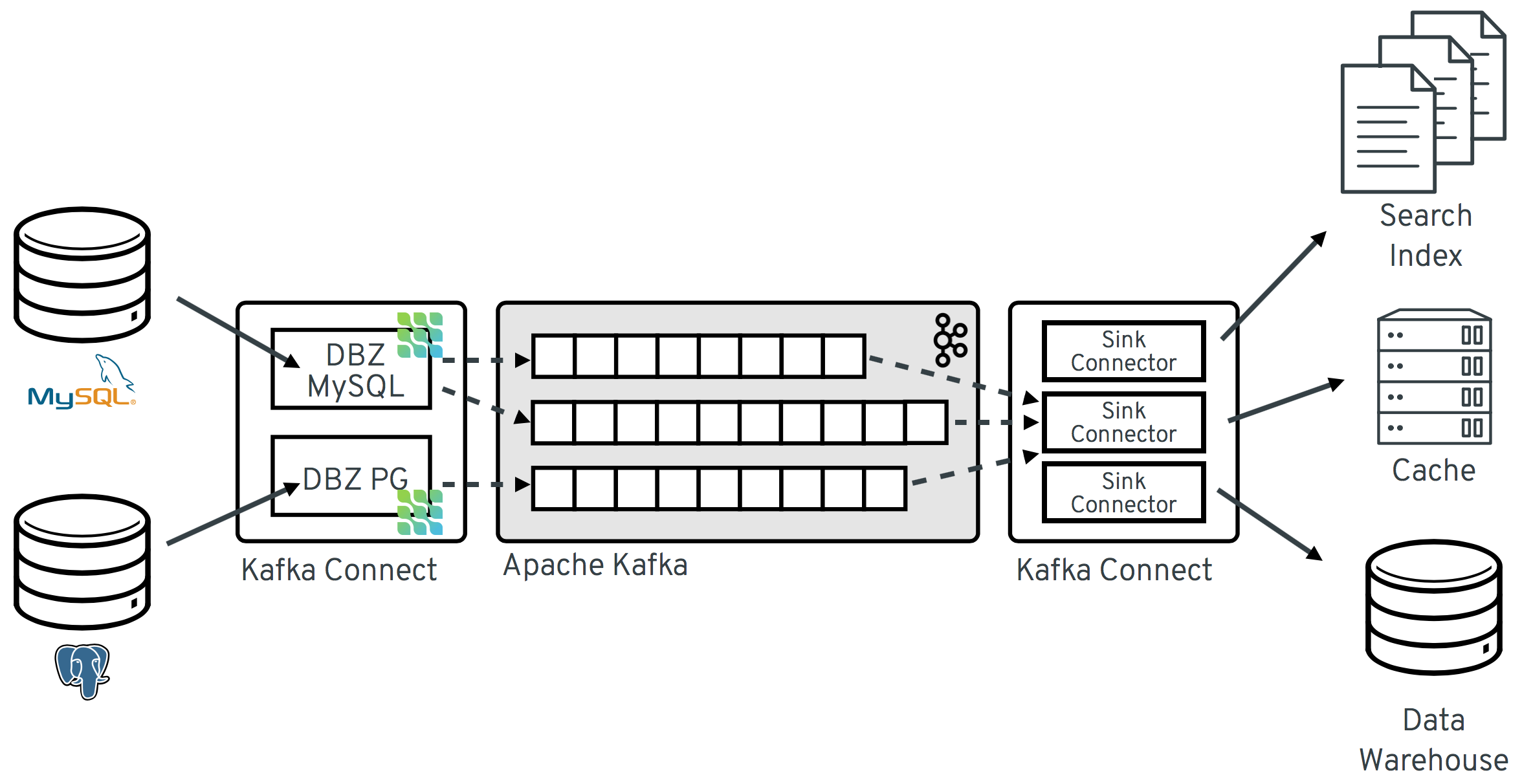
CDC는 데이터베이스에서 발생하는 Insert Update Delete와 같은 변경 사항을 실시간에 가깝게 감지해서 외부 시스템으로 전달하는 기술이다.
13.Kafka - Schema Registry
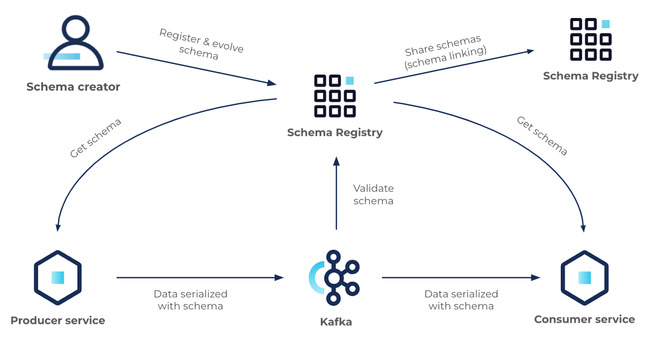
Kafka 기반 데이터 파이프라인에서 메시지 구조를 일관되게 유지하고, 스키마 변경 시 충돌 없이 안정적으로 데이터를 처리하기 위해서는 스키마 관리 시스템이 필수적이다. Schema Registry는 이러한 스키마 정의와 버전 관리를 중앙에서 수행하는 핵심 컴포넌트다.
14.Kafka - KsqlDB
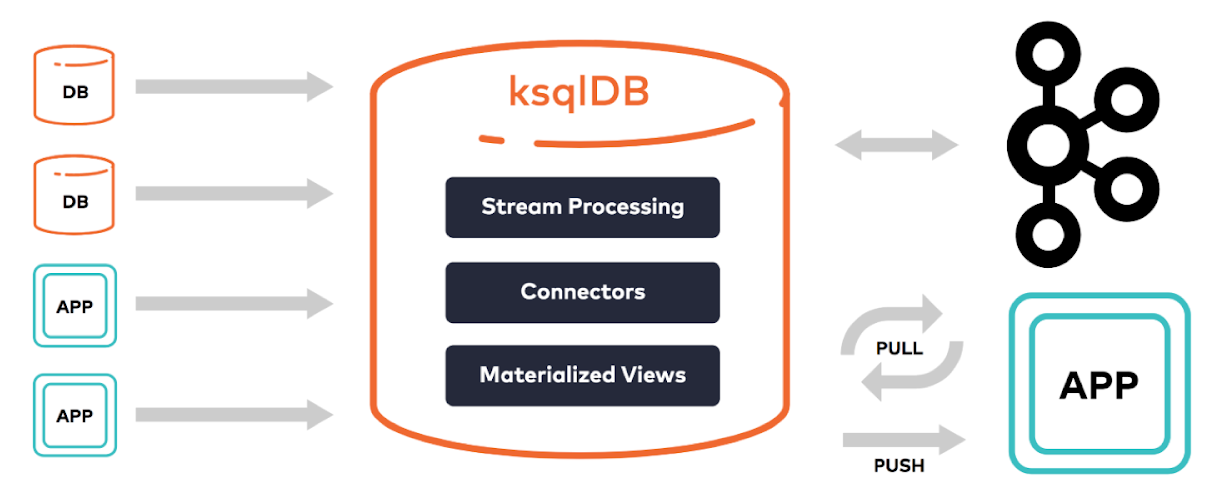
ksqlDB는 Kafka 위에서 동작하는 Streaming 전용 데이터베이스다. SQL 문법을 통해 Streaming 데이터를 실시간으로 처리할 수 있도록 구성되어 있으며 Kafka Streams API 기반으로 실행된다.
15.Kafka - KSQL Stream & Table
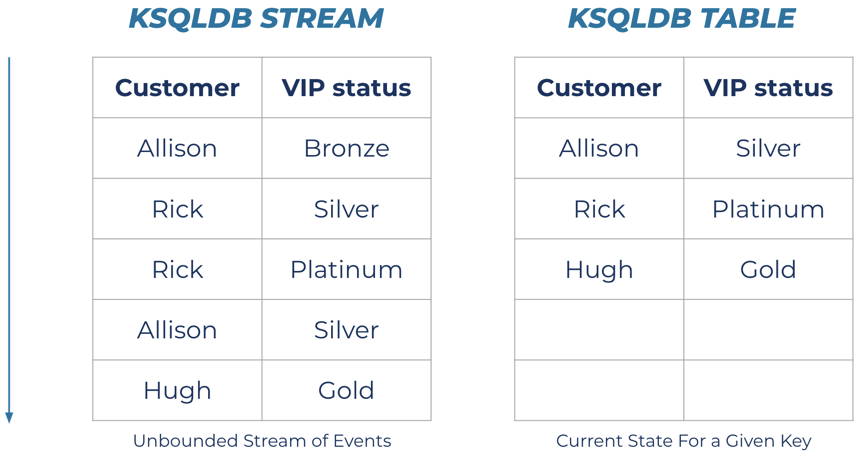
Stream과 Table은 Kafka Topic을 해석하는 두 가지 관점이다.Stream은 Topic에 기록되는 이벤트 흐름 전체를 표현하고Table은 동일 Key 기준의 최신 상태를 표현한다.
16.Kafka - KSQL MView
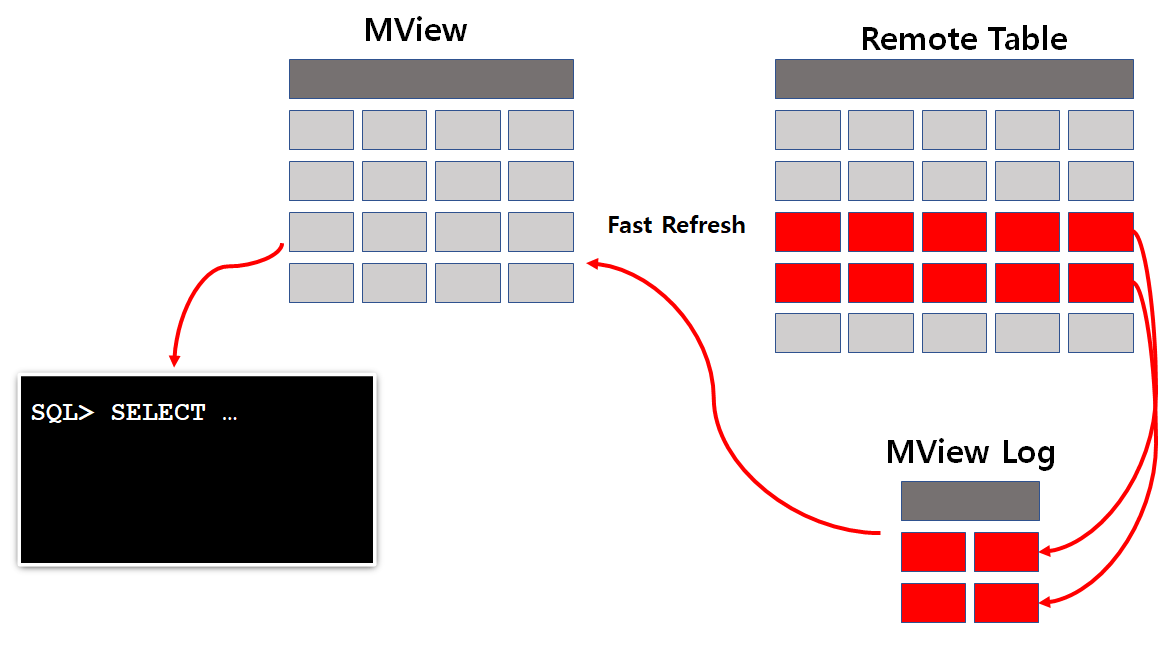
Materialized View(MView)는 Kafka 기반 스트림 데이터에서 집계·가공된 결과를 빠르게 조회하기 위한 구조다.
17.Kafka - KSQL Join
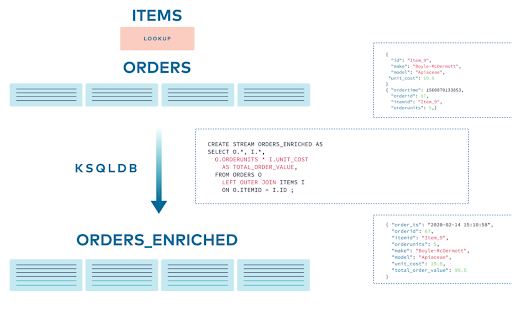
ksqlDB는 Kafka Topic으로부터 생성된 Stream 또는 Table 간에 SQL 유사한 JOIN 연산을 수행할 수 있다.
18.Kafka - KSQL Time & Window
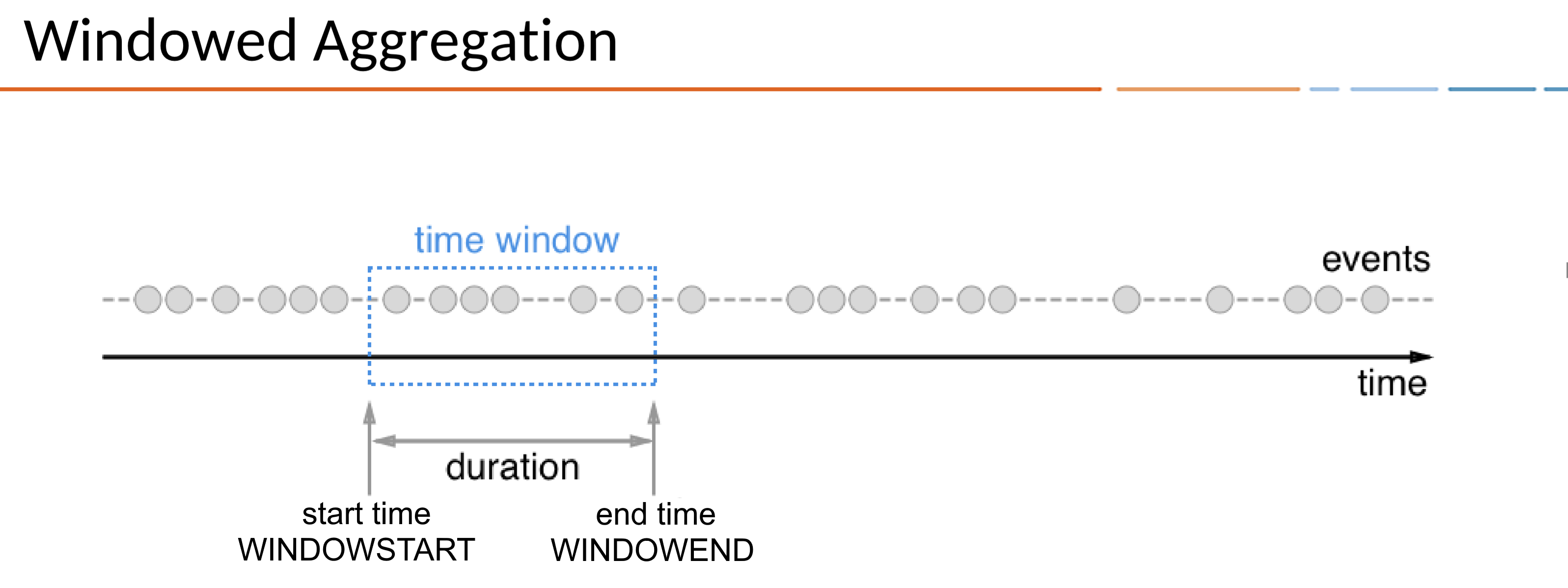
Window는 무한한 스트림 데이터를 시간 또는 이벤트 단위로 구간화하여 처리하기 위한 개념이다. 스트림 데이터는 끝이 없기 때문에 특정 기간 동안의 데이터를 묶어 집계하거나 조인하기 위해 윈도우가 필요하다.