
Apache Kafka / Confluent KafkaKafka는 분산 환경에서 대량의 데이터를 실시간으로 처리하기 위해 만들어진 메시징 플랫폼이다.
단순히 메시지를 전달하는 큐를 넘어, 데이터 스트림의 저장소이자 중심 허브 역할을 한다.
Kafka의 핵심 목표는 다음과 같다.
- 대량의 데이터를 고성능으로 처리할 수 있을 것
- 장애가 발생해도 데이터 유실 없이 복구 가능할 것
- 시스템이 확장될 때 유연하게 대응할 것
이 덕분에 Kafka는 단순한 메시지 큐를 넘어서 데이터 스트리밍 플랫폼의 표준으로 자리 잡았다.
Kafka 구성요소
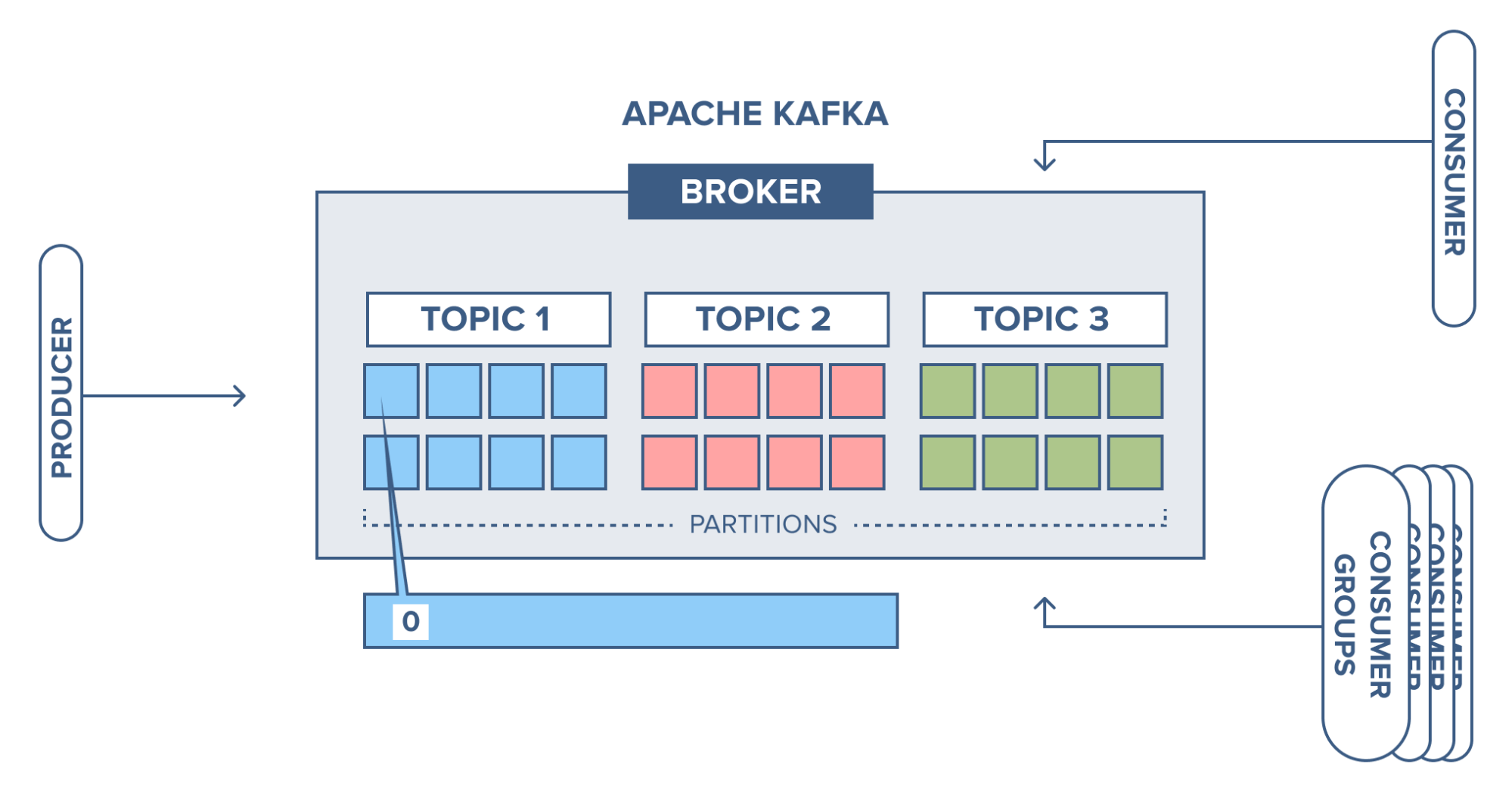
Kafka는 여러 요소가 서로 역할을 분리하며 동작한다.
| 구성요소 | 설명 |
|---|---|
| Broker | Kafka 서버. 데이터를 저장하고 Producer, Consumer와 통신한다 |
| Topic | 데이터가 저장되는 논리적 단위 |
| Partition | Topic을 여러 개로 나누어 분산 처리와 병렬 처리를 가능하게 한다 |
| Offset | Partition 내에서 각 메시지의 순서를 나타내는 번호 |
| Producer | 데이터를 Kafka로 보내는 주체 |
| Consumer | Kafka에서 데이터를 구독하고 처리하는 주체 |
| Consumer Group | 여러 Consumer가 협력해 메시지를 병렬로 처리할 수 있게 한다 |
Broker
Broker는 Kafka의 서버 단위 노드로
실제 데이터를 저장하고 관리하며 Producer와 Consumer 간 통신을 담당한다.
- 하나의 Kafka 클러스터는 여러 개의 Broker로 구성된다.
- 각 Broker는 여러 Topic의 Partition을 나누어 저장한다.
- Broker는 리더(Leader)와 팔로워(Follower) 복제본을 관리하며 장애 발생 시 리더가 교체되어 서비스가 중단되지 않는다.
예를 들어 3개의 Broker가 있고replication-factor=2로 설정된 Topic이 있다면
각 Partition은 두 개의 Broker에 복제되어 저장된다.
Broker는 Kafka 클러스터의 중심이며 Producer가 보낸 데이터를 받아 저장하고 Consumer가 요청할 때 전달하는 데이터의 중개자이자 저장소이다.
Topic
Topic은 Kafka에서 데이터가 저장되는 논리적 단위다.
데이터베이스의 테이블처럼, 목적에 따라 나눈 데이터 공간이다.
예를 들어
user-login: 로그인 이벤트order-created: 주문 정보payment-success: 결제 결과
이런 식으로 구분해 관리한다.
Partition
Topic은 내부적으로 여러 개의 Partition으로 나뉜다.
각 Partition은 메시지가 순서대로 쌓이는 로그 구조이며, Kafka의 병렬 처리 성능을 담당한다.
- Partition 수가 많을수록 병렬 처리량이 증가한다.
- Partition 내 순서는 보장되지만, Partition 간 순서는 보장되지 않는다.
즉, “같은 Partition 안에서는 순서가 유지되지만 전체 순서는 보장되지 않는다.”
Offset
Kafka는 각 메시지에 고유한 Offset을 부여한다.
Consumer는 이 Offset을 기준으로 “어디까지 읽었는지”를 추적한다.
Offset은 내부 토픽 __consumer_offsets에 저장되며
프로세스가 재시작되더라도 이어서 데이터를 처리할 수 있다.
Producer
Producer는 Kafka로 데이터를 전송한다.
보낼 데이터는 ProducerRecord 형태로 만들어지며 Topic, Key, Value를 포함한다.
- Topic : 전송 대상
- Key : 파티션 분배 기준
- Value : 실제 데이터
Key가 있으면 같은 Key는 항상 같은 Partition으로 전송된다.
Key가 없으면 Kafka가 자동으로 분배한다.
| 분배 방식 | 설명 |
|---|---|
| Round Robin | 순차적으로 파티션에 분배 (Kafka 2.4 이전 기본) |
| Sticky Partitioning | 같은 배치(batch)는 동일 파티션으로 전송 (Kafka 2.4 이후 기본) |
Consumer
Consumer는 Kafka에서 메시지를 구독(subscribe)하고 가져온다.
보통 여러 Consumer를 Consumer Group으로 묶어 병렬로 데이터를 처리한다.
| 구성 | 동작 |
|---|---|
| Consumer 수 = Partition 수 | 이상적인 병렬 처리 |
| Consumer 수 < Partition 수 | 일부 Consumer가 여러 파티션 담당 |
| Consumer 수 > Partition 수 | 일부 Consumer는 대기 상태 |
Consumer는 메시지를 읽을 때마다 Offset을 커밋(commit)하여 다음 읽을 위치를 저장한다.
