Machine translation (MT) 는 자동으로 어떤 언어로 된 텍스트를 다른 언어로 바꿔주는 것이다. 최근 몇년 간 주요한 패러다임을 지나고 있는 연구 분야이다. 본 논문에서는 word, sentence embedding으로 현대의 NMT 구조의 origin을 설명하고 encoder-docoder network family 의 예제를 설명한다.
1. Introduction
NLP 분야의 다양한 분야들이 neural network의 재발견으로 크게 발전했다. 최근 몇년 간 NMT 관련 논문들의 수가 급격하게 증가했고, 공개된 NMT toolkit 또한 많다. 산업에서도 많이 적용되고 있다.
2. Nomenclature
- 길이가 I 인 source sentence 를 x 라고 한다. (1)
- source sentence x를 번역한 target language 는 y 라고 한다. (2)
- projection function 는 tuple 이나 vector 를 k 번째 entry 에 map 한다. (3)
- matrix A 에 대해 p-th row, q-th column 인 matrix를 로 표현한다. p-th row vector는 , q-th column vector 는 로 표현한다.
For a series of -dimensional vectors ∈ () we denote the matrix which results from stacking the vectors horizontally as as illustrated with the following tautology: (4)
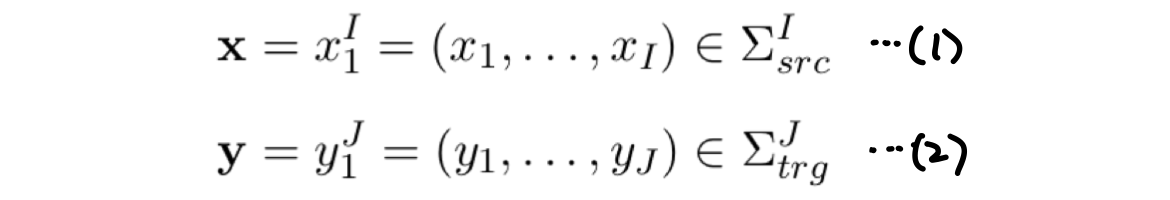
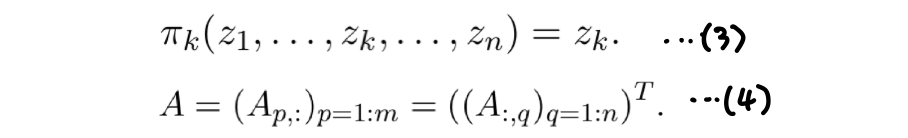
3. Word Embedding
word 또는 phrase 를 continuous vector 로 표현하는 것은 NLP 의 connectionist model 의 핵심이다. continuous space word representation의 성공한 application은 language model 이다. 핵심적인 아이디어는 단어를 d-차원의 벡터로 표현한다는 것이다. continuous word representation 은 단어 간의 morphological, syntactic, semantic similarity 를 찾아낼 수 있다.
새로운 형식의 임베딩인 Contextualized word embedding 은 NLP 의 다양한 분야에서 인기를 얻고 있다. 단어 자체 뿐만이 아니라 전체 입력 문장에 대해 depend 한다. 따라서 single embedding matrix로는 표현하지 못하고, neural sequence model 로 만들어진다. Contextrualized word embedding 은 여러 NLP benchmark 에서 SOTA 를 뛰어넘었다.
4. Phrase and Sentence Embedding
sentiment analysis 또는 MT 와 같은 다양한 자연어 처리 분야에서는 단어 하나보다 구(phrase) 또는 문장 전체를 임베딩 해야 할 경우가 많다. 초기에 phrase embedding 방법은 recurrent autoencoder를 기반으로 했다 (Socher et al.; 2011). phrase 를 d-차원의 벡터로 표현하기 위해 word embedding matrix 를 먼저 학습시킨다. 그런 다음 2차원의 입력에 대해 d-차원 표현을 찾는 autoencoder 를 재귀적으로 적용한다. recurrent autoencoder 를 사용할 때의 단점은 단어와 문장이 모두 같은 차원을 가져야 한다는 것이다. MT 에서는 이 단점이 문제가 되는데, MT 에서 문장 표현은 target 문장 분포를 조건화 하기에 충분한 정보를 전달해야하기 때문에, word embedding 보다 차원이 커야 한다. (이게 무슨 말인지 이해 못한듯 하다.)
또 다른 구, 문장 벡터 표현 방법으로 convolution 을 사용하는 방법이 있다. convolution을 사용한 모델은 각 convolution level 에서
5. Encoder-Decoder Networks with Fixed Length Sentence Encoding
Stahlberg, Felix. "Neural machine translation: A review." Journal of Artificial Intelligence Research 69 (2020): 343-418.
