The FLORES-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation (2021, Goyal et al.) 논문 리뷰 포스팅 !
기계 번역에서 해결해야 할 큰 문제 중 하나는 low-resource 언어의 데이터가 부족하다는 것이다. 이 문제에 도움을 주고자 FLORES-101 이라는 benchmark 데이터를 만들었다. FLORES-101 에서는 101 개의 언어로 English Wikipedia 에서 뽑은 3001 개 문장으로 이루어져있고, 다양한 분야와 주제를 담고있다.
Introduction
최근 Machine Translation 에 대한 연구가 활발하게 이루어지고 있다. 몇가지의 언어들에 대해서는 번역 성능이 뛰어난 반면에 training data 가 적은 low-resource 데이터에 대해서는 성능이 여전히 낮다. low-resource 언어에 대한 몇가지 benchmark 가 있지만 coverage 가 낮고, 높은 coverage 를 가진 데이터라고 하더라도 특정 분야에 편향되어 있는 경우가 많다 (COVID-19, religious texts).
FLORES-101 benchmark 데이터는 English Wikipedia 에서 뽑은 3001 개 문장으로 이루어져 있고, 101 개의 언어로 번역된 데이터 이다. 이 데이터를 통해 (1) 더 다양한 주제를 포함하는 low resource language 데이터로 높은 품질의 데이터를 제공한다. (2) 10,100 개의 언어쌍을 제공해서 many-to-many evaluation 에 적합하다. (3) 커뮤니티에게 MT dataset 을 어떻게 만드는지에 대한 정보를 제공한다. (4) 번역 문장 뿐만 아니라 문서 단위의 번역이나 멀티모달 번역과 같은 다른 종류의 task 를 제공하는 rich meta-data 도 제공한다. (5) 통합된 프레임워크에서 모든 언어의 평가를 가능하게 하는 sentence piece tokenization 기반의 BLEU metric 을 제안한다. (6) 앞으로의 관련된 연구를 위해 실험에 사용된 데이터와 baseline 을 모두 공개한다.
Dataset Construction
FLORES-101 은 다음의 목표를 위해 만들었다: 1. many-to-many multilingual model 의 evaluation 을 할 수 있게 하기 위해, 2. MT 를 넘어서 다른 종류의 평가를 할 수 있게 하기 위해, 3. high-quality evaluation benchmark 데이터를 만들기 위해.
이 목표를 달성하기 위해 세 가지 단계로 구성되어 있다.
1. English Wikipedia 로 부터 번역할 문장들을 뽑는다.
2. 번역 과정을 정하기 위해 pilot experiment 를 디자인하고,
3. 100개 언어에 대해 실제 번역 workflow 를 수행한다.

번역 workflow 는 아래 그림처럼 진행된다. 각 target 언어에 대해서 번역 Language Service Provider (LSP) 가 문장을 번역한다. 번역 결과는 자동으로 check 되고, 이 단계에서 실패하면 다시 번역하도록 보낸다. 자동 check 를 통과하면 다음 LSP 에게 보내져서 human evaluation 을 진행한다. 이때 quality 가 좋지 않으면 다시 번역하도록 앞의 LSP 에서 다시 전달한다. human score에 따라 이 과정은 여러번 반복할 수 있다.
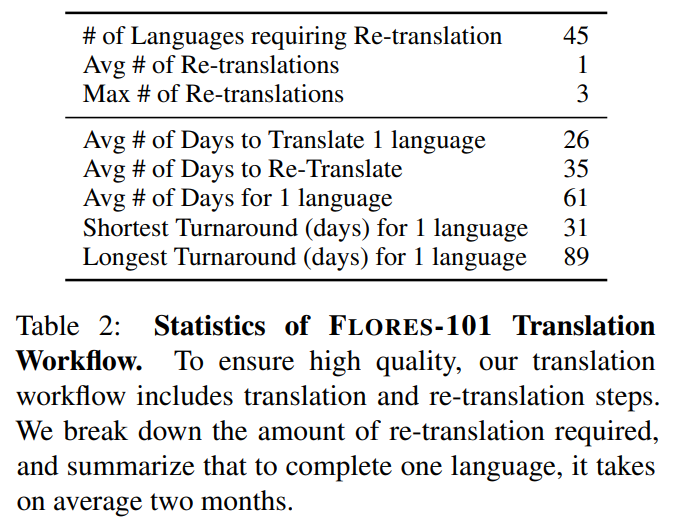
이레는 re-translation 이 필요한 양을 한 언어를 완성할 때를 기준으로 요약한 표이다. 대략 평균 두달이 걸린다.
FLORES-101 At a Glance
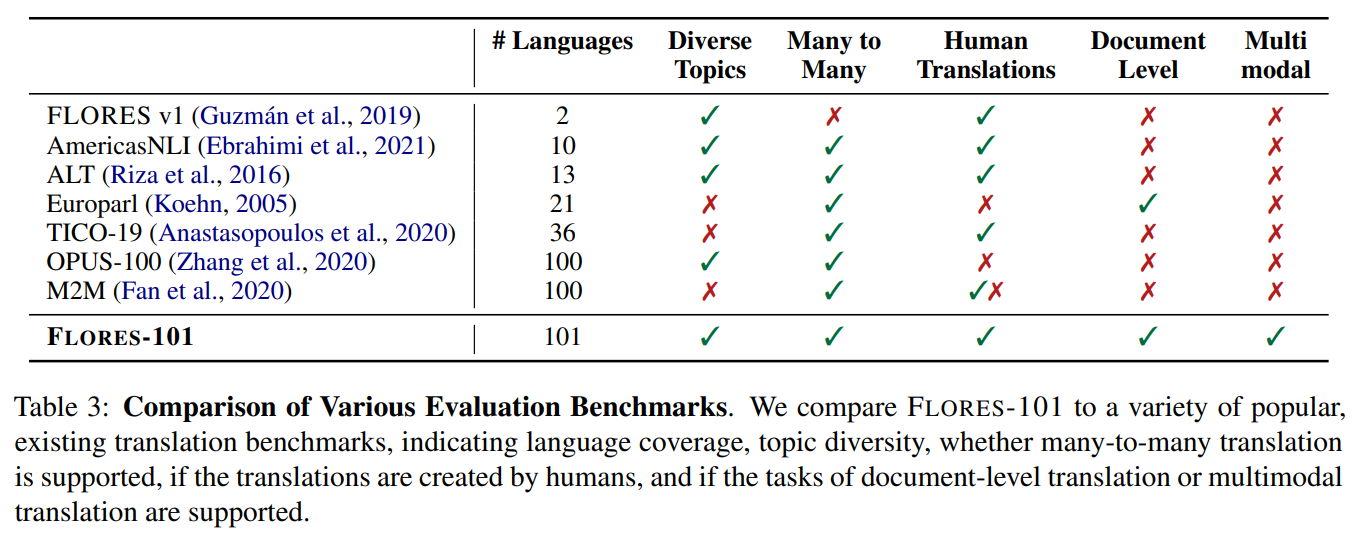
FLORES-101을 다른 benchmark 와도 비교해보았다. FLORES-101 는 다양한 주제를 다루고, many-to-many evaluation 을 지원하고, high quality 의 human translation 을 지원한다. 또한 document-level evaluation이 추가되었고 multimodal translation evaluation 을 지원한다.
FLORES-101 의 언어들을 language family 로 분류도 하였다. 그리고 FLORES-101 에서 사용한 언어는 low-resource 라고 하더라도 사실 수백명의 사람들이 사용하는 언어이다.
Metric: SentencePiece BLEU
101 개의 언어로 번역 모델을 평가하기 위해서 SentencePiece BLEU metric 을 제안한다. 대부분의 경우에 BLEU score 를 사용해서 번역을 평가하는데, BLEU 는 n-gram 을 기반으로 하기 때문에 어떤 tokenization 을 사용하느냐에 따라 의존적이다. 더 aggressive 하게 토크나이징을 할 수록 점수가 더 올라가게 된다.
많은 경우에 sacrebleu 를 사용한다. 하지만 많은 언어들은 존재하는 툴과 토크나이저로 처리하기에 충분하지 않다. 예를 들면 white-space tokenization 은 띄어쓰기가 단어를 구분하는 기준이 아닌 언어에 사용하기 어렵고, 또 어떤 언어들은 morphological 한 언어이다. 몇가지 언어들은 BLEU score 계산할 때 사용하기 위해 custom tokenizer 를 만들어 사용하기도 했다.
하지만 우리는 모든 언어에 쉽제 적용해서 사용할 수 있는 자동 evaluation process 를 사용하고 싶다. 따라서 FLORES-101의 모든 언어의 monolingual data 의 토큰들을 가지고 SentencePiece (SPM) tokenizer 를 학습했다.
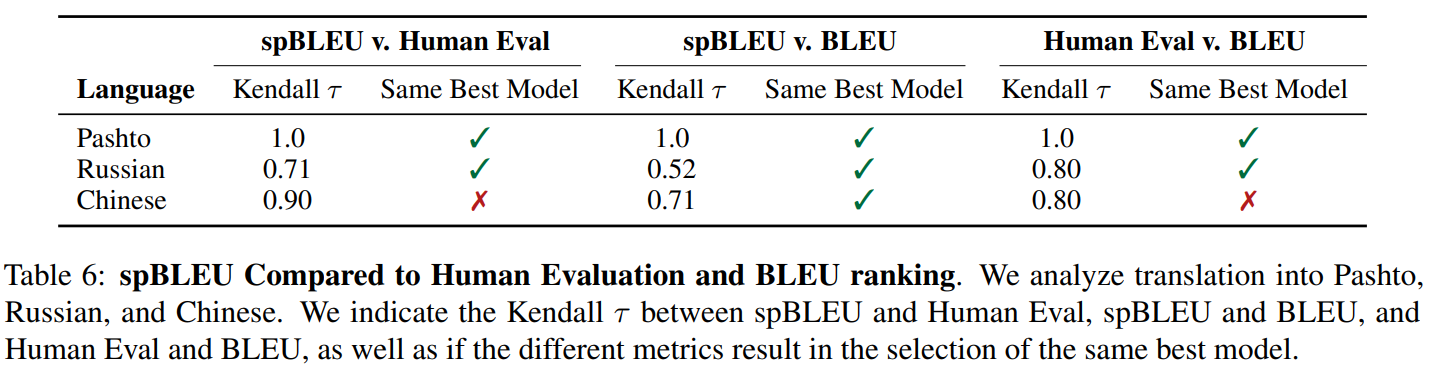
spBLEU metric 을 검증하기 위해서 mosestokenizer 를 사용하는 standard BLEU 와 비교해보고, custom-tokenizer-BLEU 와 비교해보고, spBLEU가 모델 선택을 할 때 사용될 수 있는지 검증해보았다.
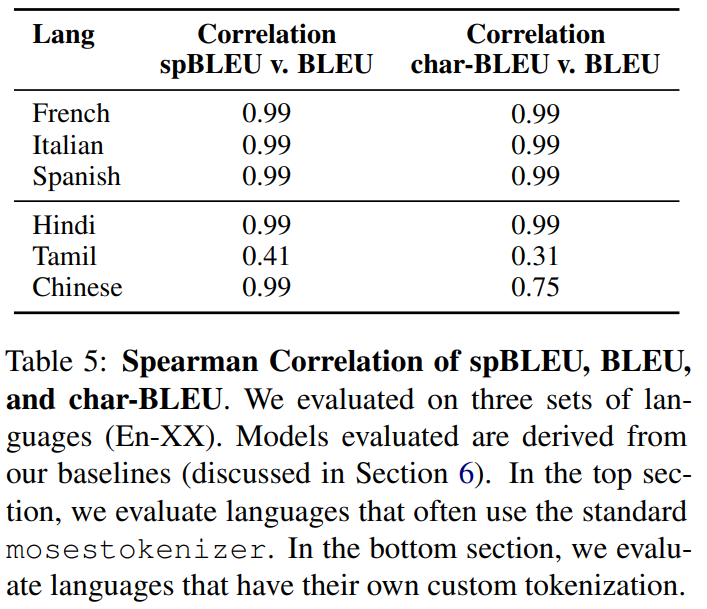
먼저 mosestokenizer를 사용하는 BLEU 와 비교했을 때 spBLEU 가 강한 positive correlation 이 있는 것을 확인했다. 아래 표5의 위 부분을 참고!
다음으로 custom tokenization 을 사용할 때 char-BLEU 보다 spBLEU 가 더 낫다는 것을 확인했다. 아래 표5의 아래 부분을 보자. Chinese, Hindi, and Tamil 세가지의 언어에 대해 확인해보았을 때 spBLEU 와 custom tokenizer BLEU 간의 correlate 가 char-BLEU 와 custom tokenizer BLEU 간의 correlate 보다 더 관계가 있다. spBLEU 를 사용하는 것이 많은 수의 언어를 사용하는 것에 대해 comparability 하고 scalability 하다.
마지막으로 model selection 에 있어서는 spBLEU 와 BLEU 가 비슷한 성능을 보였다. English to Pashto, English to Russian, and
English to Chinese 이렇게 세가지의 방향에 대해 실험해보았다. 세 언어에 대해 spBLEU 와 BLEU 모두 같은 best model 을 선택했다.
Evaluating Baselines on FLORES-101
다음으로 다양한 모델들에 FLORES-101 을 사용해보았다. 결과를 확인해보기 전에, 실험에 사용할 때 FLORES-101 데이터를 dev, devtest, test로 split 해서 사용했다. 베이스라인으로 사용한 모델은 다음의 모델들을 사용했다.
-
M2M-124
- Fan et al. (2020) 이 M2M100 multilingual model 을 학습시켰었다. 그런데 M2M-100은 FLORES-101 에서 사용하는 모든 언어를 커버하지 않는다. 그래서 M2M-100 에 없는 언어에 대해서는 OPUS 에서 데이터를 가져와 사용했고, 따라서 총 124개의 언어에 대해 실험했다. 이 데이터에 대해 두가지 크기의 모델로 학습을 했는데 각각 615M, 175M 의 파라미터를 가지고 있다. 결과 비교할 때에는 615M 모델을 사용했다.
-
OPUS-100
- Zhang et al. (2020) 는 English-centric OPUS training dataset 을 가지고 multilingual machine translation model 을 학습시켰다.
-
Models open-sourced by Masakhane
- African 언어의 NLP 에 집중하는 Maskhane Participatory Research 에서 제공하는 machine translation model 이다. 영어와 6개의 언어들(Yoruba, Zulu, Swahili, Shona, Nyanja, and Luo)로 번역하는 모델들을 평가했다.
Results
이제 결과를 보여준다. 먼저 아래 그림5를 보면 X->English 번역의 성능이 English->X 번역의 성능보다 높은 것을 볼 수 있다.
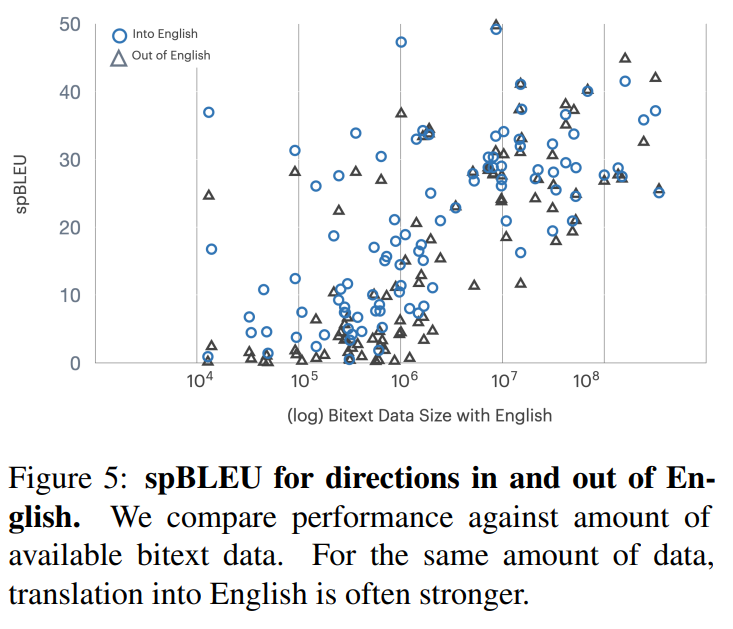
영어가 아닌 언어들 간의 번역 성능은 아직 성능이 낮다. 예를 들면 아프리카 언어들에 대해서 5 정도의 spBLEU 를 보여준다. 따라서 데이터의 양과, 비슷한 언어로부터의 transfer learning 의 중요성을 보여준다.
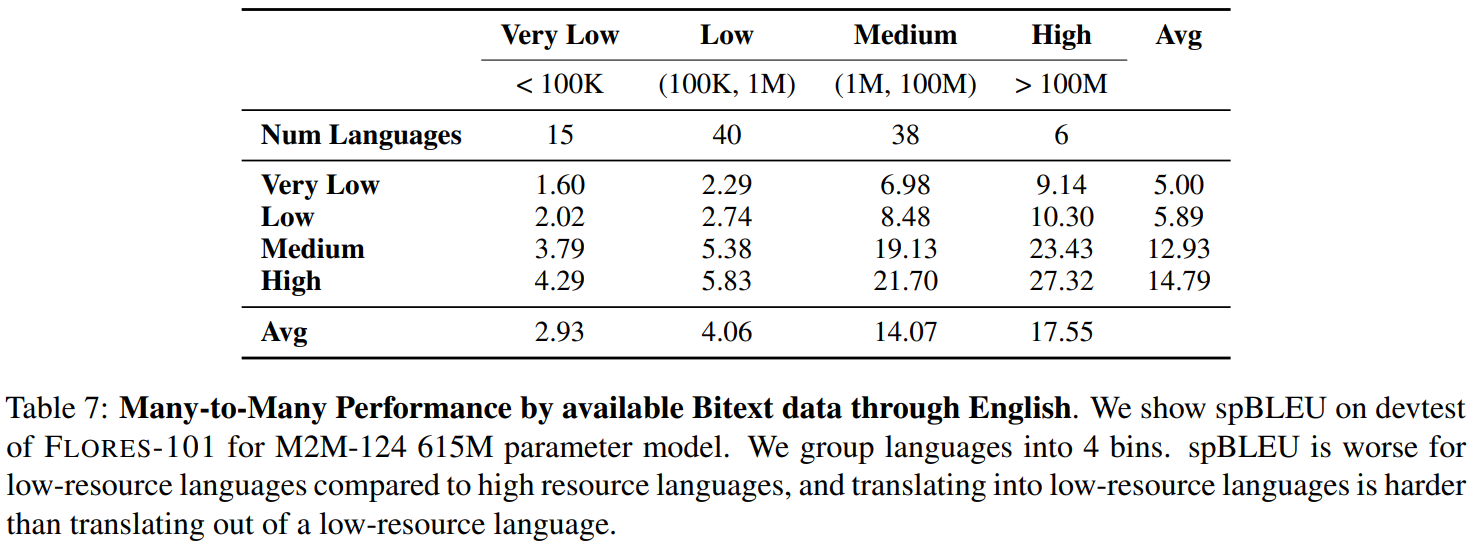
다양한 언어 family 들의 성능 분석은 training data 의 양과도 관련이 있다. 따라서 resource level 에 따라서도 성능을 분석했다. 100M 이상의 문장이 있으면 high-resource languages, between 1M and 100M 의 문장이 있으면 mid-resource, between 100K and 1M 문장이 있으면 low-resource, 그리고 100K 이하의 문장이 있으면 very
low-resource 로 분류했다. 결과는 아래 표에서 보여준다. training data 가 많을수록 성능도 높은 것을 볼 수 있다. high resource 와 low-resource languages 간의 번역 성능도 낮은 것으로 보이는데, training data 의 부족이 MT system 의 성능을 제한하는 것을 보여준다.
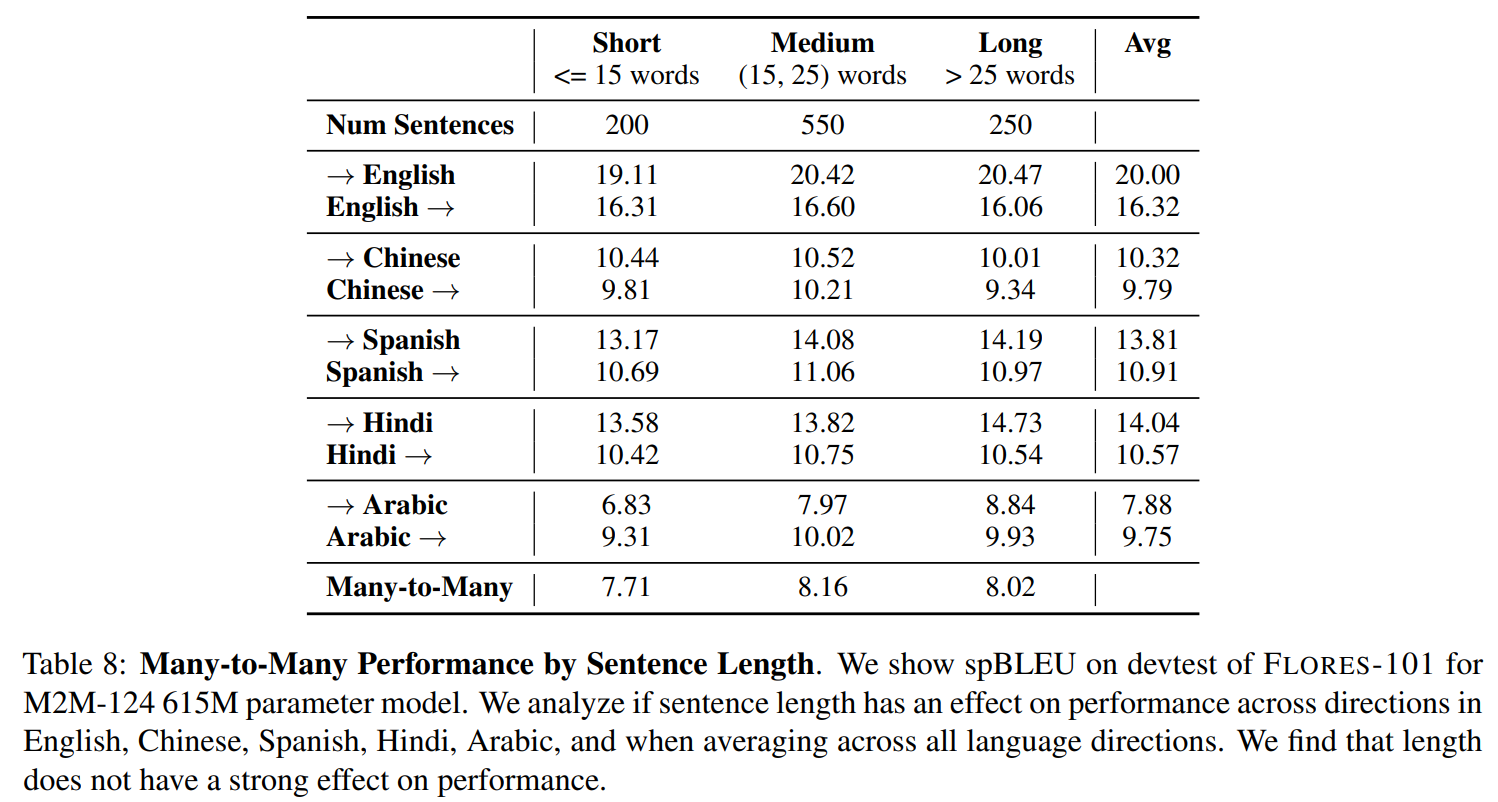
다음으로 문장의 길이가 어떻게 번역 quality 에 영향을 주는지도 평가해보았다. 문장이 길면 복합하고 번역하기 어려울 것이라고 가정했다. 문장의 길이는 token 의 수로 정했다. 아래 표에서 결과를 보여주는데, 문장의 길이와 상관없이 거의 일정한 것을 보여주었다. 그리고 오히려 문장의 길이가 길수록 조금 오르는 것을 보여주었다.
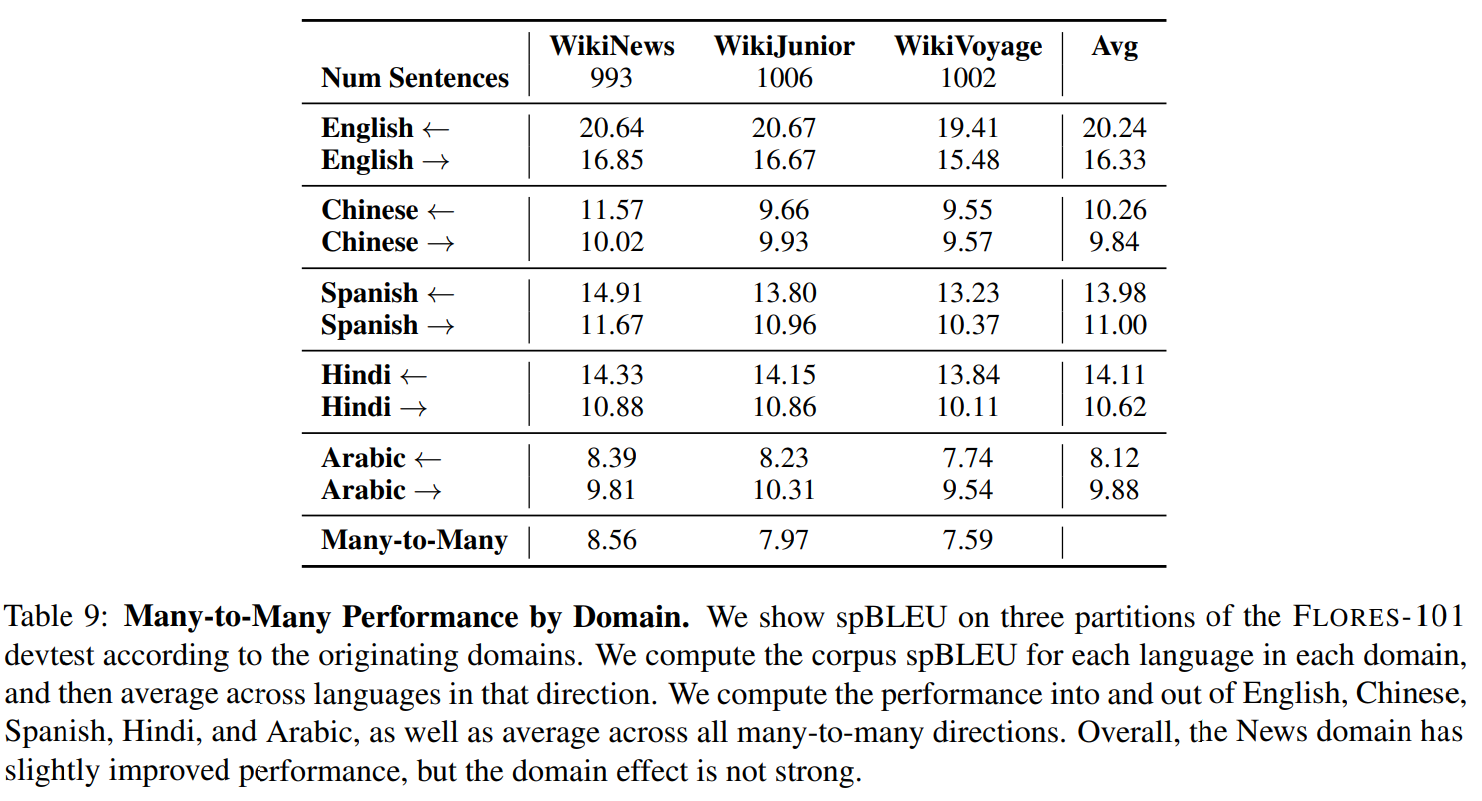
데이터의 domain 에 따라서 어떻게 성능에 영향을 주는지도 분석을 해보았다. FLORES-101 데이터는 WikiNews, WikiJunior, and WikiVoyage 이 세가지의 domain 을 가지고 있다. WikiNews 가 더 높은 성능을 보여주어서 가장 쉬운 domain 으로 보여주었고, WikiVoyage가 가장 어려운 domain 인 것으로 보여준다. 뉴스와 관련된 내용은 일관적은 형식으로 쓰여져서 번역하기 조금 더 쉬운 반면, 위치에 대한 named entity 가 많은 WikiVoyage는 정확하게 번역하기 어려울 것이다.
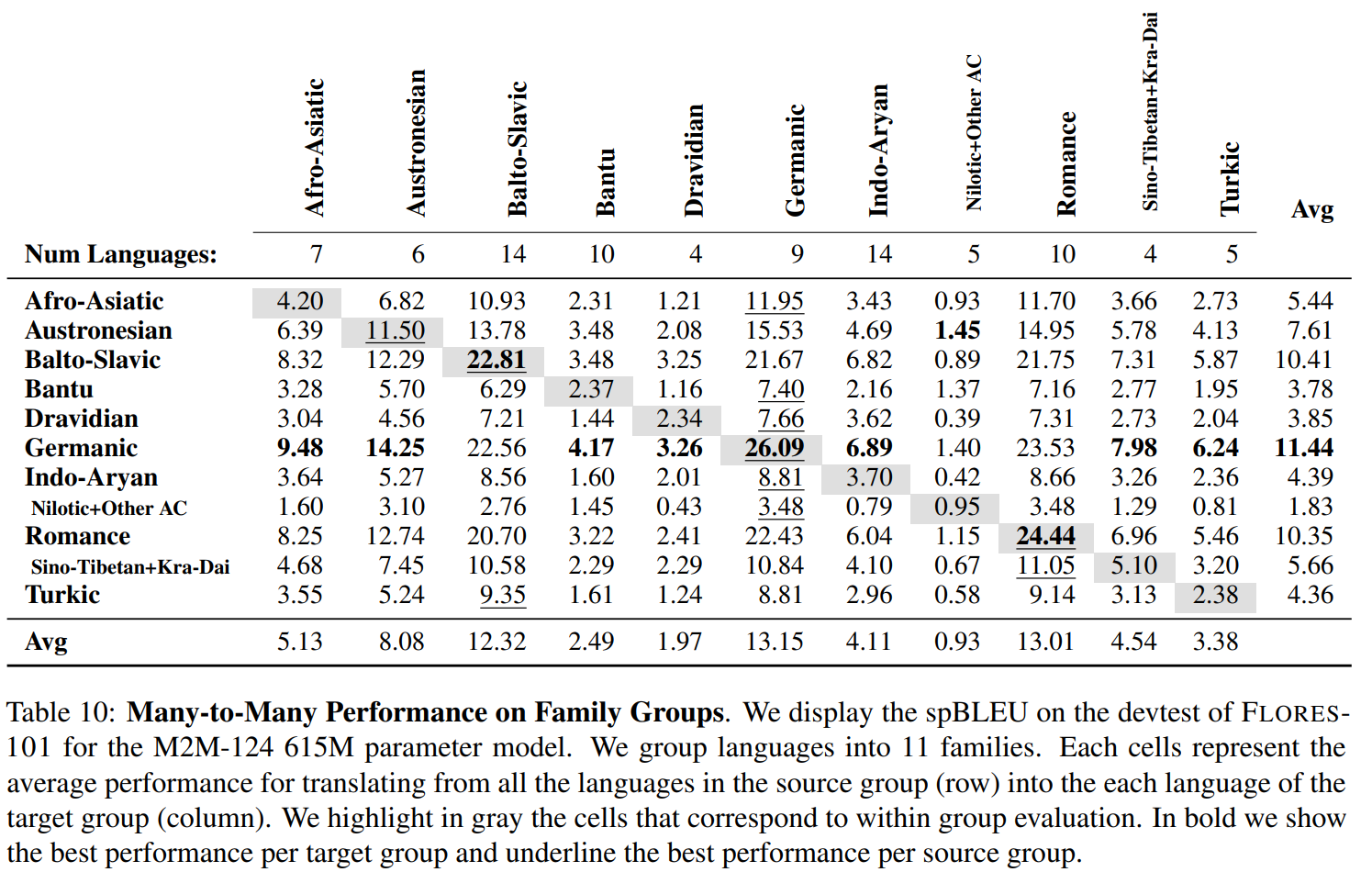
아래의 표는 언어들을 그룹을 지어주어서 11개의 family 를 만들어주고 각 family 에 대한 번역 성능을 비교한 결과를 보여준다.
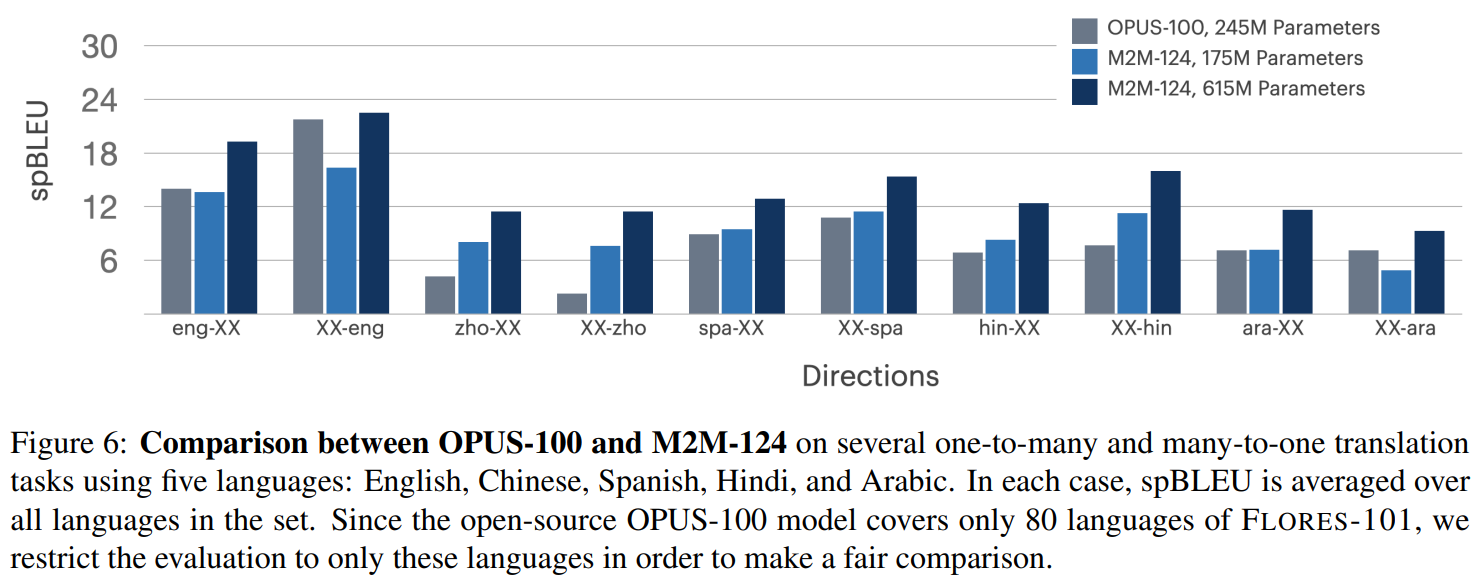
다음 그림은 OPUS-100 과 M2M-100 의 성능을 비교해서 보여준다. 대부분의 경우 M2M-124 의 큰 모델이 가장 좋고, 다음으로 M2M-124 의 작은 모델 그리고 OPUS-100 모델 순서로 성능이 좋다.
[Reference]
Goyal, Naman, et al. "The flores-101 evaluation benchmark for low-resource and multilingual machine translation." Transactions of the Association for Computational Linguistics 10 (2022): 522-538.
