Tensorflow 라이브러리 불러오기
import tensorflow as tf
버전 확인 : tf.version => 2022.10.16 버전 == 2.9.2
Keras
텐서플로우의 딥러닝 모델을 빌드하고 학습하는 API
tensorflow.keras
layer
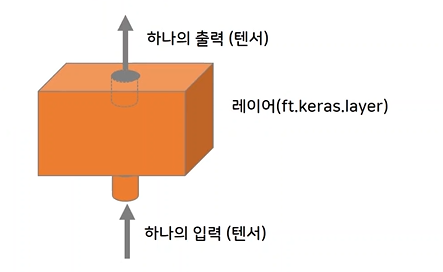
Keras의 모델
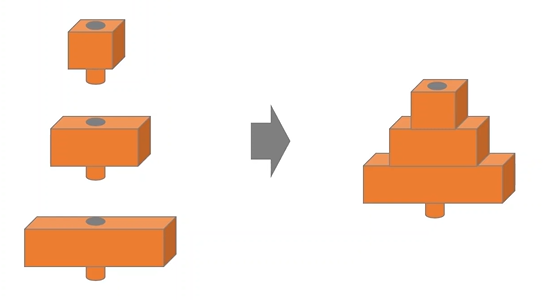
- Sequential Model : 가장 많이 사용하는 모델로, layer를 선형으로 쌓은 모델이다.
- 함수형 API : 임의의 구조를 만들 수 있는 비순환 유향 그래프
Sequential Model
layer를 선형으로 쌓은 모델로, 다중입력, 다중출력이 있는 경우 적합하지 않다.
- activation function : 다음 layer로 신호를 얼만큼 전달할 지 결정하는 함수
- input_shape : 입력되는 tensor(행렬)의 모양, 크기 지정.
//Dense layer from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense // model = Sequential([ //784칸의 1차원 텐서 Dense(units=128, activation='relu', input_shape=(784,), //units : 뉴런 갯수 Dense(units=10, activation='softmax) //activation : activation function ])//Flatten layer from tensorflow.keras.layers import Flatten // model = Sequential([ Flatten(input_shape=(28, 28)), //28x28의 2차원 텐서를 input으로 설정. //Flatten은 자동으로 28x28을 계산하여 784 1차원으로 변환 Dense(units=128, activation='relu'), //units : 뉴런 갯수 Dense(units=10, activation='softmax') //activation : activation function ])++ model.summary() 를 이용하여 모델의 구조 확인

모델 컴파일
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'] )input이 모델을 통해서 output(예측값)으로 나오면, 실제 값과 오차를 측정한다. 이때, loss(손실함수)를 사용하고, 오차를 줄이는 optimizer(최적화 알고리즘) 사용하여 오차를 줄여나간다. 최종 matrics(평가 지표)를 이용하여 훈련 단계를 모니터링한다.
손실함수(loss)
- mse : 예측값과 실제값 사이의 평균 제곱 오차를 정의한다. 차가 커질수록 제곱 때문에 오차가 뚜렷해진다. 오차가 양수든 음수든 누적 값이 증가된다.
- binary_crossentropy : 실제값과 예측값 간의 교차 엔트로피 손실을 계산한다. 값(레이블)이 0 / 1처럼 2개만 존재할 때 사용하면 좋다.
- categorical_crossentropy : 다중 분류 손실함수로 one-hot-encoding된 출력값을 비교한다.
++one-hot-encoding : 문자를 벡터 차원에 표현하고 싶은 단어의 인덱스를 1로 표시하는 벡터 표현 방식- sparse_categorical_crossentropy : 다중 분류 손실함수로, 샘플 값이 정수형이어서
one-hot-encoding이 필요하지 않은 경우 사용한다.
최적화 알고리즘(optimizer)
- Adam : 가장 많이 사용
- Gradient Denscent (경사 하강법)
- AdaDelta
평가지표(metrics)
- 분류 : accuracy
- 회귀 :
MAE(실제-예측 차이를 절대값으로 변환해 평균 계산)
MSE(실제-예측 차이를 제곱해 평균 계산)
학습
x_train, y_train = Preprocessing(data[data[' Usage'] == 'Training']) x_val, y_val = Preprocessing(data[data[' Usage'] == 'PrivateTest']) x_test, y_test = Preprocessing(data[data[' Usage'] == 'PublicTest']) // model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=5, batch_size=64)
- x_train : training용 데이터
- y_train : training용 레이블(정답)
- validation_data : 검증용 데이터 (검증용 데이터, 검증용 레이블)
- epochs : 전체 데이터 셋 학습 횟수
- batch_size : 전체 데이터를 몇개의 조각으로 쪼갤 지 결정.
위 예제에서는 총 28709 데이터를 64로 쪼개어 한번에 449개의 데이터를 training 함.

검증
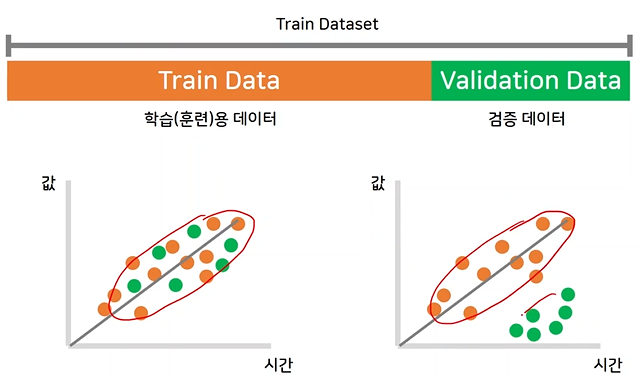
모델을 학습시키고 해당 모델이 좋은 모델인지 검증하기 위하여 validation 데이터를 이용하여 검증하는데, 이때, 첫번째 그래프와 같이 검증 데이터가 학습 데이터와 잘 섞여 있다면 문제가 없지만, 검증 데이터가 너무 동떨어져 있다면 문제가 된다. 따라서, 검증 데이터를 확인할 필요가 있다.
데이터가 training data, test data 이렇게 두 분류로 되어있는 경우, training data에서 validation data를 분류해줘야 하는데, validation_split을 사용하여 데이터의 20%를 validation data로 사용하는 것이다.

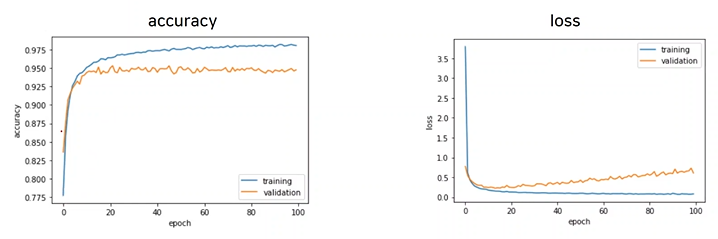
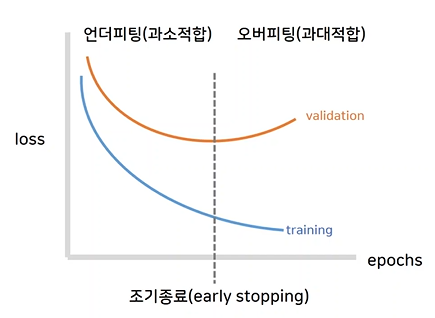
조기종료
training을 epochs를 높여 하다보면 어느순간부터 loss가 점점 다시 커지는 것을 확인할 수 있다. 이는, 그래프에서 보면 training data의 loss는 점점 줄어드는데, validation data의 loss는 다시 커지기 때문이다.
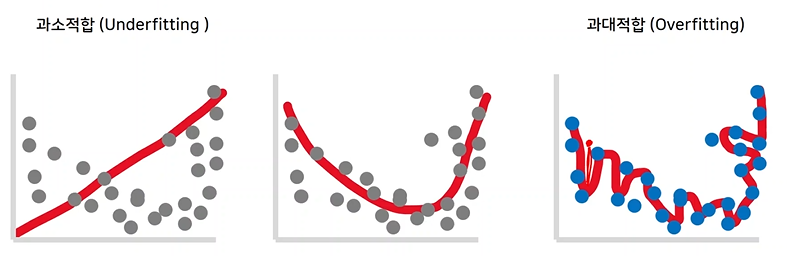
Underfitting은 데이터가 아직 충분히 훈련되지 않았을 때이고, Overfitting은 데이터가 너무 잘 훈련되어 training data에만 적합하게 되어 test data가 들어왔을 때 오히려 손실이 커지는 것을 의미한다.
따라서 Underfitting과 Overfitting의 중간에서 training을 조기종료 해야한다.from tensorflow.keras.callbacks import EarlyStopping // early_stopping = EarlyStopping(monitor='var_accuracy', patience=3) // val_accuracy를 관찰하다가 epochs 3번까지 증가하지 않을 시 종료 early_stopping = EarlyStopping(monitor='var_loss', patience=3) // val_loss를 관찰하다가 epochs 3번까지 증가하지 않을 시 종료

배치 정규화
데이터를 입력을 넣을 때, 데이터의 크기가 다른 경우 training이 불안정하게 진행되어 정확한 training이 이루어지지 않을 수 있다. 이를 해결하기 위해 BatchNormalization layer를 추가한다.
from tensorflow.keras.layers import BatchNormalization

드롭아웃
overfitting을 방지하기 위하여 hidden layer를 몇% 생략할 지 결정하는 layer
from tensorflow.keras.layers import Dropout
20% 생략

