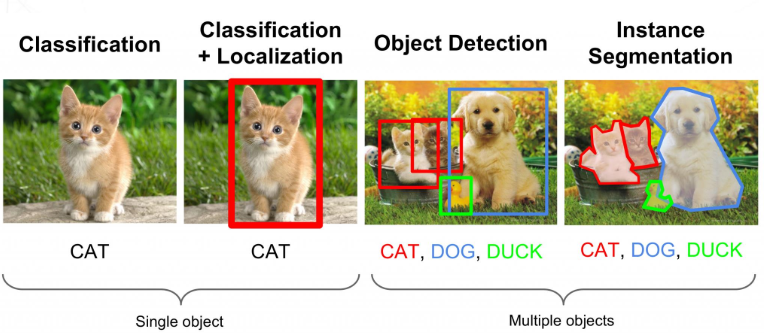
AI (Artificial intelligence)
A Technology that embodies(구현하다) the intellectual abilities of humans through computers
- Strong AI : AI with performance beyond human capabilities
- Weak AI : AI designed for use as a tool in certain areas
AI ML DL
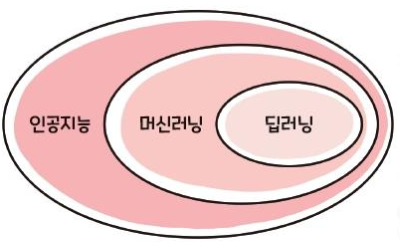
DL
- Technology for performing machine learning using artificial neural networks with multiple hidden layers
- “Deep” means deep layers of continuous neural networks
- Performance increases as this neural network deepens
ML과 DL 차이
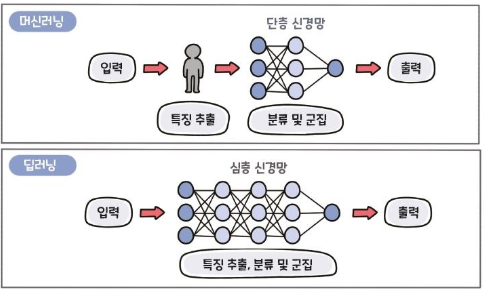
- ML involves human intervention
- DL learns on its own without human intervention
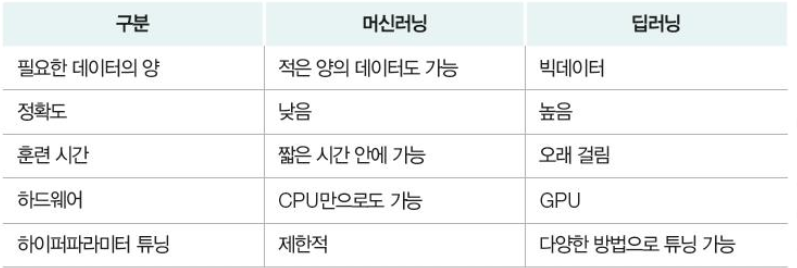
ML 종류
지도학습 vs 비지도학습
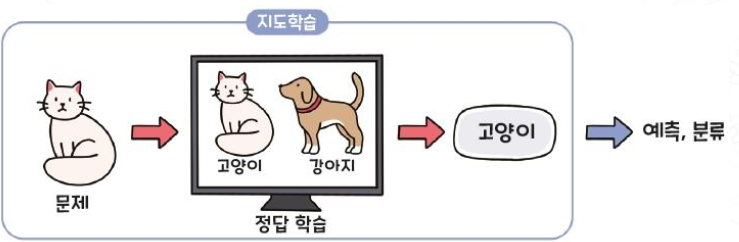
Supervised Learning (지도학습)
Learning to predict the right answer to an unknown problem by learning questions and answers together
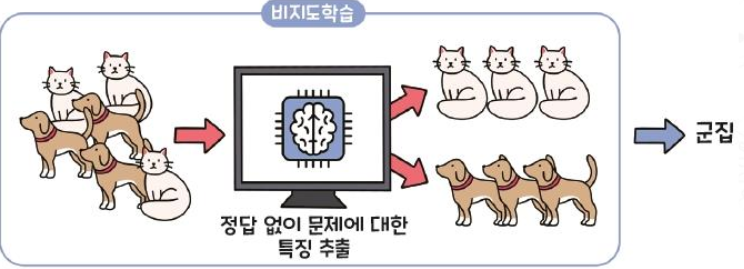
Unsupervised Learning (비지도학습)
Learning with only input data and no corresponding correct answer (label)
다음과 같이 활용된다.
- Finding a specific pattern for data without result information
- Finding latent structures and hierarchies in the data
- Finding hidden user groups
- Structuring documents according to their subject matter
- Using log information to find usage patterns
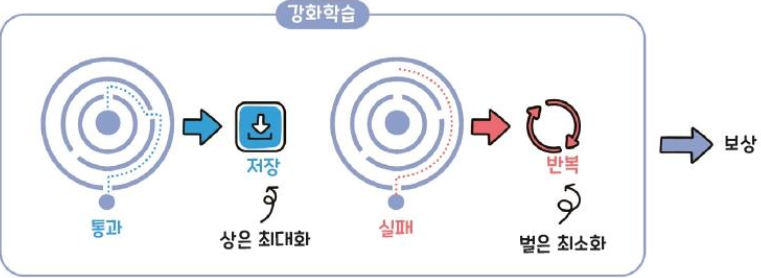
Reinforcement Learning (강화학습)
Learning to be rewarded for what you've done
Model-based-algorithm : probability that an action in the current state will result in the next state
(현재 상태의 동작이 다음 상태로 이어질 확률을 계산하는 알고리즘으로, 강화학습의 방법임)
- Agent: 주어진 문제 상황에 대해 행동을 하고 학습을 하는 주체
- State : Environment의 현재 상황
- Action: Options that the player can take
- Rewards: Benefits that follow when a player does something
- Environment: means the problem itself
- Observation : Agent가 수집한 정보. Environment로부터 수집한 정보로 행동을 결정함
머신러닝 알고리즘 종류
Classification - Supervised
- K-neighbor nearest
- Support vector machine (SVM)
- Decision tree
- Linear Discriminant Analysis
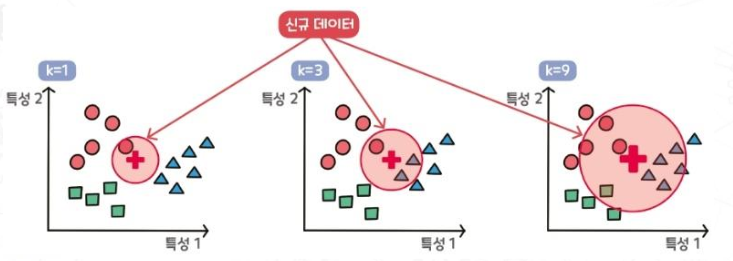
K-nearest neighbor(KNN) - Supervised
An algorithm to classify which of the existing groups of data (K groups) belongs to when new data comes in.
KNN 알고리즘은 주어진 데이터 포인트의 클래스 또는 값을 결정하기 위해 가장 가까운 k개의 이웃 데이터를 기반으로 결정한다.
새로운 데이터 포인트가 주어졌을 때, 그 포인트에 가장 가까운 k개의 데이터 포인트를 찾고, 이들의 레이블을 참조하여 새로운 포인트의 레이블을 결정합니다.
위 예시에서 신규 데이터 특성이 + 지점에 찍혔다고 하면, +로부터 가까운 이웃을 K개 선택하고 그 중 다수결 원칙에 따라 가장 많은 레이블을 선택한다.
- 장점
KNNs are not significantly affected by the noise present in the learning.
(노이즈에 큰 영향 받지 않음)- 언제 사용?
effective when the number of learning data is large
(데이터가 클 때 효과적)- 단점
it is unclear which hyperparameters are suitable for analysis.
so, researchers should randomly select.
(어떤 하이퍼 파라미터가 분석에 적합한지 불분명. 따라서 연구자들이 랜덤하게 선택해야 한다.
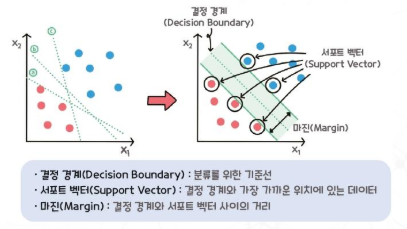
Support Vector Machine - Supervised
An algorithm that finds the optimal Decision boundary to separate data points when they belong to different classes.
Categorize data in the direction of maximizing margin.
(두 그룹 간 마진을 최대화하는 방향으로 데이터 분류)
**마진 : Decision boundary와 가장 가까운 데이터 포인트 사이 거리
서포트 벡터를 잘 선택하면 수많은 쓸모없는 데이터를 무시할 수 있어 빠르다.
- 장점
Easy to use and highly predictive- 단점
it takes time to build a model and the results are less descriptive
Support vector
Decision Boundary와 가장 가까이 있는 데이터 포인트
kernel
SVM는 선형 분류기로, 선형 문제에는 효과적이지만, XOR 같은 비선형 문제를 해결하기엔 한계가 존재한다. 이럴 때는 커널 함수를 사용하여 데이터를 고차원으로 매핑하여 비선형 문제를 선형으로 변환하여 해결한다.
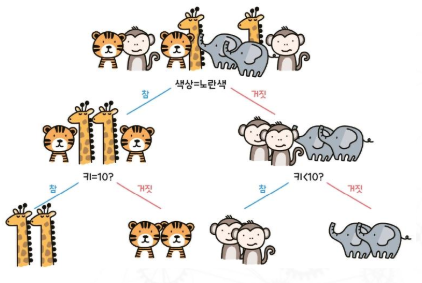
Decision tree - Supervised
An analysis method for classifying decision-making rules into tree forms
위쪽에서부터 시작해서 하위노드로 확장되는 모습 때문에 tree라 함
- 장점
intuitive and easy ro understand the analysis process
신경망이 black box 모델인 반면에, decision tree can see the anaysis process
Complex tree
decision tree에서 깊이가 깊고, 노드와 가지가 많은 트리이다.
트리의 depth가 깊을 수록, 분기 수가 많을 수록(가지가 많을 수록) 오버피팅을 유발하니, 트리의 적절한 깊이와 분기 수를 선택하는 것이 중요하다.
LDA(Linear Discriminant Analysis) - Supervised
PCA(Principal Component Analysis)는 데이터의 표현을 최적화(데이터의 중요한 정보를 보존) 하는 관점에서 데이터의 차원을 줄이는 방법이다.
LDA는 데이터를 최적으로 분류하는 관점에서 데이터의 차원을 줄이는 방법이다.
LDA는 클래스 내의 분산(Scatter)을 최소화한다.
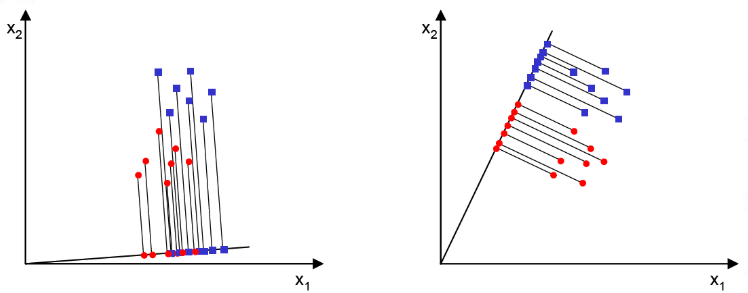
한계점
두번째, 세번째와 같이 선형적으로 분리할 수 없는 데이터에 대해 제대로 작동하지 않는다.

Ensemble Classifier
여러개의 개별 Classifier를 결합하여 하나의 강력한 Classifier를 만드는 기법이다.
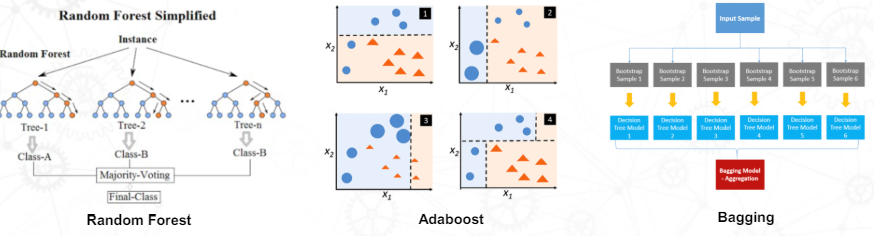
Ensemble 종류
- Random Forest : Bagging을 기반으로 한다. 여러개의 Decision tree를 생성하고 각각 트리가 독립적으로 학습하도록 한다. 최종으로 각 트리의 예측의 평균을 적용한다.
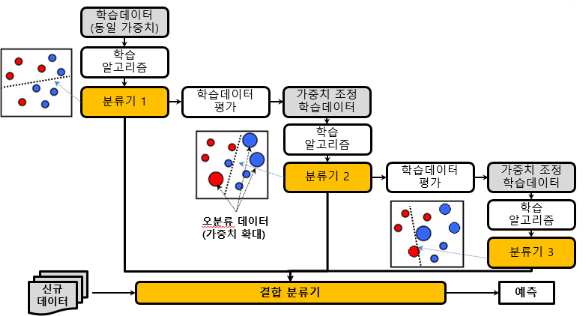
- Adaboost : 여러개의 약한 classifier를 순차적으로 학습시키고 이전 classifier의 오차를 보완하도록 한다.
Boosting(K개의 classifier를 순차적으로 생성하는 classifier 생성 기법)을 통하여 classifier를 생성한다. 이때, 분류 정확도를 기준으로 학습 데이터 가중치를 변경하여 classifier를 생성한다.
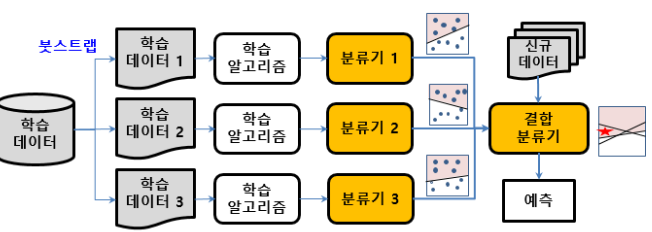
- Bagging : 여러 개의 동일한 classifier를 병렬로 학습시키고, 각 classifier의 예측을 결합하여 최종 예측을 수행하는 방법이다.
Bootstrap(원본 데이터에서 샘플 데이터를 새로 생성하는 샘플링 기법)을 통해 생성한 학습 데이터로 여러개의 classifier를 병렬 학습시킨 후 투표 또는 가중치 부여를 통해 최종 결정한다.
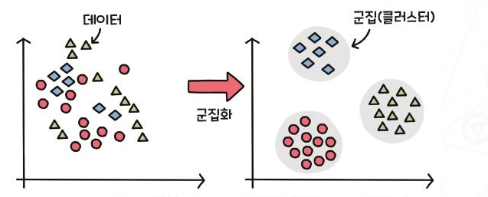
Clustering - Unsupervised
cluster : 비슷한 특징을 가진 데이터의 그룹
Hierarchical clustering
result clusters have hierarchical structures as a result of clustering
- Agglomerative hierarchical clustering (상향식) : 모든 데이터 포인트가 하나의 클러스터로 시작해서 가장 가까운 클러스터가 병합함으로써 단일 클러스터가 될 때까지 반복
- Divisive hierarchical clustering (하향식) : 모든 데이터가 포함된 하나의 클러스터에서 시작하여 클러스터가 점점 분리되는 방식
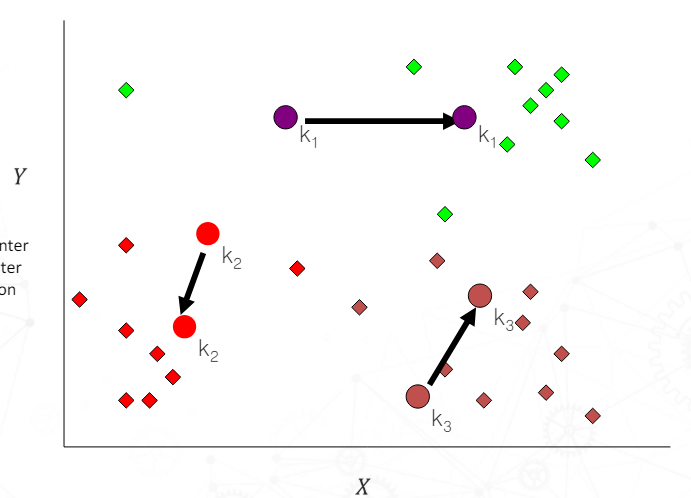
K-means clustering
데이터를 K개의 클러스터로 그룹화하는 partitioning clustering의 알고리즘 중 하나이다.
데이터 포인트 중 임의의 K개를 중심(centroid)으로 정하고 모든 데이터 포인트들을 가장 가까운 centroids에 할당하여 클러스터를 만든다. 각 클러스터에 속한 데이터 포인트들 간에 평균 위치를 기준으로 centroid를 이동시킨다. 각 클러스터의 centroid가 더이상 움직이지 않을 때까지 반복한다.
특징
- K는 미리 지정되어있다.
- 초기 클러스터 위치에 민감하다.
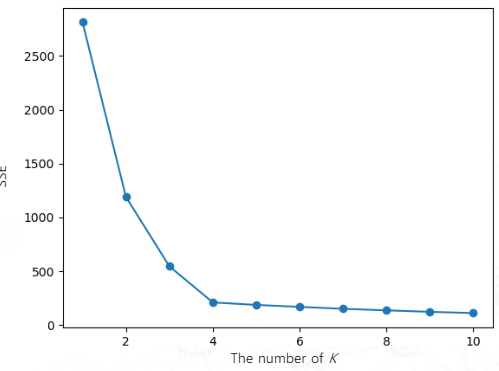
Elbow Method
최적의 K를 결정하는 방법. 군집수 K에 따른 군집화 결과에 대한 군집의 SSE(Sum Of Squared Errors)를 그래프로 그려 가장 큰 굴곡에서 K를 선택하는 방법
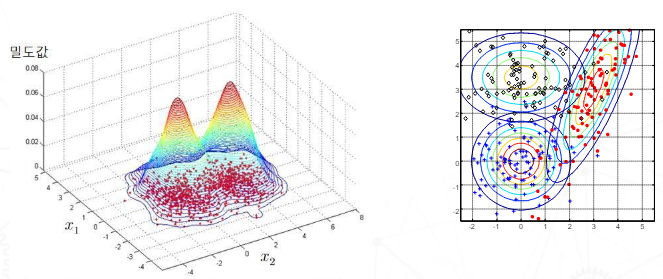
Density Estimation
언제 사용?
- Calculate the probability of generating a given data for each class
- Classify as the most likely class
Dimensionality reduction
고차원 데이터를 최소한의 loss로 저차원 데이터로 변환하는 기술이다.
언제 사용?
- 2D, 3D 로 변환하여 시각화해 직관적으로 데이터 분석이 가능하게 한다.
- Curse of dimensionality를 완화한다(mitigate)
Dimensionality reduction 기술
- PCA
- Outlier detection : 이상치 탐지. 데이터 집합에서 일반적인 패턴과 크게 벗어나는 데이터 포인트
**Noise : Observation errors, random errors in the system.제거해야될 대상이 아님.
Curse of dimensionality
고차원에서 데이터에서 발생하는 여러 문제들
- 희소성(Sparsity) : 차원이 높아질 수록 데이터가 분산되어있다. -> 밀도 감소
- 데이터 희소성에 따른 샘플 크기 증가
==================================================================
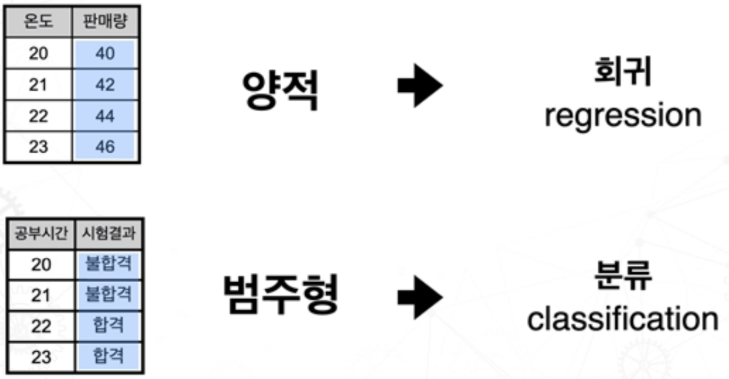
회귀
독립변수와 종속변수 간의 관계를 수학적 모델로 표현한다.
- Simple Regression : 하나의 독립변수 - 하나의 종속변수 관계 모델링
ex) 주택 가격을 예측하는 경우, 주택의 크기(단일 독립 변수)와 주택 가격(종속 변수) 간의 관계를 단순 회귀 분석을 사용하여 모델링할 수 있다.- Multiple Regression : 여러개의 독립변수 - 하나의 종속변수 관계 모델링
ex) 주택 가격을 예측하는 경우, 주택의 크기뿐만 아니라 위치, 건물 연식, 주변 시설 등 여러 개의 변수(다중 독립 변수)가 주택 가격(종속 변수)에 영향을 미칠 수 있다.
==================================================================
Performance Measurement
Generalization capabilities (일반화 능력) 이란
Performance on new data not used for learning 이다.
현장에 설치하여 성능을 측정하는 것이 일반화 능력을 확인하는 좋은 방법이지만, 비용 문제때문에 현실적으로 어렵다. 따라서, 주어진 데이터를 세분화하여 모델의 일반화 능력을 평가할 수 있는 방법을 찾아야 하는데,
학습 데이터와 검증 데이터를 나누거나(Divide into Training/Validation/Test),
교차검증(Cross Validation)을 하는 방법이 있다.
Divide into Training/Validation/Test
모델이 훈련 데이터에 과적합되지 않도록 Training/Validation/Test 데이터를 적절히 나누는 것이 중요하다. 과적합된 모델은 훈련 데이터에는 높은 성능을 보이지만, 새로운 데이터에는 일반화되지 못해 성능이 떨어진다.
- training data : 모델을 학습시키는 데 사용한다.
- validation data : 훈련 과정에서 모델의 성능을 평가하여 최적의 하이퍼파라미터를 선택하는 데 사용된다.
- test data : 훈련과 검증 과정에서 사용되지 않은 데이터로, 모델의 성능을 측정한다.
Hyper Parameter
머신러닝 모델의 학습 과정 및 성능에 중요한 영향을 미치는 파라미터로, 모델 학습 전에 설정되며 학습 중에 수정되지 않는다.
한계
단순히 데이터 셋을 분리하는 것은 한계가 존재한다.
테스트 데이터에 운좋게 쉬운 샘플이 들어가거나, 어려운 샘플이 들어가면 우연적으로 성능이 높아지거나 낮아질 수 있다. 따라서 일반화 성능(Generalization capabilities)을 평가하기 어렵다. 이를 해결하기 위해 Cross Validation을 사용할 수 있다.
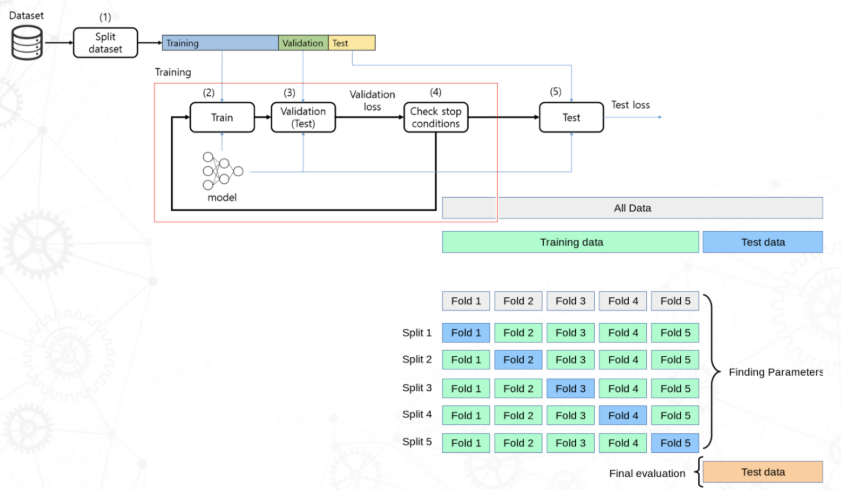
K-fold Cross Validation
데이터를 여러번 나누어 모델을 학습하고 평가
1. training data set을 k개의 subnet으로 devide
2. k번의 반복을 수행하는데, 각 반복에서 k개의 폴드 중 하나를 validation set으로 활용하고 나머지를 training set으로 모델을 학습시킨다.
3. k번의 반복 동안의 성능 평가 지표를 평균 내어 최종 성능을 평가한다.
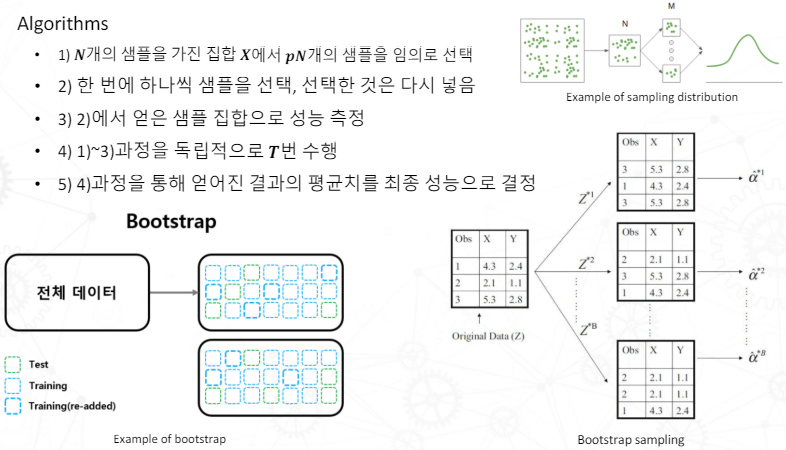
Resampling을 통한 perfromance evaluation
Resampling을은 데이터를 다시 샘플링하는 기법인데, 대표적인 기법으로 Bootstrap과 Cross Validation이 있다.
모델의 perfromance evaluation을 위해서는 데이터셋을 리샘플링하고 학습하여 사용해야 하는데, 이때, Bootstrap과 Cross Validation이 사용되는 것이다.
Overfitting
훈련 데이터를 overlearning 하여 훈련 데이터에는 높은 성능을 보이지만, 새로운 데이터에는 안좋은 성능을 보이는 현상이다. (문제 전체를 포괄하기 않고, 일부 경우에만 초점을 맞추게 됨)
문제의 복잡성에 비해 데이터가 상당히 부족(lack)할 때 발생한다.
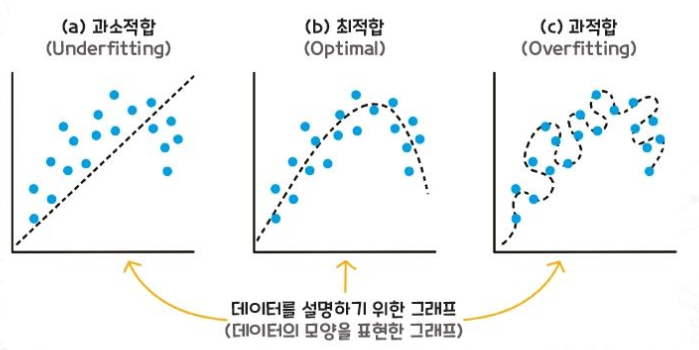
Image processing