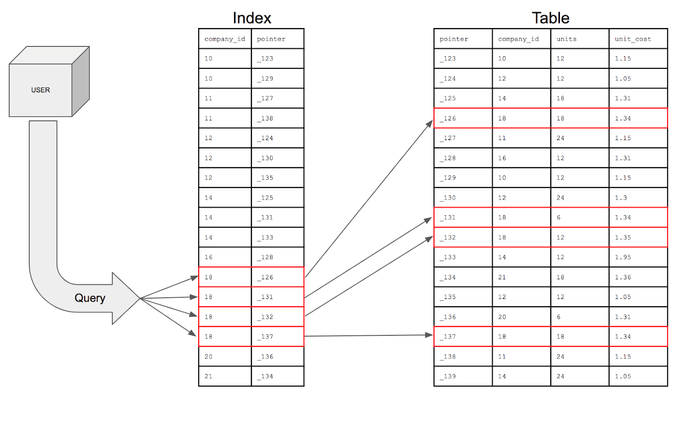
1. 인덱스
컬럼을 색인화하여 테이블 검색 속도를 향상 시키기 위한 자료구조
- 과정: 테이블의 특정 컬럼에 인덱스를 생성하면, 해당 컬럼의 데이터를 정렬한 후, 별도의 메모리 공간에 컬럼값과 데이터 물리적 주소를 (key, value) 값으로 저장한다.
- 장점
- 조회 성능 향상
- 단점
- 추가적인 작업 및 메모리 공간 필요
- 잘못 사용하는 경우 오히려 성능 저하
데이터의 수정이 잦은 경우, 매번 인덱스를 재정렬해야 한다. 또한, 인덱스는 데이터를 삭제하지 않고 '사용하지 않음' 상태로 두기 때문에 실제 데이터보다 인덱스 크기가 과도하게 커질 수 있다. 컬럼의 도메인 range가 적은 경우, 인덱스를 읽고 나서도 많은 데이터를 조회해야 해서 오히려 성능이 저하될 수 있다.
2. 인덱스의 자료구조
인덱스는 대표적으로 해시 테이블과 B+Tree로 구현할 수 있다.
1) 해시 테이블
key와 value를 한 쌍으로 데이터를 저장하는 자료구조
해시 충돌이라는 문제를 제외하면 O(1)의 성능으로 조회가 가능하다.
하지만, 해시 테이블은 데이터가 정렬되어 있지 않아 등호(=)연산에 최적화가 되어있고, 부등호 연산에는 좋지 않아 잘 사용하지 않는다.
2) B+Tree
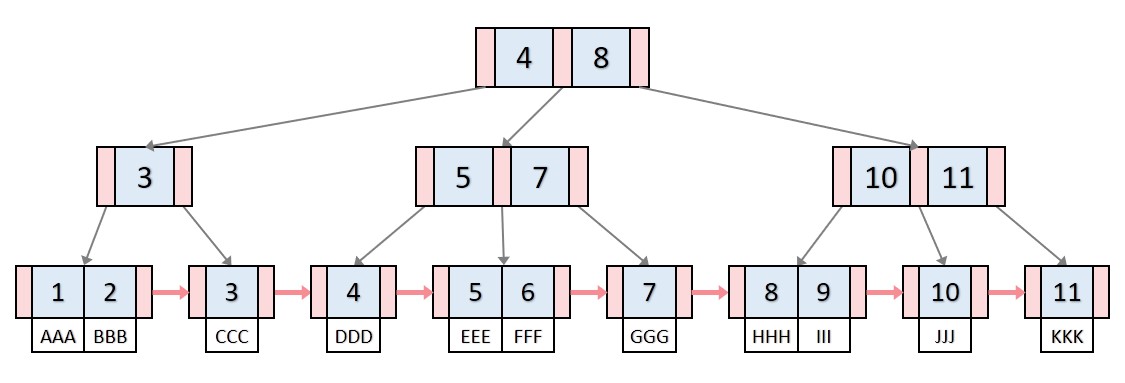
B-Tree와 연결리스트가 합쳐진 자료구조이다. 모든 중간 level의 노드들은 포인터 역할로 leaf node에 데이터 값이 저장되어 있다. 그리고 leaf node들은 연결리스트로 연결되어 있어 중간에도 다음 노드의 탐색을 효율적으로 할 수 있다.
B-Tree: 탐색 성능을 높이기 위해 균형있게 높이를 유지하는 Balanced Tree이다. 모든 leaf node가 같은 level로 유지되도록 맞춰준다.
다음 포스팅
클러스터드 인덱스
https://velog.io/@kku64r/clusteredindex
참조

SSAFY 7기. HMG. 협업, 소통, 사용자중심