DB
1.DB란? RDBMS와 NoSQL
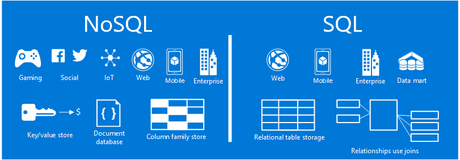
특정 목적에 필요로 공유하여 사용할 수 있도록 통합해서 저장한 운영 데이터의 집합통합 데이터 : 최소의 중복과 통제 가능한 중복만 허용하는 데이터저장 데이터 : 사용자가 접근할 수 있는 매체에 저장된 데이터운영 데이터 :조직의 주요 기능을 수행하기 위해 필요한 데이터공
2.정규화와 역정규화
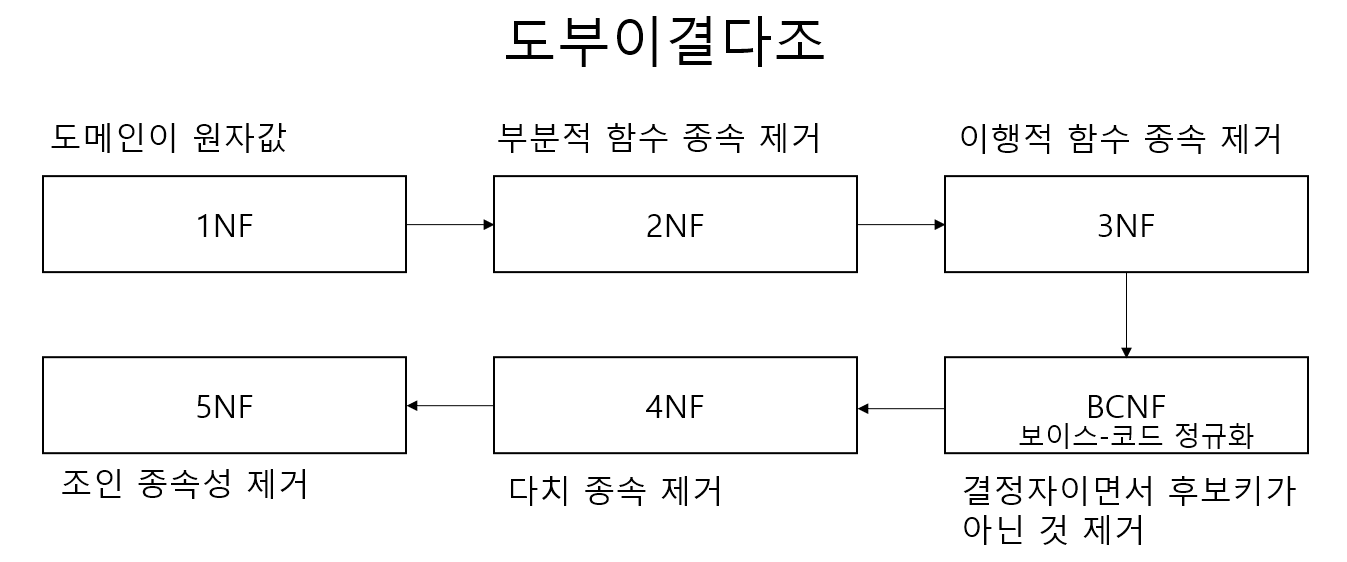
관계형 데이터베이스에서 테이블을 분리시켜 중복을 최소화하는 과정목적: 이상 현상을 방지하기 위해장점중복을 제거하여 공간 절약데이터 무결성을 보장하여 정확성과 일관성을 유지삽입, 삭제, 갱신 이상의 발생을 방지단점검색 시 성능 저하 👉 Join을 통해 연관 데이터를 가
3.인덱스란 무엇인가?
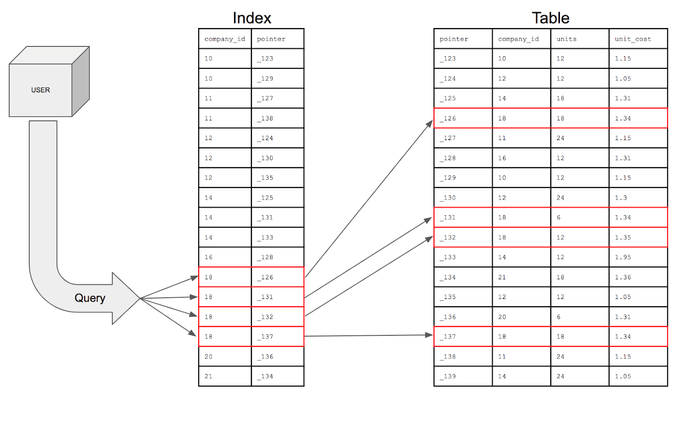
컬럼을 색인화하여 테이블 검색 속도를 향상 시키기 위한 자료구조과정: 테이블의 특정 컬럼에 인덱스를 생성하면, 해당 컬럼의 데이터를 정렬한 후, 별도의 메모리 공간에 컬럼값과 데이터 물리적 주소를 (key, value) 값으로 저장한다.장점조회 성능 향상단점추가적인 작
4.클러스터드 인덱스 vs 넌클러스터드 인덱스
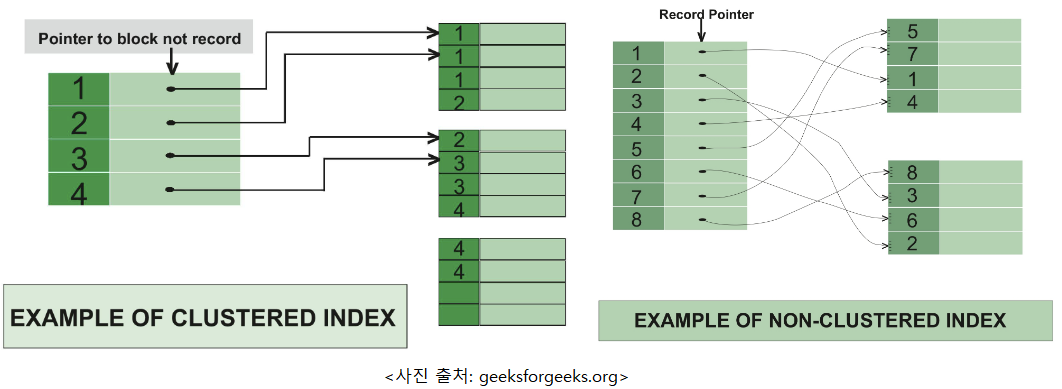
인덱스의 종류에는 클러스터드 인덱스와 넌 클러스터드 인덱스가 있다.차이는 실제 물리적인 정렬 순서와 인덱스의 정렬 순서가 같은지의 여부이다.테이블 당 1개씩만 허용. pk를 설정하면 default로 pk가 클러스터드 인덱스 컬럼이다.물리적으로 행을 재배열한다. 따라서,
5.DB 파티셔닝이란?
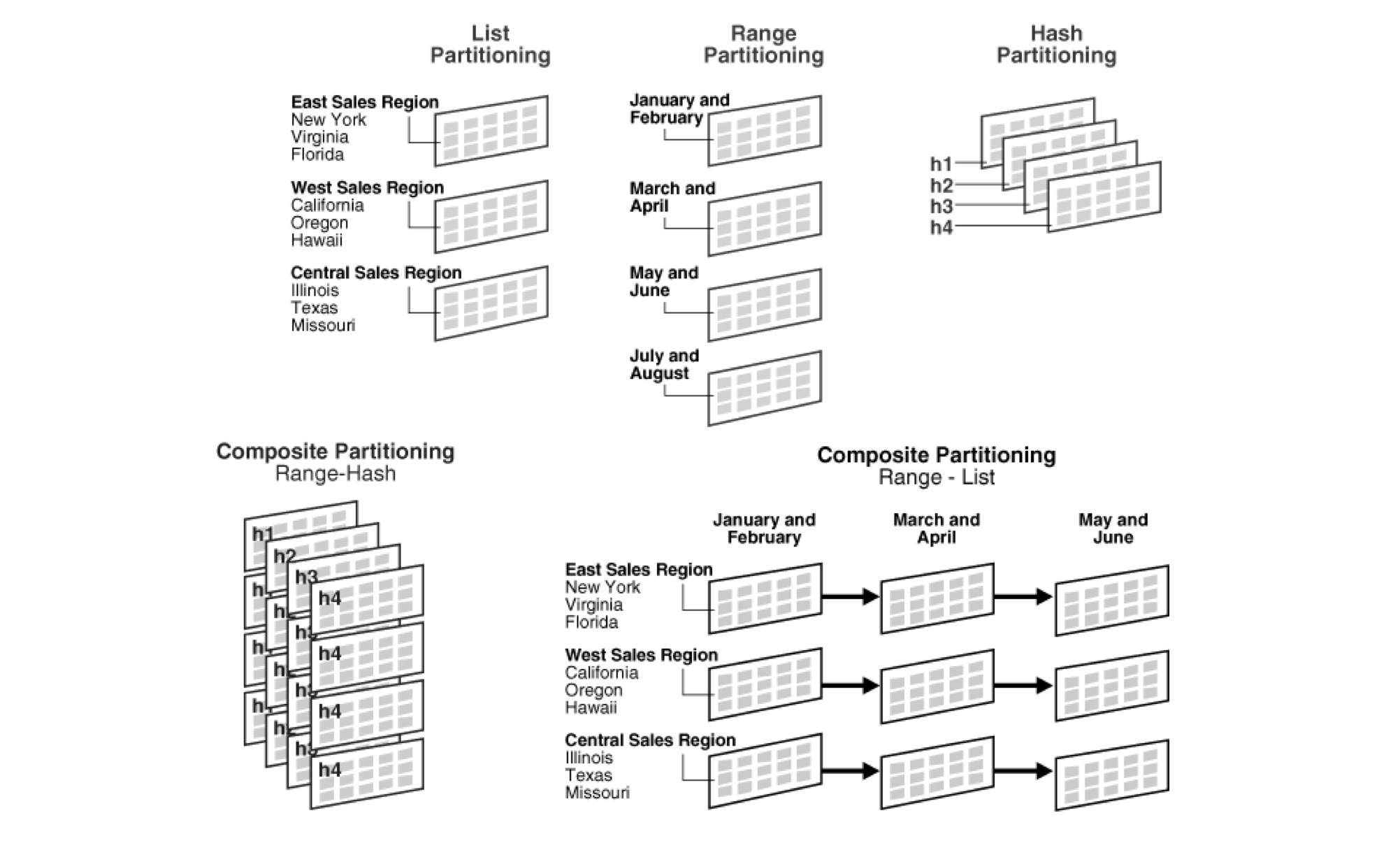
논리적인 데이터들을 다수의 entity로 쪼개는 행위데이터를 분산해서 성능을 향상. 관리 용이장점성능 향상데이터를 분할해서 저장하므로 탐색에 효율적가용성 향상데이터를 분할 저장함으로써 데이터 손실 가능성이 줄어들고 가용성 향상관리용이성 향상대용량 데이터를 기준에 맞춰
6.트랜잭션이란? (Transaction)
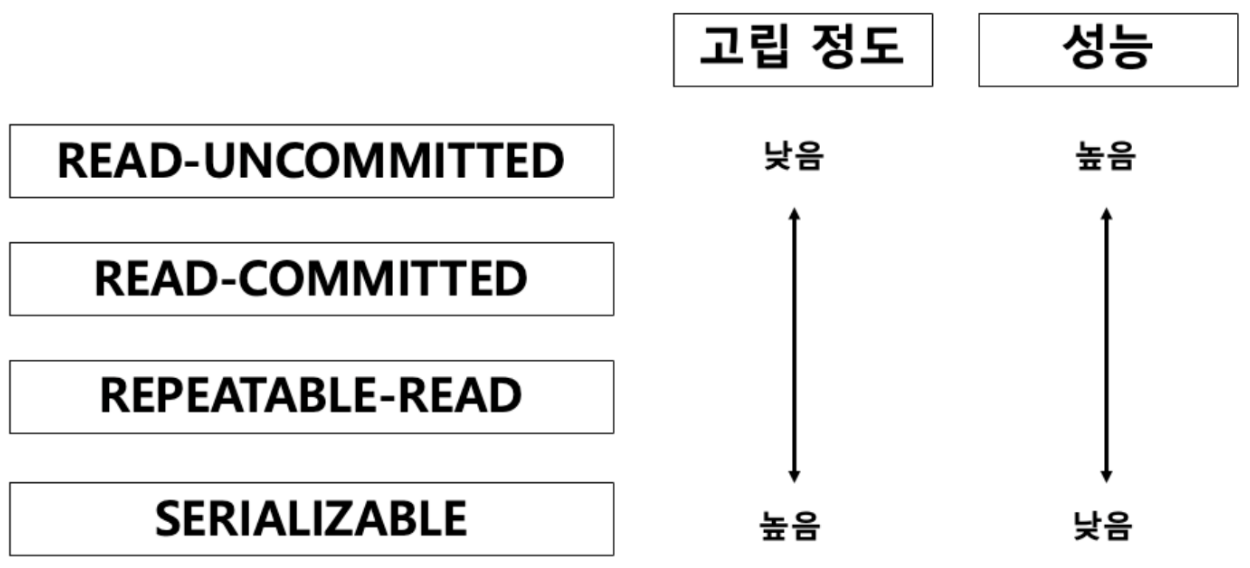
데이터베이스 상태를 변화시키는 일련의 작업 단위A 원자성: 모두 반영되거나 안돼야 한다C 일관성: 실행이 끝나면 일관성있는 상태여야 한다I 독립성: 트랜잭션은 다른 트랜잭션 연산에 끼어들 수 없다D 영속성: 실행이 끝나면 영구적으로 반영돼야 한다Commit트랜잭션에 문
7.[DB] Redis란? HA를 위한 Redis 아키텍처
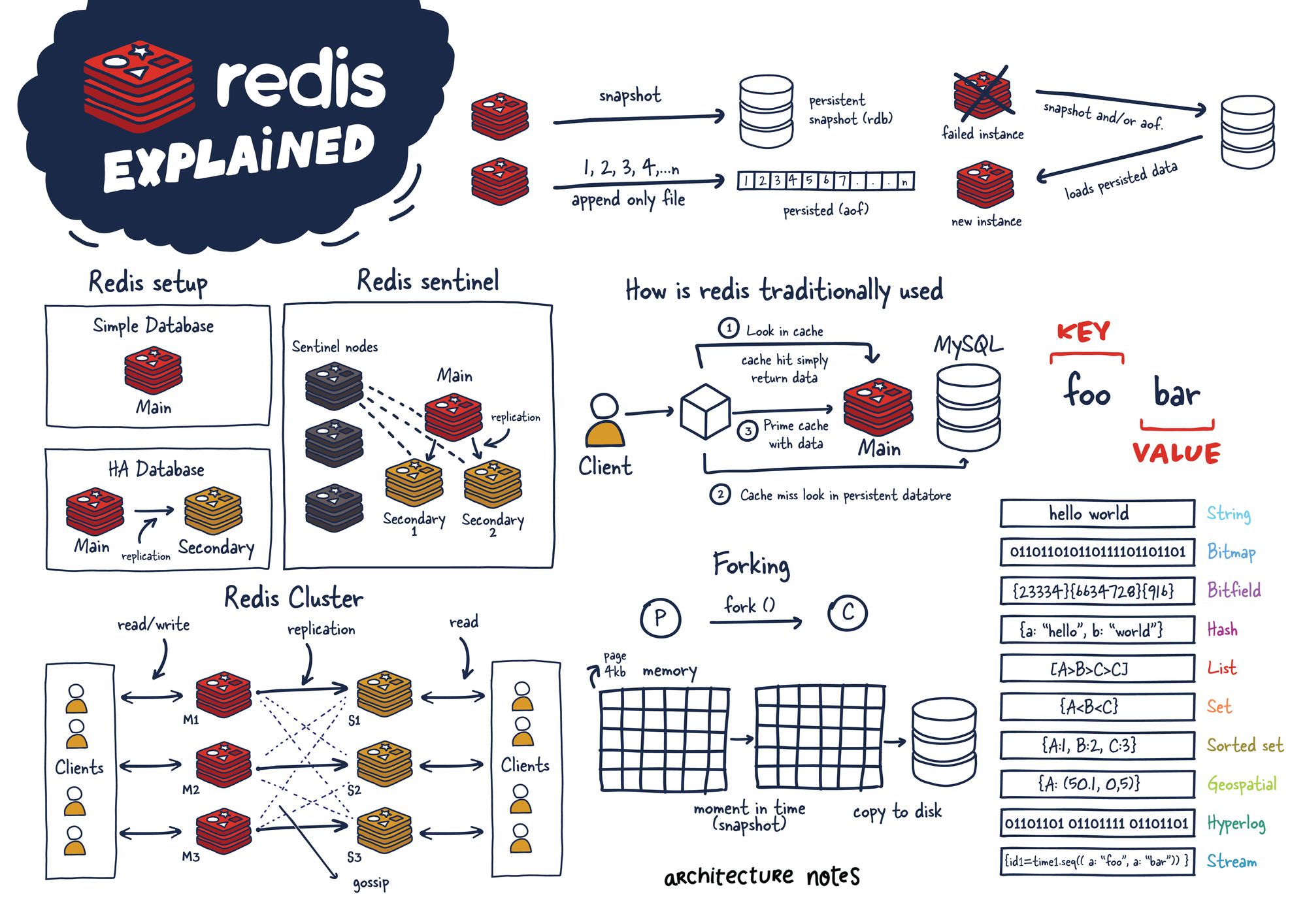
Key-Value 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈 소스 기반의 비관계형 DBMS이다. 데이터베이스, 캐시, 메세지 브로커로 사용되며 인메모리 데이터 구조를 가진 저장소이다.여러 자료구조 지원한다.String, Set, Sorted Set, Hash,
8.[DB] 조인과 서브쿼리의 차이점

평소 SQL 코테 문제를 풀 때, Join을 이용해서 푸는 편이다.하지만, 최근 얼떨결에 서브쿼리로 문제를 풀었고, Join과 Sub Query의 정확한 차이가 무엇인지 의문이 들었다. 본 포스트에서는 그 차이를 알고자 한다.\* 조인과 서브쿼리의 자세한 설명은 본 포