최근에 회사에서 새로운 업무를 맡게 됐는데,
ML 모델 학습 데이터 업데이트 및 성능 검증이다.
기존에 만들어진 모형의 학습 데이터 기간을 1년 후로 shift 한 후,
모형을 돌린 다음 성능을 비교하는 업무이다.
기존에 ML 모형의 성능 지표로 MAPE를 사용했는데,
이번에 모형 성능 지표 관련해서 개념을 정리해놓으면 좋을 것 같아서 글을 쪄본다.
부제: 내가 만든 모델은 10점 만점에 몇점?

(1) RMSE (Root Mean Squared Error)
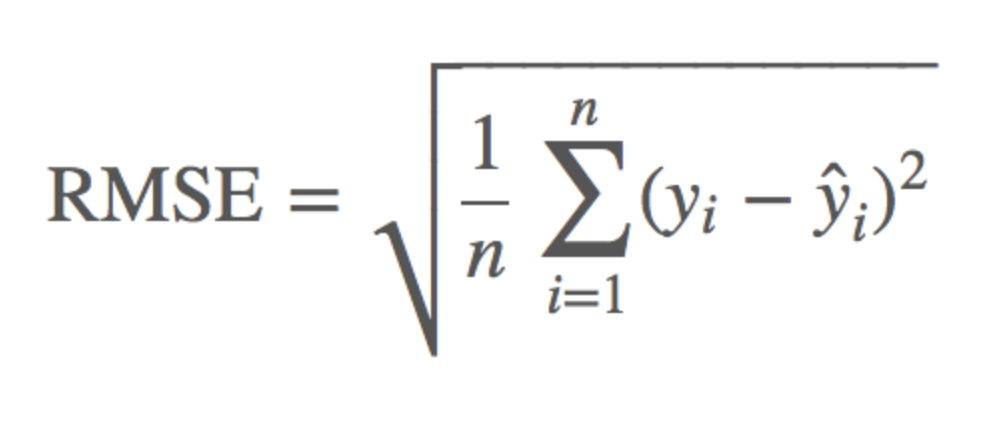
- 예측값과 실제값을 뺀 후 제곱시킨 값들을 다 더하고, n으로 나눈 후 루트를 씌운 값
(MSE 값은 오류의 제곱을 구하므로 실제 오류 평균보다 더 커지는 특성이 있음) - 평균 제곱근 편차 or 표준편차와 공식이 같음
- 모델의 예측 값과 실제 값의 차이를 하나의 숫자로 표현할 수 있음
- 에러에 따른 손실이 기하 급수적으로 올라가는 상황에서 쓰기 적합함
- 단점) 예측 대상의 크기에 영향을 바로 받게 됨 (크기 의존적 에러)
from sklearn.metrics import mean_squared_error
RMSE = mean_squared_error(y, y_pred) ** 0.5(2) MAPE (Mean Absolute Percentage Error)
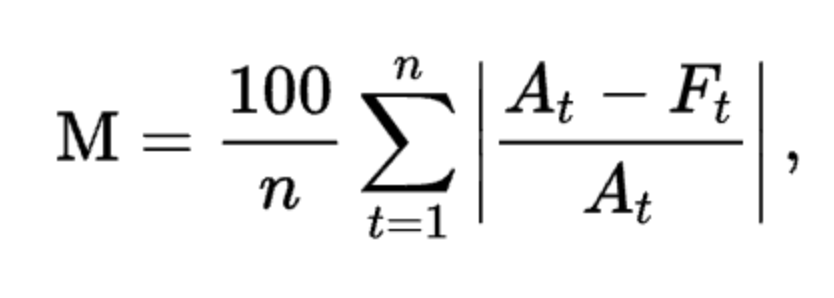
At: 실제 값
Ft: 예측 값- 예측 값과 실제 값을 뺀 후 이를 실제 값으로 나눈 값의 절대값을 모두 더한 후 n으로 나누고, 100(백분율 표현)을 곱한 값
- 산식 특성 상 백분율로 변환하기 위해 실제 값인 y로 나눠주는 방법을 취하고 있기 때문에 도출되는 값이 y에 의존적인 특성을 지니고 있음 (분자가 작더라도 분모가 더 작아지면 오차가 커지게 됨)
- 퍼센트(%)의 값을 가지며 0에 가까울수록 회귀 모형의 성능이 좋다고 해석할 수 있음
- 크기 의존적 에러의 단점을 커버하기 위한 모델
(오차 변동폭을 실제 값으로 나누면 비율 상 같은 기준으로 비교할 수 있음) - 데이터 값의 크기와 관련된 것이 아닌 비율과 관련된 값을 가지기 때문에 다양한 모델, 데이터의 성능 비교에 용이함
- 단점) 실제 값이 1보다 작은 경우, 무한대에 가까운 값을 찍을 수 있으며 실제 값이 0이라면 값 자체를 계산할 수 없음
import pandas as pd
from sklearn.metrics import mean_absolute_percentage_error
# 사용자 정의 함수
def MAPE(data):
data["Absolute Percentage Error"] = abs((data["Real"] - data["Prediction"])/data["Real"]) * 100
mape = data["Absolute Percentage Error"].mean()
return mape
# scikit-learn 라이브러리에 구현되어 있는 MPAE 값을 반환하는 함수
mape = mean_absolute_percentage_error(data["Real"], data["Prediction"])(3) MASE (Mean Absolute Scaled Error)
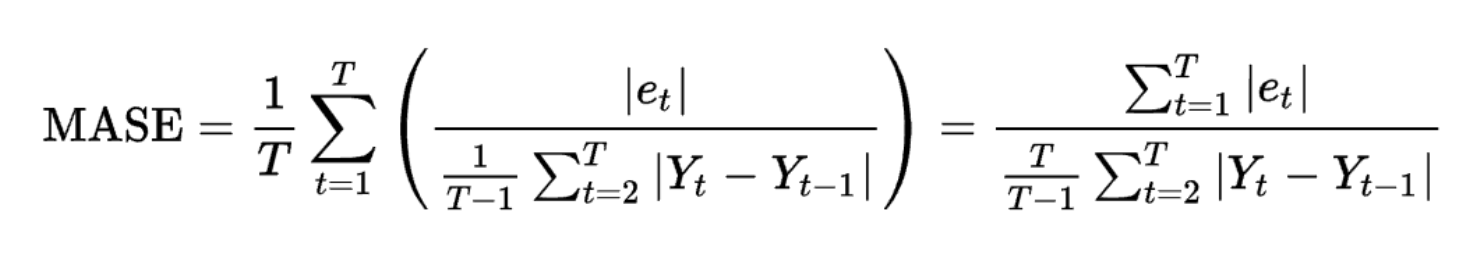
- 예측 값과 실제 값의 차이를 평소에 움직이는 평균 변동폭으로 나눈 값
: 평소 변동폭에 비해 얼마나 오차가 차이가 나는지를 측정하는 기준 - RMSE, MAPE와 접근 방식이 다름
- 변동성이 큰 지표와 변동성이 낮은 지표를 같이 예측할 필요가 있을 때 유용하게 쓰임
(4) RMSSE (Root Mean Squared Scaled Error)
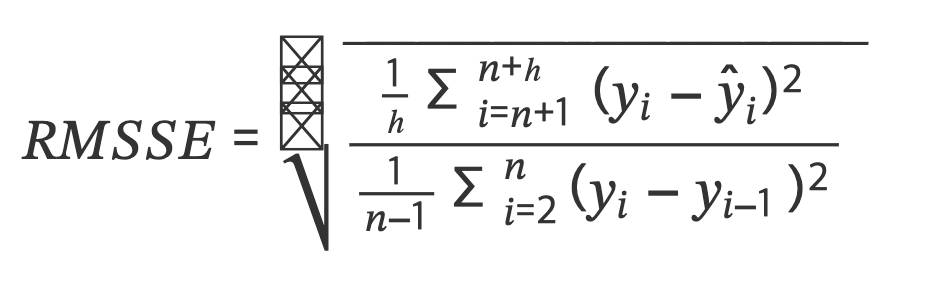
𝑦𝑖: 예측 대상인 실제 값
𝑦̂𝑖: 모델에 의한 예측 값
𝑛: 훈련 데이터셋(train dataset)의 크기
ℎ: 시험 데이터셋(test dataset)의 크기- MASE의 변형된 형태로, MAPE가 지닌 문제점 해결
- MAPE: MAE를 스케일링(scaling)하기 위해 시험 데이터의 실제 값과 예측 값을 활용하기 때문에 오차의 절대값이 같아도 과소, 과대추정 여부에 따라 패널티가 불균등하게 부여됨
- RMSSE: MSE를 스케일링 할 때 훈련 데이터를 활용하므로 이러한 문제에서 벗어남
: 훈련 데이터에 대해 naive forecasting(가장 최근 관측값으로 예측)을 했을 때의 MSE 값으로 나눠주기 때문에 모델 예측값의 과소, 과대 추정에 따라 오차 값이 영향을 받지 않음
RMSSE > 1: naive forecast 방법보다 예측을 못한다는 뜻
RMSSE < 1: naive forecast 방법보다 예측을 잘한다는 뜻출처:
https://brunch.co.kr/@chris-song/34
https://acdongpgm.tistory.com/102
https://computer-nerd-coding.tistory.com/2?category=1018603
https://mizykk.tistory.com/102

connecting the dots