코드 참고
https://bitbucket.org/VioletPeng/language-model/src/master/
요약!!
- Automatic storytelling
- title(topic)을 입력 받아 스토리를 작성하는 open-domain story generation을 진행하겠다
1. Storyline 계획
2. Storyline 기반으로 story 생성 - 두가지 planning strategies 비교
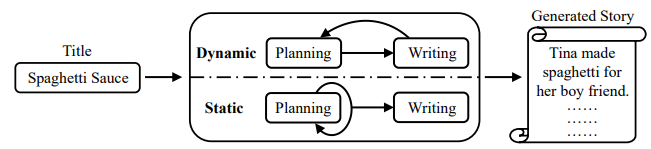
1. Dynamic schema : story planning과 surface realization(실제 story 문장)를 함께 텍스트로 생성
2. Static schema : 이야기를 생성하기 전에 전체 storyline 계획 - 결론:
명확한 storyline planning을 사용하면 생성된 스토리가 automatic and human evaluation 모두에서 사용하지 않은 스토리보다 더욱 diverse, coherent, and on topic하다!
Introduction
- Automatic Storytelling
- Prior Works :
- Composing a sequence of events that can be told as a story by plot planning
- Case-based Reasoning
- annotation에 너무 크게 의존하거나 도메인이 제한되는 문제!
- Prior Works :
- 따라서 주어진 topic(title)에서 NL story generation을 하겠다 : Dialog planning (Nayak et al. 2017)과 Narrative planning (Riedl and Young 2010)에 영감을 받아 크게 두 단계로 진행
- Story planning with generates plots
- Surface realization which composes natural language text based on the plots
- propose Plan-and-Write hierarchical generation framework
- how to represent and obtain annotations for story plots?
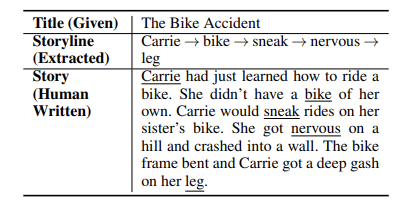
- 스토리에서 단어가 나타나는 순서를 사용해 annotation
- ex :
- 장점
- storyline representation이 간단하기 때문에, 기존 story에서 storyline을 추출하여 train 데이터를 자동으로 생성할 수 있다
- 간단하고 해석가능한 storyline representation을 통해 plan-and-write strategies를 비교할 수 있다
- 특히, dynamic schema와 static schema를 잘 비교할 수 있었음!! (뒤에서 더 설명..)
- dynamic schema : writing 동안 즉흥적으로 plot 조정
- static schema : writing 전에 전체 plot 계획
- 특히, dynamic schema와 static schema를 잘 비교할 수 있었음!! (뒤에서 더 설명..)
- Contribution!
- 스토리라인을 활용해 생성된 스토리의 다양성과 일관성을 개선하는 plan-and-write framework 제안 + dynamic & static schema의 비교
- 생성된 스토리의 다양성을 측정하기 위한 evaluation metric 개발 + human evaluation을 위한 스토리의 다양한 측면의 중요성을 조사하기 위해 새로운 분석 수행
- plan-and-write 모델은 계획하지 않은 모델보다 더 diverse, coherent, and on-top stories다!
Plan-and-Write Storytelling
- Plan의 장점
- Storyline planning이 더욱 coherent하고 on-topic한 스토리를 생성하는 것에 도움이 됨
- plan-and-write schema는 (abstract) storyline level에서 H&C interaction과 collaboration이 가능하다
Problem Formulation
1. Input:
- title : t_i (i-th word in the title)
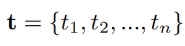
2. Output:
- stroy : based on a title, s_i (sentence in the story)
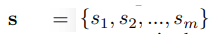
3. Storyline
- stoyline : intermediate step to represent the plot of a story, l_i (word in a storyline)
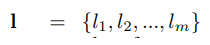
Storyline Preparation
- Training data for storyline planner
- 존재하는 story corpora에서 storyline을 만들기 위한 sequences of words 추출
- 한 문장에서 한단어 추출! -> RAKE 알고리즘 사용
- RAKE algorithm: 중요한 단어에 가중치를 부여해서 추출하는 알고리즘
Methods
1. Dynamic Schema
- emphasize flexibility
- 각 step에서 storyline의 다음 단어와 story의 다음 문장을 생성한다
- 기존의 storyline과 previously generated sentence가 모델에 제공되고 한단계 앞으로 간다
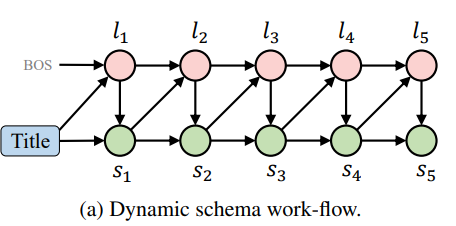
- 기존의 storyline과 previously generated sentence가 모델에 제공되고 한단계 앞으로 간다
Storyline Planning
- Storyline은 context(title+previously generated sentences)에 기반으로 plan됨
- Content-introducing generation problem:
the new content(the next word in the storyline) is generated based on the context and some additional information(the most recent word in the storyline)- ctx :
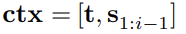
- [Encoding] hidden vectors for context :
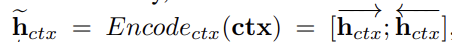
- ctx :
- Content-introducing generation problem:
- BiGRU (Yao et al. [2017])를 이용해 Context를 벡터로 encoding
- [Decoding] 그후 the auxiliary information(이 경우엔 이전 storyline word)을 decoding process에 통합한다
- BOS : beginning of decoding
- C_att : attention-based context computed from ~h_ctx
- g(-) : MLP
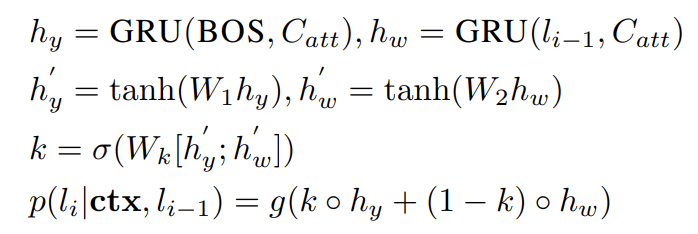
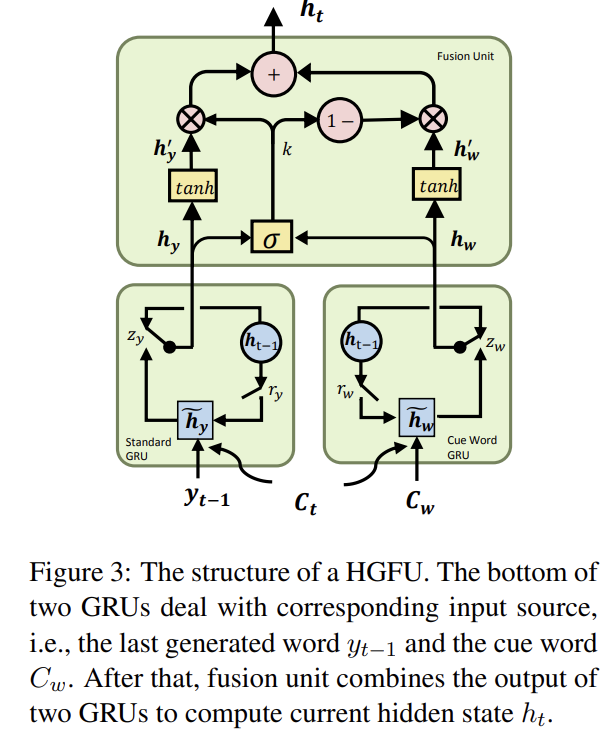
Story Generation
- 번갈아가며 planning과 writing 진행
- content-introducing generation problem
- the context & an additional storyline word를 cue로 사용해 story sentence 생성하는 방식
- 그러나! storyline generation과 story generation에는 차이가 있다는 사실!
- Storyline : 단어만 생성
- Story : variable-length sequence 생성 (즉, 문장을 생성한다!)
- content-introducing generation problem
- 그리고 storyline과 story generation 모델은 각각 따로 학습된다!
2. Static Schema
- 작가들이 보통 전체 스토리를 구상한 후 집필하는 것에 영감을 받아 개발한 방식!
- 먼저 story writing 동안 변화되지 않는 whole storyline을 생성한다
- 따라서 약간의 flexibility는 부족하다
- 하지만 "look ahead"하기 때문에 story coherence를 상승시킬 수 있다는 엄청난 장점이~
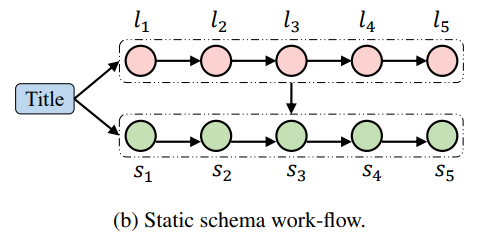
- 먼저 story writing 동안 변화되지 않는 whole storyline을 생성한다
Storyline Planning
- Dynamic schema와 다르게 title t를 기반으로 storyline planning이 홀로 진행된다
- Conditional generation problem:
the probability of generating each word in storyline depends on the prvious words in the storyline and the title - Adopt Seq2Seq model
- [Encoding] BiLSTM을 이용해 title을 먼저 벡터로 인코딩한 후
- [Decoding] 또 다른 single-directionl LSTM을 사용해 storyline의 다음 단어 생성
- Hidden vectors for a title :
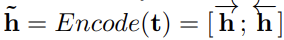
- 따라서 Conditional Probability는
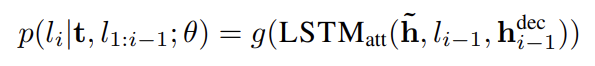
- LSTM_att : a cell of the LSTM with attention mechanism
- h-dec_i-1 : decoding hidden state
- g(-) : MLP
- Hidden vectors for a title :
- Conditional generation problem:
Story Generation
- Story는 full storyline이 생성된 뒤 만들어진다!
- Conditional generation problem
- title과 planned storyline을 BiLSTMs로 함께 인코딩한 후 Seq2Seq model을 훈련시킴
Experimental Setup
Dataset
- ROCStories corpus (저번 김지원님이 발표하신 논문에서 배포한 데이터!)
- Train & Test : 98,162 & 1,817 short commonsense stories
- 5개의 문장으로 구성되어 있으며, 해당 모델을 train하기에 좋은 데이터!
- Train 데이터에만 title로 사용할 제목이 포함되어 있으므로 해당 데이터만 사용
- Train 데이터를 8:1:1로 분할
Baselines
- Planning module이 없는 모델을 baseline으로 사용
1. Inc-S2S
- Incremental Sentence-to-sentence generation baseline
- title이 주어지면 첫번째 문장을 생성하고, 이전 문장에서 다음 문장을 계속 생성
- Planning 없는 Dynamic Schema 와 닮았다!
2. Cond-LM
- Conditional language model baseline
- title이 주어지면 전체 story를 word by word로 생성
- Planning이 없는 Static Schema 와 닮았다!
Evaluation Metrics
1. Objective metrics
- 우리의 목표는 Turing Test를 통과할 수 있는 인간과 같은 스토리를 생성하는 것이다!
따라서 BLEU같은 n-gram 중첩 기반한 평가 메트릭은 적합하지 않다- 새로운 automatic evaluation metric을 설계해서 평가하겠다
- Neural Generation model은 반복적인 content를 생성한다는 문제가 있음
- 따라서 스토리 전반에 걸쳐 diversity를 정량화할 수 있도록 설계했다

- 따라서 스토리 전반에 걸쳐 diversity를 정량화할 수 있도록 설계했다
- 2가지 측정 설계 : Inter-story repetition & Intra-story repetition
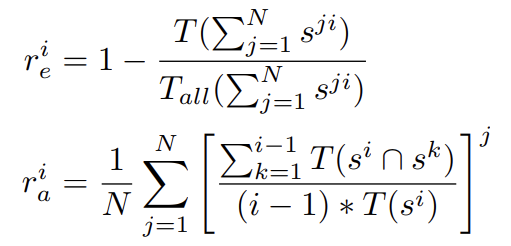
- T(.) & T_all(.) : the number of distinct and total trigrams
- s-ji : i-th sentence in j-th story
- s-i ∩ s-k : thd distinct trigram intersection set btw sentence s-i & s-k
- r-i_e : repetition rate btw stories at sentence position i
- r-i_a : the average repetition of sentence s-i comparing with former sentences in a story
- Aggregate scores
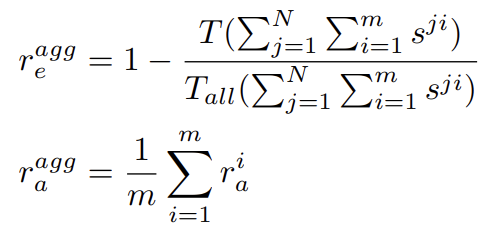
- 여기서는 m=5
- r-agg_e : the overall repetition of all stories
2. Subjective metrics
- Human evaluation에 의존하겠다! -> Amazon Mechanical Turk
- Pairwise comparison
- 유저에게 2가지 generated story를 제공하고 뭐가 더 나은지 물어봄
- 4가지 항목을 측정했다
- fidelity (스토리가 주어진 title과 관련있는지)
- coherence (스토리가 논리적으로 일관성이 있는지)
- interestingness (스토리가 흥미로운지)
- oveall user preference (어떤 스토리를 더 좋아하는지!)
Results and Discussion
1. Objective Evaluation
- 9,816개의 story 생성
- repetition ratio 계산 (the lower, the better)
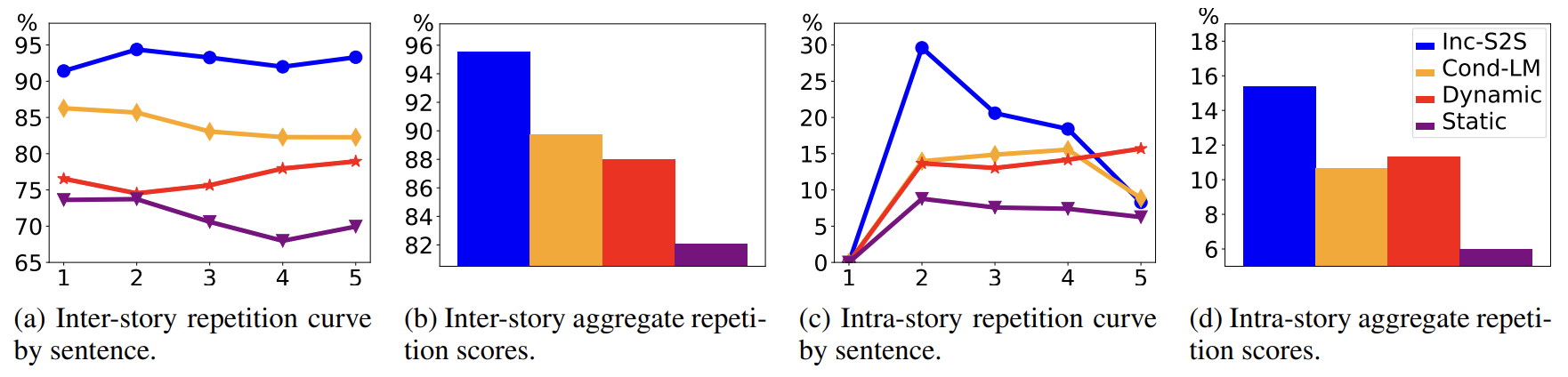
- plan-and-write framework가 효과적으로 repetition rate를 줄이고 더 다양한 스토리를 생성했다
- inter-story repetition : plan-and-write가 individual sentences & aggregate score에 대해 가장 효과적으로 성능이 좋음
- intra-story repetition : aggregate score에 대해 성능이 좋음, 근데 final sentence는 baseline에 비해 repetitive 비율이 높음
- repetition ratio 계산 (the lower, the better)
2. Subjective Evaluation
- 랜덤하게 300개의 title을 가져와서 story title과 2개의 generated story를 함께 보여준후 더 좋은 것을 고르라고 함
- 233명의 실험 참가자 (69: dynamic & Inc-S2S, 77: Static & Cond-LM, 87: Dynamic & Static)
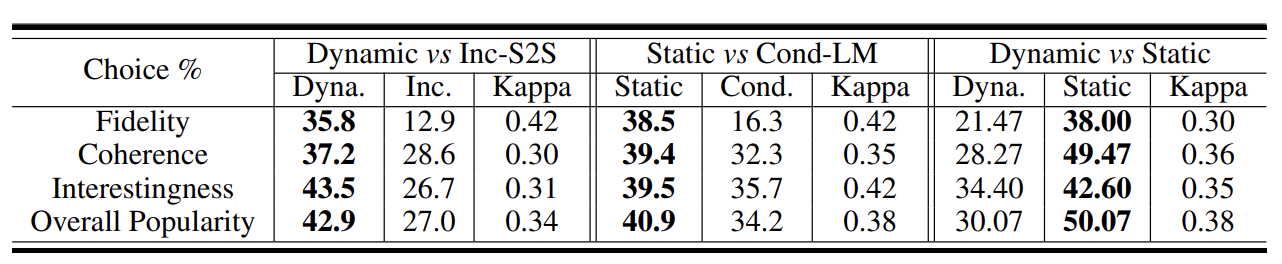
- Dynamic & Static Schema 가 훨씬 성능이 좋다!!
- 그중에서도 Static 성능이 BEST!
- 233명의 실험 참가자 (69: dynamic & Inc-S2S, 77: Static & Cond-LM, 87: Dynamic & Static)
3. Analysis
- 여기선 좀더 Dynamic 방식과 Static 방식을 비교하겠다!
Storyline analysis
- Quality of the generated storylines -> correlations btw storyline & generated story
- BLEU score!
- l-s : storyline words & generated story sentences
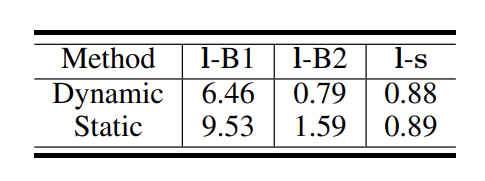
- Static schema가 BLEU기준 더 좋은 성능을 보여줌
- 또한 storyline과 비교해서도 higher correlation을 보여준다
- 이는 better storylines, it's easier to generate more relevant and coherent stories를 증명함
- l-s : storyline words & generated story sentences
- BLEU score!
Case study
- planning components가 없으면 이야기가 진행되지 않고 반복적인 문장을 생성하는 경향이 있다
- 하지만 계획을 하면 합리적인 흐름을 따르는 storyline 생성 가능!
- 따라서 적은 반복으로 일관된 이야기를 생성할 수 있다~
- 두번째 예의 dynamic schema에 의해 생성된 storyline은 일관성이 좋지 않은데, 이는 우리 프레임워크에서 storyline 계획의 중요성을 반영한다!!

Error analysis
- 수동 오류 검수
- 주제에서 벗어남, 반복적임, 논리적 일관성이 없음.
- Local context 내에서 일관된 문법 문장을 생성할 수 있지만, 여전히 논리적인 문장의 시퀀스를 생성하는 것은 어렵다ㅠ

Conclusion and Future Work
- Storyline planning을 통해 주어진 title에서 story를 생성하는 plan-and-write framework 제안!
- Dynamic & Static Schema를 사용함으로써 baseline 능가한다~
- 특히 Static Schema는 전체를 바탕으로 storyline을 계획하므로 보다 일관되고 주제와 관련있는 스토리를 생성하는 경향이 있다! 따라서 성능 더 좋음
- 현재 모델은 word sequence에서 줄거리를 대략적으로 나타내기 때문에 이야기에서 의미 구조를 너무 단순화한다
- 따라서 event나 entity, relation structure를 가지고 더 풍부한 표현으로 확장해서 story plot을 묘사할 계획인다!
- 또한 더욱 긴 문서를 생성하기 위해 plan-and-write framework를 확장시키려고 한다
- 현재는 story corpus에서 자동으로 추출된 storyline에 의존하지만, storyline induction 및 joint storyline 등을 더욱 연구해보려고 한다
끝!
느낀점
- velog 처음 쓰는데 다루기가 힘들다... notion에 너무 익숙해짐
- 지난주 지원(강)님이 발표해주신 논문의 내용이 static schema와 비슷하지만 더욱 발전된 방식인 것 같음!

wtf