다른 분의 블로그를 보고 정리한 글입니다.
https://hoons-dev.tistory.com/91?category=1091955
👻자료구조
🍀 Array 와 LinkedList가 각각 무엇인지, 어떻게 다른지 설명해주세요.
Array는 인덱스로 해당 원소에 접근할 수 있어 찾고자 하는 원소의 인덱스 값을 알고 있으면 O(1)에 해당 원소로 접근할 수 있습니다. 즉 random aceess가 가능해 속도가 빠르다는 장점이 있습니다.
하지만 삽입 또는 삭제의 과정에서 각 원소들을 shift 해줘야 하는 비용이 생겨 이 경우 시간 복잡도는 O(n)이 된다는 단점이 있습니다.
이 문제점을 해결하기 위한 자료구조가 LinkedList입니다. 각각의 원소들은 자기 자신 다음에 어떤 원소인지만을 기억하고 있기 때문에 이 부분만 다른 값으로 바꿔주면 삽입과 삭제를 O(1)으로 해결할 수 있습니다. 하지만 Linked List는 원하는 위치에 한번에 접근할 수 없다는 단점이 있습니다. 따라서 원하는 위치를 찾기 위한 serach 과정에 있어서 첫번째 원소부터 확인해봐야 합니다. 따라서 O(n)시간이 추가적으로 발생하게 됩니다.
정리하자면 Array는 검색이 느리지만 삽입, 삭제가 느리며 LinkedList는 삽입, 삭제가 빠르지만 검색이 느립니다.
🍀 Stack과 Queue에 대해 설명하고, 각각 어디에 사용되었는지 말해주세요.
Stack은 먼저 넣게 되는 자료가 마지막으로 나오게 되는 LIFO(Last In First Out) 구조입니다. top을 통해서 push, pop을 하면서 삽입, 삭제가 일어나고 DFS나 재귀에서 사용됩니다.
Queue는 먼저 넣게되는 자료가 먼저 나오게 되는 FIFO(First In First Out) 구조입니다. 한 쪽 끝에서 삽입 작업을, 다른 쪽 끝에서 삭제 작업을 진행합니다. 주로 데이터가 입력된 시간 순서대로 처리해야하는 경우에 사용하며 BFS나 캐시를 구현할 때 사용합니다.
🍀Priority Queue가 무엇이고, 어떻게 구현할 수 있는지 설명할 수 있나요?
우선순위 큐는 들어간 순서에 상관없이 우선순위가 높은 데이터를 먼저 꺼내기 위해 고안된 자료구조 입니다.
우선순위 큐 구현 방식에는 Array, Linked List, Heap 등이 있고 그 중 힙 방식이 worst case라도 시간 복잡도 O(log n)을 보장하기 때문에 일반적으로 완전 이진 트리 형태의 힙을 이용해 구현합니다.
⭐ 그렇다면, Heap이 무엇인지, 삽입 및 삭제시 어떻게 동작하는지 설명할 수 있나요?
Heap은 완전이진트리 면서, 모든 부모노드와 자식노드 간에 '크거나 같은' 혹은 '작거나 같은'의 관계를 가지고 있는 트리를 의미합니다.
삽입 및 삭제를 하면 Heap의 구조가 무너지는데, 다시 Heap으로 만드는 과정을 Heapify라고 합니다.
삽입 시 트리의 가장 마지막 노드 다음 인덱스에 새로운 노드를 집어 넣고 heapify 연산을통해 힙으로 구성합니다.
삭제 시 트리의 루트 노드를 반환 및 제거하고, 트리의 가장 마지막 인덱스를 가진 노드의 위치를 루트 노트로 이동시킵니다. 그 후 Heapify 연산을 통해 다시 힙으로 구성합니다.
삽입과 삭제 연산 모두 트리의 높이에 따라 연산횟수가 결정되며, worst case의 경우 시간복잡도는 둘다 O(log n)을 보장합니다.
🍀 해시 테이블 (Hash Table)에 대해서 설명할 수 있나요?
해시 테이블은 (Key,Value) 로 데이터를 저장하는 자료구조이고 빠르게 데이터를 검색할 수 있는 자료구조 입니다.
🍀 해시 테이블 (Hash Table)의 검색 시간 복잡도는 어떻게 O(1)을 유지할 수 있나요?
내부적으로 배열(버킷)을 사용해서 데이터를 저장하기 때문입니다.
각 Key 값은 해시 함수에 의해 고유한 index를 가지게 되어 바로 접근할 수 있기 떄문입니다.
⭐ 그렇다면 Hash Collision(해시 충돌)에 대해 설명할 수 있나요? 해결 방법은 어떻게 되나요?
해시 테이블에 접근하는 Key값은 무한하고, 해시 함수를 통해 나온 Hash 값은 유한합니다. (값이 저장되는 메모리는 한계가 있으므로)
따라서 서로 다른 Key에 대해 같은 해시값을 갖는 경우를 해시 충돌이라고 합니다.
해결 방법은, Channing 방식과 Open Addressing 방식이 있습니다.
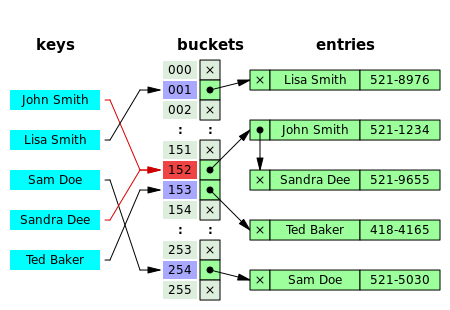
- 체이닝(Channing)
인덱스의 버킷을 연결리스트로 구현해, 이미 값이 존재하더라도 연결리스트에 해당 값을 삽입하는 방식
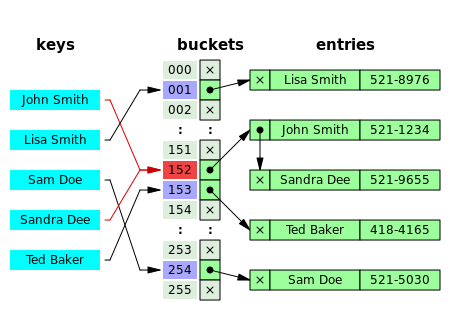
- 개방 주소법 (Open Addressing)
해시 충돌이 일어난경우, 특정한 간격만큼 이동후 비어있는 주소 값에 저장하는 방식
⭐ 그렇다면, 체이닝 방식과 개방주소법의 장단점을 비교해주세요.
-
체이닝 방식
장점: 상대적으로 적은 메모리를 사용합니다.
단점: 한 Hash에 자료들이 계속 연결된다면(쏠림현상) 검색 효율을 낮출 수 있습니다. -
개방주소법 방식
장점: 또 다른 저장공간에서의 추가적인 작업이 없습니다.
단점: 데이터의 길이가 늘어나면 그에 해당하는 저장소를 마련해두어야 합니다.
⭐ 해시 테이블의 단점은 무엇이 있을까요? 언제 사용하면 안 될까요?
해시 테이블에 있는 Key 값들은 무한하고, 해시 함수를 통해 나온 Hash값은 유한합니다. (값이 저장되는 메모리는 한계가 있으므로)
따라서 서로 다른 Key 값에 같은 Hash 값을 갖는 해시 충돌이 일어날 수 있습니다.
또한 해시 함수 의존도가 높아진다는 단점이 있습니다.
해시 테이블은 순서 없이 (Key, Value)로 저장하기 때문에 순서가 필요한 데이터에는 적합하지 않습니다.
🍀 BST (Binary Search Tree)와 BST의 특징에 대해 설명할 수 있나요?
이진 탐색 트리(BST)는 이진 탐색과 연결 리스트를 결합한 자료구조 입니다.
이진 탐색의 효율적인 탐색 능력을 유지하면서, 빈번한 입력과 삭제가 가능하다는 장점이 있습니다. 이진 탐색 트리는 왼쪽 트리의 모든 값은 반드시 부모 노드보다 작아야 하고, 오른쪽 트리의 값은 부모 노드보다 커야한다는 특징이 있습니다.
🍀 BST의 성능을 개선하기 위한 방법에는 무엇이 있나요?
이진 트리 탐색의 탐색 연산은 트리의 높이에 영향을 받아 높이가 h 일때 시간복잡도는 O(h)이며, 트리의 균형이 한쪽으로 치우쳐진 경우 worst case가 되고 O(n)의 시간복잡도를 가집니다.
이런 worst case를 막기 위해 나온 기법이 AVL, RBT가 있습니다.
⭐ AVL트리는 무엇인가요?
이진 탐색 트리의 특징을 가지고 있으며, 왼쪽, 오른쪽 서브 트리의 높이 차이가 최대 1입니다. 어떤 시점에서 높이 차이가 1보다 커지면 회전을 통해 균형을 잡아 높이 차이를 줄입니다.
삽입, 검색, 삭제의 시간복잡도는 O(log n) 입니다.
⭐ 트리와 그래프의 차이에 대해서 설명할 수 있나요?
그래프는 트리보다 더 포괄적인 개념입니다.
그래프는 각 요소를 나타내는 노드와 노드 사이의 관계를 나타내는 엣지로 구성되어 있습니다.
트리는 사이클이 없는 그래프를 의미하며, 계층 구조를 나타낼 때 용이합니다.
