IF KAKAO 컨퍼런스에서 백엔드와 관련된 세션 중 흥미가 가던 몇가지 세션의 기술적인 부분을 조사해 보았다. 깔끔하게 정리한다는 느낌보단 그냥 내가 보고 느낀 감상과 궁금한 점을 조사해서 적어보려고 한다. 혼자 생각한 넉두리에 가까운 글이니 기술적으로 틀린부분이 있을 수 있으니 그냥 이런게 있구나 정도로 넘어가 줬으면 한다.
Kakao Cloud Portal_카카오 클라우드 포털 개발 여정
카카오의 사내 클라우드 포탈을 소개하는 페이지 중에서 평소에 잘 정리가 안되던 부분이 나와 정리를 해보려고 한다. 사실 프론트엔드의 템플릿이나 보일러플레이트 부분은 잘모르는 관계로.. 그냥 그렇구나 싶었고 인증부분에서 평소 궁금하던 SSO관련 내용이 나와서 정리를 해보려고 한다. KCP(KAKAO Cloud Portal)의 인증관련 내용에서 내가 알아보려고 한 키워드는 SSO와 Keystone token 그리고 OAUTH 2.0이다. 카카오는 사내 클라우드를 통해 다양한 서비스를 제공하면서 이를 하나의 인증체계로 구축하기 위해 Single Sign On을 사용했다고 한다. 틀릴수도 있지만 if kakao에 발표내용을 토대로 전체적인 인증구조를 그려보자.

우선 KCP는 OAUTH 2.0을 따르고 있다고 한다. 세션을 봤다면 알겠지만 OAUTH2.0의 Authorization Code 방식을 선택했다고 한다. 구글의 OAUTH2.0을 해보신 분이라면 익숙한 방식이다. 아마도 대부분 이방식을 사용하는 것 같다.
발표에선 OAUTH 2.0을 토대로 Access token을 발급받고 이를 통해 keystone token을 발급받는 다고 하였다. 그러면 아래 그림과 같은 느낌이 될 것같다.
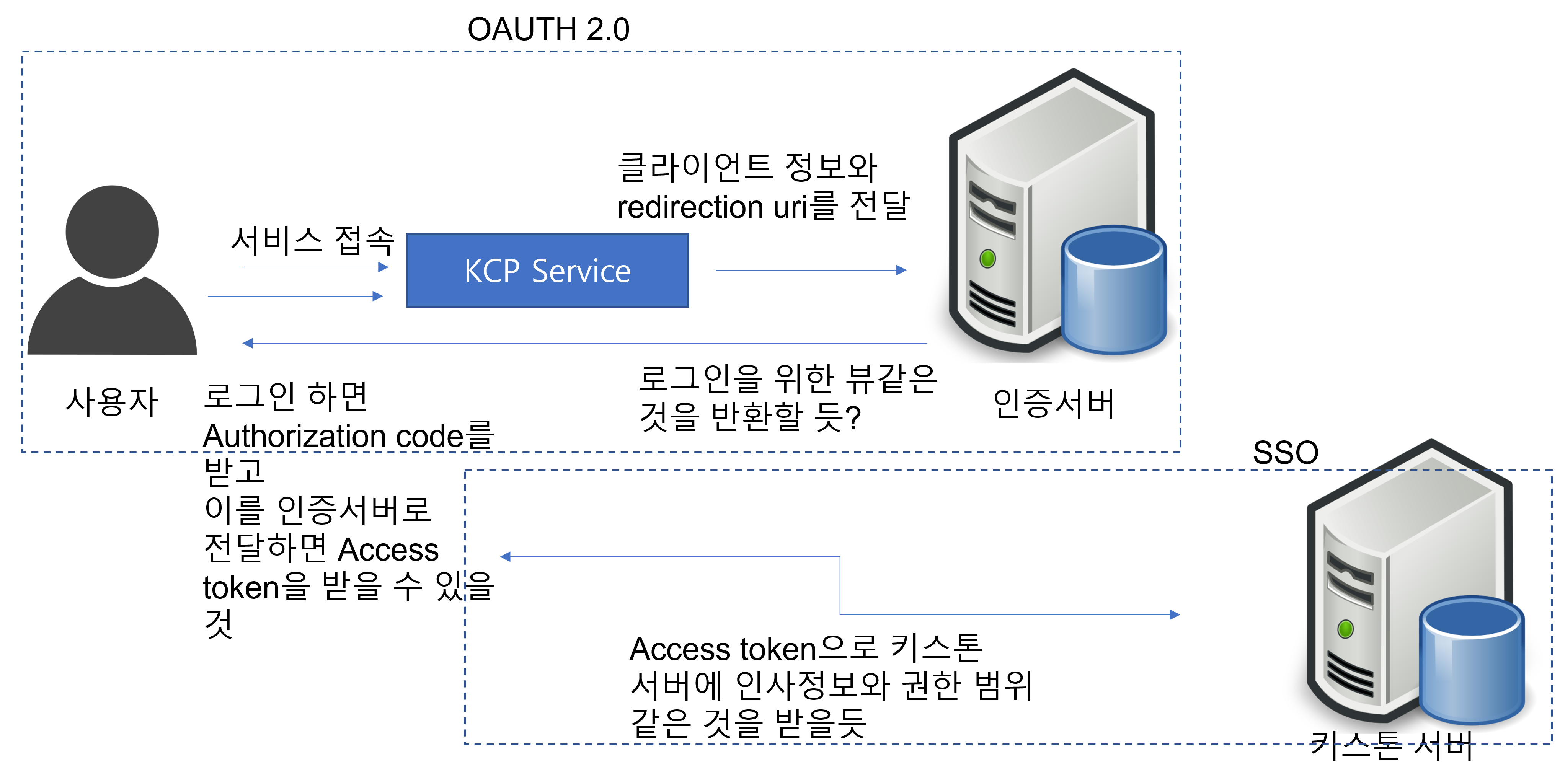
- KCP Service에 접속하면 인증서버에 클라이언트 정보와 redirection uri를 전달해서 로그인 화면 같은 뷰를 반환받을 것 같다(구글의 로그인 같은...), 규격대로 구현한다면 이때 인증의 scope를 지정해주는 것도 가능할 것
- 로그인을 하고 나면 인증서버는 Authorization code를 사용자에게 넘기고 redirection uri를 통해 전달받고 이를 다시 KCP Service로 전달하면 Access token이 발급된다.(필요에 따라 refresh token이 발급될수도 있다) 이러한 절차는 아마도 보안을 위해 로그인 과정에 클라이언트가 관여하는 것을 막기위함으로 보임, KCP는 사내시스템인데 굳이 필요할까 라는 의문이 있긴 하지만 확장성을 위해 선택했다고 한다.
- 이제 Access token으로 키스톤 서버에 키스톤 토큰과 인사정보를 요청하고 이 정보에 따라 KCP Service에 접근할 것이다. 여기서 키스톤 서버는 서비스 별 권한을 구분하고 SSO를 구현하기 위해 존재하는 것으로 보인다. 키스톤에 대한 자세한 내용은 해당 링크 참조...
위는 KCP 세션을 보고 아마도 이렇지 않을까.. 란 느낌으로 그려본 것이다. 기술적인 부분에서 잘못된 부분이나 실제 KCP에 구현과는 다를 수 있다. 이 세션은 기술적으로 특별한 내용은 없었지만 현재 내가 업무하는 곳에서 사내 Cloud Portal에서 서비스를 개발하고 있어(여기도 SSO를 사용하고 있음) SSO에 대한 평소 궁금증과 내가 업무하는 곳과는 어떻게 다른지 확인을 해보고 싶어 조사를 해보았다.
카카오톡 서버의 스프링 공화국 탈출기
톡서버 부문의 세션인데 주요내용은 해당 팀이 Spring이 아닌 프레임워크로 넘어가고자 하고 단순히 특정 프레임워크의 개발자가 아닌 코틀린 개발자를 지향하고자 한다고 한다. 그의 일환으로 코틀린 기반의 ktor라는 웹프레임워크를 도입과 관련된 내용을 다루고 있다.
해당 세션에서 제시한 스프링을 벗어나게 되어 얻는 장점을 크게 아래 2가지로 이야기 하고 있다.
-
관습에서 벗어나 표준에 맞게 개발할 수 있다.
해당 세션에선 예시로 rfc7235를 예로 들었다. 스프링의 경우 해당 표준을 지키지 않는데 반해 ktor는 비교적 최신 프레임워크 이니 만큼 시도-응답 인증을 지원하고 있다고 한다. 해당 내용은 차후 좀더 자세히 공부해 봐야겠다. 해당 링크에 친절한 누군가가 한글로 번역해둔 내용이 있다. -
복잡한 의존성 문제에서 탈출.
이 부분은 스프링 기반 어플리케이션을 개발하면서 필요한 라이브러리를 가져오다 보면 그에 따른 복잡한 의존성 문제가 발생하고 특정 라이브러리의 의존성이 어디까지 전파 되는지 알수 없다는 내용이다. 이부분은 스프링에서 벗어나면 깔끔하게 해결될지는 아직 내지식 수준에선 감이 오지 않는다.
사실 미묘하다면 미묘하다고 할 수 있는 장점이라 생각하는데 요지는 스프링에 대한 의존성에서 벗어나 개발자로서 한걸음 더 나아가자는 것이 큰 줄기라고 생각된다.
마지막으로 간략하게 ktor라는 프레임워크에 대해 알아보자. 해당 프레임워크는 intelliJ에서 개발한 프레임워크로 스프링에 비해 매우 경량의 프레임워크라고 한다. 스프링에서 기본적으로 제공되는 다양한 기능, 의존성 주입이나 JDBC같은 기능을 제공하지 않고 외부의 라이브러리를 붙여다 사용한다. 얘기를 들어보면 nodejs랑 비슷한 느낌이지 않을까 싶다.
fun Route.customerRouting() {
route("/customer") {
get {
}
get("{id}") {
}
post {
}
delete("{id}") {
}
}
}위 코드는 ktor로 crud를 정의한 코드이다. 어노테이션이 빠지고 DSL을 활용하여 매우 직관적인 코드를 정의할 수 있다.
만약 의존성주입과 같은 기능을 사용하고 싶다면 koin과 같은 외부 라이브러리를 사용하면 된다.
//gradle에 추가
dependencies {
implementation ("io.insert-koin:koin-ktor:3.1.4")
//...
}fun Application.main() {
//Ktor에서 Koin기능을 사용하는 것을 명시
install(Koin) {
//의존성 주입을 수행할 모듈 지정
modules(helloAppModule)
}
//의존성 주입
val helloService by inject<HelloService>()
routing {
get("/hello") {
call.respondText(helloService.sayHello())
}
}
}
//의존성 주입을 수행할 모듈
val helloAppModule = module {
single<HelloServiceImpl>(createOnStart = true) bind HelloService::class
single<HelloRepository>(createOnStart = true)
}위의 코드는 HelloServie와 HelloRepository 라는 기능이 존재한다 가정하고 Koin으로 의존성 주입을 정의하였다. 예시로 한번에 보여주기 위해 하나의 파일에 정의하였다. 당연히 컨트롤러 파일별로 분리도 가능하다. 기존 Spring에선 Spring의 자채 컨테이너에서 의존성주입을 위한 객체를 관리하던 것과 달리 Koin을 사용하게 되면 Koin에서 관리하는 별로의 컨테이너를 사용하게 된다. 독립적인 라이브러리인 만큼 안드로이드에서 활용하는 것도 가능한 것 같다.
스마트 메시지 서비스 개발기
아직 MSA환경에서 개발경험이 없다보니 카카오같은 대규모 트래픽을 처리해야 하는 회사에서 어떤 방식으로 서비스를 구성하는지 알고싶어 정리를 해보려고 한다.
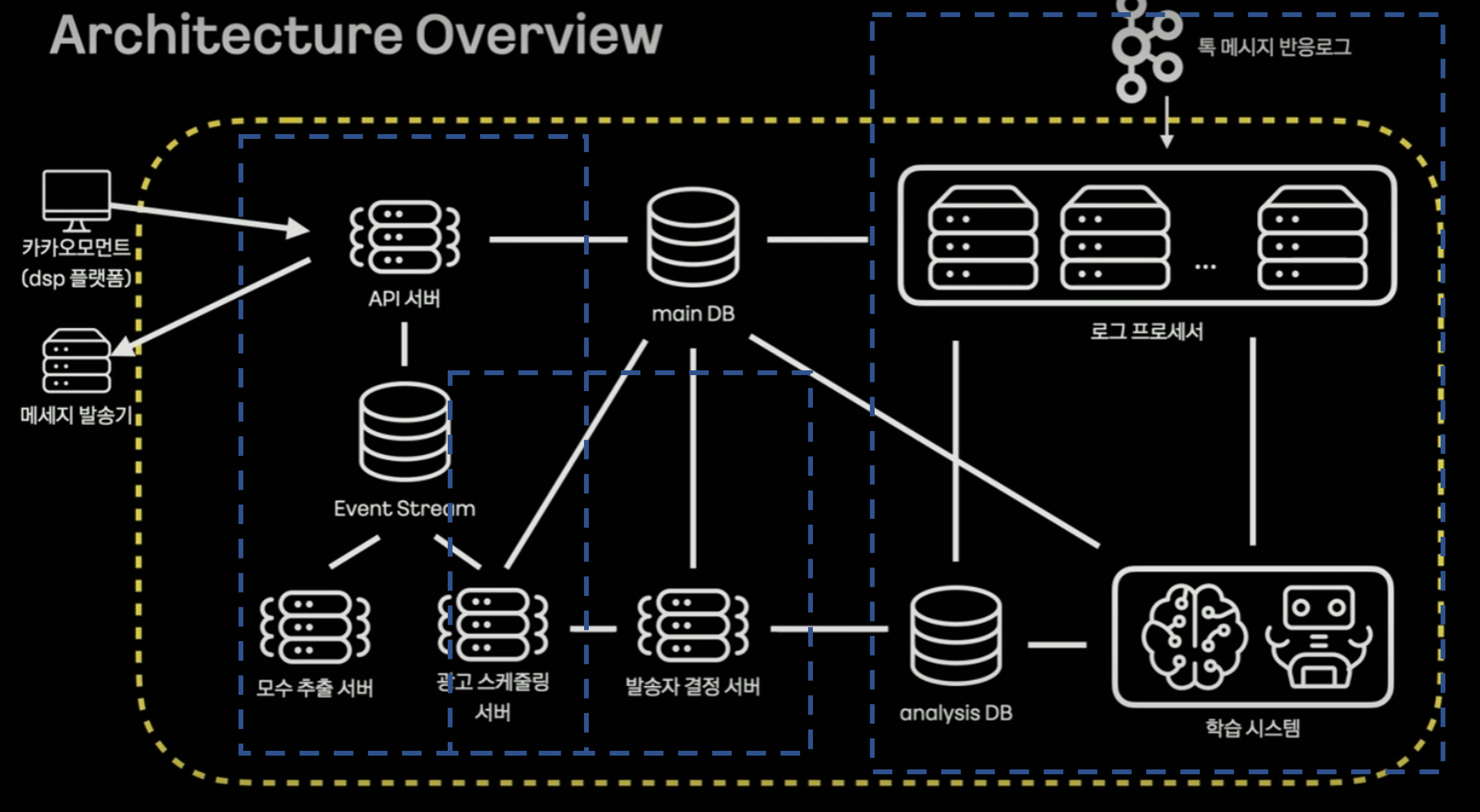
우선 세션에서 설명된 기준으로는 크게 3파트로 나눌수 있을 것 같다.
- 플랫폼과 통신하는 API서버 파트
- 광고를 스케줄링하고 결정하는 파트
- 사용자의 메시지를 처리하고 학습하는 데이터 파트
API파트
흔히 말하는 MSA의 구조를 갖고 있는 것 같다. 광고주가 플랫폼을 통해 API서버에 광고 등록을 요청하고 이를 통해 스케줄링 서버가 DB에 광고에 대한 정보를 등록하고 스케줄링을 진행하는 것으로 보인다. API 서버, 모수 추출 서버, 광고 스케줄링 서버이 3가지 요소는 이벤트 브로커인 Kafka를 사용하여 3개 서버의 트랜잭션을 수행하는 것으로 보인다. 여기서 CQRS와 Kafka Transaction이라는 요소가 나오는데 CQRS는 명령과 조회의 책임을 분리하는 것이 기본적인 컨셉으로 해당 구조에선 API서버에서 조회를, 광고 스케줄링 서버에서 명령(Insert, Update?)를 수행한다고 한다. Kafka Transaction은 분산환경에서 동기화를 위한 구성요소로 보인다. 이 2가지에 대해선 좀더 공부를 해두어야 겠다.
광고 스케줄링 파트
DB에 광고가 등록?되면 광고를 전송하라는 메시지를 RabbitMQ에 적재한다(적재하는 주체는 모르겠음). 여기서 RabbitMQ에 job queue와 delay queue로 구성이 되는데 우선 특정한 TTL을 가진 광고를 개재하라는 메시지를 job queue에 넣고 TTL이 만료되면 delay queue로 옮긴다. 그리고 delay queue에 메시지가 존재하면 광고 스케줄링 서버가 이를 consume하고 발송자 결정 서버로 전달하게 된다.
데이터 파트
이 세션에서 가장 중요한 부분인듯 하다. 사용자의 톡 정보를 수집하여 사용자에게 맞는 광고가 전달되게 하기 위해 학습을 시키는 파트로 보인다. 여기서 카프카 스트림즈라는 라이브러리가 등장하는데 카프카의 이벤트를 스트림형태로 처리하는 것을 도와주는 라이브러리로 JVM계열 언어에서 사용이 가능하다. 카프카 스트림즈는 아파치에서 공식으로 제공하는 라이브러리여서 카프카가 릴리즈 될때 마다 같이 릴리즈 되어 카프카의 새로운 기능에 빠르게 대응이 가능하다고 한다.
카프카 스트림즈는 카프카의 특정 토픽으로 부터 메시지를 받아 이를 다른 토픽으로 만들어주거나 바로 consume하는 등의 행위가 가능하다. 카프카 스트림즈는 상태를 갖고있는(stateful) 스트림 처리가 가능한데 이를 위해 카프카 스트림즈는 rockDB와 카프카의 특정 토픽(changelog)를 사용한다. 그리고 이 카프카 스트림즈를 통해 처리된 데이터로 학습시스템에서 학습을 시키게 된다.
정리
IF 카카오에서 관심이 가던 세션 몇가지를 정리해보았다. 아직 내가 모르는 부분들이 많이 존재하다는 것과 어떤 키워드를 통해 공부를 해야하는지 조금이나마 방향을 잡은 것 같다. 차후에도 이런 세션을 보면서 알아야할 키워드를 계속 찾아봐야 겠다.
