Primary Key와 Unique Key
Primary Key와 Unique Key는 정확히 어떤 차이점을 갖고 있을까? 우선 눈으로 확인할 수 있는 차이점은 Unique Key는 Null을 허용 한다는 것일 것이다. 그렇다면 정말로 차이점은 그 뿐일까? 내부적으로는 어떠한 차이점을 갖고 있을까? 두 요소의 차이점을 Index를 통해 알아보도록 하자.
Clustered Index
우선 해당 내용은 MariaDB의 storage engine인 innoDB를 기준으로 정리를 하려고 한다.
사실 Primary Key와 Unique Key의 근본적인 차이점은 Index의 생성방식에 대해만 안다면 이해할 수 있게된다. 특별한 설정을 해주지 않는다면 모든 테이블은 하나의 Clustered Index를 갖게 된다. Clustered Index는 B-Tree의 일종으로 다음과 같은 구조를 갖고 있다.
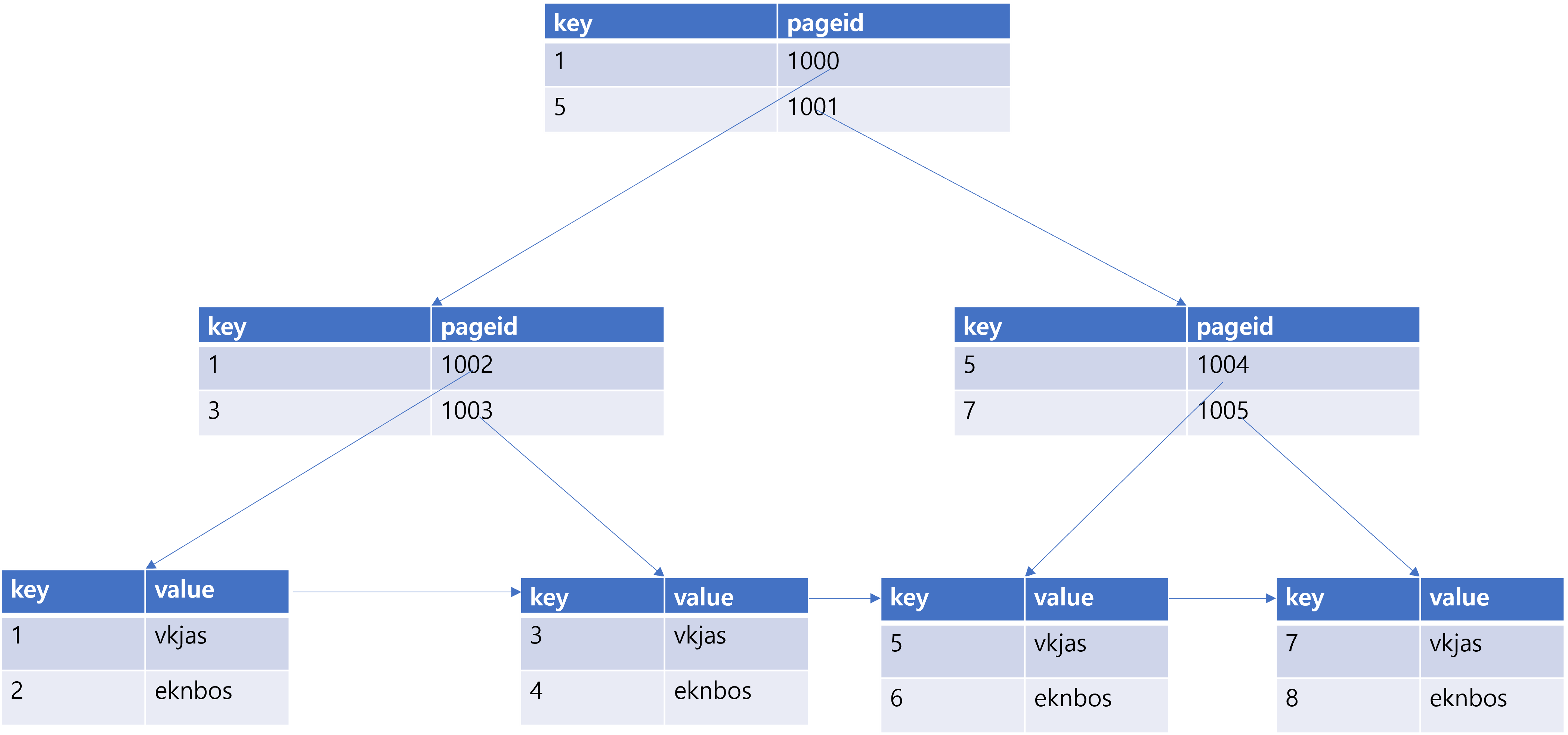
Key값을 기준으로 물리적으로 정렬이 되어있는 tree의 구조를 갖고있고 Binary Search Tree처럼 Clustered Index는 Key값으로 지정한 값을 기준으로 작은값이 왼쪽 노드, 큰 값이 오른쪽 노드에 붙게된다. 그리고 리프노드에는 양방향 Linked List의 형태로 서로 순회도 가능하도록 구성이 되어있다. 그렇다면 이 Key값을 선정하는 기준은 무엇일까?
링크에 따르면
- Primary Key
- NOT NULL인 Unique Key
- 자채 생성된 AUTO INCREMENT column
의 우선순위를 갖고 생성이 된다. Clustered Index는 리프노드에 실제 저장된 Table의 Data를 갖고있기 때문에 무조건 하나만 갖고 있을 수 있다. 만약 Clustered Index의 Key값을 명시적으로 변경하게 되면 DB는 현재 Table의 내용을 복사하고 새로 정렬을 하여 만들게 될 것이기 때문에 시간이 오래걸려 사용에 주의가 필요하다.
그렇다면 만약 Primary Key가 존재하는 상황에서 Unique Key값이 존재한다면 어떤 처리를 하게 될까? 이런 경우에는 Secondary Index가 생성이 되게 된다.
Secondary Index
Secondary Index(None Clustered Index)와 Clustered Index와의 차이점은 리프노드에 실제 Data대신 Clustered Index의 Key값이 되는 값을 갖고 있게 된다. 보통 Primary Key가 될 것이다. 그렇기 때문에 실제 Table의 데이터와 별개로 Secondary Index의 Key값이 되는 기준으로 정렬된 B-Tree가 필요해진다. 그러면 Secondary Index를 기준으로 Data를 찾는 경우 Secondary Index의 Node에서 PK를 확인하고 해당 PK를 기준으로 Clustered Index에서 Data를 찾게 된다.
만약 PK와 Secondary Index의 Key값만 찾는 경우에는 Covered Index라고 해서 어차피 Secondary Index PK를 갖고있기 때문에 굳이 Clustered Index를 탐색하지 않아 효율을 높일수가 있다. 그렇다면 복합키 같은 것으로 PK를 만들면 Secondary Index에서의 탐색만으로 원하는 Data의 대부분은 탐색이 가능하지 않을까? 이는 좀 생각이 필요한 부분이다. Secondary Index는 추가적인 공간을 사용하여 만들기 때문에 PK의 Size가 커질수록 차지하는 공간이 커진다. 이를 잘 고려하여 설계를 할 필요가 있을 것 이다.
