Query DSL은 복잡한 쿼리를 매우 편하고 빠르게 구현할 수 있게 해주는 매우 좋은 도구이다. 하지만 관계형 데이터베이스에서 객체로 매핑해주는 과정에서 발생하는 불균형 때문에 여러가지 직관적이지 않은 문제가 발생을 하는데 최근에 Query DSL을 사용하면서 흔히 마주치게 될수 있는 toMany관계를 사용하며 발생하는 문제를 내가 마주쳤던 상황을 통해 알아보려고 한다.
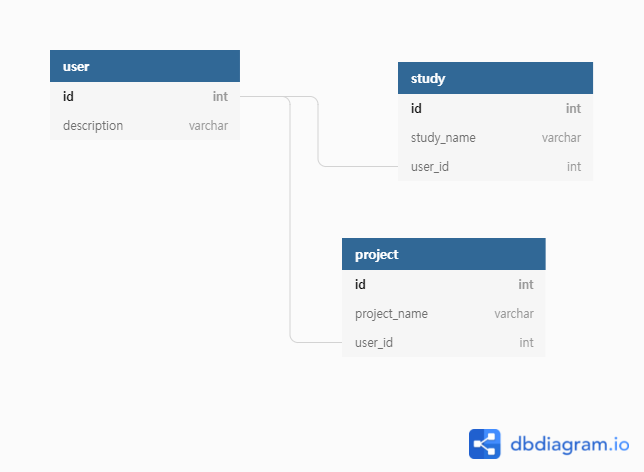
상황을 간략하게 재현하기 위해 위와 같이 User Table에 1:N관계를 갖는 2개의 Table study와 project가 있다고 가정해보자. Entity객체는 다음과 같이 정의하고 User에 포함된 모든 Study와 Project를 n+1문제에 빠지지 않고 한번에 조회하려고 한다.
//User.java
@Entity
@Getter
@Setter
@Table(name = "user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "id", nullable = false)
private Long id;
private String userName;
private String description;
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Study> studies = Lists.newArrayList();
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Project> projects = Lists.newArrayList();
public void addStudy(Study study) {
study.setUser(this);
studies.add(study);
}
public void addProject(Project project) {
project.setUser(this);
projects.add(project);
}
}//Study.java
@Entity
@Getter
@Setter
@Table(name = "study")
public class Study {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "id", nullable = false)
private Long id;
private String studyName;
@ManyToOne
@JoinColumn(name = "user_id")
private User user;
}//Project.java
@Entity
@Getter
@Setter
@Table(name = "project")
public class Project {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "id", nullable = false)
private Long id;
private String studyName;
@ManyToOne
@JoinColumn(name = "user_id")
private User user;
}study나 project는 하나도 존재하지 않을 수 있다. 그렇다면 inner join을 사용할 경우 user를 전부 조회하지 못할 수 있으니 outer join을 사용하면 아래와 같이 QDSL을 작성할 수 있을 것이다.
@Transactional(readOnly = true)
public List<User> findAllInnerFetchJoin() {
return jpaQueryFactory.selectFrom(user).leftJoin(user.studies).fetchJoin().leftJoin(user.projects).fetchJoin().fetch();
}자 그러면 아래의 코드로 테스트를 진행해 보자.
@ExtendWith(SpringExtension.class)
@SpringBootTest
class StudyApplicationTests {
@Autowired
UserRepository userRepository;
@Autowired
StudyRepository studyRepository;
@Autowired
ProjectRepository projectRepository;
@Test
void testToManyFetchJoinTest() {
for(int i = 0; i < 10; i++) {
User user = new User();
user.setUserName(String.format("user%d", i));
user.setDescription("this is for test");
userRepository.save(user);
for (int j = 0; j < 10; j++) {
Study study = new Study();
user.addStudy(study);
study.setStudyName(String.format("study%d", j));
studyRepository.save(study);
}
for (int j = 0; j < 10; j++) {
Project project = new Project();
user.addProject(project);
project.setProjectName(String.format("project%d", j));
projectRepository.save(project);
}
}
List<User> userList = userRepository.findAllInnerFetchJoin();
Assertions.assertEquals(10, userList.size());
Assertions.assertEquals(10, userList.get(0).getStudies().size());
Assertions.assertEquals(10, userList.get(0).getProjects().size());
}
}
MultipleBagFetchException이 발생한다! fetch join은 toMany관계가 여러개이면 실행할 수 없다고 한다. 그렇다면 아래와 같이 하나만 fetch join을 시도해 보자.
@Transactional(readOnly = true)
public List<User> findAllInnerFetchJoin() {
return jpaQueryFactory.selectFrom(user).leftJoin(user.studies).fetchJoin().fetch();
}
음.. userList가 100개가 조회 된다. 분명 10개를 넣었는데 말이다. Query DSL도 결국 SQL문을 사용할 것이고 outer join을 사용하는 이상 카테시안 곱 문제에서 자유로울 수 없고 이를 마법처럼 해결해 주진 않는 것 같다. 그러면 만약 여기서 한번더 outer join을 사용하게 되면 project의 개수만큼 곱셈되어 조회되는 칼럼의 수는 늘어날 것이다. 아마도 MultipleBagFetchException는 이를 사전에 방지하기 위한 예외가 아닐까 싶다.
찾아보던 중 Set을 사용하면 문제가 없다고 하여 한번 테스트를 해보려고한다. 아래와 같이 User Entity클래스를 변경해보자.
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Study> studies = Lists.newArrayList();
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private Set<Project> projects = Sets.newHashSet();쿼리는 처음과 동일하게 해보자.
@Transactional(readOnly = true)
public List<User> findAllInnerFetchJoin() {
return jpaQueryFactory.selectFrom(user).leftJoin(user.studies).fetchJoin().leftJoin(user.projects).fetchJoin().fetch();
}이번엔 MultipleBagFetchException이 발생하지 않지만 테스트에서 실패하고 말았다. 개수가 맞지 않는 것 같다. 한번 확인을 해보자.

오.. user가 100개가 되었다. 분명 10개일텐데.. 최종적인 입력부가 Set인 Project는 10개로 정상적으로 들어와도 카테시안 곱문제가 해결되는 것은 아니기에 동일한 user가 100개가 조회되었다. 그러면 중복을 제거하기 위해 distict를 사용하면 해결될까? 아래와 같이 변경해보자.
@Transactional(readOnly = true)
public List<User> findAllInnerFetchJoin() {
return jpaQueryFactory.selectFrom(user).leftJoin(user.studies).fetchJoin().leftJoin(user.projects).fetchJoin().distinct().fetch();
}user는 10개로 조회되지만 이번엔 List인 study가 100개로 조회된다.
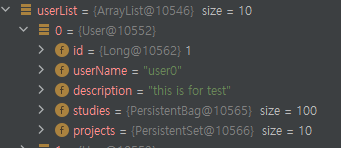
그러면 user까지 그냥 Set으로 변경해버리면 일단 개수는 10개로 정상적으로 조회된다 정확히는 study와 project가 set이고 distict인 경우에만 정상적으로 조회된다. 일단 원하는 결과는 얻기는 했지만 뭔가 찜찜하다. 여기엔 몇가지 문제점이 존재한다.
- Set의 사용이 강요되기 때문에 DB에 정렬된 상태로 조회되는 것을 보장하지 않음
- DISTINCT를 사용하기 때문에 성능적인 이슈가 있을 수 있고 CLOB이 있으면 동작이 불가능
사실 2번째 문제는 내가 실무에서 CLOB을 사용하다 마주친 문제다. CLOB은 제한없는 길이의 문자열을 저장할 수 있는 대신 이를 사용해 DBMS의 쿼리를 사용할 순 없다. 그렇기 때문에 CLOB인 ROW에 대하여 DISTINCT를 사용할 수 없다.(테스트 환경인 인메모리 h2DB에선 문제가 발생하지 않았음, 실무에서 사용한 DB는 오라클, DB에 따라 조금 다를수 있음)
그렇다면 2가지 정도의 해결책이 있을 것 같다.
- 쿼리를 2번(toMany관계의 수만큼) 날린다
링크에서 이상적이라고 제안된 방법인데 JPQL로 작성되어 있으니 이를 QDSL로 변경하면 대충 아래처럼 될 것 같다.
@Transactional(readOnly = true)
public List<User> findAllInnerFetchJoin() {
List<User> userList = jpaQueryFactory.selectFrom(user).leftJoin(user.projects).fetchJoin().distinct().fetch();
jpaQueryFactory.selectFrom(user).leftJoin(user.studies).fetchJoin().fetch();
return userList;
}정확한 동작방식은 더알아봐야 할듯 하지만 아마도 프록시객체가 PK를 식별자로 사용한다는 이야기가 있으니 아마 같은 트랜잭션내에서 조회만 해준다면 동일 PK의 프록시객체가 가리키는 실제 엔티티는 초기화가 되는 것이 아닌가 싶다. 위와 같이 해주면 실제 쿼리는 다음과 같이 2번만 수행된다.

물론 이 방법은 DISTICNT때문에 적용하지 못했다... JPQL의 DISTINCT는 SQL 쿼리에서 한번, 인메모리에서 또 한번 중복(카테시안곱)을 제거하는데 한번 사용함으로 SELECT에 CLOB인 Row가있는 경우 SQL 쿼리를 실행하는 부분에서 문제가 발생한다.
- Batchsize를 사용한다
향로님 블로그에서 제안한 방법이다. toMany관계에 있는 객체들을 fetch join으로 한번에 가져오지 않고 JPA에서 로딩할 때 한번에 가져올 개수를 지정하는 방법이다. 방법은 전역으로 설정하는 방법과 toMany객체에 @BatchSize 어노테이션을 붙여주는 2가지 방법이 있다.
#전역적 설정
spring.jpa.properties.hibernate.default_batch_fetch_size=10application.properties에 위 방법을 추가하거나
@BatchSize(size = 10)
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Study> studies = Lists.newArrayList();
@BatchSize(size = 10)
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Project> projects = Lists.newArrayList();위와 같이 @BatchSize 어노테이션을 추가하면 된다. size는 스키마에 따라 적절하게 설정을 해주어야 할 것이다. 그러면 다음과 같은 코드로 조회를 수행하면 된다.
@Transactional(readOnly = true)
public List<User> findAllInnerFetchJoin() {
List<User> userList = jpaQueryFactory.selectFrom(user).fetch();
userList.stream().map(User::getStudies).forEach(Hibernate::initialize);
userList.stream().map(User::getProjects).forEach(Hibernate::initialize);
return userList;
}그러면 다음과 같이 3번의 쿼리가 수행된다.

사진이 좀 잘렸는데 뒤의 쿼리를 살펴보면 where studies0_.user_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)로 출력된다. 한번에 10개의 study정보를 가져온 것이다.
두 방법 중에서 본인이 현재 수행하고 있는 작업에 맞는 방법을 선택하면 될 것 같다 그냥 BatchSize를 쓰는게 가장 문제가 적은 것 같다. 결국 쿼리를 toMany의 관계 수 만큼 날려준다는 의미에서 첫번째 방법과 BatchSize를 활용한(Size가 적절하다면) 방법은 결과적으로 컨셉의 차이가 없고 distinct를 쓰게되는 첫번째 방법의 특성상 성능적인 문제만 야기 시킬 것 으로 보인다.
결론적으로 toMany관계가 여러개면 fetchJoin을 사용하긴 어렵다라는 생각이 든다.
