
데이터 결측값(Missing Value)
결측 데이터
- 결측 데이터는 완전 무작위, 무작위 결측, 비 무작위 결측이 있다.
- 결측값이란 누락된 데이터 및 비어있는 데이터를 의미한다.
- 분석결과를 왜곡하거나 함수 적용이 불가능한다.
완전 무작위 결측(Missing Completely at Random, MCAR)
- 변수 상에 발생한 결측값이 다른 변수들과 전혀 관계가 없는 경우
- 결측값은 대부분 완전 무작위 결측으로 가정하고 결측값을 처리한다.
- 일반적인 경우 사람들의 실수에 의해서 발생하는 입력 누락이거나 프로그램 오류에 의해서 발생
무작위 결측(Missing at Random, MAR)
- 누락된 데이터가 특정 변수와 관련이 있지만 그 변수의 결과는 관계가 없을 경우
- 누락이 있는 변수로 설명이 가능
- 남성이 우울증 설문조사에 기입하지 않지만 우울증 정도와의 상관관계가 없다.
비 무작위 결측(Missing Not at Random, MNAR)
- 누락된 변수 결과가 다른 변수와 관련이 있는 경우
- 남성이 우울증 설문조사에 기입하면 우울증과 관련이 있다.
결측값 처리방법
명시형 모형에 의한 대체
- 각 변수들은 특정 확률분포에 따른다고 가정한 후에 분포의 모수들을 추정하여 대체
- 평균 대체, 중앙값 대체, 확률 대체, 비율 대체, 회귀 대체, 확률적회귀 대체, 분포를 가정한 대체 방법이 있다.
내재적 모형에 의한 대체
- 각 변수들은 특정 확률분포를 따른다고 가정하지 않고 가능한 정확한 값을 가지고 대체하는 방법
- 핫덱 대체, 콜드덱 대체, 대입 기법
핫덱과 콜드덱 대체
- 핫덱 대체
- 데이터 내의 응답값을 사용해서 결측값을 대체하는 방법
- 표본조사의 결측값을 대체하기 위해서 사용
- 콜드덱 대체
- 결측 값을 외부출처에서 가져온 값으로 대체
- 동일한 조사 자료가 아니라 다른 조사의 값으로 대체
혼합된 대체
- 명시적 모형 대체와 내재적 모형 대체를 혼합하여 사용
결측값 비율 내 용 10% 미만 어떤 방법으로든 결측값을 제거한다. 10% 이상 20% 미만 Hot-deck, Regression(회귀대체), Model based method 20% 이상 Regression, Model based method
R을 사용한 결측값 확인
- "data"라는 데이터 프레임을 만들고 임의로 두 개의 결측값을 넣었다.
data <- data.frame(sex=c("M","F", NA, "F","M"), score = c(4,5,3,4,NA))
data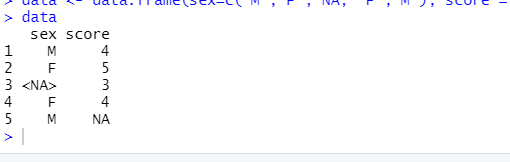
- 데이터 프레임에서 값이 없는 것을 확인하기 위해 is.na()함수를 사용한다.
빈도수를 확인하고 싶으면 table함수와 is.na함수를 같이 사용한다.
is.na(data)
table(is.na(data))
- 결측값 제거
① 단일변수 결측값 제거
- R에서 결측값 제거를 위해서 "dplyr"패키지를 설치하고 library()함수로 패키지를 로드한다.
install.packages("dplyr");
library(dplyr);
library(ggplot2)
search()
# data 변수에 포함되어 있는 값을 사용한다.
data %>% filter(is.na(score)) #스코어의 결측지를 찾는다.
data %>% filter(!is.na(score)) #스코어의 결측지를 제거한다.
data- 특히 data 변수의 원본데이터는 손상시키지 않았다.
#새로운 변수를 만들어 결측지를 제거하고 평균을 계산한다.
data_nomiss <- data %>% filter(!is.na(score))
# score의 평균을 계산한다.
mean(data_nomiss$score)② N개 변수 결측값 제거
- 결측값이 여러 개의 변수에 있는 경우 is.na()함수를 AND(&) 조합을 사용해서 결측값을 제거할 수 있다.
- na.omit()함수는 모든 결측값을 한번에 제거한다.
# AND연산자를 사용하여 2개의 변수의 결측값을 제거할 수 있다.
data_nomiss <- data%>%filter(!is.na(score) & !is.na(sex))
# 위와 동일하게 모든 결측값을 제거한다.
data_nomiss <- na.omit(data)③ 평균값으로 결측값을 대체
- 결측값을 평균값으로 대체 할 수 있다. mean()함수는 평균을 계산하는데
mean()함수를 사용할 때 "na.rm =T" 옵션을 주면 결측값을 제외하고 평균을 계산한다. - 평균을 계산하고 x변수에 평균을 저장한다.
ifelse문으로 score변수에 결측값이 나오면 평균값 x를 넣고 그렇지 않으면 score값을 넣는다.
#na.rm =T 옵션은 결측값을 제거하고 평균을 계산한다.
x = mean(data$score, na.rm=T)
#만약 data의 score가 결측값일 경우 평균값을 넣고 아닐 경우 그대로 둔다.
data$score <- ifelse(is.na(data$score), x, data$score)
data # 마지막 행의 값이 결측값에서 평균값으로 바뀌었다.데이터 이상값 처리
데이터 이상값
- 관측된 데이터의 범위에서 벗어나는 아주 큰 값 혹은 아주 작은 값을 의미
- 이상값은 데이터를 분석하는데 영향을 미치기 때문에 제거해야한다.
또한 평균값을 왜곡 시키기 때문에도 제거되어야 한다.
이상값 구현하고 삭제하기
#극단적인 값(이상값)을 가진 벡터데이터를 만들어보자
test = c(1,500,550,560,600)
boxplot(test)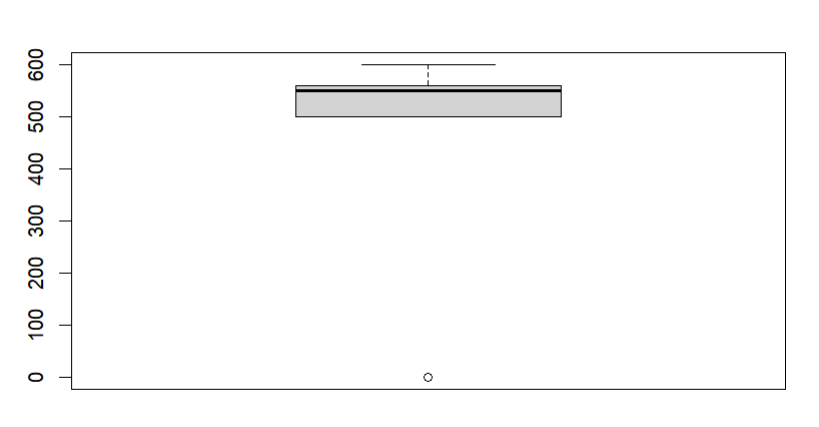
위 사진 자료의 값 1이 다른값에 비에 동떨어진 것을 볼 수 있다.
삭제하는 로직은 다음과 같다.
- ifelse문을 사용해서 1 값을 제외하고 특정범위의 값만으로 test 벡터에 저장한다. 1 값은 NA로 변경해서 저장한다.
- boxplot을 그릴 때 na.rm=T 옵션을 사용해서 결측값을 제외한다.
# 극단적인 값을 제외할 수 있도록 특정값의 범위를 만들어서 그 외의 수를 NA로 넣자
test <- ifelse(test>=500 & test<=600, test, NA)
# 이상 값은 이제 NA로 바뀌었다.이제 NA값을 na.rm=T 옵션을 두어 결측값을 제거하자
boxplot(test, na.rm=T)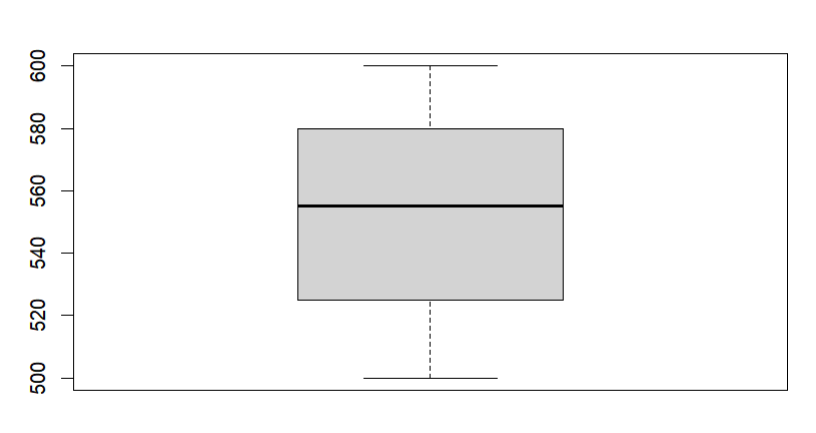
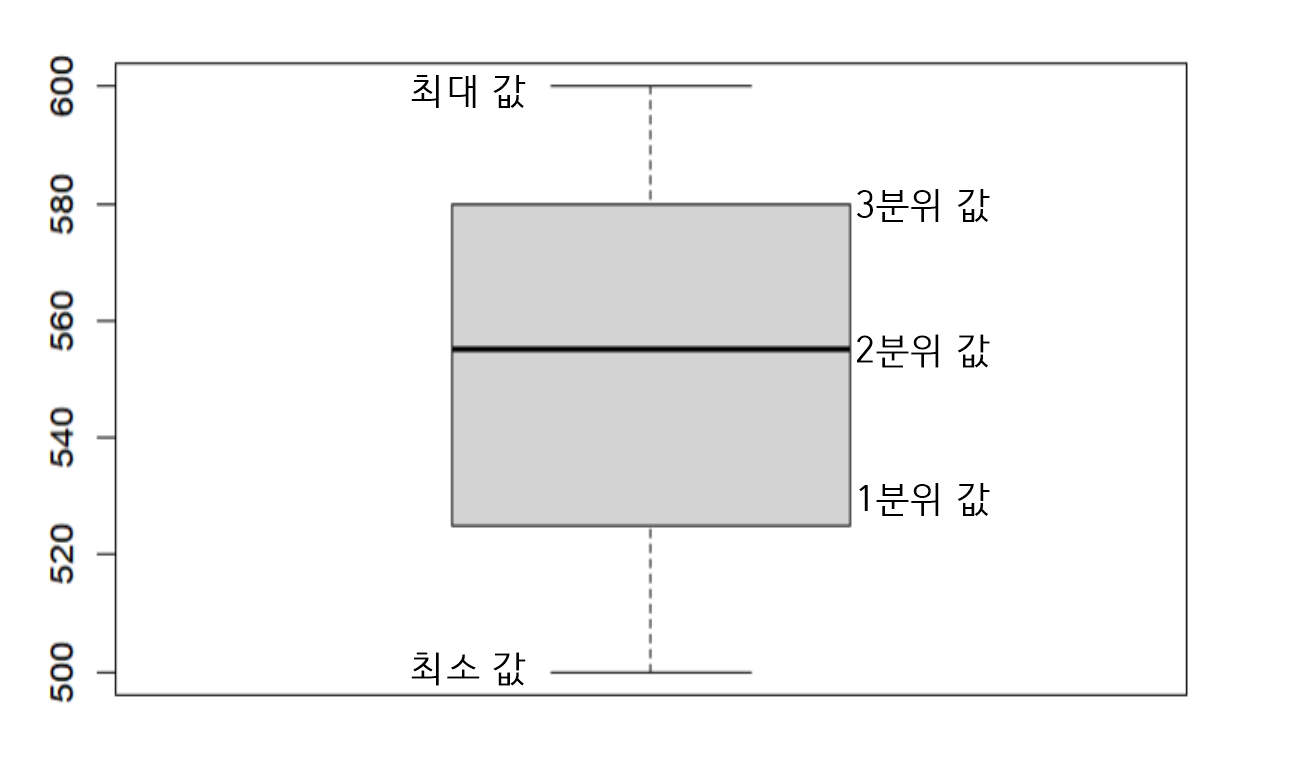
boxplot의 의미
사자그림은 사분위수 데이터를 나타낸다.
- 0사분위수 : 최소값
- 1사분위수 : 최소값 ~ 25%번째 값
- 2사분위수 : 중앙값
- 3사분위수 : 중앙값 ~ 75%번째 값
- 4사분위수 : 최대값

AllTimeDevelop