
R언어 개요
R 언어
- 95년에 S언어를 개선하여 개발
- 오픈소스 소프트웨어 다양한 통계분석을 할 수 있다.
- 시각화 도구를 제공, 빅데이터 분석 도구로 활용
- C++, JAVA, 파이썬과 같은 프로그래밍 언어와 연동 가능
R의 특징
- 다양한 통계분석을 지원, 데이터마이닝, 딥러닝 가능
- 2D, 3D 그래프 기능으로 가시화 가능
- 데이터베이스, 엑셀, CSV, SPSS, SAS 등 다양한 형태의 데이터와 연동
- 빠른 데이터 처리를 위해 RAM에 올려놓고 분석
- 웹 크롤링 및 텍스트마이닝 등 모두 지원
- GIS 정보 및 빅데이터 분석 가능
R환경
- R 스튜디오를 사용하면 R언어를 이용이 가능하며 데이터마이닝, 텍스트마이닝 등을 하려면 R 클라우드에서 패키지를 설치하면 된다.
- 데이터 마이닝
- cluster, tree, svm
- 텍스트 마이닝
- NLP, tm, worldcloud
- 그래픽 툴
- ggplot, lattice
- 최신 알고리즘
- 추가 분석 알고리즘
R 구성요소
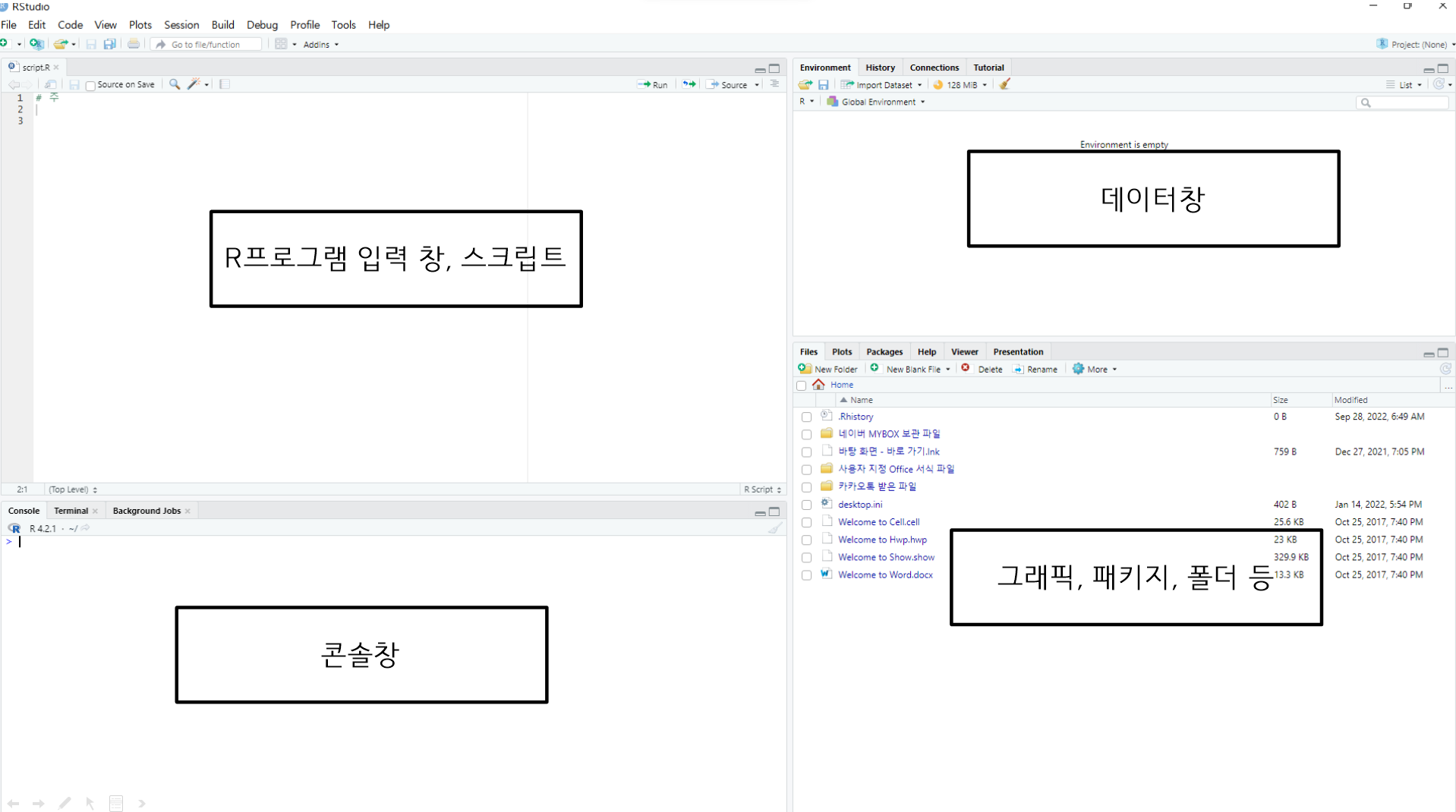
- R 프로그램 입력창
- 스크립트를 작성하고 실행 할 수 있는 창
- 콘솔창
- R 스크립트로 작성한 프로그램을 실행하면 결과를 확인 할 수 있다.
- 콘솔창은 ctrl + L 로 초기화 가능
- 데이터창
- 환경과 히스토리를 확인하고 환경 창에서는 데이터 셋을 확인 할 수 있다.
- 그래픽, 패키지, 도움말 창
- R스클립트에서 차트를 실행하면 확인할 수 있다.
- 패키지 정보를 확인 가능
R언어 기본
R 언어 기본기능
# 주석달기
# 세미클론은 하나의 명령어가 끝났다는 것을 알려주는 기능,
# 마지막 줄에는 세미클론을 사용할 수 없다.
number1 = 1;
number2 = "문자열"
# Ctrl + shift / 명령실행, 다중 명령일 경우 블록을 잡고 명령실행
# Shift + Enter / 동일한 위치에 다른 아규먼트가 올 수 있도록 함
# 대소문자를 구분함
number3 = 1;
Number3 = "다른 변수가 됨"산술연산
# 변수할당
num1 = 2;
num2 = 4;
num3 = num1 + num2;
num4 = num2 - num3;
num2 / num1;
# 거듭제곱
num1**2 == num1^2; # true
# 몫
num2 %/% num1;
# 나머지
num2 %% num1
할당 연산자
변수를 재할당해서 저장할 수 있다.
다른 프로그래밍 언어와 마찬가지로 변수의 재할당으로 인한 오류를 방지하기 위해서
변수네이밍과 변수의 관찰이 필요하겠다.
# 할당 연산자
# 오른쪽의 값을 왼쪽에 저장
num5 <- 30;
num6 = "문자열이 아니다";
# 왼쪽의 값을 오른쪽에 저장
20 -> num6비교 연산자
1 > 2 #false
30 >= 29 #True
20 < 30 #True
1 <= 2 #True
# == 같다
20 == 20 #True
# != 같지않다.
5 != 20 #True
# ! 부정연산자
!(1 > 2) #True논리 연산자
- &, && : AND 연산자
- (조건1) & (조건2)
- (조건1) && (조건2)
- |, || : OR 연산자
- (조건1) | (조건2)
- (조건1) || (조건2)
R데이터 타입
R 데이터 타입
기본 데이터 타입
- 정수, 문자열, 실수형, 논리형
특수 데이터 타입
- NULL : 존재하지 않는 객체로 지정
- NA : 결측값(Missing Value)를 의미
- NaN : 수학적으로 계산이 불가능한 수
- inf : 양의 무한대
- -inf : 음의 무한대
데이터 타입 확인 함수
mode() 함수
num = 1;
str = "하이";
float = 1.23;
boolean = FALSE
# mode() 함수, 데이터 타입을 문자열 형태로 반환한다.
mode(num)
mode(str)
mode(float)
mode(boolean)
is 함수
num = 1;
str = "하이";
float = 1.23;
boolean = FALSE
# is 함수 , TRUE 또는 FALSE로 반환
# 실수 여부 확인, 정수도 실수다.
is.double(float)
# 정수 여부 확인, 실수는 정수가 아니다.
is.integer(float)
# 수치형 확인
is.numeric(float)
# 문자형 확인
is.character(str)
# 논리형 확인
is.logical(boolean)
# 복소수형 여부 확인
is.complex(num)
# NULL여부 확인
is.null(str)
# NA 여부 확인
is.na(num)
# 유한수치 여부 확인
is.finite(num)
# 무한수치 여부 확인
is.infinite(num)
강제 형변환
- as함수를 이용하여 강제 형변환이 가능하다.
# 강제 형변환
char = "3";
float = 1.23;
char = as.numeric(char) # char = 3
float = as.integer(float) # float = 1
# 실수형으로 변확
as.double(데이터)
# 문자형으로 변환
as.character(데이터)
# 논리형으로 변환
as.logical(데이터)
# 복소수형으로 변환
as.complex(데이터)R데이터 구조
데이터 구조
-
벡터
- 하나 혹은 하나이상의 원소를 가질 수 있는 데이터 구조
- 원소는 문자, 숫자, 논리 연산자이지만 하나의 벡터는 동일한 자료타일을 가진다.
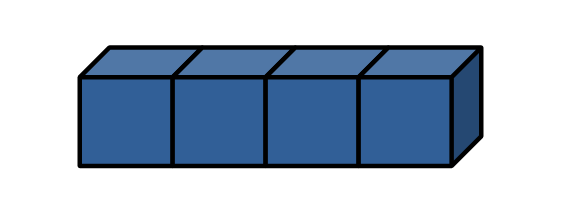
-
매트릭스
- 여러 개의 벡터로 구성된 것으로 2차원 형태
- 행과 열로 구성
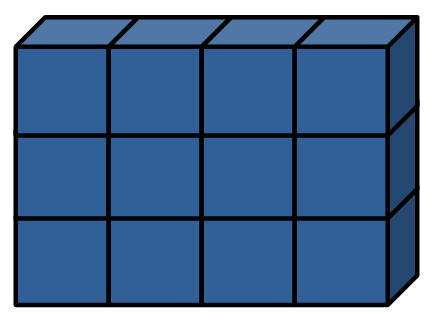
-
배열
- 다차원 형태의 데이터 구조를 가진다.
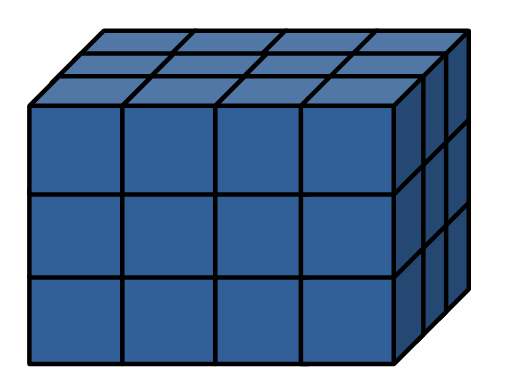
- 다차원 형태의 데이터 구조를 가진다.
-
데이터 프레임
- 여러 데이터 타입을 가질 수 있는 2차원 구조
- 매트릭스 형태로 행과 열로 이루어져 있지만, 여러 데이터 타입을 가진다.
- 저장된 원소의 데이터 타입도 저장
- 데이터 프레임에 삽입되는 벡터의 크기는 서로 동일
-
리스트
- 키와 값의 형태로 서로 다른 데이터 저장할 수 있는 연관 배열
벡터
- 벡터는 동일한 데이터 타입으로 이루어진 한개 이상의 값들로 구성된다.
- 데이터 분석 시에 가장 기본단위로 활용되고 하나의 열로 되어있다.
- 벡터는 숫자형, 문자형, 논리 연산자 벡터가 있다.
벡터 관련 함수
# 숫자형 벡터
x = c(1,2,3,4);
# 문자형 벡터
x2 = c("커피", "우유");
# 논리연산자형 벡터
x3 = c(TRUE, FALSE, TRUE)
#변수를 이용하여 벡터를 저장할 수 있으며
#하나의 타입으로 자동형변환되어 저장된다.
x4 = c(x, x2)
# a : b -> a ~ b까지 int형으로 벡터에 저장한다.
x4 = 1 : 4 # 1,2,3,4
#seq함수,조건을 부여하여 값을 생성한다.
x5 = seq(from=2, to=20, by = 3)
#2부터 20까지 3씩 증가하여 값을 담아라.
#sequency 함수 정수만 값을 포함하여 담는다.
x4 = sequence(4)
#함수에 들어가는 매개변수까지 1씩 증가여 담는다.
# rep()함수, 첫번째 매개변수의 값을 두번째 매개변수 만큼 반복한다.
x2 = rep("3번 반복", times=3)
x3 = rep(c(x,x4), times=2)벡터 결합함수
- cbind() : 열을 기준으로 벡터를 결합한다.
# 열을 기준으로 벡터를 결합한다.
# 각각의 매개변수를 열로 구성하여 하나의 데이터로 결합시킨다.
x3 = cbind(x1, x2)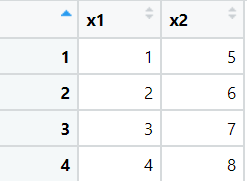
- rbind() : 행을 기준으로 벡터를 결합한다.
#행을 기준으로 벡터를 결합한다.
# 각각의 매개변수를 행으로 구성하여 하나의 데이터로 결합시킨다.
x4 = rbind(x1, x2)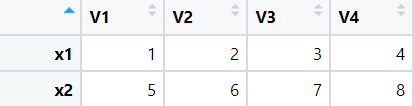
- factor() : 범주형 데이터로 집단별로 자료를 분석할 때 사용한다.
# 1차원 벡터 내부에 존재하는 값들이 어떤 값으로 이루어져 있는지 확인 가능
gender = c("m", "m", "f", "m", "f")
gender_f = factor(gender)
gender_f # Levels : f m
행렬
- 행과 열을 가지는 2차원으로 저장되고 matrix() 함수를 사용한다.
- 하나의 데이터 타입만을 가질 수 있다.
행렬 생성
# 행렬(Matrix) 생성
# 행렬을 2개열로 생성함, 값은 열방향으로 할당된다.
x1 <- matrix(c(1:6), ncol = 2)
x1
#행렬을 2개 행으로 생성함,값은 열방향으로 할당된다.
x2 <- matrix(c(1:20), nrow = 2)
x2행렬 곱셈
#생성은 위와 동일
x2 <- x2 * 3
#각각의 값마다 3을 곱한다.
x2
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
# [1,] 3 9 15 21 27 33 39 45 51 57
# [2,] 6 12 18 24 30 36 42 48 54 60배열
- 데이터를 3차원 형태로 저장할 수 있는 것으로 행렬을 확장한 것이다.
- 하나의 데이터 타입만 가질 수 있고 1차원 ~ 4차원 등으로 구성이 가능하다.
#1차원 배열, 2차원 배열 생성
x1 = array(1: 10, dim = 10);
#아래와 같이 작성해도 결과는 동일하다.
x1 = array(c(1:10))
x1[1]
#2차원 배열 구성
# dim의 값에 c(a,b) 값을 넣어 행렬의 수를 정할 수 있으며 부족한 수는 자동으로
# 1씩 증가하여 채우고 초과한 값은 생략한다.
x2 = array(1:10, dim = c(3,5))
x2
x2[2,3]리스트
- 리스트는 벡터, 요인, 행렬, 배열, 데이터 프레임 및 리스트 자신 자체까지 저장할 수 있는 데이터 구조이다.
- 데이터를 분석할 때 리스트 형태를 많이 사용한다.
#인수형 매트릭스 생성
x1 = matrix(1:6, nrow = 3, ncol = 2)
#인수형 배열 생성
x2 = array(1:100, dim = c(10,10))
#문자형 백터 생성
x4 = c("문자열", "벡터")
#생성된 변수 list에 저장
x3 = list(x1,x2,x4)
x3[1] #x1의 데이터- 다양한 타입으로 생성된 데이터를 한번에 저장할 수 있다.
데이터 프레임
- 데이터 프레임은 2차원 구조로 되어 있는 데이터 구조로 다양한 데이터 구조를 가지고 있다.
- 데이터 프레임은 하나의 열은 하나의 데이터 타입만 가질 수 있다.
- 데이터 프레임에는 데이터 타입 정보도 같이 저장되고 관리된다.
- 텍스트 파일, CSV 파일, 엑셀, 데이터베이스 파일 등의 외부 데이터는 데이터 프레임에 저장된다.
- str() 함수는 데이터 프레임의 구조를 확인할 수가 있다. 즉, 행 수, 열 수, 변수명, 데이터 타입을 확인 할 수 있다.
#데이터 프레임
x1 = 1:4
x2 = c(10,20,30,40)
x3 = c("m","f","m","f")
#생성된 데이터를 프레임에 저장하기
#열의 갯수가 맞아야하며 열마다 저장되는 타입이 동일해야 되기때문에
#데이터 타입을 준수하는 적절한 데이터 함수를 이용한다.
df = data.frame(x1, x2, x3)
df
#콘솔창에서 데이터 타입과 구조를 살펴봄
str(df)
#테이블 형태로 데이터구조를 살펴봄
View(df)조건문, 반복문, 함수
조건문
# 조건문
x = 50
# 다른 프로그래밍 언어와 동일하다
if(x > 100){
print("x는 100보다 큽니다다")
}else{
print("x는 100다 작습니다다")
}
#ifelse(조건문, 실행문1, 실행문2)
# ifelse는 True이면 실행문1, FALSE이면 실행문2를 실행한다
ifelse(x > 40, print("x는 40보다 큽니다."), print("x는 40보다 작습니다다"))
반복문
- 반복문은 동일한 문장을 반복적으로 실행 할 때 사용하는 문장
- for문과 while문은 "{실행문}"을 반복적으로 실행한다.
for문
# 반복문
x = matrix(c(1:100), nrow = 10, ncol = 10)
x
for (i in 1:10) {
for (j in 1:10) {
print(x[j,i])
}
};
while문
#while문
a = 0
while(a < 10){
#변화되는 값을 할당할때는 화살표를 사용한다.
print(a <- a + 1)
}함수
- 다른 프로그래밍 언어와 동일하게 매개변수를 만들고 매개변수를 사용하여 return을 하여 값을 출력 할 수 있다.
- 화살표 함수를 이용하여 익명함수를 생성하자.
#함수
username <- function(x) {
return (x + 1)
}
username(10)패키지 관리
패키지
- 패키지는 함수, 데이터, 코드, 문서 등을 묶어서 배포하는 것을 의미
- R을 설치할 때 기본적으로 제공하는 패키지가 있고 필요에 따라 추가적으로 설치해야 하는 패키지가 있다. ex)신경망 분석을 하기 위한 mxnet설치
- 패키지에 대한 도움말은 help()함수를 이용
패키지 설치
- "install.packages" 함수를 사용하여 패키지를 추가설치한다.
- 추가 패키지 설치방법(클라우드 설치, 다운로드 파일 설치)
- install.packages("패키지명")
- install.packages("c:/data/파일명")
#현재 설치되어 있는 패키지를 확인
search()
#패키지가 설치되는 경로 확인
.libPaths()
#패키지 설치 경로 변경
.libPaths("C:/Program Files/R/R-4.2.1/library")
#패키지 설치
install.packages("ggplot2")
#패키지와 R언어를 연결
library("ggplot2")
#패키지 업데이트
update.packages("ggplot2")
#패키지 삭제
remove.packages("ggplot2")
#패키지가 설치되어 있는 위치와 패키지 목록
searchpaths()외부파일
외부파일 읽기
- R에서 데이터를 분석하기 위해서는 외부파일을 읽어와야 한다
- R은 엑셀, CSV, 텍스트 파일, SPSS, SAS 등의 파일을 읽을 수 있다.
- 또한 데이터베이스와 연결해서 데이터베이스에서 데이터를 로딩 할 수 있다.
텍스트파일 읽기

#header 옵션은 첫줄을 header로 사용할 것인지 결정
sep 옵션은 데이터를 어떤 것을 기준으로 구분할 것인지 결정
table = read.table(file = "절대경로", header = TRUE, sep=" ")콤마로 구분된 파일 읽기
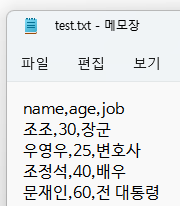
- sep 옵션을 콤마를 집어 넣으면 ,로 구분된 데이터를 읽을 수 있다.
table = read.table(file = "경로", header = TRUE, sep=",")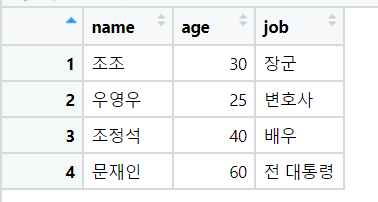
CSV파일 읽기
- CSV 파일은 콤마로 구분된 엑셀파일이다. 엑셀에서 자유롭게 읽을 수가 있기 때문에 많이 사용되는 파일구조이다.
setwd("파일 기초 경로 지정")
table2 <- read.csv("age2.csv")
table2
엑셀 파일 읽기
- 엑셀 파일을 읽기 위해서 readxl이라는 패키지를 추가 설치한다.
install.packages("readxl")
library(readxl)
# sheet가 여러개 일경우 sheet이름을 지정한다.
test = read_excel(path="C:/Users/km253/OneDrive/바탕 화면/Rlanguae/test.xls",
sheet = "test",
col_names = TRUE
)일변량 자료와 다변량 자료 탐색
일변량 자료
- 변수가 하나인 데이터를 의미하며 양적자료와 질적자료로 구분
- 예를 들어 학생들의 몸무게이다. 몸무게라는 변수가 하나인 데이터가 일변량 자료이다.
일변량 데이터 탐색
- 일변량 데이터의 변수형태는 연속형 데이터와 범주형 데이터로 나뉜다.
- 연속형 데이터
- 히스토그램
- 상자 그림
- 바이올린 그래프
- 커널밀도 곡선
- 범주형 데이터
- 막대 그래프
- 원 그래프
빈도 분석
- 질적자료를 개수를 세어서 분석하는 것이 일반적
- R에서 table() 함수를 사용해서 도수분포표를 만들 수 있고 전체 개수는 length()함수를 사용
평균과 분산, 표준편차
- 평균은 모집단의 대표값이고 분산은 데이터가 얼마나 뭉쳐있는지 확인한다.
- 양적자료를 분석할 때 평균, 사분위수, 표준편차, 상자 그림, 히스토그램 등을 사용할 수 있다.
- 그 중에서 평균은 크기가 주어진 자료를 분석할 때 먼저 사용
- 절사평균
- 표본중에서 작은값 n%와 큰 값 n%를 제외하고 나머지 (100-2n)%의 자료만 사용해서 구하는 평균
- 극단적인 값에 의해서 발생되는 오차를 줄임
평균, 표준편차, 분산 관련 R함수
- mean() : 평균
- var() : 분산
- sd() : 표준편차
- summary() : 최소값, 최대값, 중앙값, 평균
다변량 자료
- 변수가 두 개인 데이터를 의미하며 양적자료와 직적자료로 구분
- 예를 들어 출생지역과 몸무게의 상관관계, 즉 변수가 출생지역과 몸무게가 된다.
- 다변량 자료는 2차원 배열에 넣어서 분석하는 주제가 되는 변수
다변량 데이터 탐색
- 연속형 데이터
- 산점도
- 선 그래프
- 시계열 그래프
- 범주형 데이터
- 모자이크 그래프
다변량 자료 관련 R함수
- plot()
- 두 개의 변수의 관계만을 나타내는 2차원 그래프
- 점 그래프, 선 그래프, 계단형 그래프 등을 표현
- pairs()
- 여러 변수들의 상관관계를 한번에 보여줌
- cor()
- 변수들의 상관관계를 구함
일변량 질적자료
일변량 질적자료
- 일변량 질적자료 분석은 빈도와 백분율을 사용해서 할 수 있다.
- 빈도는 자료가 가지는 값이 몇 개인지를 계산하고 백분율은 전체를 100으로 해서 얼마나 차지하는 비율을 구한다.
일변량 질적자료 분석 시
- 표
- 빈도
- 백분률
- 그래프
- 막대 그래프
- 원 그래프
빈도
library(ggplot2)
# 패키지에 저장되어있는 데이터
diamonds
# 각 변수의 빈도를 확인 할 수 있다.
table(diamonds$cut)
# 가시성을 좋기 하기 위해 sort를 이용하여 정렬한다.
# sort 함수의 decreasing 옵션은 내림차순 여부를 결정할 수 있다.
sort(table(diamonds$cut), decreasing = TRUE)
백분률
- prop.table()함수는 0과 1사이의 값을 반환하여 백분률을 알 수 있다.
즉, 반환값에 100을 곱하면 된다.
# 0과 1사이의 값으로 반환
prop.table(table(diamonds$cut))
#100을 곱하여 백분률로 표현
prop.table(table(diamonds$cut)) * 100
#round함수를 이용하여 반올림, digits 옵션은 몇 째자리에서 반올림 할 것인지 결정
round(prop.table(table(diamonds$cut))*100, digits = 2)

빈도와 백분률을 한번에 계산
- 만약 빈도와 백분율을 한꺼번에 계산하려면 prettyR 패키지에 있는 freq()함수를 사용
- freq() 함수는 결측값이 있는 경우 결측값을 제거하고 계산
install.packages("prettyR")
library(prettyR)
# 패키지 내부의 freq 함수를 사용
# display.na = FALSE옵션은 결측값을 제외한다.
table = freq(diamonds$cut, display.na = FALSE)
table
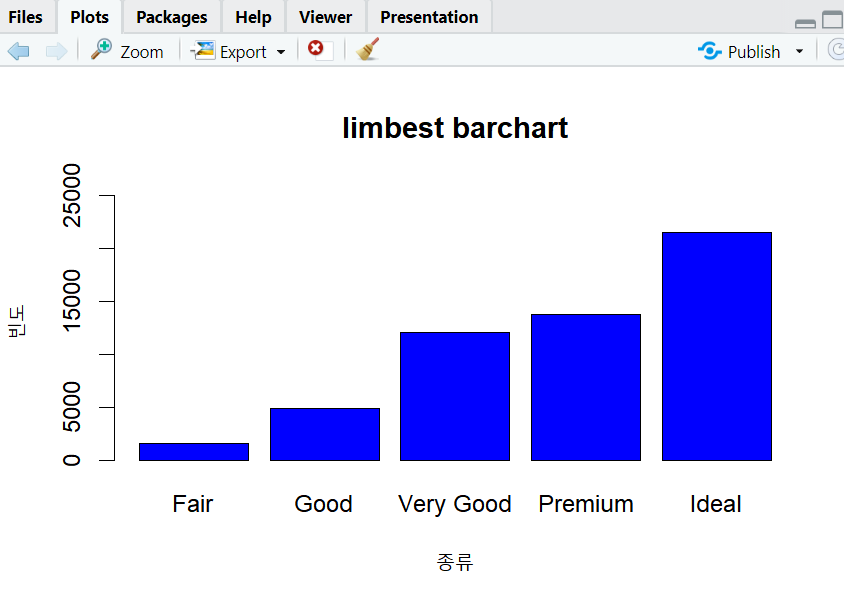
막대 그래프
- 막대 그래프는 빈도 혹은 백분율을 가시화하기 위해서 많이 사용하는 그래프
- x축과 y축에 값을 입력하고 최소값을 0부터 시작해 최대값이 포함되도록 한다.
- 질적 자료의 특성을 분석하기 위해 많이 사용
- barplot()이라는 함수를 사용해서 가시화 가능
# ylab : y축 제목, ylim : 눈금 범위 지정, main : 제목
barplot(table(diamonds$cut), col="blue",
ylab = "빈도",
xlab = "종류",
ylim = c(0,26000),
main = "limbest barchart"
)
- ggplot2 패키지를 이용해서 막대그래프를 만들 수 있음
#aes 함수는 x축 혹은 y축에 입력된 데이터이다.
ggplot(data = diamonds, mapping = aes(x = cut))+geom_bar()원 그래프
- 원 그래프는 전체에서 각 항목이 얼마만큼의 비중을 차지하는지 한 눈에 알 수 있다.
- 강조하고 싶은 부분을 분리해서 가시화 가능, 일반적으로 5개 이하가 적당함
- 원 그래프는 pie()함수를 이용
# 원 그래프 표시
pie(table(diamonds$cut))
# 반지름을 최대로
pie(table(diamonds$cut), radius = 1)
# 시작하는 각도를 -30도로 지정
pie(table(diamonds$cut), radius = 1, init.angle = -30)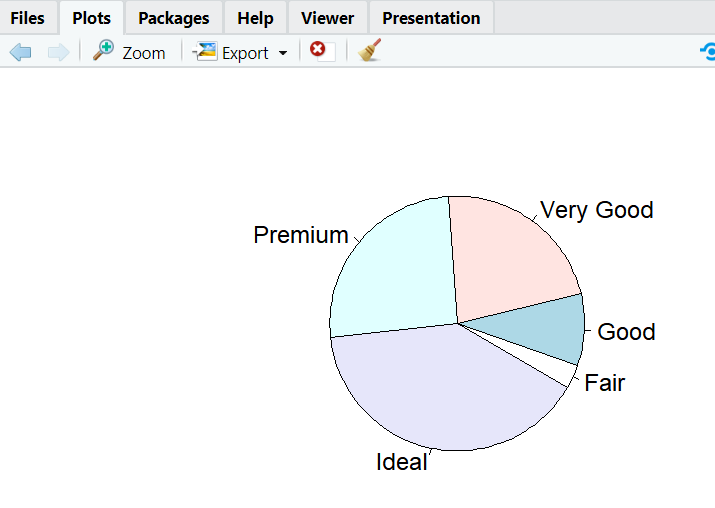
일변량 양적자료
일변량 양적자료
- 일변량 양적자료 분석은 표, 그래프, 기술 통계량 등을 통해 분석할 수 있다.
히스토그램
- 각 구간별 현황 및 대칭 여부를 확인하기 위해서 히스토그램을 사용할 수 있다.
- 데이터에 이상 값 유무를 확인 할 수 있다.
- hist() 함수를 사용해서 히스토그램을 표현할 수 있다.
- 히스토그램의 x는 반드시 숫자여야한다.
#히스토그램 작성
hist(diamonds$price)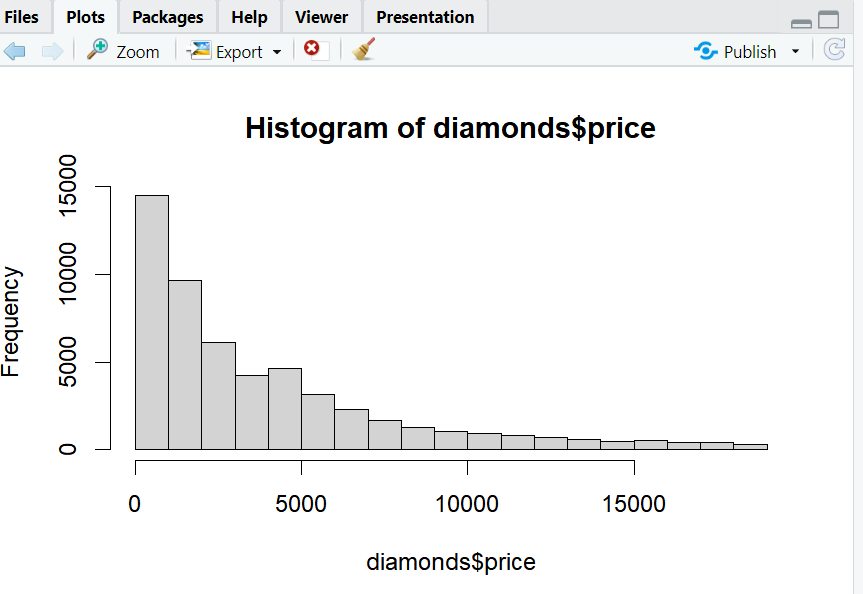
# 지정한 구간 데이터로 히스토그램 작성
hist(diamonds$price, breaks = c(0,5000,10000,15000,20000))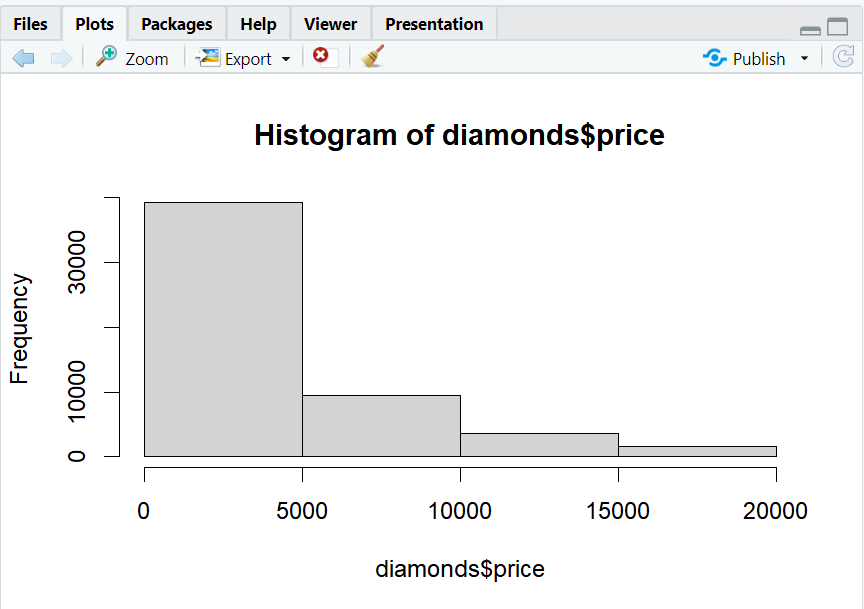
# 아래와 같이 단위를 작성해도 됨
hist(diamonds$price, breaks = 10)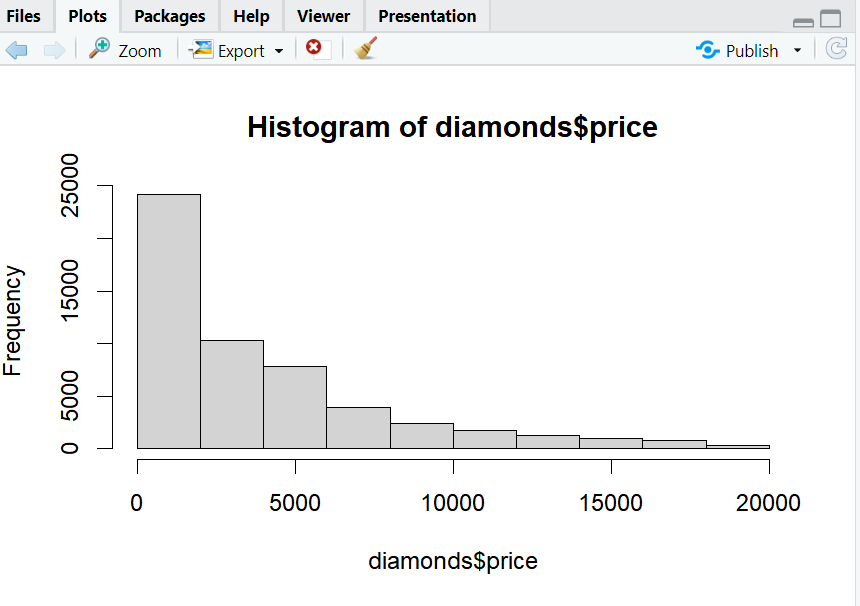
상자그림
- 상자 그림은 대칭여부 확인, 이상값 확인, 자료의 분포를 확인 가능
- boxplot()함수를 사용해서 가시화 할 수 있다.
# boxplot
boxplot(diamonds$price)
# range 이상 값을 분석하기 위해서 사용
boxplot(diamonds$price, range = 3)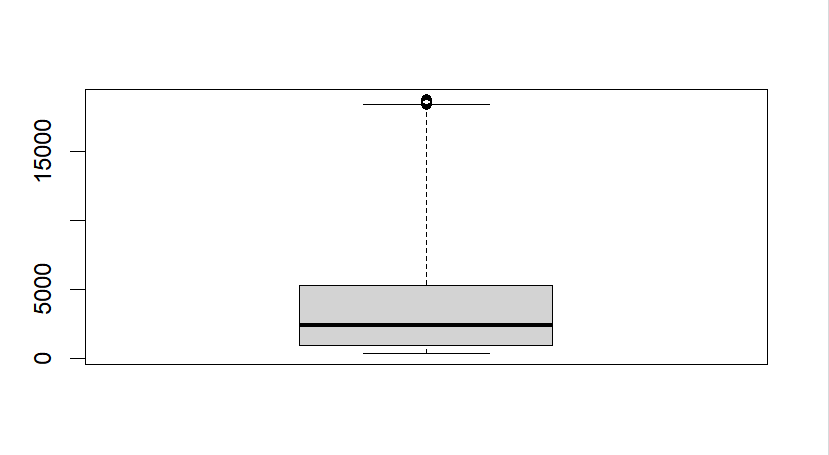
# 양적자료 + 질적자료
boxplot(diamonds$price ~ diamonds$cut)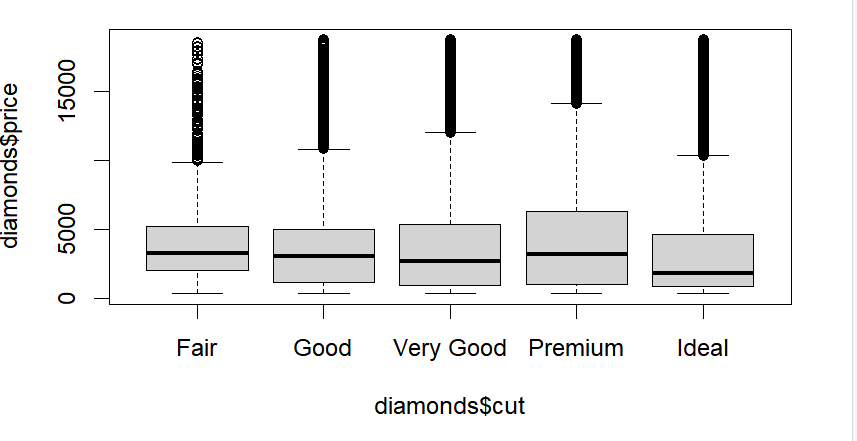
기술 통계량
- 데이터의 범위, 사분위 범위, 분산, 표준편차, 중위수 절대편차를 확인한다.
- 최소값, 최대값을 확인 할 수 있고 데이터가 퍼져있는 정도를 확인한다.
- 기술통계량은 summary() 함수와 psych패키지에 있는 describe()함수, describeBy()함수를 사용해서 한번에 여러 개의 기술 통계량을 확인할 수가 있다.
다변량 자료
다변량 자료 탐색절차
일반정보 확인
- 데이터의 크기, 변수의 수, 변수 타입 등을 확인
- str()함수를 사용하면 변수의 수, 변수 타입 등이 확인 가능
x1 = 1:4
x2 = c(10,20,30,40)
x3 = c("m","f","m","f")
df = data.frame(x1, x2, x3)
str(df)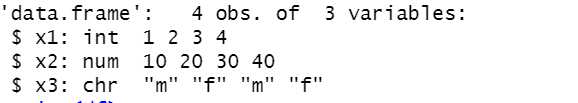
'data.frame' 은 데이터가 저장된 타입을 말하며, 4 obs는 행수를 의미한다.
또한 3 variables는 3개의 변수가 있다는 것을 말한다.
데이터 분포 확인
- 열 데이터 분포를 확인한다. summary()함수를 사용해 평균과 중심값을 확인해서 데이터의 정규분포 정도를 확인한다.
- sd()함수로 표준편차를 확인하고 평균으로부터 데이터가 얼마나 떨어져 있는지 확인한다.
그룹별 분포 확인
- 열에 대해서 그룹별 분포를 확인한다.
- boxplot() 함수로 그룹별 분포를 확인할 수 가 있다.
# 4개의 값을 한번에 봄
par(mfrow = c(2,2))
boxplot(Sepal.Length~Species, data = iris, main = "Sepal.Length")
boxplot(Sepal.Width~Species, data = iris, main = "Sepal.Width")
boxplot(Petal.Length~Species, data = iris, main = "Petal.Length")
boxplot(Petal.Width~Species, data = iris, main = "Petal.Width")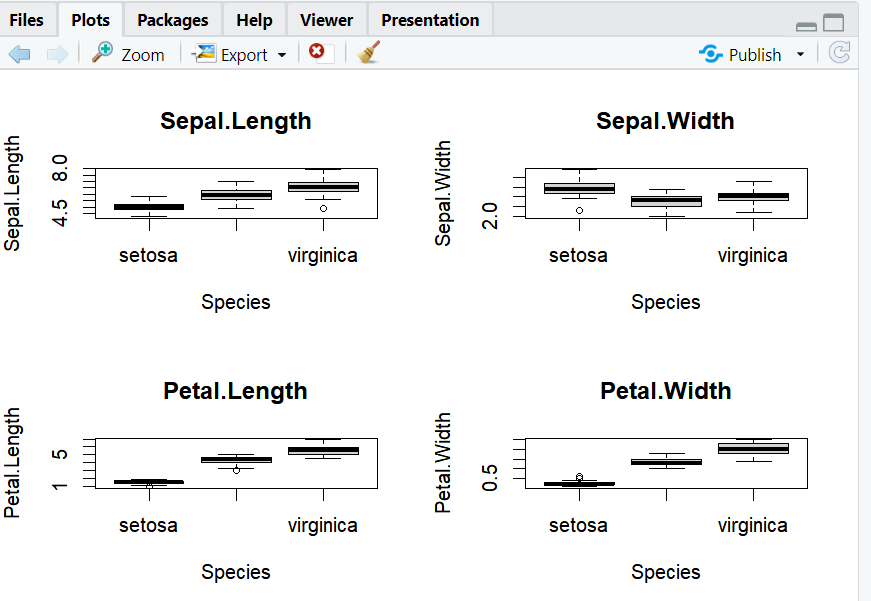
선 그래프와 산점도 확인
산점도
- 두 개의 변수 혹은 여러 개의 변수 간에 대해서 상관관계를 확인
- 수치로 된 자료에 대해서 두 변수 간의 관계를 산점도를 표현
- 다변량 자료는 pairs()함수를 사용, pairs() 함수를 사용하면 여러 변수들 간의 관계를 한눈에 파악 가능
x1 = c(10,1,5,2,4,6,1,3,8)
x2 = c(82,94,88,90,87,84,91,87,93)
cor(x1, x2)
#상관관계 표를 만듦
plot(x1, x2, main = "상관관계 테스트")
# 붉은 선을 정의
abline(lm(x2~x1), col="red", lwd=2, lty=1)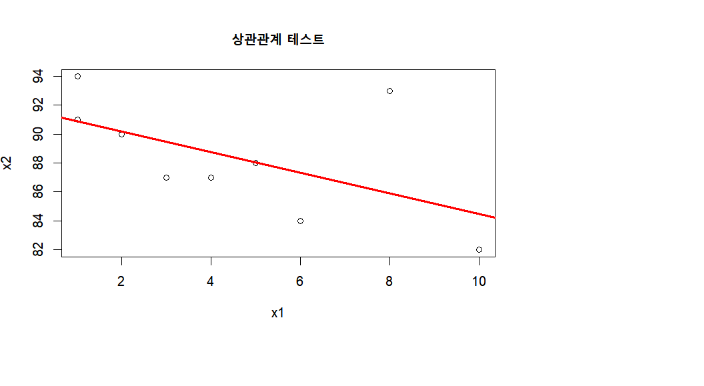
선 그래프
- 선 그래프는 두 개의 변수에서 하나의 변수가 시간변수 일 때 많이 사용
- 시계열 분석을 우해 자주 사용되는 그래프
par(mfrow=c(1,1))
month = 1:12
late = c(4,5,7,10,12,13,6,5,4,2,8,9)
#type 은 선 그래프의 종류를 의미
plot(month, late, main ="선그래프", type="l", lwd=2, xlab="월", ylab="횟수")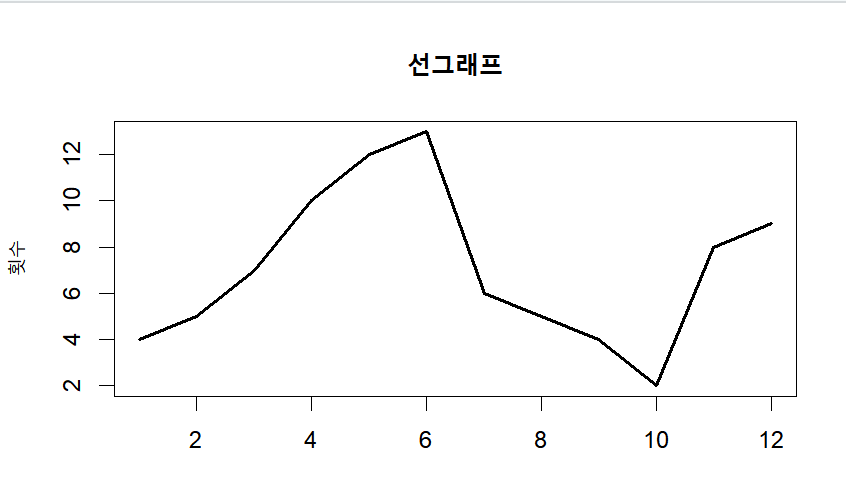
plot(month, late, main ="선그래프", type="b", lwd=2, xlab="월", ylab="횟수")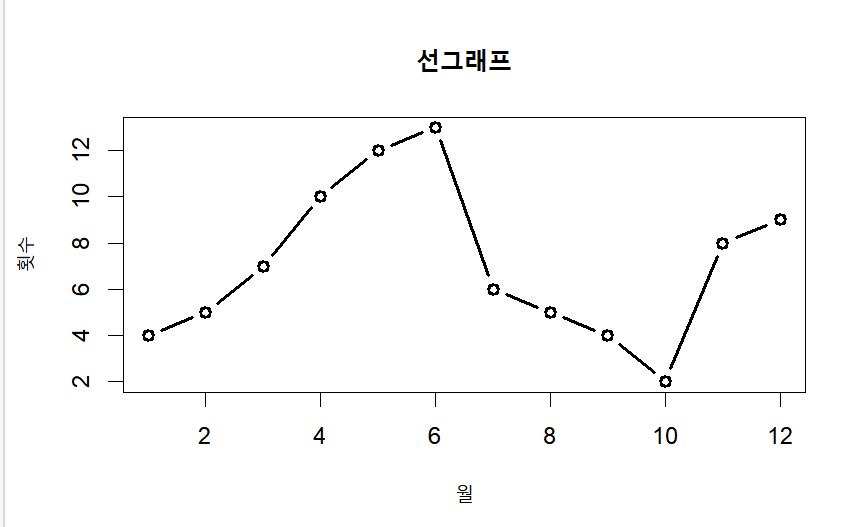
plot(month, late, main ="선그래프", type="s", lwd=2, xlab="월", ylab="횟수")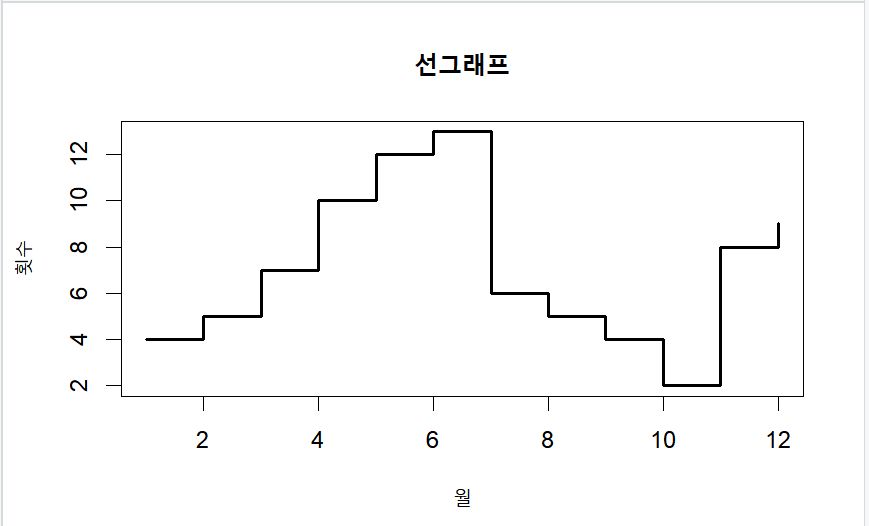
late2 = c(8,7,5,4,11,12,6,2,7,1,10,12)
plot(month, late, main ="선그래프", type="l", lwd=2, xlab="월", ylab="횟수")
# 선 추가하기
lines(month, late2, type="l", col="red")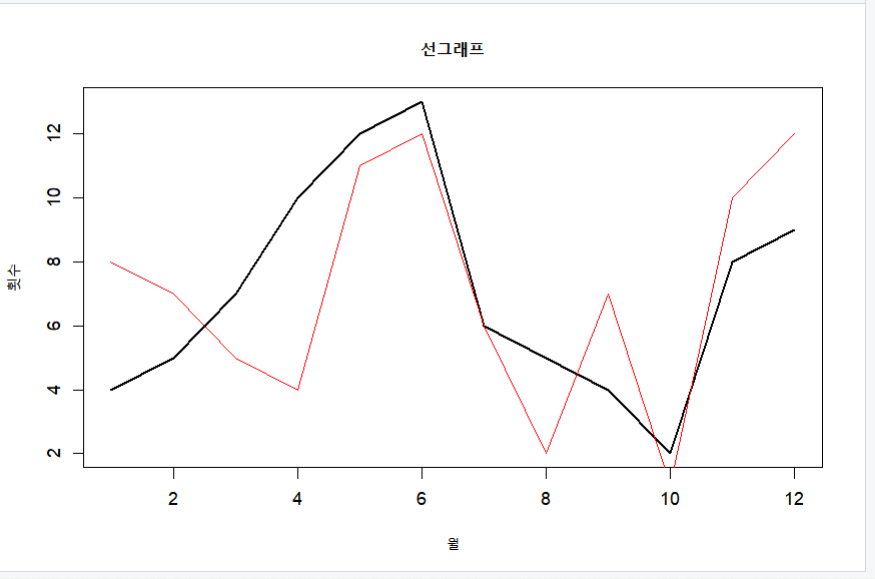

AllTimeDevelop