
기술통계 분석
기술통계
- 통계는 자료수집, 표본추출, 요약정리를 하는 "기술통계"와 확률을 사용하여 추리, 추론을 하는 "추리통계"가 있다.
- 추리통계는 확률을 사용하여 모수와 표본 간의 오차 범위를 예측하는 것
- 기술통계는 모집단으로부터 수집도니 자료를 정리, 요약하여 자료의 특징을 분석하는 것
- 표 및 그래프, 객관적인 수치를 사용한다.
표본과 모수
- 표본
- 조사하기 위해 추출한 모집단의 일부 원소들
- 모수
- 표본 관측으로 구하고자 하는 모집단에 대한 정보
질적자료와 연속자료
- 질적자료
- 요약방법
- 도표, 그래프
- 자료정리
- 도수분포표, 분할표
- 그래프 종류
- 막대 그래프(빈도, 퍼센트)
- 원 그래프
- 요약방법
- 연속자료
- 요약방법
- 수치, 그래프
- 자료정리
- 산술평균, 중앙값, 조화평균
- 그래프 종류
- 히스토그램
- 상자그래프
- 시계열
- 산점도
- 요약방법
질적자료 기술통계 요약
도수분포표
- 수집된 자료에 대해서 적절한 등급으로 분류해서 정리한 표
- 각 자료에 대해서 출현 빈도를 계산하고 여러 구간으로 분류한 표
- 관측값을 여러 개의 그룹으로 나누고 관측값의 수를 요약 정리한 표
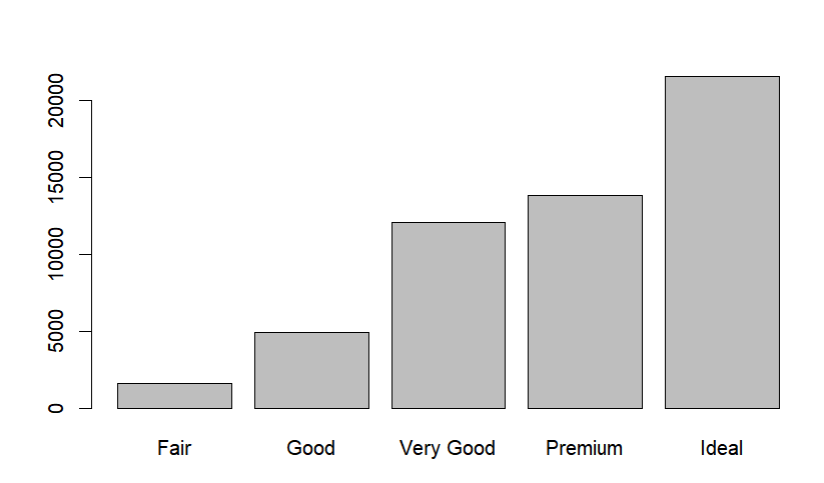
- 도수분포표는 테이블 형태로 빈도 수를 정리한 것
- 위 도수분포표를 사용해서 그래프를 그리는 것이 막대그래프다.
분할표
- 질적변수가 2개일 때 관측지를 몇 개의 그룹으로 분할해서 빈도수를 정리한 것
연속자료 기술통계 요약
연속자료 기술통계
- 자료의 분포 특성을 파악하기 위해서 숫자로 표현
- 중심위치와 산포경향을 파악하여 요약
- 중심위치
- 관측 자료가 어디에 집중되어 있는지를 분석
- 산술평균, 중앙값, 최빈값, 기하평균, 조화평균, 가중평균
- 산포경향
- 자료가 중심위치를 기준으로 어느 정도 흩어져 있는지를 분석
- 범위, 편차, 표준편차
중심위치
- 평균은 자료 분포상의 무게중심 역할을 한다.
- 평균은 데이터의 분포에 따라서 역할을 못할 때도 있다.
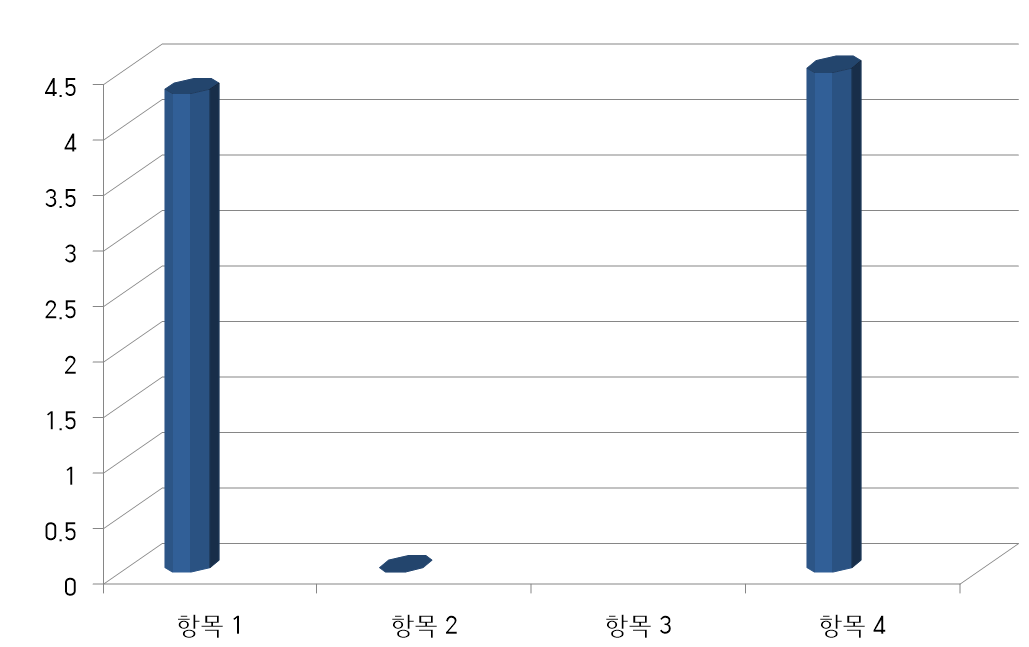
- 위 예는 처음과 끝에만 자료가 있다. 위와 같은 분포에서 평균을 계산하면 평균 값은 전체 데이터의 특성을 표현할 수가 없다.
- 이러한 데이터 특성을 파악하기 위해서 그래프를 사용할 수는 있지만 데이터 특성을 파악하기 위해서 매번 그래프를 사용할 수가 없다. 그래서 표준편차 값으로 위와 같은 특성을 분석한다.
- 즉, 표준편차느 평균을 기준으로 데이터가 떨어져 있는 거리 값이므로 표준편차가 크게 나타나면 평균을 기준으로 데이터가 멀리 흩어져 있다는 것을 알 수 있다.
- 책 p156 참고
① 산술평균
AM = =
② 중앙값(Median)
- 자료를 크기 순서로 나열하면 가장 가운데 오는 값
- 중앙값은 이상값에 영향을 받지 않고 좌우의 분포 면적이 같다.
③ 최빈값(Mode)
- 빈도를 분석하여 발생빈도가 가장높은 값
- 빈도수가 동일한 자료가 있을 수가 있으므로 유일하지 않다.
④ 가중평균
- 가중평균은 평균을 계산할 때 자료의 중요도 및 영향 등에 따라서 가중치를 반영한 평균값
- 중요도가 다른 점수를 산수령균으로 계산하면 값에 왜곡이 발생한다.
| 영어 | 수학 | 체육 | 미술 | 음악 |
|---|---|---|---|---|
| 80 | 100 | 90 | 70 | 100 |
| 10 | 35 | 10 | 10 | 35 |
⑤ 기하평균
- 기하평균은 연간 경제성장률, 물가 인상율, 연간 이자율 등과 같은 곳에 사용
- 변화량을 계산할때 사용
- 예를 들어 2010년부터 2020년까지 경제성장률에 대한 평균이다. 즉 2010년의 경제성장률이 2020년의 경제 성장률이 되려면 매년 평균 몇 퍼센트가 증가해야 하는가?
연도 수익금액 증가율 2014 635 - 2015 998 57.17% 2016 1,265 26.75% 2017 1,701 34.47% 2018 2,363 38.92%
기하평균 계산
-
기하평균은 위의 예에서 2014년부터 2018년 매년 몇 퍼센트씩 증가하면 되는지에 대한 평균이다.
-
즉, 매년 38.9%씩 증가하면 2018년 수익율이 된다.
-
모 회사에 투자하여 첫해에 10%, 둘째 해에 50%, 셋째 해에는 30%의 수익을 올렸다면, 3년간 평균 수익률은 얼마인가?
⑥ 조화평균
- 여러 단위가 결합될 때 평균적인 변화를 계산한다.
- 상대적인 비를 계산한다.
- 경기도에서 서울까지 자동차로 다녀왔는 데, 갈 때에는 고속도로를 이용하여 100km/h로 갔고, 올때는 국도를 이용해서 70km/h로 돌아 왔다면, 왕복 평균 속도는 얼마인가?
2/(1/100+1/70) = 82.35km/h
⑦ 절단 평균
- 너무 큰 값과 작은 값이 존재하면 평균값은 부정확해질 수 있다.
- 절단평균은 가장 큰 값과 작은 값을 잘라내고 산술평균을 구하는 것이다.
산포경향
① 범위
- 자료의 최대 값에서 최소 값을 뺀 것이다.
- 이상 값에 민감하게 영향을 받는다.
- 범위는 최대 값에서 최소 값을 빼기 때문에 자료의 변동을 확인 할 수 없다.
- 따라서 범위는 실제로 사용되지 않는다.
② 분산 - 자료가 평균을 중심으로 얼마나 분포하고 있는지를 나타낸다.
- 확률변수가 기대 값으로부터 얼마나 떨어진 곳에 분포하는지를 나타내는 숫자이다.
- 분산은 평균 이하의 값과 평균 이상의 값들을 모두 더하면 0이되어야 한다.
- 분산의 공식
- 위의 분산공식을 보면 N은 모집단의 크기, X는 데이터, 는 평균이다.
- 모든 데이터 평균과 빼면 0이 되기 때문에 자승을 하는 것이다.
- 분산은 데이터 값에 자승을 하기 때문에 숫자가 너무 커지는 문제가 있다.
- 분산이 숫자를 크게 만드는 문제를 해결하기 위해서 분산 값에 루트를 사용하는 것이 표준편차이다.
x1 <- c(10,15,17,20)
min(x1) #최소값을 구한다.
max(x1) #최대값을 계산한다.
mean(x1) #평균을 계산한다.
var(x1) #분산을 계산한다.
③ 표준편차
- 평균을 중심으로 자료가 흩어진 정도
- 자료의 분포와 변동에 대한 정보를 제공한다.
- 표준편차는 분산 값을 루트를 사용해서 값을 작게 만든다.
- 해석
- 표준편차 값이 크다 : 평균으로부터 멀리 떨어져 있다.
- 표준편차 값이 작다 : 평균 값에 값들이 몰려 있다.
- 용도
- 자료에 분포와 변동에 대한 정보를 제공
- 자료에 있는 이상치를 점검
- 가설검정을 한다.
④ 평균, 분산, 표준편차의 차이
A와 B회사의 연봉에 대해서 평균, 분산, 표준편차를 구해 그 차이를 비교해보자
- 먼저 A회사의 평균연봉은 다음과 같다.
1200 + 1600 + 5600 + 6000 + 7000 = 21,400 / 5 = 4,280만원- B회사의 평균연봉은 다음과 같다.
4000 + 4500 + 4250 + 5000 + 3650 = 21,400 / 5 = 4,280만원A와 B회사의 평균연봉은 동일하지만 A와 B회사의 연봉을 평균으로는 해석하기 어렵다.
A회사는 평균으로부터 넓게 분포되어 있고 B회사는 평균으로부터 밀집되어 있다.
- 평균으로부터 얼마나 떨어져 있는지 알기위해서 표준편차를 구해야 하고 표준편차를 구하기 위해서는 먼저 편차를 구한다.
| 1200 | 1600 | 5600 | 6000 | 7000 |
|---|---|---|---|---|
| -3080 | -2680 | +1320 | +1720 | +2720 |
| 4000 | 4500 | 4250 | 5000 | 3650 |
|---|---|---|---|---|
| -280 | +220 | -30 | +720 | -630 |
즉, 편차는 평균과의 차이이고 편차의 합은 0이 된다.
분산은 평균으로부터 값이 얼마나 멀리 떨어져 있는지 알기 위해서 사용되는 것으로 분산에서 양수와 음수는 의미가 없다. 그래서 분산은 평균제곱을 구한다.
- A회사의 연봉 1200의 편차를 제곱하면 (-3080) * (-3080) = 9486400이 되고 음수가 없어진다. A회사의 평균 제곱을 구하면 다음과 같다.
- A회사의 분산
(9486400 + 7182400 +1742400 +2958400 +7398400) / 5 = 5753600 - B회사의 분산
(78400 + 48400 +900 +518400 +396900) / 5 = 208600
분산을 통해 평균을 중심으로 데이터가 얼마나 퍼져 있는지를 알 수 있다. 이때 제곱을 했기 때문에 값이 너무 커지는 문제가 있다. 그래서 분산의 결과에 루트를 사용해서 값을 낮추는데 그것이 표준편차이다. 즉, A회사의 표준편차는 2399가 되고 B회사의 표준편차는 457이 된다.
결과적으로 A회사의 평균연봉을 중심으로 값이 멀리 떨어져 있고 B회사는 평균연봉에 밀집되어 있는 것을 알 수 있다.
분산이 크다는 것은 평균으로부터 넓게 퍼져있다는 것
⑤ 변동계수
- 변동계수는 측정 단위가 다른 자료나 자료값의 차이가 너무 큰 경우에 사용한다.
- 변동계수를 다른말로 상대표준편차라고도 한다. 즉, 상대적인 산포를 계산한다.
- 변동계수 공식
- 변동계수는 표준편차를 산술평균으로 나눈 것
그래프
히스토그램
- 각 구간별 현황 및 대칭 여부를 확인하기 위해서 히스토그램을 사용할 수 있다.
- 데이터의 이상값 유무를 확인 할 수 있다.
#정규분포에 맞게 임의의 난수를 생성
x1 <- rnorm(10000)
# 히스토그램 생성
hist(x1)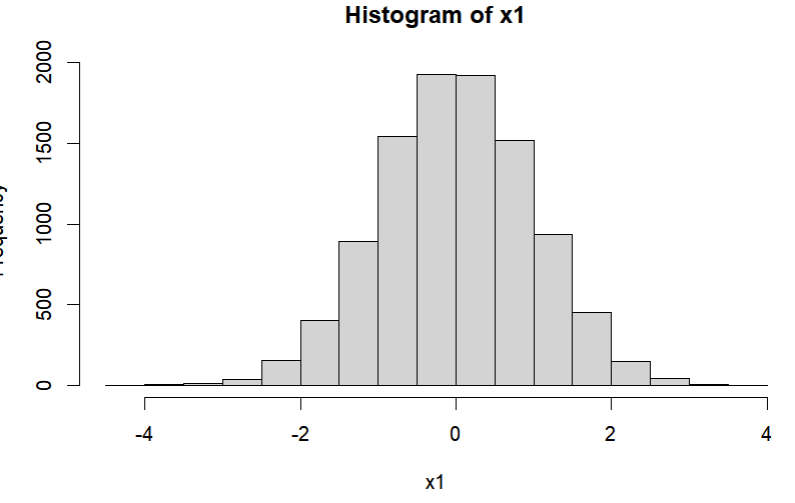
상자그림
- 상자 그림은 대칭여부, 이상값, 자료의 분포를 확인 할 수 있다.
- 최대값, 최소값, 중위값 및 이상값을 확인 할 수 있다.
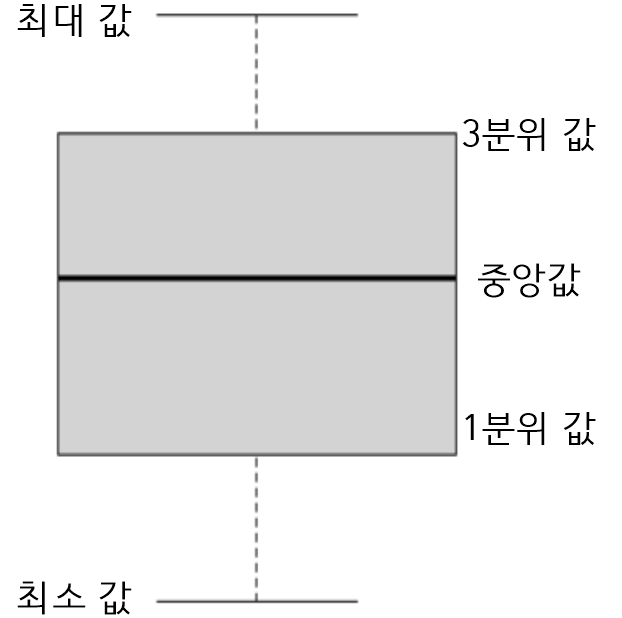
- 제1사분위수(Q1)
- 데이터의 25%가 이 값보다 작거나 같다.
- 제2사분위수(Q2)
- 중위수 데이터의 50%가 이 값보다 작거나 같다.
- 제3사분위수(Q3)
- 데이터의 75%가 이 값보다 작거나 같다.
- 사분위간 범위
- 제1사분위수와 제3사분위수 간의 거리(Q3-Q1)이고, 데이터 50%의 범위이다.
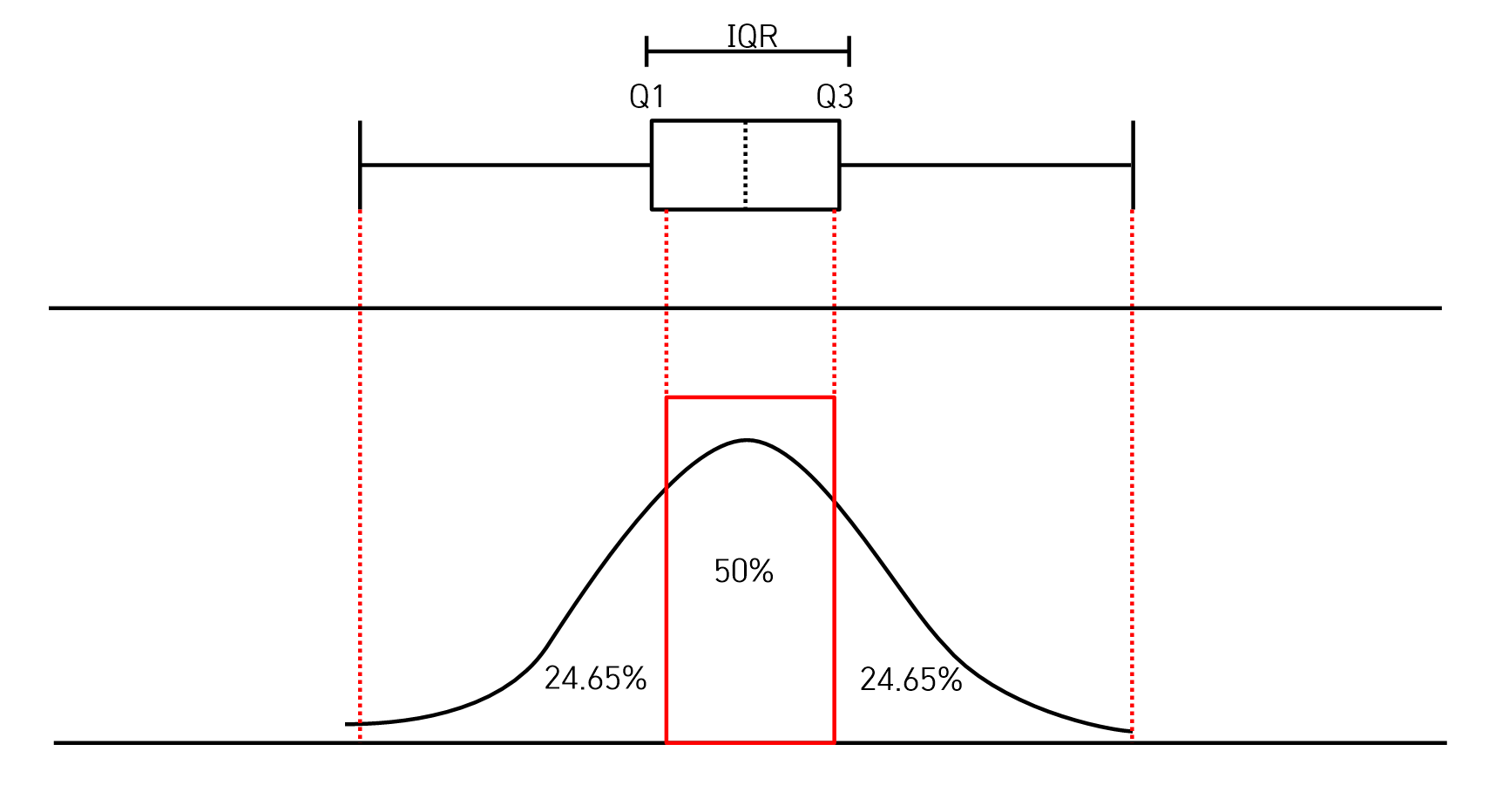
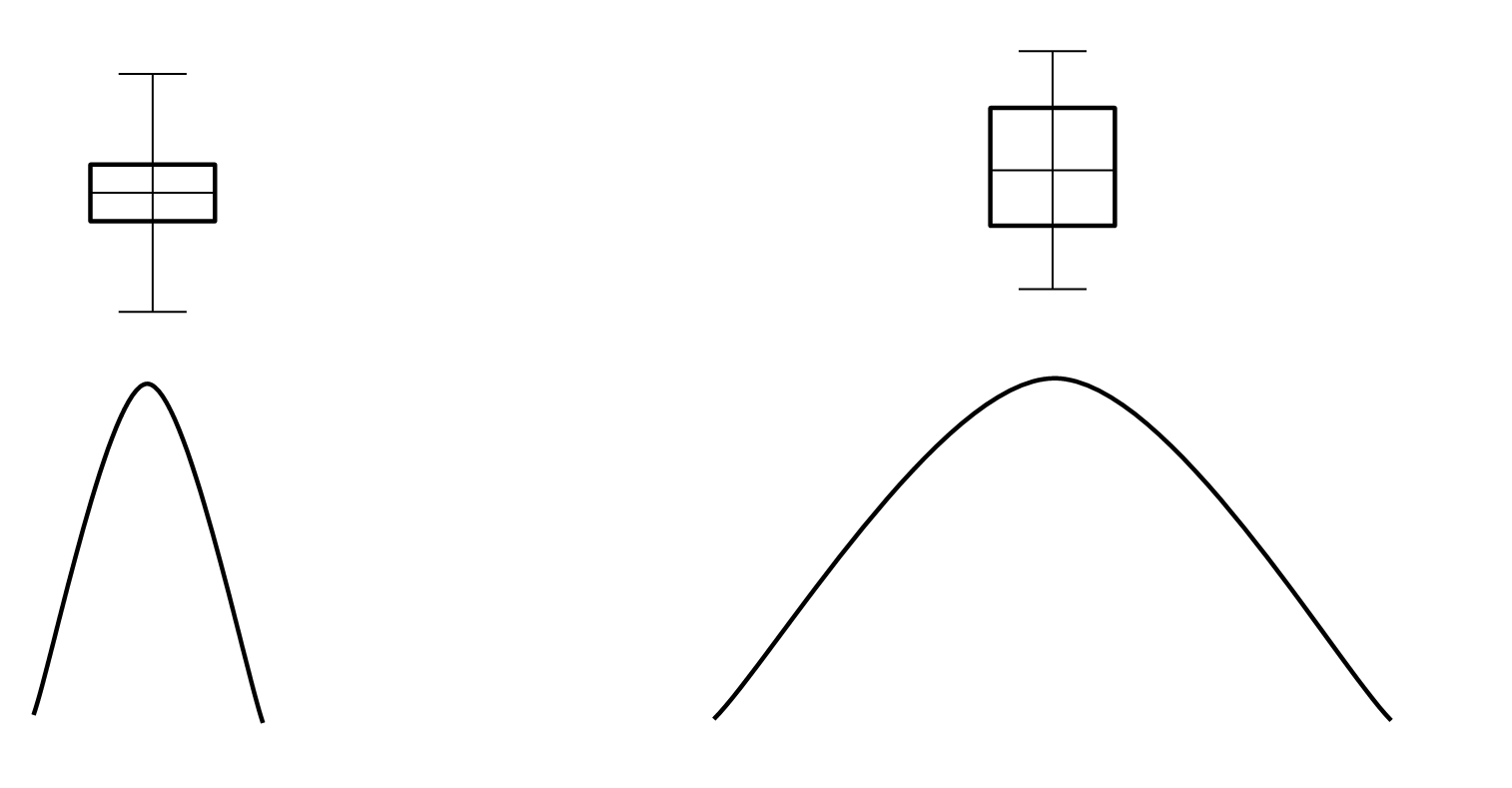
- 제1사분위수와 제3사분위수 간의 거리(Q3-Q1)이고, 데이터 50%의 범위이다.
- 왼쪽 상자그림의 박스 길이가 짧으면 평균을 중심으로 데이터가 모여있다는 것이다.
- 오른쪽 상자그림처럼 박스 길이가 길면 평균을 중심으로 데이터가 퍼져있다는 것이다.
시계열 분석
- 시계열 데이터는 관측지가 시간적 순서를 가지고 있다.
- 시계열 데이터는 주가, 환율, 거래량 변동, 기온, 습도 변화 등의 데이터
- 시계열 분석은 시계열 데이터를 사용해서 추세분석, 원인 예측, 전망 등을 분석하는 것으로 즉, 시간에 흐름에 따라서 관찰되는 데이터인 시계열 데이터를 분석하는 것
- 시계열 데이터의 목적은 미래를 예측하는 것
시계열 데이터 구성요소
- 시계열 데이터 구성요소는 추세, 계절적 변동, 주기적 변경, 임의변동이 있다.
- 추세
- 기술 혁신, 인구증가, 문화의 변화 등과 같이 장기간에 걸쳐 일정한 방향으로 지속적으로 상승 또는 하강하는 것
- 계절적 변동
- 봄, 여름, 가을, 겨울에 따라서 특정 소비가 증가, 감소하는 형태로 나타난다.
- 주기적 변동
- 경기동향, 실업률, 이자율과 같이 일정한 주기를 가지고 장기간에 걸쳐 변동된다.
- 임의 변동
- 불규칙 변동이라고 하며 우연한 요인에 의해서 발생되기 때문에 패턴이 없다.
추세 분해 방법
- Lowess/Loess 회귀
- 특정 범위에 다항 회귀선을 구하여 병합하는 방법
- 이동 평균
- 특정 기간 동안의 값의 평균변화를 분석
시계열 예측 분석
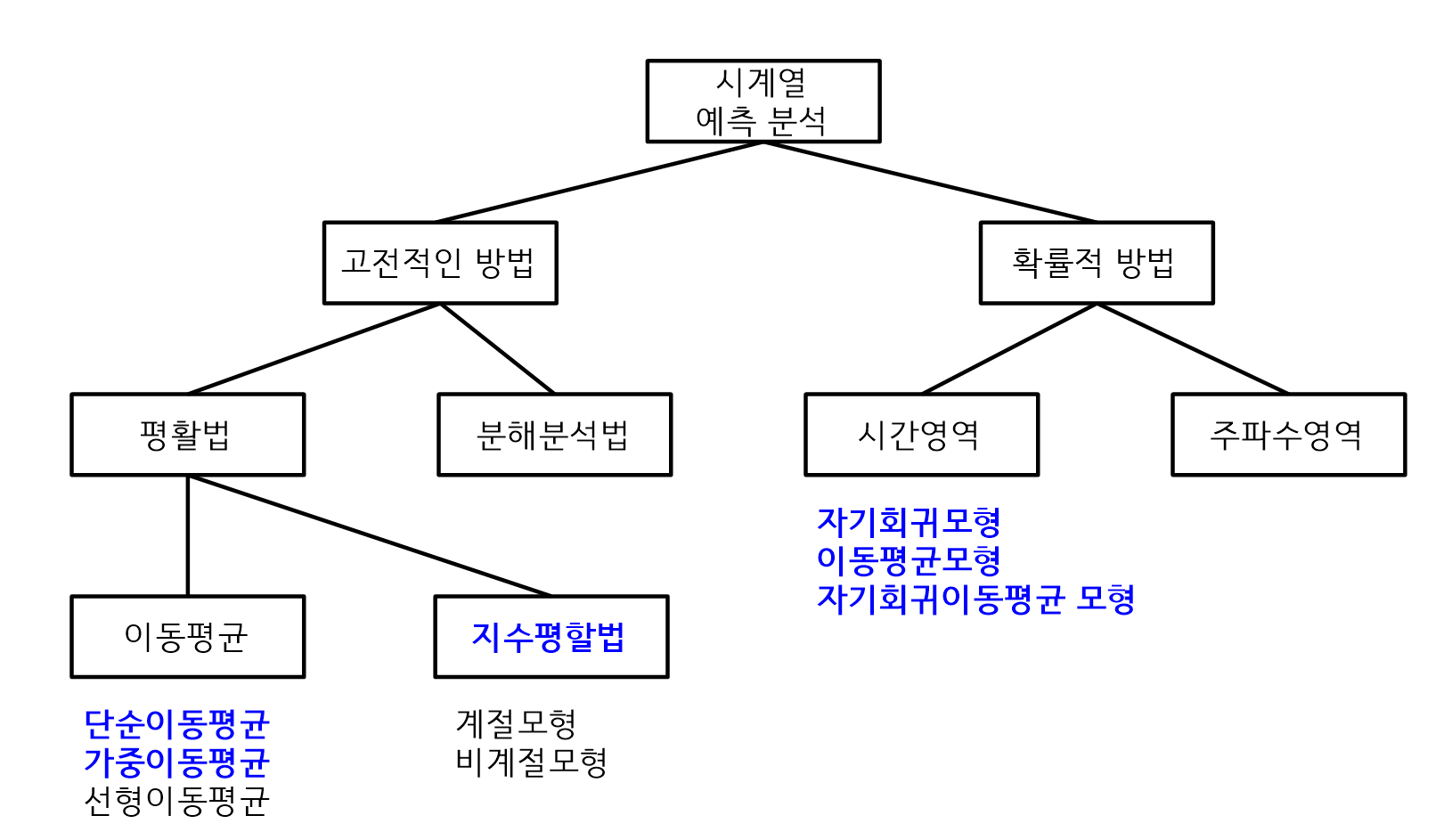
단순 이동평균
- 평활법이란, 불규칙한 변동을 평탄하게 하여 예측값을 구하는 방법
- 이동평균 중에서 추세가 없는 경우 적용
- 시계열의 평균수준이 시간과 관계 없이 변하기 않고 단지 불규칙 변동만을 포함하는 수평적 시계열 데이터에 적용
- m기간 동안의 자료의 평균을 예측값으로 추정
가중 이동평균
- 단순 이동평균에 가중치가 반영된 것으로 m기간으로 설정하면 m기간의 값에 가중치를 곱해서 예측값이 m+1기간에 나타난다.
- 시계열의 평균수준이 시간과 관계없이 변하지 않고 단지 불규칙 변동만을 포함하는 수평적 시계열 데이터에 적용한다.
지수평활법
- 가중이동평균 방법과 매우 유사하지만 가중치가 과거로 올라갈수록 지수함수적으로 감소
- 과거의 모든 자료를 사용하고 장기적인 추세가 있는 경우에 사용
- 지수평활화 방법은 계절모형과 비계절모형으로 분류된다.
자기회귀모델
- 자기회귀, 자기 자신에 대한 변수의 회귀를 의미
- 자기회귀모델은 목표변수들의 선형조합을 이용하여 관심 변수를 예측하는 방법
- 변수들의 과거 값에 대해서 선형조합을 사용해서 관심 변수를예측
- ARMA모형은 자기회귀모델과 이동평균모델을 사용한 것
- 백색잡음
- 시계열 데이터에서 특정 기준시점을 지정하고 기준시점과 이전과의 차이를 잡음이라고 한다.
- 자기상관이 없는 시계열을 백색잡음이라고 한다.
자기상관모형
- 자기상관이란 어떤 Random 변수에 대해서 이전의 값이 이후 값에 미치는 상황을 의미
- 예를 들어 이전 값이 크면 이후에는 낮은 값이 나온다는 경향을 의미
안정적 시계열
- 안정적이란, 평균과 분산 등의 통계적 특성이 변화되지 않는 데이터를 의미한다.
정적 데이터 모델링
- 평균, 분산 등의 통계적특성이 변화되지 않는 데이터를 의미
- 뚜렷한 추세를 확인할 수가 없다.
- 시간이 지나도 분포도에 변화가 없다.
정적 데이터 모델링
- 이동평균모델
- T시점과 이전 시점들 사건의 영향의 가중평균
- 일반적으로 오래된 사건은 영향도가 낮아진다.
- 자가 회귀 모델
- T시점의 값은 이전 특정 시점의 값에 영향을 준다.
- 자기상관함수, 자기부분 상관함수를 사용
- 자가회귀 이동평균 모델
- 자기 연관성과 자기 회귀성을 검사
비정적 데이터 모델링
- ARIMA(Auto-regressive Integrated Moving Average)는 시계열 기법으로 과거 관측값과 오차를 사용해서 현재 시계열 값을 설명하는 것
- ARIMA 모델은 안정적인 시계열 뿐만 아니라 비안정적에도 가능한 모델이다.
- ARIMA 모델은 변동의 형태를 파악하여 변동 형태로 예측이 가능한 장점이 있다.
채권시강, 증권시장 등에서 많이 사용되고 있다.
