
모델성능평가
모델성능평가 개요
- 빅데이터 분석 시에 분석 모델을 평가하기 위해서 각 모델에서 성능평가를 실시한다.
- 과적합을 방지해서 실제 업무에 적용할 때 분류와 예측력을 향상 시킨다.
- 빅데이터 분석모델에 대해서 예측모델과 분류모델에 대해서 성능평가를 실시한다.
- 예측 및 분류모델에 대해서 다양한 세팅을 한다.
- 최적의 모델을 찾기 위해서 모델을 평가한다.
- 빅데이터 분석모델 성능평가는 결과변수가 있는 지도학습에 대해서 평가할 수 있으며 비지도 학습인 경우 결과변수가 없기 때문에 분석모델의 정확성을 평가하기 어렵다.
- 지도학습에서만 사용되는 것으로 결과변수를 알고 있을 때 예측 및 분류모델의 유용성을 평가하고 다른 모델과 상호 비교할 수 있는 방법
모델 성능평가 종류
- 예측모델 성능평가
- 예측된 데이터에 대해서 성능평가를 실시한다.
- 평균오차, MAPE, RMSM, 향상차트를 사용해서 평가한다.
- 분류모델 성능평가
- 분류된 데이터가 올바르게 분류되었는지를 확인한다.
- 정오행렬, 분류행렬, 정확도, 오분류율, 민감도, 특이도, ROC도표, 향상차트를 사용해서 평가한다.
- 랭킹 성능평가
- 점수를 활용해서 등수로 분류
- 향상차트를 사용한다.
- 확대 샘플링
- 샘플링이 적은 경우 개체 수를 증가하거나 cut-off를 증가 시켜서 실시한다.
지도학습의 결과 정보
- 예측값
- 예측모델로부터 도출된 수치형 데이터
- 예측된 클래스 소속도
- 분류모델은 결과변수가 범주형인 경우
- 경향
- 결과변수가 범주형인 경우 클래스 소속도의 확률
경향
- 분류
- cut-off를 사용해서 클래스 소속을 예측한다.
- 랭킹
- 관심이 있는 클래스에 속할 가능성 있는 큰 집단을 추출한다.
예측모델 성능평가
예측모델
- 예측모델이란 결과변수가 수치형인 데이터로 예로 학생의 공부시간에 따른 성적이 어떻게 나오는지 예측하는 것
- 예측모델의 가장 대표적인 것이 회귀분석이다.
- 회귀분석은 통계적으로 변수들 사이의 관계를 추정하는 방법
예측모델 성능평가
- 모델 성능평가란 실제 값하고 예측 값하고 비교해서 오차를 구하는 것
- 실제값 - 예측값 = 0 이되면 오차가 없는 것, 100% 적중한 것이다.
- 예측값과 실제 값과 100% 적중하기 어렵기 때문에 오차를 구해서 어느 정도까지 허용할지를 것이 모델 성능평가다.
편차
- 평균으로부터 떨어진 거리를 편차라고 한다.
- 평균을 모두 더하면 편차는 0이되기 때문에 자승을 하는 분산을 사용하고 다시 분산에 루트를 씌워서 표준편차를 구하는 것이다.
- 자료가 어떻게 분포되었는지를 확인
잔차
- 회귀 직성하고 실제 데이터가 얼마나 떨어져 있는지 평가
- 회귀분석에서 사용되고 회귀직선 모델에 적합도를 확인
오차
- 실제 값과의 차이를 의미하며 데이터마이닝에서 사용
- 실제값과의 차이를 의미, 정합도라고 한다.
예측모델 평가척도
- 예측모델 평가척도는 평균을 사용해서 오차를 확인한다. 따라서 이상치에 영향을 크게 받기 때문에 이상치를 제거한다.
평균오차
- 예측 값이 평균적으로 반응의 예측을 초과하거나 미달하는지는 확인한다.
- 즉 실제 값하고 평균 값하고 차이를 의미하며 자승을 하지 않기때문에 차이가 없으면 0에 가까운 값이 나온다.
- 음의 오차는 동일한 크기의 양의 오차를 상쇄시킨다.
- 절대값을 사용하지 않기 때문에 초과와 미달을 확인 가능
절대평균오차
- 절대값을 사용해서 오차를 확인
평균백분율오차
- 예측값이 실제값과 얼마나 벗어났는지를 확인
절대평균백분율오차
- 예측결과가 평균적으로 얼마나 실제 값에서 벗어나는지를 백분율 점수로 나타낸다.
- 퍼센트에 절대값을 준 것이다.
평균제곱오차의 제곱근
- 오차에 자승과 루트를 사용해서 표준편차와 비슷하며 많이 사용한다.
향상차트
- 관심이 있는 클래스에 속할 가능성이 가장 높은 데이터의 부분집합을 추출한다.
- 리프트는 분석을 하지 않고도 예측한 값을 1이라고 할 때 1이상 예측을 하는 확률을 의미한다.
- 상대적으로 사례를 적게 선택하고 상대적으로 높은 응답자 비율을 찾는 것이다.
- 기준선은 예측모델을 사용하지 않고 알 수 있는 선이고 기준선을 1로 할 때 예측모델을 사용하면 기준선보다 몇 배 더 높은 정확도를 갖는지 분석하는 것이다.
분류모델 성능평가
분류모델
분류모델 성능평가
- 분류모델은 결과값이 범주형으로 대출 가능 혹은 불가, 신용상태 우수 혹은 불량 등의 데이터로 분류하는 것이다.
- 분류모델은 데이터를 가장 잘 분류할 수 있는 예측 변수를 찾는 것이 가장 중요하다.
즉, 예측변수는 데이터를 가장 잘 구분할 수 있어야 한다.
분류모델 평가기준
- 일반화 가능성
- 데이터를 확장해서 적용가능한지 평가한다.
- 모집단 내의 다른 데이터에 적용해서 안정적인 결과를 제공하는 것을 의미한다.
- 효율성
- 얼마나 효과적으로 구축 되었는지를 평가한다.
- 적은 입력변수를 필요로 할수록 효율적이다.
- 예측과 분류의 정확성
- 분석모형의 정확성 측면에서 평가한다.
오분류 오차
- 오차는 실제 값과 예측 값의 차이로 분석모델이 실제 클래스가 아니라 다른 클래스로 분류하는 것을 의미한다.
- 오차율은 Validation 데이터의 오분류 비율이다.
정오행렬
- 정오행렬은 분류결과의 정확성을 평가하기 위한 방법을 제공한다.
- Training데이터와 Validation 데이터를 사용해서 검증하며, 과적합 검증도 가능하다.
경향
- 결과변수가 범주형인 경우 클래스 소속도의 확률이다.
- 경향은 업무의 중요도에 따라서 정확도가 떨어질 수는 있지만 분석 목적의 중요도에 따라서 Cut-off를 조절해야 한다.
F-Measure
- 정확성을 측정하는데 사용하는 방법으로 정확도와 재현율을 구해야 한다.
- 분류가 얼마나 정확하게 분류되었는지를 판단하는 척도 중에 하나이다.
- 정확도(Precision)과 재현율(Recall)을 하나의 지표로 통합해서 정확성을 측정한다.
- 정확도와 재현율은 조화평균을 구할 수 있으며 모두 높으면 100% 정답을 찾은 것이고 재현율만 높다면 정답이라고 생각 되는 것은 많이 찾지만 대부분 오답이다. 정확도가 높다면 정답의 개수는 적지만 대부분 정답이다.
Precision(정확도)
- 양성으로 판단하는 것 중에 진짜 양성의 비율
Recall(재현율)
- 진짜 양성 중에서 양성으로 올바르게 판단한 비율
- 실제 True인 것 중에서 모델이 True로 예측한 비율
F-Measure 종류
- F1 Measure
- 정확도와 재현율 모두 중요하다.
- F2 Measure
- 정확도보다 재현율이 중요하다.
- F0.5 Measure
- 정확도가 재현율보다 중요하다.
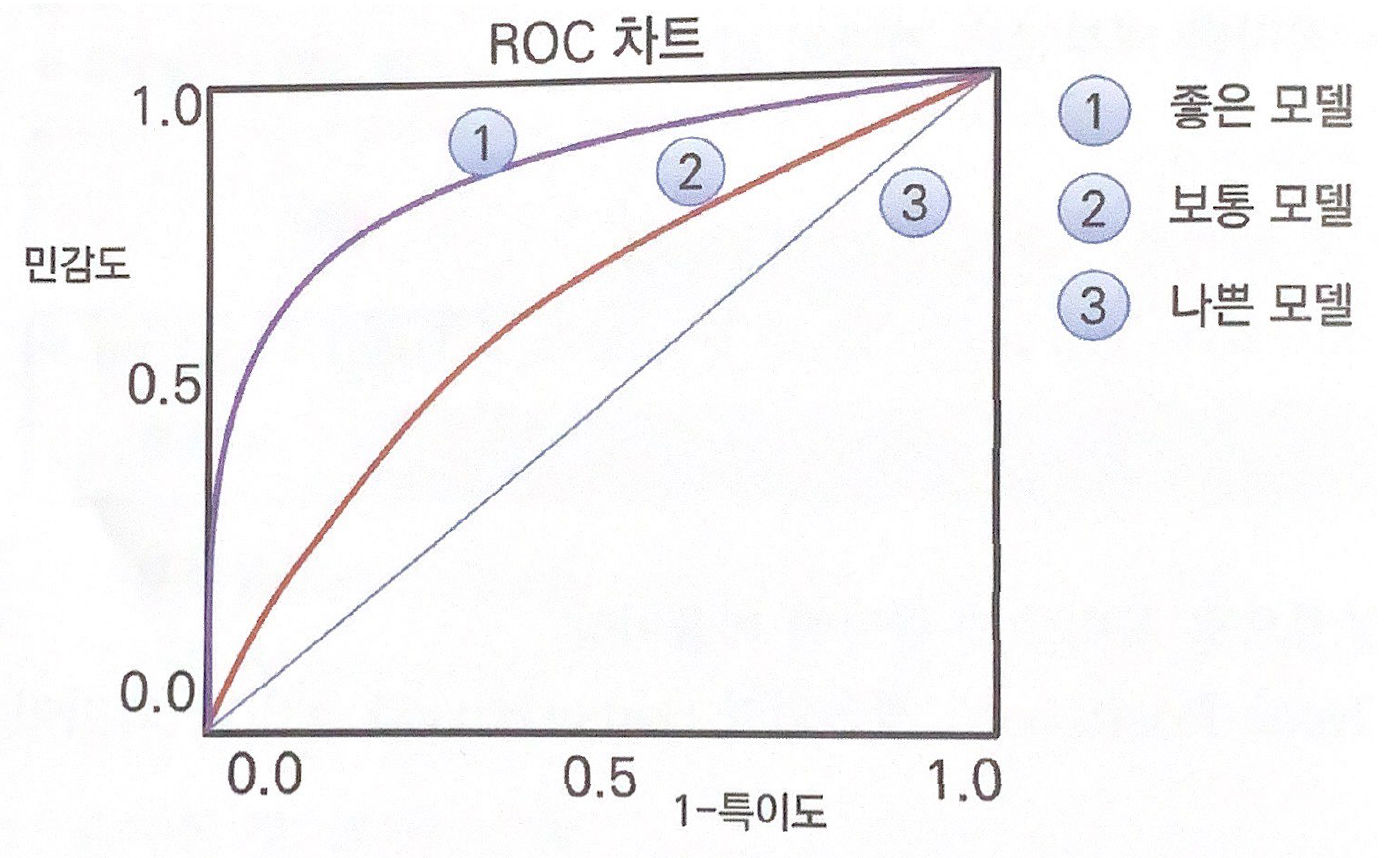
ROC(Receiver Operating Characteristic)
- ROC Curves는 모델의 성능을 평가하기 위한 방법 중에 하나로 민감도와 특이도를 사용해서 모델의 성능을 평가한다.
- 민갑도는 실제 양성인데 모델도 양성을 평가하는 비율이고 특이도는 정상을 음성으로 평가하는 비율이다.
- 민갑도는 정분류와 오분류 중 관심 대상에 대해서 더 잘 맞추는지 확인할 수 있다. 즉, 관심있는 대상에 대해서 민감도를 계산한다.
- 특이도는 민감도와 반대로 계산해서 관심 없는 대상을 파악하는 것이다.
- 민감도와 특이도는 Trade-off관계를 가지고있다.
랭킹 성능평가
랭킹
- 사용자가 관심있는 클래스에 속할 가능성이 큰 집단을 추출한다. 랭킹은 경향을 사용해서 결과 변수가 범주형일 때 클래스 소속도의 확률을 계산한다.
- 향상차트를 사용해서 결과변수가 범주형일 때 클래스 소속도의 확률을 계산한다.
향상차트
- 향상도 곡선을 사용하면 예측모델이 무작위 예측모델보다 얼마나 더 좋은 성능인지를 확인 할 수 있다.
확대 샘플링
확대 샘플링
- 샘플링되는 데이터가 적을 때 추가적으로 샘플을 확보하거나, 샘플을 확보하기 어려울 때는 가중치를 사용한다.
- 표본이 비대칭 구조를 가지고 있다.
- 가중치를 사용하면 샘플링이 적은 데이터에서 특정 값을 곱해서 평가한다.
모험형가 시에 데이터 추출방법
홀드아웃
- 랜덤 추출방식으로 학습용 데이터와 검증용 데이터를 7대3 비율로 추출한다.
#R에서 수행하는 방법
sample(2, nrow(iris), replace = TRUE, prob = c(0.7,0.3))교차검증
- 데이터를 K개로 나누고 K번 반복측정한다. 최종결과를 평균 내어 평가한다.
부트스트랩
- 교차검증과 비슷하게 반복측정하지만 학습용 데이터를 반복해서 재선정한다.
- 복원 추출법으로 학습용 데이터를 한번 이상 사용한다.

AllTimeDevelop