
군집분석과 연관규칙
자율학습(비지도학습, Unsupervised learning)
- 목표변수가 없는 상태에서 학습을 통해서 모델을 만드는 기법이다
- 군집분석
- 데이터를 특성에 따라 군집화하고 군집으로 전체 데이터의 특성을 파악한다.
- 연관규칙
- 대용량 데이터베이스에 발생하는 데이터를 분석하여 각 거래 간의 상호 관련성을 분석하는 방법
군집분석(Cluster analysis)
- 객체들을 유사한 속성으로 군집하는 데이터마이닝 기법, 계층적 방법과 비계층적 방법이 있다.
- 결과변수 값을 알지 못하는 상태에서 군집을 수행하는 자율학습기법이다.
- 각 객체 간의 유사도를 측정하여 군집을 생성한다.
- 군집은 객체 간의 거리 값을 측정하여 생성되고 거리 값은 각 객체 간의 유사도를 계산하여 생성한다.
- 위의 그림처럼 각 객체들을 유사한 것으로 묶어주는 방법이다. 즉, 소득에 따른 기업 충성도를 분석하거나, 기업의 우수고객, 유입고객, 신규고객 등을 군집화할 수가 있다.
군집분석을 위한 유사성 척도
- 군집을 묶기 위해서는 각 객체 간의 유사성을 측정하여 군집을 묶는다.
- 군집분석의 유사성 척도는 거리척도, 상관계수 척도가 있다.
- 거리척도
- 거리 값을 생성하여 그 값을 기준으로 군집을 생성한다.
- 즉, 거리 값이 가까우면 유사성이 높고 거리 값이 멀어지면 유사성이 낮다.
- 상관계수 척도
- 객체 간에 상관계수를 계산하여 유사성을 결정한다.
- 객체 간에 상관계수가 크면 유사성은 높아지고 상관계수가 작으면 유사성은 낮아진다.
거리척도를 사용한 유사성 계산기법
유클리디안 거리
- 유클리드라는 수학자가 만든 공식, n차원의 공간에서 두 점간의 거리를 계산
- 유클리드 거리 계산법은 L2 distance라고도 한다.
- 각 객체의 속성 값을 기준으로 각 객체사이의 유사도를 측정한다.
- 유클리디안 거리
유클리디안 거리 R로 계산하기
data <- matrix(
c(140,50,120,55,78,80,95,85,95,90),
nrow=5,
ncol=2,
byrow=T
)
data # 1열은 소득, 2열은 충성도이다
D1 <- dist(data) #유클리디안 거리를 구한다.
D1
- 1에서 2로 가는 경로 값은 20.61553이다.
- 1에서 3으로 가는 경로는 68.8767이다.
민코프스키 거리
- 유클리디안 거리의 일반화된 방법으로 m값이 2일때는 유클리디안 거리와 동일하다.
- 민코프스키 거리
민코프스키 거리 R로 계산하기
D2 <- dist(data, method = "minkowski", p=3)
D2

- 결과는 유클리디안과 거의 동일하다.
마할라노비스 거리
- 변수 간에 상관관계가 있는 경우 사용하는 유사성 척도이다.
멘하튼 거리
- 유클리디안 거리 계산법은 각 객체 간의 거리를 계산할때 직선으로 계산하지만 맨하튼 거리는 객체의 거리를 계산하는 경우 각 객체를 이어주는 길을 고려해서 측정하는 방법이다.
- 멘하튼 거리
멘하튼거리 R로 계산하기
D3 <- dist(data, method = "manhattan")
D3
상관계수를 사용한 유사성 계산
- 두 개의 변수 간에 상관계수를 산정하여 유사성을 산정한다.
- 상관계수가 크면 두 객체 간의 유사성이 크다.
data2<-matrix(
c(18,6,14,20,7,15,43,4,2),
nrow=3,
ncol = 3,
byrow = T
)
data
cor(data2[1,], data2[2,])- 위의 예는 data2[1]과 data2[2] 객체 간의 상관계수를 구한 것이다. 즉, 매트릭스 내에 있는 모든 데이터에 대해서 상관계수를 구한다.
- 상관계수가 크면 유사성이 크기 때문에 군집분석에서 군집의 기준으로 사용된다.
군집분석의 종류
- 군집분석은 사전에 k값을 결정하지 않고 트리 형태로 군집을 생성하는 계층적 군집분석과 사전에 k값을 결정하고 군집을 생성하는 비계층적 군집분석이 있다.
계층적 군집분석
- 군집분석을 하기 전에 사전에 최적 k를 결정하지 않고 트리형태로 군집을 생성한다.
- 상위 트리의 계층을 만들고 반복해서 하위 트리를 생성하는 방법이다.
- 계층적 군집분석은 트리 형태 구조로 군집을 하기 때문에 어느 레벨에서 군집을 중단 할 것인지를 결정해야 한다.
계층적 군집분석의 종류
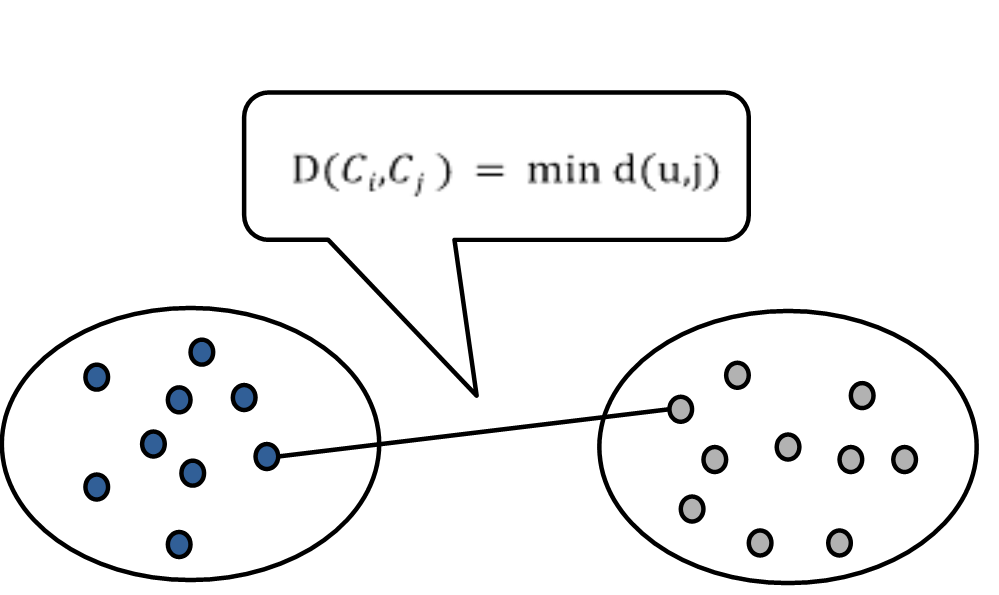
① 단일 연결법
- 군집i와 군집j에 유사도 척도를 사용해서 두 군집에 있는 객체 중 가장 가까운 거리를 사용하여 연결하는 방법이다.
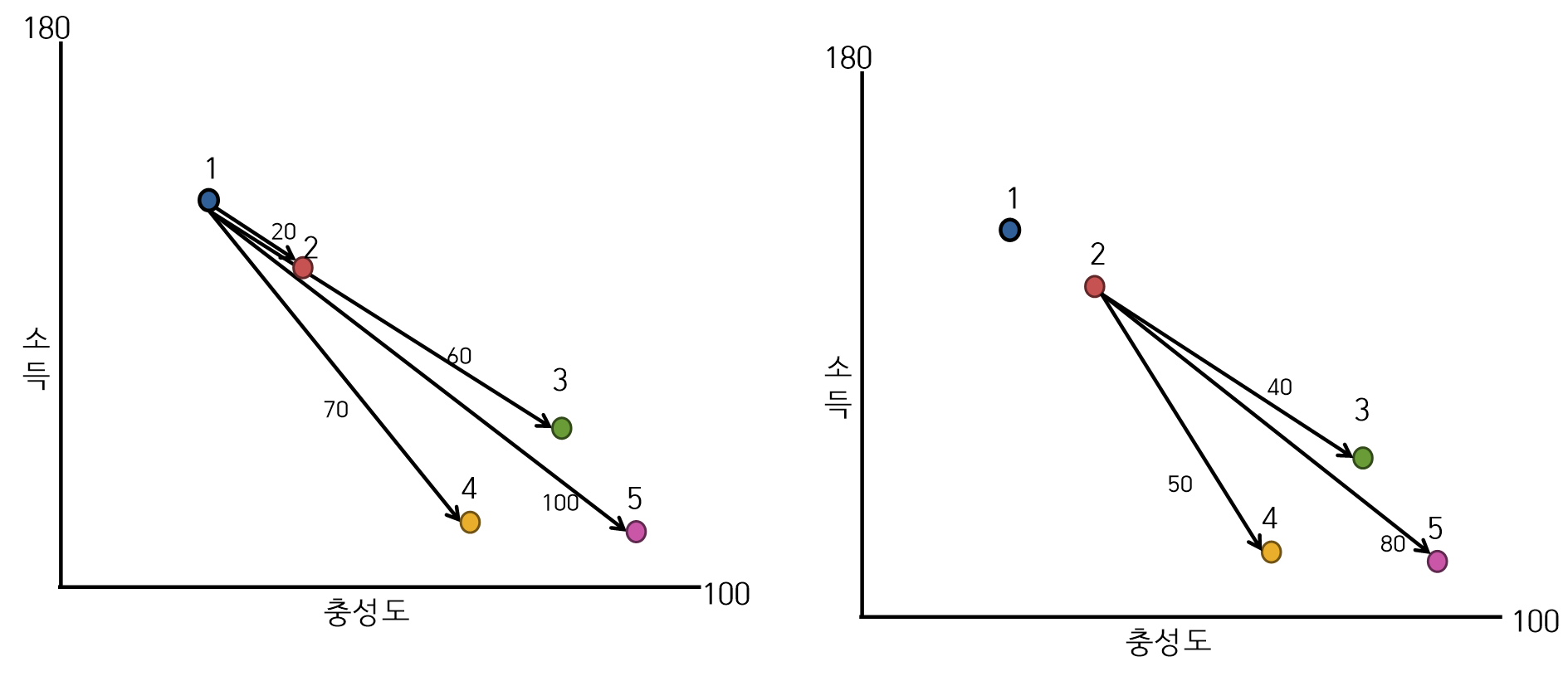
- 유클리디안 거리를 사용한 단일 연결법 군집과정(1단계)
- 유클리디안 거리를 사용한 단일 연결법 군집과정(2단계 : 거리계산)
- 거리계산
- 1 → 2 : min(20) = 20
- 1 → 3, 4, 5 : min(60,70,100) = 60
- 2 → 3, 4, 5 : min(40,50,80) = 40
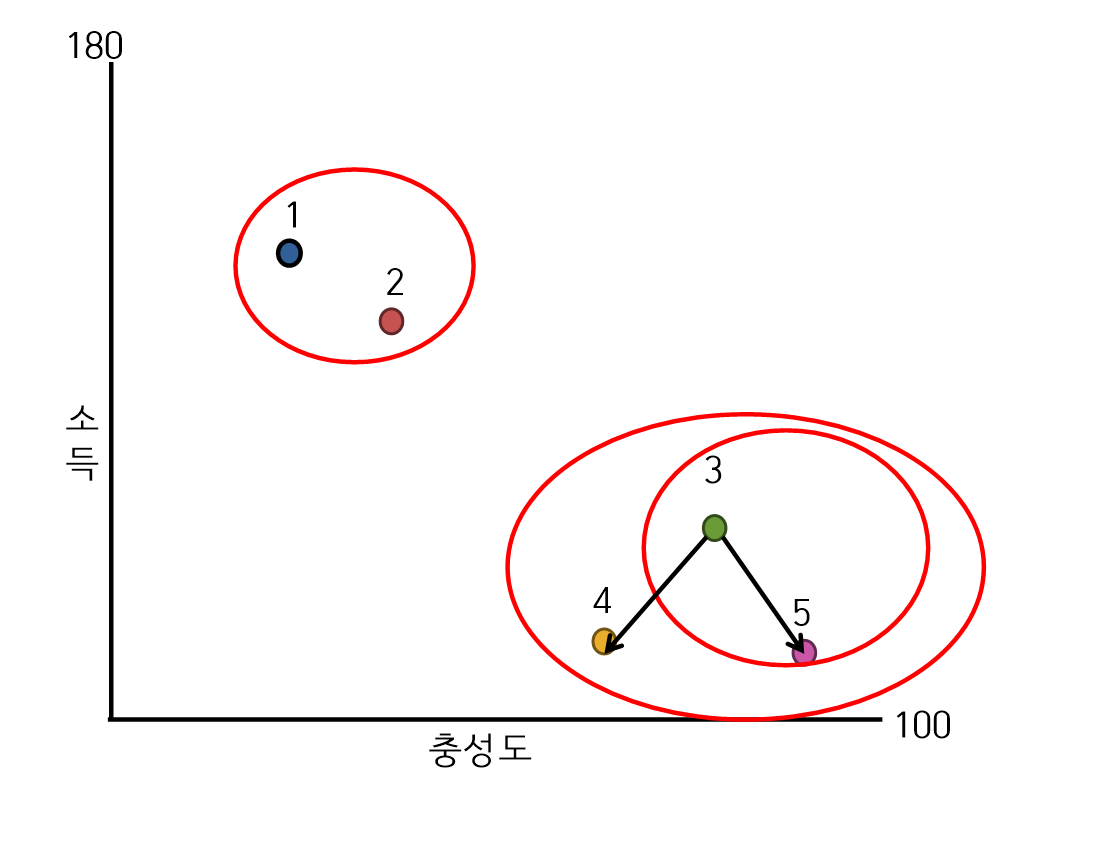
- 거리계산
- 유클리디안 거리를 사용한 단일 연결법 군집과정(3단계 : 군집)
- 덴드로그랩
- 덴드로그램은 각 단계에서 관측지의 군집화로 만들어진 그룹을 유사성을 기준으로 표현하는 트리 다이어그램으로 군집이 어떻게 형성되는지와 군집의 유사성 수준을 확일 할 수 있다.
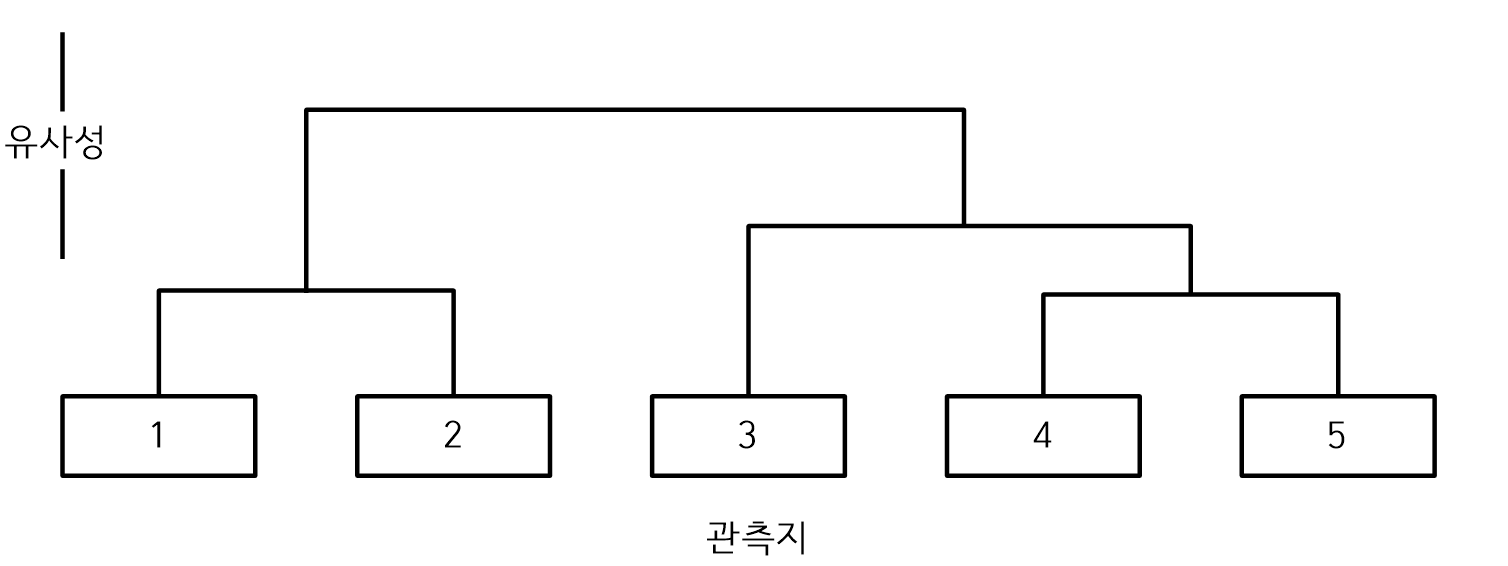
- 덴드로그램은 각 단계에서 관측지의 군집화로 만들어진 그룹을 유사성을 기준으로 표현하는 트리 다이어그램으로 군집이 어떻게 형성되는지와 군집의 유사성 수준을 확일 할 수 있다.
② 완전 연결법
- 군집에 있는 두 객체간에 가장 먼 거리를 사용하여 군집을 연결한다.
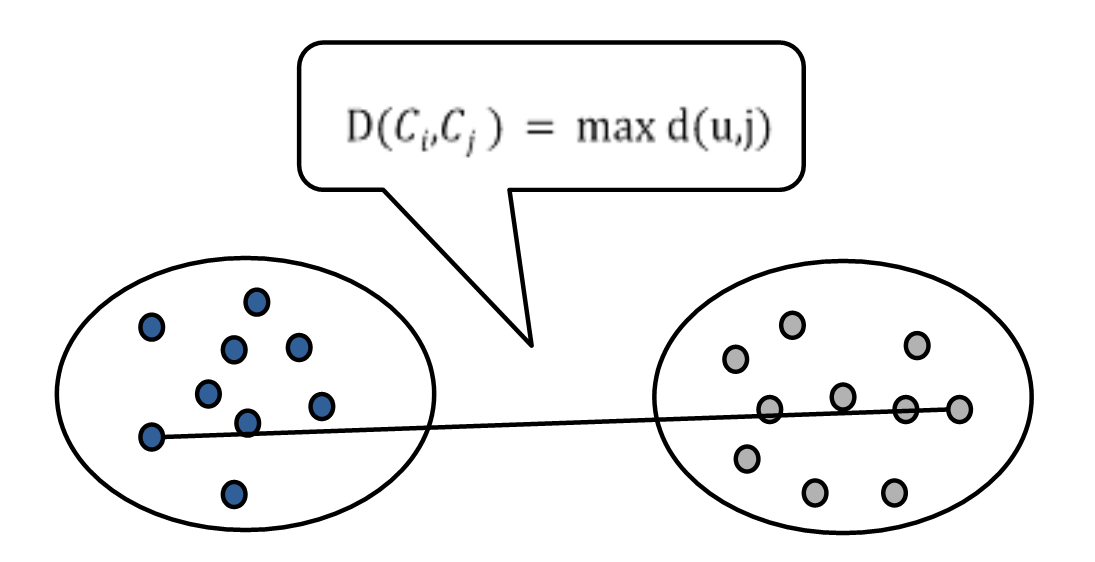
③ 평균 연결법
- 두 군집에 있는 모든 객체에 대해서 평균거리 값을 사용해서 군집을 연결한다.
④ 중심 연결법
- 두 군집에서 중심좌표를 계산하여 두 개의 군집을 연결한다.
⑤ 워드 연결법
- 연결 가능한 군집조합에서 군집을 연결한 후에 군집 내 제곱합을 계산하고 최소 제곱합을 가지는 군집 간에 연결을 하는 방법, 제곱합은 군집의 중심에서 관찰지까지 거리 제곱하을 의미한다.
- 워드 연결법(와드 연결법)은 거리 계산을 위해서 유클리디안 거리를 사용하는 방법이다.
비계층적 군집분석
- 군집분석을 하기 전에 먼저 최적 k를 결정하고 각 객체를 k개 중 하나의 군집에 배정하는 것이다.
비계층적 군집분석의 종류
- 비계층적 군집
- K-means 알고리즘
- K-medoids 알고리즘
- PAM
- CLARA
K-means 알고리즘
- 비계층형 군집분석에서 가장 많이 사용되는 방법으로 군집의 중심좌표를 고려해서 각 객체를 가까운 군집에 배정하는 방법
K-means 알고리즘
| 실행단계 | 내용 |
|---|---|
| 초기객체를 선정 | K개의 개체좌표를 사용해서 초기 군집좌표를 선정한다. |
| 객체 군집 배정 | 각 객체와 K개의 중심좌표와 거리를 산출한다. 거리가 가장 가까운 군집에 객체를 배정한다. |
| 군집 중심좌표 산출 | 새로운 군집에 대해서 중심좌표를 다시 산출한다. |
| 수렴조건 점검 | 이전의 중심좌표와 새로운 중심좌표를 비교해서 수렴조건을 만족하면 알고리즘을 종료한다. 수렴조건 미충족 시 객체 군집 배정으로 이동하여 반복한다. |
install.packages("DAAG")
install.packages("lattice")
library(DAAG)
data("wages1833")
head(wages1833, n =10)
dat <- wages1833
dat <- na.omit(dat)
#최적 k를 구하기 위한 패키지
install.packages("factoextra")
library(factoextra)
fviz_nbclust(dat, kmeans, method = "wss")
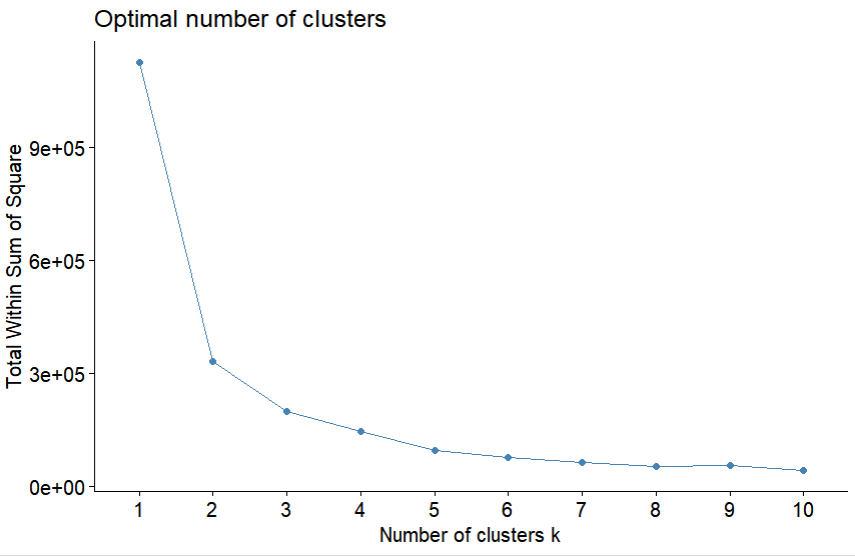
#k-means 시각화
set.seed(200)
km <- kmeans(dat, 3, nstart = 25)
fviz_cluster(km, data = dat, ellipse.type = "convex", repel = T)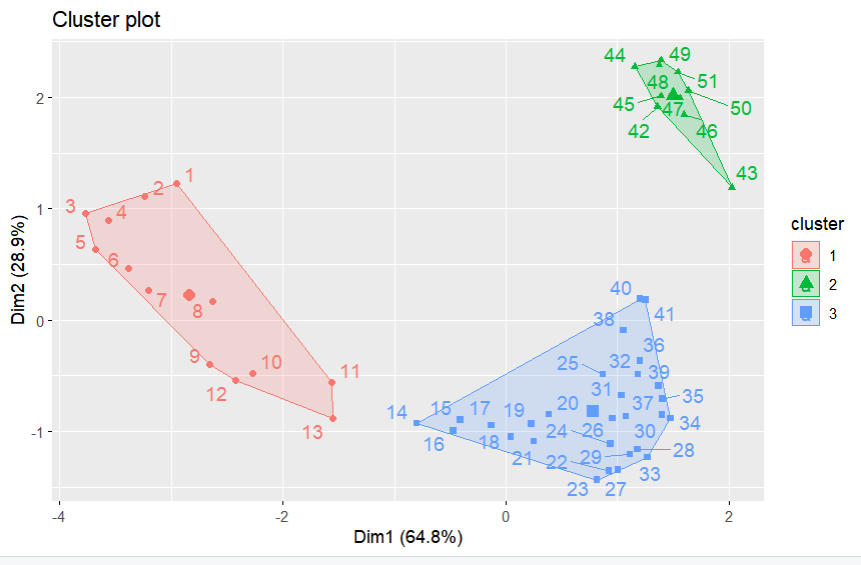
K-medoids 알고리즘 / Top-down 방식
- 군집 내에서 다른 객체들과의 거리가 최소가 되도록 하는 대표 객체를 고려하는 방법으로 PAM과 CLARA 알고리즘이 있다.
- 객체가 속한 군집의 대표 객체와의 거리 합을 최소로 하는 방법이다.
K-medoids 알고리즘 종류
| 종류 | 내용 |
|---|---|
| PAM 알고리즘 | PAM은 중앙점을 사용해서 N개의 모든 데이터를 최종 K개의 군집으로 군집화시키는 방법이다. 임의로 K개의 관측지를 중앙점으로 할당하고 모든 관측지에서 중앙점까지 거리의 총합이 최소화 될 때까지 중앙점을 할당한다. 총합을 계산하기 때문에 큰 데이터에서는 성능이 떨어질 수 있다. |
| CLARA 알고리즘 | 모든 객체를 대상으로 하지 않고 객체 중 일부만 대표 값으로 해서 군집화한다. 샘플링을 수행하고 PAM알고리즘을 사용해서 대표 객체를 선정한다. |
library("cluster")
pamout <- pam(dat,3)
pamout
table(pamout$clustering)
#PAM 결과 시각화
fviz_cluster(pamout, data = dat, ellipse.type = "convex", repel = F)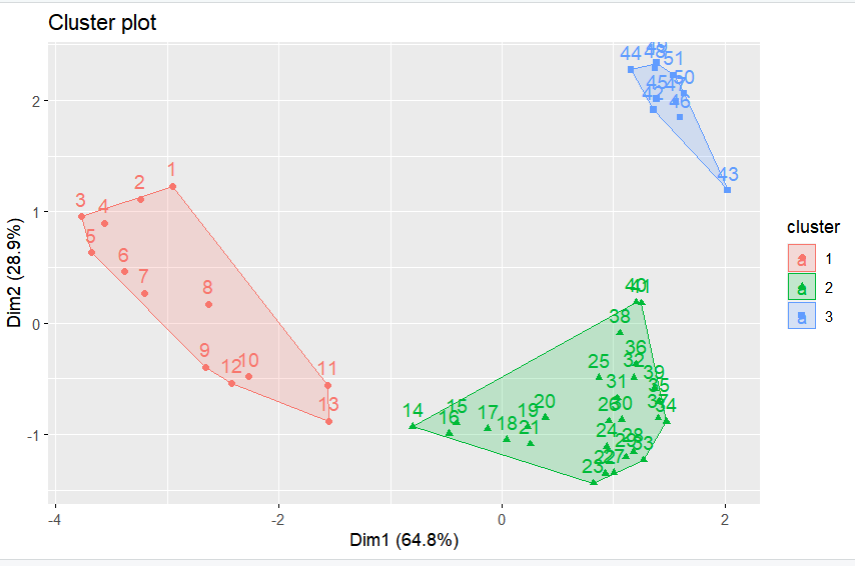
SOM(Self Organizing Map)
SOM
- 코호넨에 의해 개발도니 것으로 자기조직화 네트워크 기법이다.
- 군집분석 시에 신셩망 분석을 수행하는 방법이며 거리 값은 유클리드의 거리수식을 사용한다.
- 신경망과 K-means 기법의 특징을 모두 가지고 있다.
SOM특징
- 데이터 간에 잘 구분되지 않은 상관관계를 확인할 수가 있다.
- 자율학습으로 군집화를 수행한다.
- 신경망에서 사용하는 Back-propagation 과정이 없다.
- Back-propagation 과정이 없어서 수행 속도가 빠른 장점이 있다.
연관규칙
- 대용량 데이터베이스에 발생하는 데이터를 분석하여 각 거래 간의 상호 관련성을 분석하는 방법이다.
- 규칙기반 머신러닝 기법으로 데이터베이스에서 발생하는 강력한 규칙을 식별한다.
- 특정 사건들은 동시에 발생한다는 패턴에 대해 상호관련성을 분석하는 방법으로 연관규칙은 원인과 결과의 직접적인 인과관계가 아니다.
- 장바구니 분석, 친화성 분석에 이용된다.
- 연관규칙
- X 사건이 발생하면 Y 사건이 발생할 확률을 계산한다.
연관규칙의 활용
- 보험사기 적발, 상품진열, 교차판매
Apriori 알고리즘
- Apriori 알고리즘은 가장많이 사용하는 연관규칙 알고리즘이며, Apriori 알고리즘을 개선한것으로 AprioriTID, AprioriHybrid, DHP 등이 있다.
- 빈도 수를 분석하여 높은 빈도를 가지는 조합을 찾는다. 조합의 수가 증가하면 모든 조합을 생성해야 하기 때문에 계산시간이 증가한다.
- 최소 지지도 값을 설정하여 빈도 수가 높은 항목의 집합들을 도출한다.
- 지지도를 사용해서 다음 단계로 후보군을 설정한다.
연관규칙 측정방법
- 연관규칙의 측정은 지지도, 향상도, 신뢰도를 사용해서 측정한다.
지지도
- 두 항목의 X와 Y의 지지도는 전체 거래 중에서 항목집합 X와 Y를 포함한 거래 건수의 비율이다.
- 지지도를 사용해서 불필요한 연산을 줄이기 위한 가지치기의 기준으로 사용된다.
- 지지도
신뢰도
- 조건부 확률로 항목집합 X를 포함하는 거래 중에서 Y를 포함하고 있는 거래 비율이다.
- 신뢰도가 높으면 연관성이 높다. 즉, 두 항목 X -> Y에서 항목 Y의 확률이 커야 연관규칙에 의미가 있다.
- 신뢰도
향상도
- 항목 X를 구매한 경우 그 거래가 항목 Y를 포함하는 경우와 항목 Y가 임의로 구매되는 경우의 비를 나타낸다.
- 항목 X와 Y는 독립적이지만 서로 상관성이 있는지 확인한다.
- 1보다 큰 값이어야 유용한 정보라고 할 수 있다.
- 향상도
| 향상도 | 내용 |
|---|---|
| 1 | 두 항목의 거래 발생이 독립적인 관계이다. |
| <1 | 두 항목의 거래 발생이 음의 상관관계이다. |
| >1 | 두 항목의 거래 발생이 양의 상관관계이다. |
연관규칙 분석을 위한 데이터 구조
-
연관규칙 분석을 위해서는 데이터를 트랜잭션 데이터로 변환하고 트랜잭션 데이터를 다시 동시발생 행렬로 변환하여 각 항목별로 빈도 수를 계산해야 한다.
-> 일반적인 데이터 -> 트랜잭션 데이터 -> 동시발생 행렬 -
일반적인 데이터
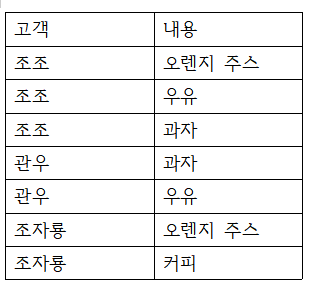
-
트랜잭션 데이터

-
동시발생 행렬

install.packages("arules")
library(arules)
m <- read.csv("C:\\Users\\km253\\OneDrive\\바탕 화면\\Rlanguae\\market.csv",
header = T ,encoding = "UTF-8")
m
m.list <- split(m$Item, m$ID)
m.trans <- as(m.list, "transactions")
m.trans
inspect(m.trans)
m_rule <- apriori(m.trans,
parameter = list(support=0.2,
confidence=0.20,
minlen=2))
m_rule
inspect(m_rule)
itemFrequencyPlot(m.trans,support=0.2,
main="연관규칙",
col="red")
#연관규칙 가시화
install.packages("arulesViz")
library(arulesViz)
plot(m_rule, method = "graph")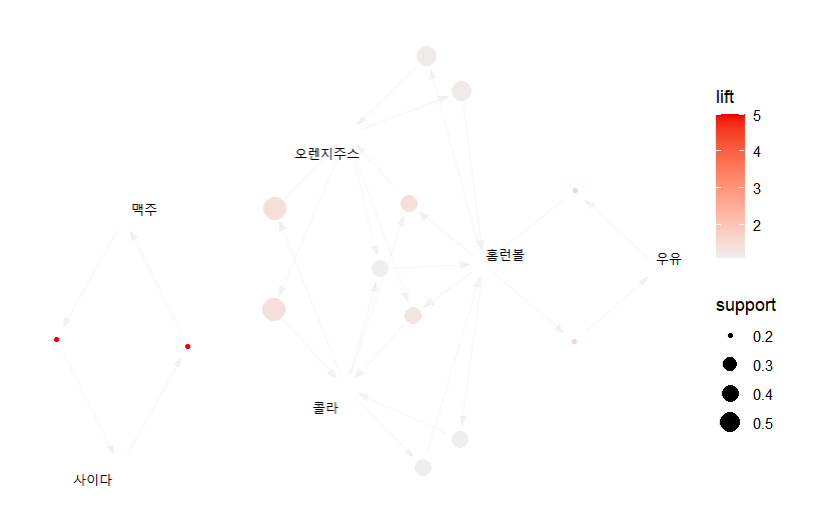
연관규칙 장단점
- 장점
- 연관규칙 분석의 결과에 대해서 이해가 쉽다.
- 분석이 간단하고 편리하다.
- 비목적성 분석기법이다.
- 단점
- 품목의 수가 증가하면 계산이 기하급수적으로 증가하기 때문에 속도가 느려진다.
- 거래량이 적은 품목은 연관규칙 분석에서 제외될 수가 있다.
- 품목이 너무 세분화 되면 의미 없는 분석결과가 나올 수 있다.
순차적 패턴분석
순차적 패턴분석
- 시간 및 순서에 따라 발생되는 연관성을 분석하는 방법으로 시퀀스를 이용해 순차적인 정보를 사용해서 분석한다.
- 순차 패턴분석을 위한 데이터 셋은 식별정보, 시간정보를 사용하고 평가척도는 지지도만 사용된다.
연관규칙 분석과 패턴분석
| 고객 | 연관규칙분석 | 순차적 패턴분석 |
|---|---|---|
| 분석관점 | 동시발생 사건 | 시간 및 순서에 따른 사건 |
| 데이터 | 거래 집합 셋 | 거래 집합 셋 식별정보, 타임스탬프 |
| 평가방법 | 지지도, 신뢰도, 향상도 | 지지도 |
순차 패턴 분석 알고리즘
| 알고리즘 | 내용 |
|---|---|
| 1단계 : 정렬단계 | 거래 데이터를 시퀀스 데이터로 변환한다. |
| 2단계 : 빈발항목 집합 | 지지도를 사용해서 빈발 항목 집합을 도출해야 한다. |
| 3단계 : 변환단계 | 고객 시퀸스를 빈발항목 집합을 사용해서 시퀀스로 변환해야 한다. |
| 4단계 : 시퀀스 단계 | 빈발 시퀀스를 도출한다. |
| 5단계 : 최대화 단계 | 빈발 시퀀스에서 최대 시퀀스를 탐색한다 |
텍스트마이닝
텍스트마이닝
- 텍스트마이닝은 자연어 처리 기술을 사용해서 문서의 어휘적, 문법적 특성을 분석하는 비정형 데이터 분석기법이다.
- 비정형 데이터를 사용해서 의미 있는 정보를 추출하는 것으로 각 정보와의 연계성을 분석한다.
문서분류
- 문서분류는 서지학의 한 부분으로 도서관 등에서 수많은 도서를 정해진 규칙에 의해서 분류하는 것이다.
- 방대한 양의 도서를 텍스트마이닝 기법을 사용해서 자동으로 분류한다.
문서분류(학습과정)
① 전처리
- 문서 내에 있는 오탈자를 교정하고 불용어 등을 제거한다.
- 문서특징 값을 추출하기 위해서 반드시 수행되어야 한다.
② 토큰화
- 토큰화는 문서를 분류하기 위해 수행되어야 하며 형태소 분석기를 사용해서 명사, 동사, 형용사 등을 추출한다.
- 분석하는 목적에 따라서 추출되는 형태서는 달라질 수가 있다.
③ 특징 값 추출
- 문서의 핵심단어를 식별하는 것으로 적은 수의 카테고리에 분포되고 카테고리 내에서는 빈번하게 출현해야 한다.
- 만약, 어떤 단어가 모든 카테고리에 분포되어 있다면 차별성이 없는 단어이다.
④ 분류
- 학습 알고리즘을 사용해서 문서를 분류한다.
문서군집
- 각 문서의 특징을 분석하여 각 문서 간에 관련성이 높은 것을 군집한다.
- 문서군집은 유사도를 계산하여 관련 있는 문서를 묶어주는 방법을 사용한다.
정보추출
- 비정형 문서로부터 중요 키워드, 핵심개념, 날짜, 상황, 지명, 인명 등의 정보를 추출하여 정보를 요약하여 새롭고 가치있는 정보를 제공한다.
- 시멘틱 웹과 온톨로지에서 사용되어 의미기반 검색을 제공한다.
문서요약
- 문서들의 특징을 분석하기 위해서 자동으로 문서정보를 요약한다.

AllTimeDevelop