
빅데이터의 수집
데이터 유형
데이터 유형
- 정형 데이터
- 관계형 데이터베이스의 고정된 필드에 저장한다.
- 데이터베이스 스키마를 지원한다.
- 데이터 종류(RDB, 스프레드시트)
- 반정형 데이터
- 데이터 속성인 메타데이터를 가지고 있으며 스토리지에 저장되는 데이터 파일이다.
- XML 형태의 데이터로 값과 형식이 일관성이 없다.
- 데이터 종류(HTML, XML, JSON, 웹페이지, 웹로그, 센서데이터)
- 비정형 데이터
- 언어분석이 가능한 데이터
- 형태와 구조가 복잡한 이미지, 동영상 같은 멀티미디어 데이터
- 데이터 형태(소셜 데이터, 문서, 이미지, 오디오, 비디오)
데이터 유형별 수집기술
- 정형 데이터
- ETL, FTP, Open API
- 반정형 데이터
- Crawling 크롤링, RSS, Open API, FTP
- 비정형 데이터
- 크롤링, RSS, Open API, FTP
데이터 수집기술
- Crawling, 크롤링
- 뉴스, SNS, 웹페이지 등의 인터넷 정보를 수집한다.
- 데이터 종류(웹 페이지)
- FTP
- 인터넷 프로토콜를 사용해서 파일을 다운로드 한다.
- sftp프로그램은 암호화하여 송수신한다.
- 데이터 종류(파일 수집)
- Open API
- SNS정보를 API를 사용해서 데이터를 수집한다.
- 데이터 종류(실시간 데이터)
- RSS
- XML 기반으로 뉴스, 블로그 등을 수집
- 데이터 종류(컨텐츠 수집)
- Streaming
- 음성, 오디오, 비디오 등의 멀티미디어 데이터를 실시간으로 수집한다.
- 데이터 종류(실시간 데이터)
- Log Aggregator, 로그 수집기
- 웹로그, 웹서버 로그, 트랜잭션 로그, 웹페이지 클릭로그, DB 로그 등을 수집
- 데이터 종류(로그수집)
- RDB Aggregator, RDB 수집기
- 관계형 데이터베이스에서 정형화된 데이터를 수집하여 분산파일시스템이나 HBase와 같은 NoSQL에 저장한다.
- RDB 기반 데이터 수집
데이터 종류
- 내부 데이터베이스 데이터
- 데이터베이스에 저장된 데이터
- 텍스트 데이터
- 워드, 엑셀, 아래한글 등
- SNS 데이터
- 페이스북, 트위터, 블로그 등에 있는 데이터를 API로 수집 가능
- 보통 JSON형태로 데이터를 제공
- 로그 데이터
- 서버, 네트워크, 웹 서버 등 자동으로 생성되는 로그파일 수집
- 센서 데이터
- IOT를 통한 센서 데이터
- 음성 데이터
- 사용자 음성 데이터는 아날로그 데이터로써 아날로그 데이터를 디지털로 변환하여 저장
- 음성은 Speech to Text, Text to Speech를 지원
- 이미지 데이터
- 이미지에서 픽셀을 추출하여 빅데이터 분석에 사용가능
데이터 속성 파악
- 관계형 데이터베이스 측면
- 문자, 문자열, 정수, 실수, 날짜 등
- 통계적 측면
- 질적변수와 양적변수 등이 있다.
- 경험적 측면
- 휴먼 빅데이터
- 사람의 행위에 대한 정보를 저장하고 있는 빅데이터
- ERP, SCM, MES, CRM, DW, VOC 등에 저장되어 있음
- 시스템 빅데이터
- 서버, 데이터베이스 로그, 보안장비 등과 같은 시스템 내부에 저장되는 빅데이터
- 소셜 빅데이터
- 웹 뉴스, SNS 등에서 수집되는 빅데이터
- 행태 및 상태 빅데이터
- 사람의 행위에서 발생하는 빅데이터로 스마트폰에서 발생하는 통화기록
- 휴먼 빅데이터
데이터 특성 파악
- JSON
- JSON 타입은 속성과 값의 표현식으로 사람과 기계 모두가 이해하기 쉬운 데이터 타입
- 최근 XML을 대체해서 데이터 전송에 많이 사용
- 키 : value 구조
- Open API
- 실시간 데이터 수집
- 누구나 인터넷에 있는 정보를 사용
- 표준화된 인터페이스를 사용해서 원하는 컨텐츠를 읽어올 수 있음
- RSS(Rich Site Summary 혹은 Really Simple Syndication)
- 뉴스 혹은 블로그에서 사용되는 컨텐츠 표현 방식으로 누구나 쉽게 컨텐츠 구독
- RSS는 새로운 뉴스 혹은 블로그에 새로운 글이 게시되면 자동 통보
- WSNs(Wireless Sensor Networks)
- 넓은 공간을 관측하기 위해서 수백에서 수천개의 센서를 배포하여 네트워크를 형성
- 환경, 군사, 국방, 보안, 교통 등의 관리를 하며 센서들의 데이터를 수집 및 분석
- 크롤링(Crawling, Web Scraping)
- 웹사이트를 방문하면서 원하는 정보를 스스로 추출하는 것을 의미한다.
- 크롤러는 웹사이트를 탐색해서 정보를 추출하는 컴퓨터 프로그램이다.
적합한 품질의 데이터 변환
데이터 변환 방법
표준화
표준화
- 평균을 중심으로 데이터가 어느 정도 떨어져 있는지를 구할 때 사용
- 값의 스케일이 다른 두 개의 변수가 있을 때 이 변수들의 스케일 차이를 제거
- Z-score 표준화 = (측정값 - 평균) / 표준편차
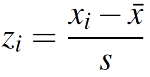
정규화
- 데이터를 0과 1로 변환하여 데이터 분포를 조정하는 방법
- (해당 값 - 최소값) / (최대값 - 최소값)
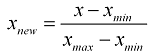
Z 변환
- 중심극한정리에 근거하여 표본을 추출하는 경우 표본은 정규분포에 근사하다고 가정
- Z 변환은 Z Table이라는 경험적 통계를 사용해서 평균을 중심으로 떨어져 있는 면적으로 구하는 것 가능
[0-1] 변환
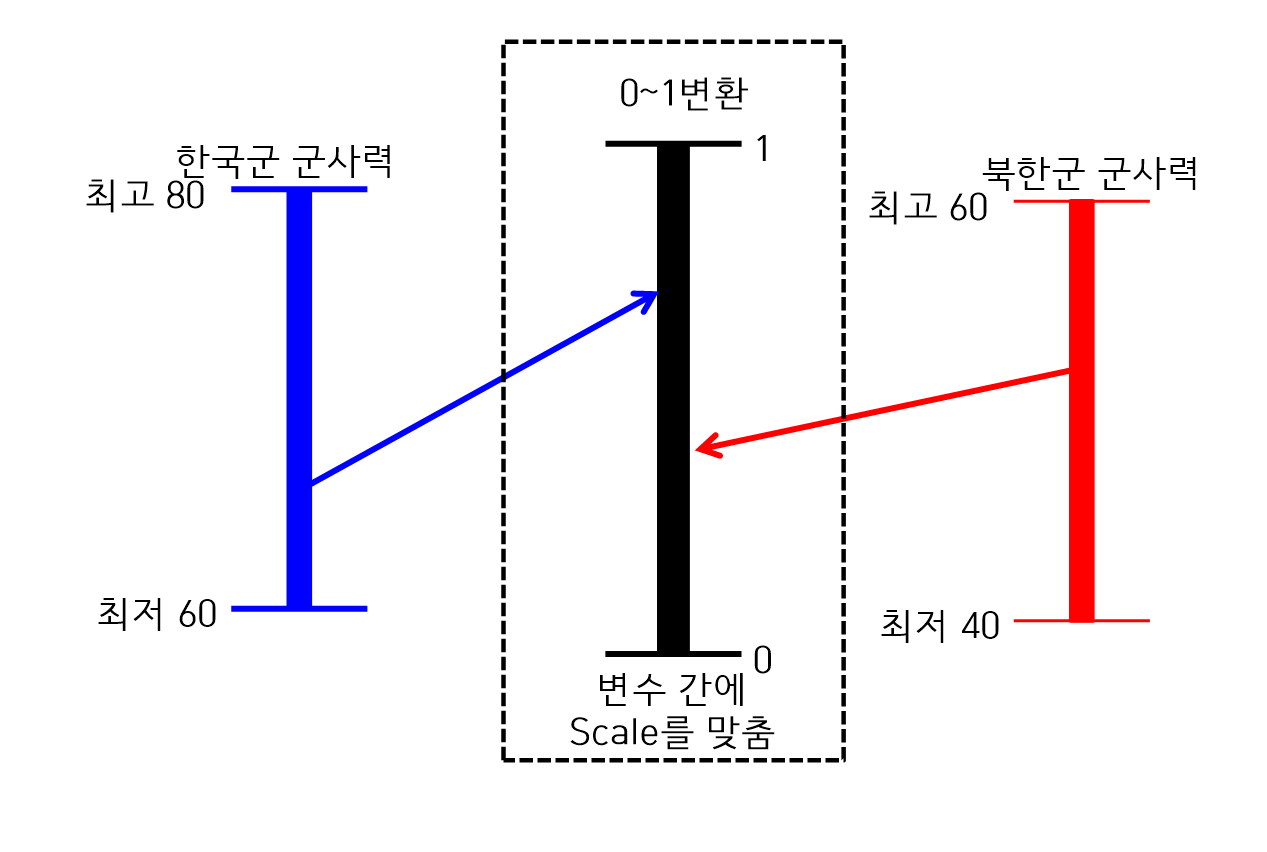
- [0-1]변환은 연속형 변수를 0 ~ 1사이의 값을 변환하는 것
- 변수들 간의 Scale이 다를 때 0 ~ 1사이의 값을 표준화한 후에 분석을 한다.
- x-min(x) / (max(x) - min(x))
정규분포화
로그변환
- 입력되는 데이터가 멱함수 분포를 나타내는 경우 log를 사용해서 정규분포로 변환한다.
- 멱함수 분포

제곱근 변환
- 정규분포가 아닌 데이터를 제곱근을 사용해서 정규분포 변환
- 로그변환과 제곱근 변환 중에서 정규분포를 가장 잘 나타내는 것으로 사용한다.
범주화
이산형화
- 범주형 변수를 특정 분석 데이터로 변환한다.
- 회귀분석을 할 때 범주형 변수를 가변수로 변환한여 분석 수행
- 이산화는 다수의 구간으로 연속형 변수를 범주화한다.
이항변수화
- 이항변수는 0과 1의 두개의 값을 가변환 한다
개수축소
데이터에서 확률표본 추출 기법을 사용해서 개수축소를 할 수 있다.
- 확률표본 추출 기법
- 단순 임의 추출
- simple random sampling
- 모집단에서 표본을 균등하게 임의로 추출
- 체계적 추출
- Systematic sampling
- 모집단에서 시간적, 공간적으로 간격을 두고 표본을 추출
- 층화 임의 추출
- Stratified random sampling
- 모집단을 몇 개로 분류하고 분류 내에서 임의추출
- 군집 추출
- Cluster sampling
- 모집단을 특정 군집으로 분류하고 군집 내의 모든 데이터를 표본으로 추출
- 다단계 추출
- Multi-stage sampling
- 표본을 추출할 때 단계를 나누어 표본을 추출하는 방법으로
예를 들어 1단계에서는 군집추출을 하고 2단계에서는 층화 임의 추출을 할 수가 있다.
- 단순 임의 추출
차원축소
요인분석
- 요인분석은 잠재된 요인을 분석하는 것으로 심리학에서 많이 사용
- 요인분석은 수많은 변수 중에서 잠재적인 몇 개의 요인을 찾는 방법으로 공통적인 요인을 찾아냄
- 잠재적인 요인을 찾기 때문에 여러 변수들을 하나로 축약시켜 새로운 변수가 생성되는 효과가 있다.
요인분석의 장점
- 변수의 특성 분석
- 입력 변수들 간의 상관관계를 파악하고 데이터 특성을 이해할 수 있다.
- 새로운 변수 생성
- 분석모델에 잠재적인 변수를 추출하여 새로운 변수를 생성하는 효과
- 데이터 축소
- 변수의 수를 줄일 수 있어서 분석결과에 대한 해석이 용이
- 다중공선성 문제
- 독립변수 간의 상관관계가 있는 다중공선성 문제는 잠재적 변수를 추가해서 해결가능
주성분분석
- 변수를 선택하거나 축소하는 방법
- 여러 변수들 간의 상관관계를 분석하여 소수의 주성분 혹은 요인을 차원을 축소
데이터 변환방법
- 평활화(smoothing)
- 데이터로부터 잡음을 제거하기 위해 추세에 벗어나는 값들을 변환
- 집계(Aggregation)
- 다양한 차원의 방법으로 데이터를 요약
- 일반화(Generalization)
- 특정 구간에 분포하는 값으로 스케일 변환
- 정규화(Normalization)
- 최소, 최대 정규화 및 z-스코어 정규화, 소수 스케일링 등 통계적 기법을 적용
- 속성 생성(Attribute construction)
- 데이터 통합을 위해서 새로운 속성이나 특징을 만든다.
- 여러 데이터 분포를 대표할 수 있는 새로운 속성과 특징 활용
시그널 데이터 변환
푸리에 변환
- 푸리에 변환은 시간에 따른 진폭 데이터를 주파수별 세기로 변환
웨이블릿 변환
- 푸리에 변환은 모든 주파수가 혼합되어 있는 형태로 나오는 문제가 있는데 이러한 문제를 해결한 것이 웨이블릿 변환임
- 작은 파를 패턴으로 하여 이것을 천이하거나 확대, 축소의 스케일을 사용해서 임의의 파형으로 표현한다.
데이터 변환 후 품질 검증
품질 검증이 모든 과정에서 이루어 진다.
- 빅데이터 수집단계 품질 확인사항
- 수집기준의 타당성이 확보되었는지 확인
- 데이터 추출 조건에 맞는 정보의 항목이 모두 추출됬는지 확인
- 악의적 유포 데이터 제거방법을 확보되었는지 확인
- 빅데이터 저장관리
- 누락된 데이터 확인
- 저장을 위한 key 구성의 적절성 평가
- 파일 검증
- 저장 Layout에 따른 검증
- 빅데이터 분석 활용
- 빅데이터의 데이터가 최신성을 유지하고 있는지 확인
- 데이터 분석을 위한 충분한 정보 제공됬는지 확인
- 사용자가 원하는 정보가 제공되는지 확인
- 빅데이터 품질관리 확인 방법
- 내부 사용자 설문조사
- 피드백
- 만족도 조사
- 사후 고객 만족도 분석
빅데이터의 정제
데이터 정제 절차
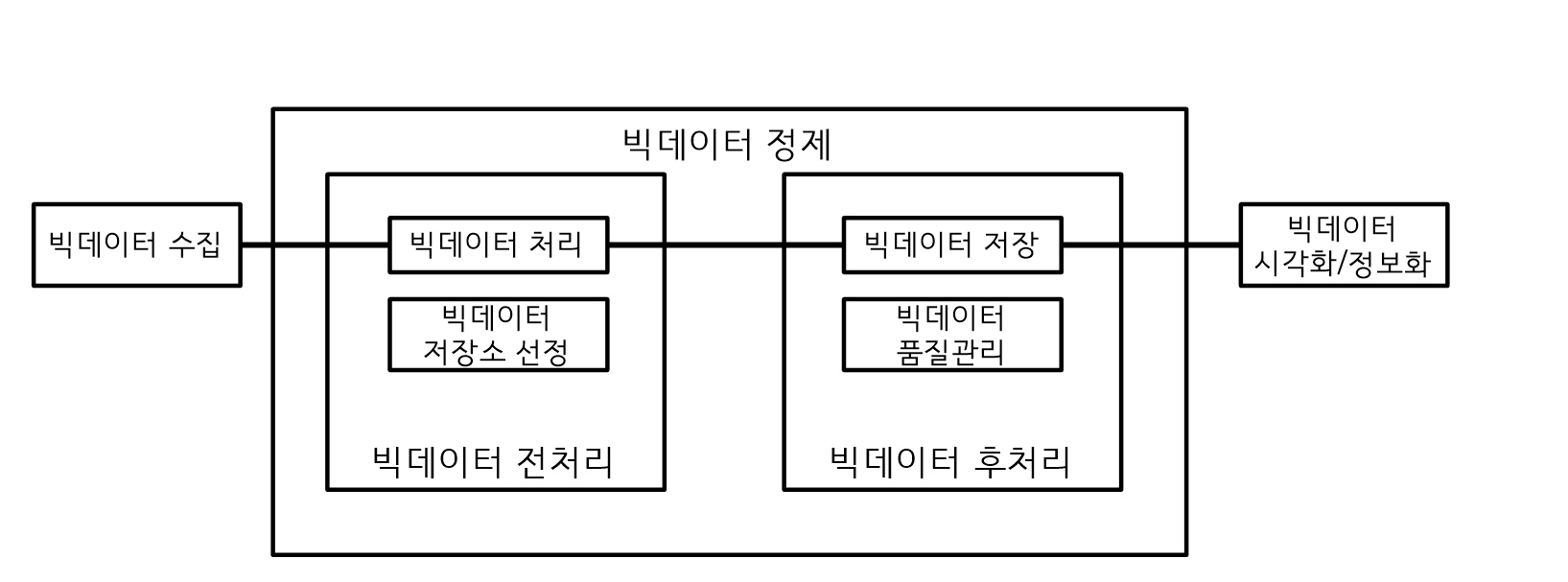
빅데이터 정제 절차
- 빅데이터 분석은 수집된 데이터에 대해서 데이터 정제를 수행한다.
- 정제를 수행하지 않으면 데이터 일관성, 무결성에 문제가 발생한다.
빅데이터 전처리
- 빅데이터 전처리 과정은 구조화 되지 않은 비정형 데이터를 분석 가능한 구조적 형태로 교정하는 단계
전처리 관정
- 데이터 변환
- 데이터 유형을 변환하거나 분석이 용이한 형태로 변환
- 데이터 교정
- 이상치를 제거, 노이즈 데이터를 교정
- 비정형 데이터 수집 시 반드시 교정을 시행
- 데이터 통합
- 유사 데이터 연계 및 통합
- 레거시 시스템과 함께 분석 시 데이터 통합을 수행
전처리 기술
- 데이터 여과
- 오류 발견, 보정, 삭제, 중복확인 등 과정을 거쳐 품질 향상
- 데이터 변환
- 유형 변환하거나 분석이 용이한 형태로 변환
- 정규화, 집합화, 요약화, 계층생성 등의 방법을 사용
- ETL 도구가 제공
- 데이터 정제
- 결측치에 데이터 삽입 및 이상치 식별 혹은 제거, 잡음의 평활화를 통해 불일치성을 교정
- 데이터 통합
- 분석에 용이하도록 유사 데이터 통합
- 데이터 축소
- 분석에 활용되지 않는 데이터 제거
빅데이터 후처리
- 빅데이터 처리 과정을 확보된 데이터를 저장하고 지속적인 품질관리 활동을 수행하는 것을 빅데이터 후처리라고 한다.
- 정제된 데이터를 데이터의 유형, 크기 등을 고려 빅데이터 저장소 용량을 산정하고 저장
- 저장 후에 집계, 일반화, 정규화를 수행하여 데이터 일관성을 향상 시킨다.
저장방식
- RDB
- 관계형 데이터베이스에 저장하므로 SQL을 사용해서 쉽고 편리하게 관리할 수 있다.
- Oracle, MySQL
- NoSQL
- key-Value, Document Key-Value, Column 기반으로 사용
- 몽고DB, HBase, Redis, Cassandra
- 분석 파일 시스템
- 분산 서버를 사용해서 여러 서버에 분산하여 저장
- 대규모 저장소를 제공하고 성능 향상
- 하둡
데이터 정제 기술
결측지 처리 방법 : 해당 레코드 무시, 자동 채우기, 수작업 입력
- 해당 레코드 무시
- 데이터 분류에서 각 클래스의 라벨 구분이 없는 경우 해당 레코드를 무시한다.
- 해당 레코드 무시는 결측지가 자주 발생하는 환경에서 매우 비효율적
- 자동 채우기
- 결측지 값을 특정 값으로 입력
- 전체 평균값, 중앙값, 해당 클래스와 같은 레코드에 속한 데이터의 평균값으로 입력
- 담당자에 의한 수작업 입력
- 담당자가 데이터를 확인하고 적절한 값으로 수정
- 많은 시간이 걸리지만 높은 신뢰성
데이터 정제 방법(잡음처리)
데이터 정제 방법 : 구간화, 회귀값 적용, 군집화
- 구간화
- 데이터를 정렬한 후 여러개의 구간으로 나누고 구간에 있는 값들을 대표값으로 대체
- 데이터 잡음을 제거하고 축약하는 효과
- 구간화에 사용되는 대표값은 평균값, 중앙값 등이 있다.
- 회귀값 적용
- 데이터를 잘 표현하는 추세함수를 찾아 이 함수 값을 적용
- 군집화
- 비슷한 성격을 가지고 있는 클러스터 단위로 군집한 후 극단치를 제거

AllTimeDevelop