
스케일링하기
각 칼럼에 있는 데이터의 상대적 크기에 따라 분석 결과와 모델링 결과가 달라질 수 있으므로 수치형 데이터의 경우 상대적 크기 차이를 제거해야하는데 이를 스케일링이라고 한다.
정규화하기
min-max Scaling은 데이터의 범위를 0~1사이로 변환하여 데이터 분포를 조정하는 가장 일반적인 정규화 방법이다.
정규화의 공식은 다음과 값다.
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding='cp949')
df.drop('Unnamed: 0', axis=1, inplace=True)
df_num = df[['duration', 'days_left', 'price']]
# 정규화 공식 적용
df_num = ((df_num - df_num.min()) / (df_num.max() - df_num.min()))
df_num.describe()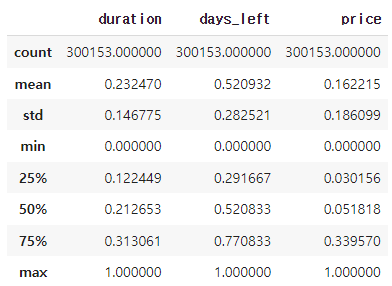
3개의 값 모두 min이 0, max가 1인 값으로 정규화되었다. min-max scaling은 극단적인 이상치에 민감하여 유의하여 이상치 처리 뒤 사용해야 한다.
표준화하기
수치형 데이터를 평균이 0이고 표준편차가 1인 표준 정규분포로 변환하는 것으로 수식은 다음과 같다.
# 표준화
df_num = (df_num - df_num.mean()) / df_num.std()
df_num.describe()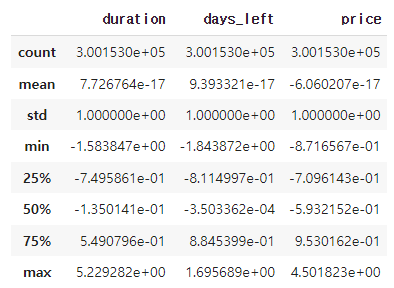
표준화된 값을 칼럼에 붙이면 다음과 같다.
df.drop(['duration','days_left', 'price'], axis=1, inplace=True)
#표준화된 값을 넣어주기
df = pd.concat([df, df_num], axis = 1)
df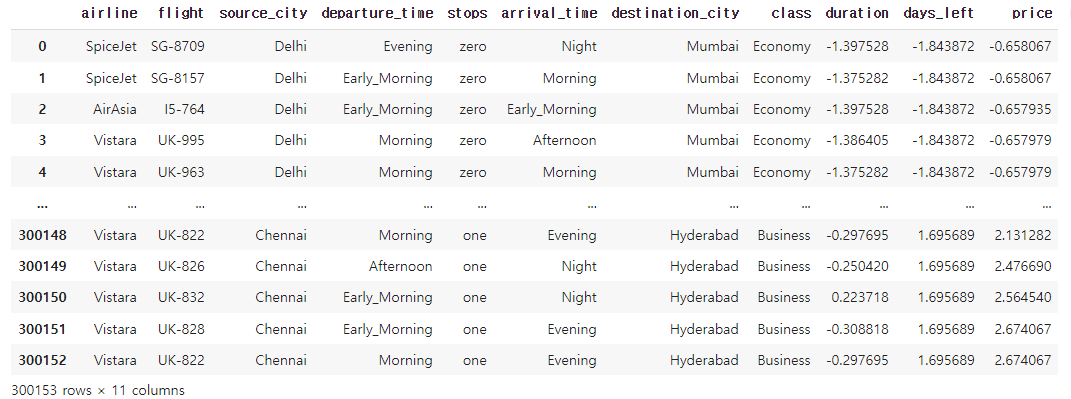
변수 선택하기
신규 변수 생성하기
하나의 데이터로 여러 개의 새로운 칼럼 만들기
lambda를 활용하면 이름이 없는 함수로 간결해지고 메모리를 절약하는 효과도 있어 재사용 가능성이 없는 함수를 만들 때 사용한다.
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding='cp949')
df.drop('Unnamed: 0', axis=1, inplace=True)
def split_flight(flight) :
manufacture = flight.split('-')[0]
model = flight.split('-')[1]
return manufacture, model
df['manufacture'], df['model_num'] = zip(*df['flight'].apply(lambda x : split_flight(x)))
df[['manufacture','model_num']]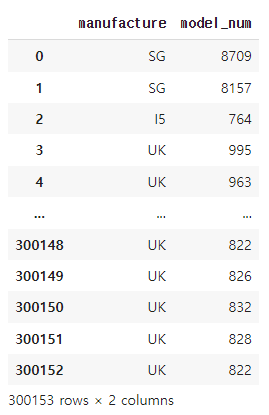
여러 개의 데이터로 하나의 새로운 칼럼 만들기
lambda 함수와 apply 함수를 이용하면 여러 개의 데이터로 새로운 하나의 새로운 칼럼을 만들 수 있다.
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding='cp949')
df.drop('Unnamed: 0', axis=1, inplace=True)
df['rotue'] = df.apply(lambda x : (x['source_city']+'에서 '+ x['destination_city']), axis = 1)
df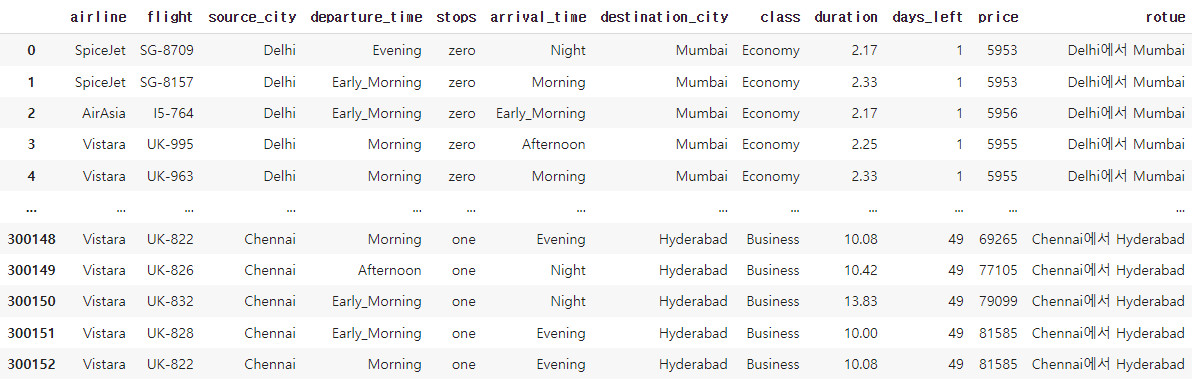

AllTimeDevelop