딥러닝 AI모델링
컴퓨터가 인간의 두뇌를 모방하면 예측결과가 좋아지지 않을까 하는 가설에 탄생하였다.
두뇌에 존재하는 시냅스와 시냅스간의 연결 동작을 모방하여 인공신경망 학습체계를 만들었는데 이를 딥러닝이라고 한다.
시냅스와 인공신경망
시냅스의 수상돌기 부분에서 정보의 입력을 받아 축삭돌기를 통해 축삭말단에서 정보를 전달한다.
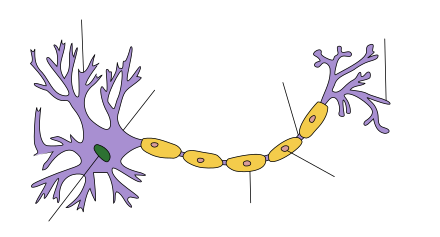
이 매커니즘을 모방하여 입력 - 학습 - 출력의 매커니즘을 가진 인공신경망이 만들어졌다.
인간이 경험을 통해서 정보(지식)을 가지고 향후 행동에 대한 예측을 하는데 인공신경망도 마찬가지로 이미 답이 있는 정보, 데이터를 가지고 학습이 이루어지고 학습에 따라 예측결과를 출력한다.
인간과 달리 인공신경망의 학습 단계는 가중치와 편향의 가중합과 활성화 함수를 통해 가중치를 줄여나가는 방식으로 학습을 이루게 된다.
출력의 결과는 정해진 값이 아니라 확률적인 값으로 가장 높은 확률의 답을 얻기 위해서는 데이터 전처리와 적절한 학습모델(활성화 함수)와 손실함수를 선택하여야 한다.
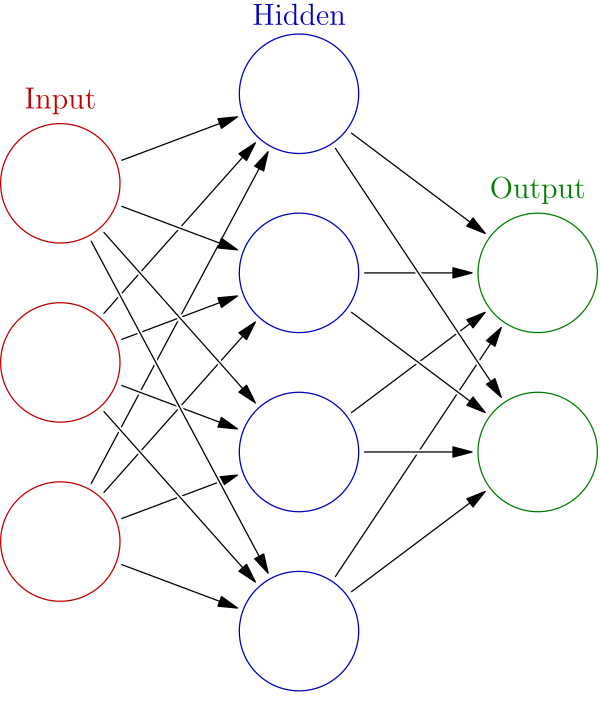
가중치와 편향, 활성화 함수가 존재하는 곳을 은닉층이라고 하며 은닉층이 깊어질 수록 데이터 자체로 알지 못한 높은 수준의 특징과 패턴을 찾아낼 수 있다.
활성화 함수
시그모이드
분류모델로 많이 사용되는 시그모이드함수는 0에서 1 사이의 값을 변화시킨다. 이 함수를 이용하면 기울기 소실 문제가 발생하여 모델 학습이 제대로 이뤄지지 않을 수 있다.
하이퍼볼릭 탄젠트
시그모이드 활성화 함수의 한계점을 개선한 방법 중 하나로 하이퍼볼릭 탄젠트 함수가 제안되었다. -1 에서 1사이의 값을 출력하며 미분값이 시그모이드 함수에 비해 커졌다. 하지만 하이퍼볼릭 탄젠트 함수도 x값이 크거나 작아짐에 따라 기울기가 매우 작아져서 기울기 소실 문제가 발생한다.
렐루 (ReLU)
시그모이드와 하이퍼볼릭 탄젠트 활성화 함수들의 기울기소실 문제를 개선한 함수로 입력값이 양수일 때 출력은 입력값 x와 같고, 음수일때 출력은 0이다.
특별한 연산이 없으므로 연산 속도가 빠르다.
정리
인공신경망을 사용하기 위해서는 출력값들에 대한 가중치와 편향이 있어야 되며 이러한 가중치와 편향을 활성화 함수로 일정 기준에 따라 변환하여 값을 출력한다. 인공신경망의 학습을 위해서는 실제값과 예측값의 차이를 계산해야되는데 이러한 함수를 손실함수라고 하며
손실함수에는 평균제곱오차, 평균절대오차, 바이너리-크로스엔트로피가 있다. 인공신경망은 역전파알고리즘을 통해 가중치를 최소화하는 과정을 거치며 경사하강법을 통해 최소의 가중치를 찾고 최소의 가중치를 가지는 결과를 출력한다.
이런 과정들은 텐서플로와 케라스 라이브러리를 통해 쉽게 인공신경망 학습을 할 수 있다.
코드
#설치된 텐서플로 버전 확인하기
import tensorflow as tf
print(tf.__version__)
#필요한 라이브러리 불러오기
import numpy as np
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
#모델 학습 데이터 생성
x = [1,2,3,4,5,6,7,8,9,10]
y = [3,5,7,9,11,13,15,17,19,21]
x_train = np.array(x)
x_train = x_train.reshape(-1,1)
y_train = np.array(y)
# 입력 데이터와 출력데이터로 지도학습을 시킬 준비다.
# print(f'입력 데이터 : {x_train}')
# print(f'입력 데이터 형태 : {x_train.shape}')
# print(f'출력 데이터 : {y_train}')
# print(f'출력 데이터 형태 : {y_train.shape}')
#Keras의 Sequential 모델 구성하기
initializer = tf.keras.initializers.GlorotUniform(seed=42) # 모델 시드 고정하기
model = Sequential()
# 은닉층 추가하기 , 여기에 활성화 함수를 넣는다.
model.add(Dense(units=1, input_shape=(1,), kernel_initializer = initializer))
model.summary()
# 모델을 학습시킬 최적화 방법, loss 계산 방법, 평가 방법 설정하기
model.compile(optimizer = 'sgd', loss = 'mse', metrics=['mae'])
# 모델 학습하기
model.fit(x_train, y_train, epochs=1000)
# 학습이 완료된 모델 사용 예측
print(model.predict([[11],[12],[13]]))실제 데이터로 AI학습하기
from tensorflow.python.framework.type_spec import Sequence
#필요한 라이브러리 불러오기
import numpy as np
import pandas as pd
import warnings
#심층신경망 모델 생성
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Dropout
#from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.models import Sequential
from tensorflow.keras.callbacks import EarlyStopping
import random
#경고 메시지를 무시
warnings.filterwarnings('ignore')
#csv파일에서 데이터를 로드해서 데이터프레임으로 저장
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/invistico_Airline.csv')
#결측지 확인
df.isnull().sum()
#데이터 전처리하기
#결측지 전처리
#SimppleImputer 객체로 결측지 대체
from sklearn.impute import SimpleImputer
#평균값으로 대체
mean_imputer = SimpleImputer(strategy = 'mean')
df['Arrival Delay in Minutes'] = mean_imputer.fit_transform(df[["Arrival Delay in Minutes"]])
#데이터 인코딩하기
#object 칼럼 유형 string 유형으로 변경하기
cols = ['satisfaction', 'Customer Type', 'Type of Travel', 'Class']
df[cols] = df[cols].astype(str)
#범주형 데이터를 수치값으로 변경
df['satisfaction'].replace(['dissatisfied','satisfied'], [0,1], inplace=True)
#순서형 인코딩하기
categories = pd.Categorical(
df['Class'],
categories = ['Eco','Eco Plus','Business'],
ordered=True
)
labels, unique = pd.factorize(categories, sort = True)
df['Class'] = labels
#원핫 인코딩하기
cat_cols = ['Customer Type', 'Type of Travel']
df = pd.get_dummies(df, columns=cat_cols)
df.info()
# 데이터세트 분리하기
# 데이터세트를 입력과 레이블로 분리하고, 훈련 데이터세트와 검증 데이터세트로 분리한다.
from sklearn.model_selection import train_test_split
#데이터 세트를 입력x와 레이블y로 분리하기
x = df.drop(['satisfaction'], axis = 1)
y = df['satisfaction'].reset_index(drop=True)
#데이터세트를 훈련 데이터와 검증 데이터로 분리하기
x_train, x_val, y_train, y_val = train_test_split(x,y,test_size=0.2,
random_state=42,
stratify=y)
#데이터 스케일링하기
#데이터 정규화
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(x_train)
X_train = scaler.transform(x_train)
X_val = scaler.transform(x_val)
#모델
#모델 시드 고정
tf.random.set_seed(42)
np.random.seed(42)
random.seed(42)
#Keras의 Sequential 객체로 딥러닝 모델 구성
initializer = tf.keras.initializers.GlorotUniform(seed=42)
model = Sequential()
#훈련 데이터가 23개이므로 입력데이도 23개가 되어야한다.
model.add(Dense(32,activation='relu', input_shape=(23,),
kernel_initializer = initializer))
model.add(Dense(64, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
print(f'훈련 데이터 세트 크기 : X_trian{X_train.shape}, y_train {y_train.shape}' )
print(f'훈련 데이터 세트 크기 : X_val{X_val.shape}, y_val {y_val.shape}' )

#모델을 학습시킬 최적화 방법, loss함수, 평가방법설정
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
#모델 학습
es = EarlyStopping(monitor='val_loss', min_delta=0,patience = 10, verbose=1,restore_best_weights=True)
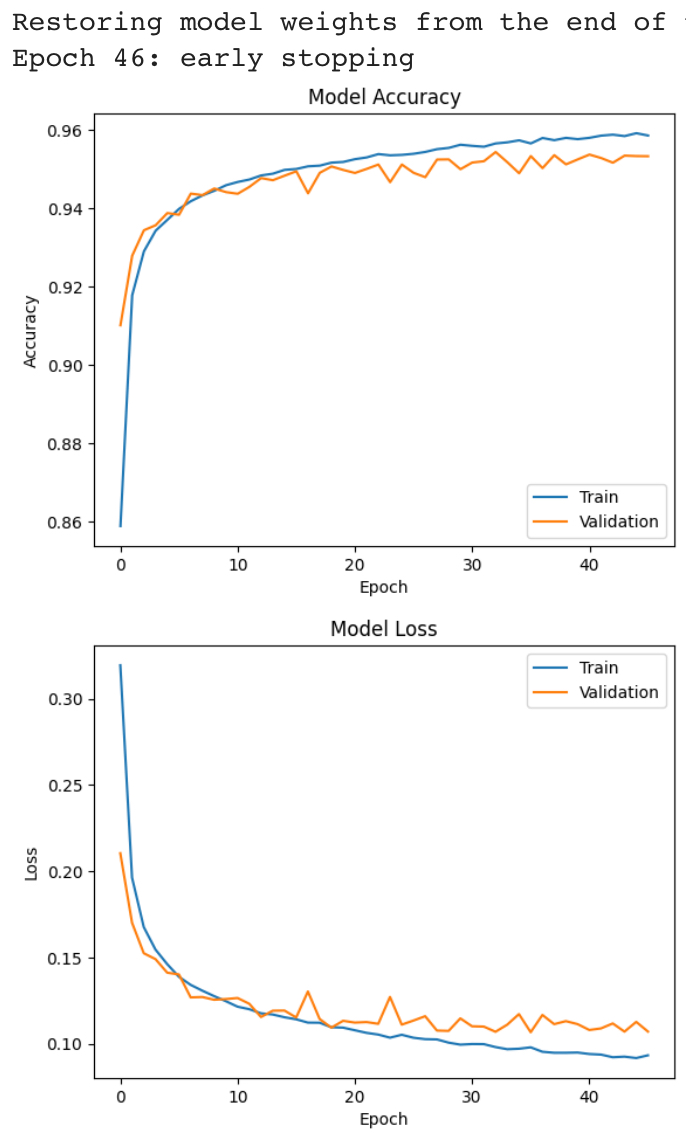
history = model.fit(X_train, y_train, epochs=100, batch_size=128, verbose=0, validation_data=(X_val, y_val), callbacks=[es])
#모델훈련 과정 시각화하기
import matplotlib.pyplot as plt
#훈련과정 정확도 시각화
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(['Train','Validation'],loc='lower right')
plt.show()
#훈련 과정 손실 시각화
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(['Train','Validation'],loc='upper right')
plt.show()