
랜덤 포레스트
랜덤포레스트란?
의사결정나무를 다수로 학습시켜 그 결과를 종합하는 배깅 기반의 앙상블 알고리즘이다.
데이터 준비
구글의 텐서플로를 활용하여 데이터를 준비
from tensorflow.keras.datasets.mnist import load_data
# load_data로 데이터 할당하기
(x_train, y_train), (x_test, y_test) = load_data()
#손 글씨 데이터는 이미지라 3차원 행렬
print("변경 전 = ", x_train.shape)
#3차원 행렬을 2차원으로 변경하기
X_train = x_train.reshape(-1, 784)
X_test = x_test.reshape(-1, 784)
#변경결과확인
print("변경 후 = ", X_train.shape)의사결정나무 모델링하기
# 의러결정나무, 랜덤 포레스트 라이브러리
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
#의사결정나무 학습하기
dct = DecisionTreeClassifier(random_state = 0)
dct.fit(X_train, y_train)
#의사결정나무 결과 확인
acc_train_dct = dct.score(X_train, y_train)
acc_test_dct = dct.score(X_test, y_test)
print(f'''학습결과 = {acc_train_dct}, 검증결과 = {acc_test_dct}''')
랜덤포레스트 모델링 및 결과 비교
#랜덤 포레스트 학습하기
rfc = RandomForestClassifier(random_state=0)
rfc.fit(X_train, y_train)
#랜덤 포레스트 결과 보기
acc_train_rfc = rfc.score(X_train, y_train)
acc_test_rfc = rfc.score(X_test, y_test)
#학습결과 수치 출력
print(f'''의사결정나무 : train_acc = {round(acc_train_dct,3)}, test_acc={round(acc_test_dct,3)}''')
print(f'''의사결정나무 : train_acc = {round(acc_train_rfc,3)}, test_acc={round(acc_test_rfc,3)}''')
#랜덤 포레스트 결과를 토대로 비교 그래프 그리기
import matplotlib.pyplot as plt
#x축 정의하기
acc_list_x = ['dct_train','dct_test','rfc_train','rfc_test']
#y축 정의하기
acc_list_y = ['acc_train_dct','acc_test_dct','acc_train_rfc','acc_test_rfc']
colors = ['orange','orange','blue','blue']
#막대그래프 설정하기
plt.bar(acc_list_x, acc_list_y,color=colors)
#화면 출력하기
plt.show()
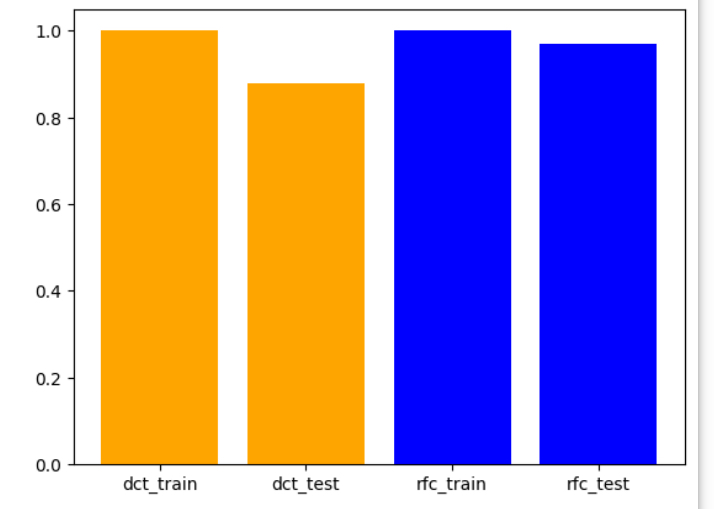
의사결정나무와 랜덤 포레스트 2가지 모델을 이용하여 결과를 비교해보면 상대적으로 랜덤 포레스트가 의사결정나무보다 시험 데이터 세트에 대한 정확도가 높은 것을 확인 할 수 있다.
훈련 데이터세트의 정확도도 중요하지만 훈련데이터의 정확도가 일정 수준 이상이라면 시험 데이터세트의 정확도가 더 중요하다.

AllTimeDevelop