
의사결정 나무
의사결정나무란?
트리 기반 모델로써 Feature를 조건 기반으로 참 거짓으로 나눠 마치 스무고개를 하듯이 학습을 이어나가는 것을 말한다. 선형성이 없기에 수학적 가정이 불필요하며 범주와 연속형 수치 모두 예측 가능하다.
단, 과대적합 발생 확률이 높고 트리 구조로 인한 선형성이 떨어진다.
의사결정나무 실습
의사결정나무는 과대적합이 발생하기 쉬움으로 하이퍼파라미터를 통해 과대적합을 예방해야되며 하이퍼파라미터는 다음과 같다.
하이퍼파라미터
# max_depth : 깊어질 수 있는 최대 깊이, 괒대적합 방지용 # max_features : 최대로 사용할 feature의 갯수, 과대적합 방지 # min_samples_split :지트리의 노드가 가지고 있는 최소한의 샘플 수, 과대적합 방지
데이터 준비
#라이브러리 불러오기
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
#데이터 불러오기
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/국민건강보험공단_건강검진정보_20211229.CSV', encoding='cp949')
#트리 예시를 만들기 위해 일부 특성만 추출
sample_df = df[['신장(5Cm단위)','성별코드','체중(5Kg 단위)','음주여부']]
#sample_df
데이터 전처리
#info정보를 통한 결측지 확인
print('Info 정보 확인')
sample_df.info()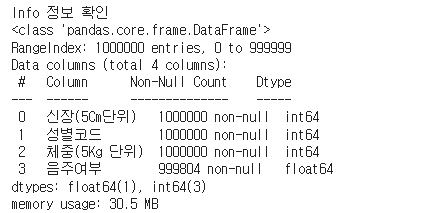
약 100만 건의 데이터 중 음주여부 칼럼에 결측치가 일부 존재하여 196건의 데이터를 drop처리하여 최종 학습 데이터로 준비하고, Label데이터에 편향이 심하지 않은지 불균형 여부도 확인한다.
#결측차가 포함된 칼럼 삭제하기
sample = sample_df.dropna()
#결측지 다시 확인하기
print('Drop 후 Info 정보 확인')
sample.info()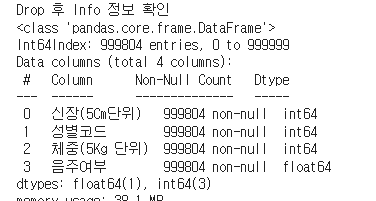
#원핫 인코딩을위해 데이터 object 형태로 변경하기
sample = sample.astype('str')
#label(결과, Y)생성
y = sample.음주여부
#음주여부 학습 데이터 구성하기(음주여부 제외한 데이터)
X = sample.drop('음주여부', axis = 1)
# label 데이터의 편향성 확인하기(1.0는 음주, 0.0은 음주x)
y.value_counts()
#학습/검증 데이터 분리하기
x_train, x_vaild, y_train, y_vaild = train_test_split(X, y, test_size=0.2, shuffle=True, random_state=34)의사결정나무 모델링
모델링을 위해서 사이킷런의 DecisionTreeClassifier 모델을 활용합니다.
# 의사결정나무 모델링하기
#의사결정나무 모델 불러오기
from sklearn.tree import DecisionTreeClassifier
#의사결정나무 모델 생성하기
dt = DecisionTreeClassifier(random_state=1001, max_depth=2)
#의사결정나무 학습하기
dt_model = dt.fit(x_train, y_train)
#학습 데이터 정확도 확인하기
print('학습 정확도 : ', dt_model.score(x_train, y_train))
#검증 데이터 정확도 확인하기
print('검증 정확도 : ', dt_model.score(x_vaild, y_vaild))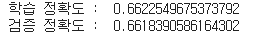
의사결정나무 그래프 그리기
그래프는 graphviz라이브러리를 활요하여 학습된 의사결정나무 모델의 그래프를 출력한다.
#그래프그리기
import matplotlib.pyplot as plt
#트리모양 그래프 작성을 위한 라이브러리 설치하기
#!pip install graphviz
#그래프 라이브러리 불러오기
import graphviz
#사이킷런의 graphvizs 지원 모듈 불러오기
from sklearn.tree import export_graphviz
#그래프 생성하기
tree_graph = graphviz.Source(export_graphviz(dt_model, class_names=['X','O'], feature_names=['height', 'sex', 'weight'], impurity=True, filled=True))
tree_graph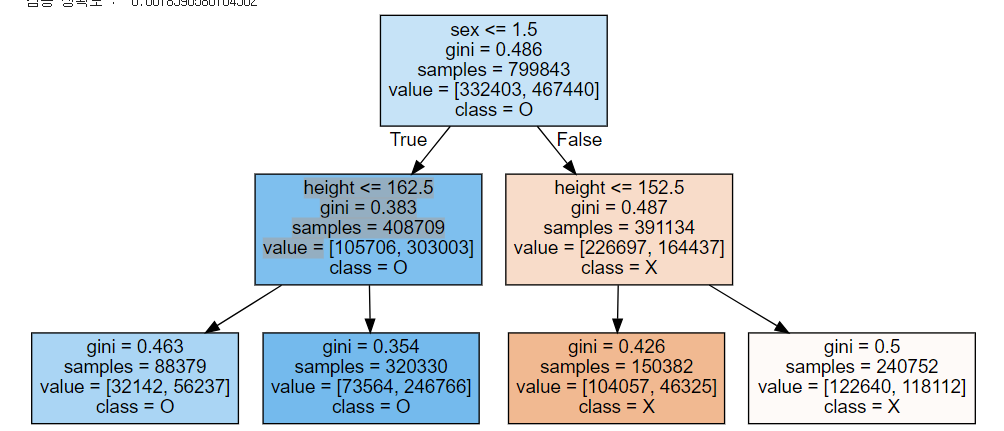
각 노드 안에는 분할조건, 지니계수, 입력된 샘플의 수, 각 value 별 count 등이 있다. 노드에 분할 조건이 없으면 리프 노드라고 한다.
불순도 알아보기
불순도란 데이터가 섞여있는 정도를 말한다. 의사결정나무 노드에 의해 출력된 데이터 레이블의 불순도를 줄이는 방향으로 노드를 분할해 나간다. 이러한 불순도를 측정하는 대표적인 지표로 지니계수가 있다. 지니계수는 불순도를 측정하는 지표로서, 데이터의 통계적인 분산의 정도를 정량화해서 표현한다.
#불순도 함수 생성하기
def gini(x):
n = x.sum()
gini_sum = 0
for key in x.keys():
gini_sum = gini_sum + (x[key] / n) * (x[key] / n)
gini = 1 - gini_sum
return gini
# 데이터 준비하기(불순도 예시)
과일바구니1 = ['사과'] * 9
과일바구니2 = ['사과', '바나나', '사과', '바나나', '바나나', '바나나', '복숭아', '복숭아', '복숭아']
과일바구니3 = ['사과', '바나나', '사과', '바나나', '사과', '복숭아', '복숭아','사과','복숭아']
print(round(gini(pd.DataFrame(과일바구니1).value_counts()),3))
print(round(gini(pd.DataFrame(과일바구니2).value_counts()),3))
print(round(gini(pd.DataFrame(과일바구니3).value_counts()),3))
AllTimeDevelop