모수란?
- 통계적 모델링은 적절한 가정위에서 확률분포를 추정하는것이 목표이고, 머신러닝과 통계학이 공통으로 추구하는 목표이다.
- 그러나 유한한 데이터로 모집단의 분포를 정확하게 알아내는것은 불가능하므로 근사적으로 추정 할 수 밖에 없다.
- 데이터가 특정 확률분포를 따른다고 선험적(a priori)으로 가정한 후 그분포를 결정하는 모수를 추정하는 방법을 모수적(parametric) 방법론이라고 한다.(모수란 모집단 전체를 설명하는 측도를 의미한다. 예를 들어, 정규분포에서는 평균, 분산이 모수가 될 수 있다.)
- 반면에 특정 확률분포를 가정하지 않고 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌면 비모수방법론이라고 부른다.(비모수방법론은 모수가 없는 것이 아니라 모수가 무한히 많거나 모수의 개수가 데이터에 따라 바뀌는경우를 의미한다. )
- 대부분의 기계학습의 방법론은 비모수방법론에 속한다.
확률분포 가정
- 데이터가 2개의 값(0 또는 1)만 가지는 경우 → 베르누이분포로 가정
- 데이터가 n개의 이산적인 값을 가지는 경우 → 카테고리분포나 다항 분포로 가정.
- 데이터가 [0,1] 사이에서 값을 가지는 경우 → 베타분포로 가정
- 데이터가 0 이상의 값을 가지는 경우 → 감마분포, 로그 정규분포 등으로 가정
- 데이터가 RR 전체에서 값을 가지는 경우 → 정규분포, 라플라스 분포 등으로 가정
데이터로 모수 추정하기
- 데이터의 확률분포를 가정했다면 모수를 추정해볼 수 있습니다. 정규분포의 모수는 평균 과 분산 으로 이를 추정하는 통계량(statistic)은 다음과 같다.
표본평균 :
표본분산:
- 위의 식을 설명하면, 표본평균들의 평균은 모집단의 평균과 일치하고 표본 분산들의 평균은 모집단의 분산과 일치하게 된다는 것을 표현한 식이다. 이때, 표본 분산을 구할 때 이 아니라 로 나누는 이유는 불편(unbiased) 추정량으로 만들어 주기 위해 사용합니다. 불편 추정량은 추정량의 기댓값이 모수와 같을 때의 추정량을 말한다. 그러므로 위에서 봤을 때, 표본 분산들의 평균은 모집단의 분산과 일치하지 않기 때문에 불편 추정량이 아니게 되고, 이를 같아지게 만들어주기 위해서 이 아닌 로 나눠주는 것이다.
- 통계량의 확률분포를 표집분포(sampling distribution)라 부르며, 특히 표본 평균의 표집 분포는 이 커질수록 정규분포 를 따릅니다. 이를 중심 극한 정리(Central Limit Theorem)이라 부르며, 모집단의 분포가 정규분포를 따르지 않아도 성립한다. 여기서 말하는 표집 분포(sampling distribution)는 표본 평균들의 확률분포를 이야기하는 것으로 중심 극한 정리가 적용되지만 표본의 분포는 정규분포를 따르지 않을 수도 있다는 차이를 구분해야 합니다.
최대가능도 추정법
- 표본평균이나 표본 분산은 중요한 통계량이지만 확률분포마다 사용하는 모수가 다르므로 적절한 통계량이 달라지게 됩니다. (단순히, 표본 평균과 표본 분산만 가지고 확률분포를 추정하는 것은 위험합니다.)
- 모수를 이론적으로 가장 가능성이 높은 모수를 추정하는 방법 중 하나는 최대 가능도 추정법(maximum likelihood estimation, MLE)입니다.
여기서 argmax f(x)는 f의 최대값을 만들어주는 x값을 의미한다.
- 데이터집합 X가 독립적으로 추출되었을 경우 로그가능도를 최적화한다.
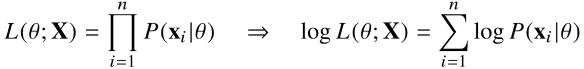
그러면 왜 로그가능도를 사용할까?
- 로그가능도를 최적화하는 모수 는 가능도를 최적화하는 MLE가 된다.
- 데이터의 숫자가 적으면 상관없지만 만일 데이터의 숫자가 수억 단위가 된다면 컴퓨터의 정확도로는 가능도를 계산하는 것은 불가능하다.
- 데이터가 독립일 경우, 로그를 사용하면 가능도의 곱셈을 로그가능도의 덧셈으로 바꿀 수 있기 때문에 컴퓨터로 연산이 가능해진다.
- 경사하강법으로 가능도를 최적화할 때 미분 연산을 사용하게 되는데, 로그가능도를 사용하면 연산량을 에서 으로 줄여준다.
- 대게의 손실 함수의 경우 경사 하강법을 사용하므로 목적식을 최소화하게 됩니다. 보통 로그 가능도의 경우에는 maximum을 찾아야 하기 때문에 이것을 최소로 만들어주는 음의 로그 가능도(negative log-likelihood)를 최적화하게 된다.

Naver Boostcamp AI Tech 3기🎈⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ㅤㅤ⠀⠀ㅤㅤㅤㅤㅤㅤㅤㅤ2022 데이터분석 청년수련생