
디스크 읽기 방식
랜덤 I/O와 순차 I/O가 존재합니다.
"어떻게 DISK I/O를 줄일까?"가 관건일때가 상당히 많습니다.
HDD와 SSD
CPU나 메모리 같은 주요장치는 대부분 전자식 장치지만 보조기억장치의 HDD는 기계식 장치입니다.
하지만 같은 보조기억장치의 SSD는 원판을 제거하고 플레시 메모리를 장착해
물리적으로 원판을 회전시키지 않아 아주 빠릅니다.
속도 : DRAM > SSD > HDD
-
한번에 많은 양을 읽는 순차 I/O는 HDD와 SSD가 비슷한 성능을 보이나
랜덤 I/O의 경우 SSD가 성능이 더 좋습니다. -
디스크에 데이터를 쓰고 읽는 것에 걸리는 시간은 헤더를
움직여서 읽고 쓸 위치로 옮기는 단계에서 결정
즉 디스크 헤더의 위치 이동없이 얼마나 많은 데이터를 한번에 기록하느냐가 관건 -
쿼리를 튜닝해서 랜덤I/O를 순차I/O로 변경시키는 방법은 별로 없습니다.
일반적으로 쿼리를 튜닝하는 것은 랜덤I/O자체를 줄이는 것이 목적
정확히는 쿼리를 처리하는데 꼭 필요한 데이터만 읽도록 개선하는 것이 목적
B-TREE
1. MyISAM과 InnoDB의 차이
MyISAM과 InnoDB는 데이터 파일의 정렬에서 많은 차이를 보입니다.
MyISAM 테이블의 레코드는 프라이머리 키의 값과 무관하게 Insert되는 순서대로 저장되며 모든 레코드는 RowID라는 물리적 주소를 가지며 인덱스 테이블에서는 해당값을 참조합니다.
하지만 InnoDB는 데이터 파일이 클러스터되어 저장되므로(클러스터링 테이블) 프라이머리 키 순서로 저장됩니다.
(클러스터링 : 비슷한 값을 최대한 모아서 저장하는 방식)
인덱스 테이블에서 실제 데이터를 참조할 때
MyISAM은 인덱스 테이블에서 RowID를 참조하며
InnoDB는 MyISAM처럼 데이터를 바로 참조하지 못하며 루트 노드에서 부터 리프 노드로 이동하여 리프 노드의 데이터를 읽습니다.
결국 InnoDB는 세컨더리 인덱스를 사용한다고 하여도 무조건 데이터 파일의
B+-Tree 형식으로 구조화된 자료구조(클러스터링 테이블)를 사용하게 됩니다.
Clustring은 인덱스 군집에 관한 것입니다.
해당내용에 대하여는 추후에 다시 알아보겠습니다.
2. 다시 B-Tree
InnoDB B+-Tree
https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/
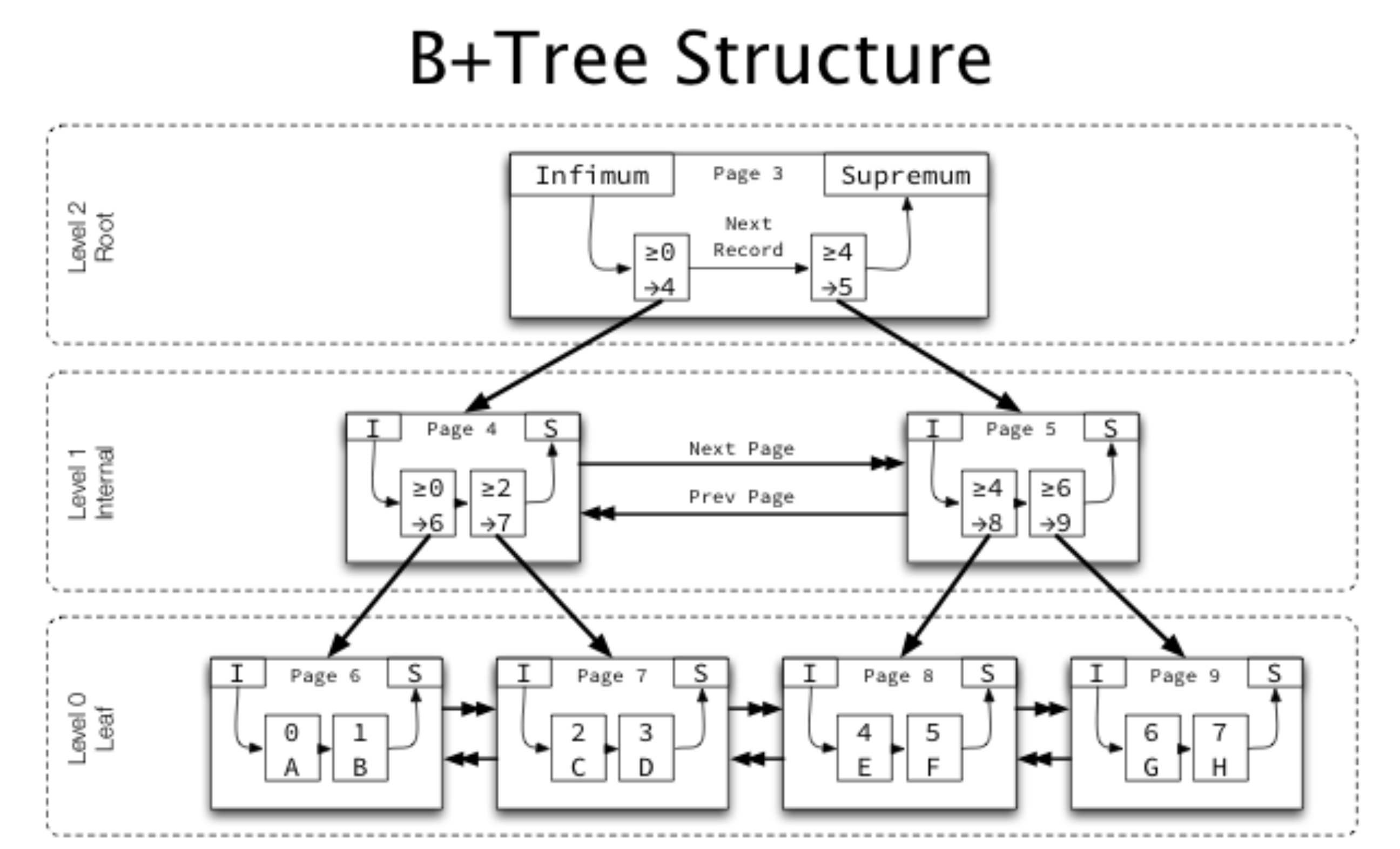
- 가장 일반적인 인덱싱 알고리즘
- 전문 검색과 같은 특수한 요건이 아닌 경우, 대부분 B-Tree를 사용
루트 노드, 브랜치 노드, 리프 노드로 이루어집니다.
데이터의 주솟값은 항상 리프 노드에 존재하며 항상 정렬되며 균형이 맞는 형태로 유지됩니다.
Index를 논외로 정렬이 되며 균형이 유지되는 Tree형식의 자료구조는 insert, delete에서 노드들의 순서를 재정의 할 수 있습니다.
그리고 데이터 파일의 레코드는 항상 정렬되어 있지 않고 임의의 순서로 저장되어 있습니다.
왜냐하면 중간중간 레코드가 변경되거나 삭제되기 때문입니다.
B-Tree에 키 추가나 삭제가 어떻게 처리되는지 알아두면 도움이 됩니다.
- 인덱스 키 추가
새로운 키 값이 B-Tree에 추가될 때 Storage Engine에 따라 새로운 키 값이 즉시 인덱스에 저장이 안 될수도 있습니다.
InnoDB의 경우 세컨더리 키의 경우 추가의 지연이 가능하나 Primary Key, Unique Key같은 경우는 중복 확인을 위해 바로 처리되어야 합니다.
- 인덱스 키 변경
기존 인덱스 키 값을 삭제한 후 키 값을 추가하는 절차로 진행, InnoDB의 경우 체인지 버퍼를 활용해 지연처리 합니다.
- 인덱스 키 검색
CUD의 추가적인 비용을 감당하면서도 B-TREE를 사용하는 이유는 빠른 검색을 위해서입니다.
검색은 100% 일치 또는 값의 앞부분만 일치하는 경우에 사용할 수 있습니다.
부등호 비교조건에서도 활용할 수 있지만 인덱스를 구성하는 키 값의 뒷부분만 검색의 용도로 사용할 수 없습니다.
인덱스를 사용하여 조회시 넥스트 키락이나 갭락으로 레코드를 잠급니다.
스캔범위를 잘못 지정하면 과도하게 락이 걸리는 위험이 존재합니다.
