low-level mechanism (context switch)은 알게되었고.
좀더 high-level의 OS scheduling policies에 대해서 알아보자
Workload Assumption
Wokrload란 실행중인 프로세스에 대한 가정이다.
아래의 가정들을 할 것이다.
- 각각의 프로세스는 같은 시간동안 동작한다.
- 모든 프로세스는 같은 시간에 시스템에 도착한다. (시스템에 도달하는데 걸리는 시간이 모두 0이다)
- 프로세스가 한번 시작하면 각 프로세스는 완료될 때 까지 동작한다.
- 모든 프로세스는 CPU만 사용한다.
- 각 프로세스의 run-time을 알고있다.
Scheduling Metrics
Workload에 대한 가정 이외에도 scheduling metric을 이용해서 scheduling policies를 비교할 수 있다.
여러가지 metric이 있겠지만 turnaroun time(프로세스 완료까지 걸리는 시간)만을 사용할 것이다.
FIFO
First In First Out의 약자로써 단순해서 이해가 쉬운 정책이다.
먼저 도착하면 먼저 실행된다는 개념이다.

위와같은 상황에서 평균 turnaround time은 20초다.

하지만 위와같은 상황에서는 평균 turnaround time은 110초로 상당히 길다. B, C는 실행 시간은 짧지만 대기시간이 너무 길다는 단점이 있다.
Shortest Job First
이름 그대로 실행시간이 짧은 프로세스부터 먼저 실행하겠다는 것이다.
우리의 가정들로 봤을 때 시스템에 모두 동시에 프로세스가 안착하고, 실행시간도 알고있으므로 최적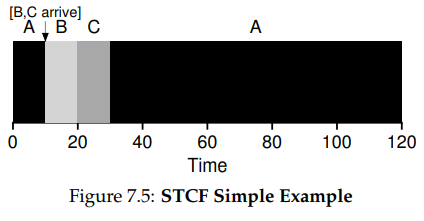 의 scheduling policy이다.
의 scheduling policy이다.
하지만 실제는 이렇지 않으므로 이상적인 이야기에 불과하다.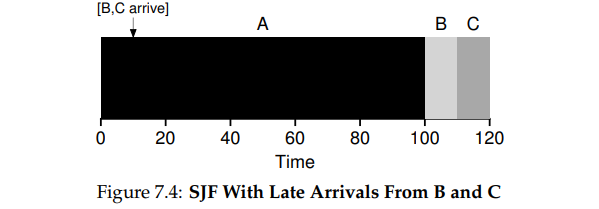
실제로 A가 0초에 시스템에 도착해서 실행되고, B,C는 시스템에 도착하기까지 10초가 걸린다면 실제 실행결과는 위와같게된다.
Shortest Time-To-Completeion First
이 방법은 프로세스를 실행할 때 preempt(선점)하는 방식으로 진행된다. 위에서 한 가정 3을 조금 변경하여 프로세스가 끝까지 진행되는 것이 아니라 앞서 배운 timer interrupt처럼 동작되는 것이다.
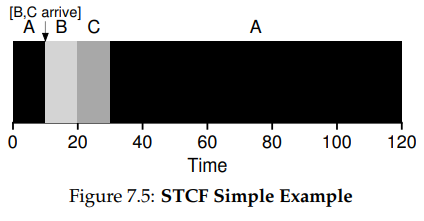
위의 그림처럼 A라는 프로세스를 선점하고 새로운 B, C프로세스가 시스템에 도착했을 때 종료되는 시간이 더 짧으면 A를 멈추고 B, C 즉, 더 짧게 걸리는 프로세스를 먼저 실행한다.
Response Time
과거의 일괄처리 시스템(batch computing system)에서는 STCF가 적합했다.
하지만 Time-shared machine이 도입되면서 상황이 바뀌었다.
이제 User는 터미널을 통해서 컴퓨터 시스템과 상호작용하게되었기 때문에 response time이라는 metric이 새롭게 필요해졌다.
response time은 프로세스가 시스템에 도달하는데 걸리는 시간이다.
터미널을 열고, 명령어를 입력하고 10초 뒤에나 시스템으로부터 response가 온다면 생각만해도 끔찍하다..
따라서 response time에 민감한 scheduler가 필요해졌다.
Round Robin
round robin은 프로세스를 잘게 쪼개서 실행한다(time slice, scheduling quantum).
A,B,C라는 프로세스가 있고 5초동안 진행된다고 할 때 RR은 1초단위로 time slicing해서 평균 response time은 1이다. 하지만 SJF인 경우 평균 response time은 5가된다.
RR에서는 time slicing을 하기 때문에 몇번이나 time slincing을 하는지가 매우 중요하다.
time slice를 많이 할 수록 response time에 대한 performance가 좋아지지만,
너무 많다면 모든 resorce의 performance가 context swtiching에 집중되는 문제가 있다.

turnaround time을 생각하면 RR은 딱히 좋지않다.
위의 그림에서 볼 수 있듯이 평균 turnaround time은 무려 14초이다.
일반적으로 time slicing을 통해서 CPU을 fair하게 나누는 policy들은 turnaround time을 생각했을 땐 성능이 좋지않다.
이처럼 turnaround time과 response time은 trade-off 관계에 있다.
Incorporating I/O
모든 프로그램은 I/O를 수행할 수 있다.
프로그램이 I/O request를 수행하면 CPU를 사용하지 않는 block상태에 있기 때문에 schedler가 그동안 다른 프로세스를 CPU에 할당할 필요가 있다.
그 후 I/O가 끝나면 다시 scheduler가 block상태에서 ready상태로 프로세스를 바꿔주어야 한다.
예를들어 50ms동안 실행되는 프로세스 A, B가 있다. A는 10ms 동안 I/O request를 수행하고 B는 I/O없이 실행된다.
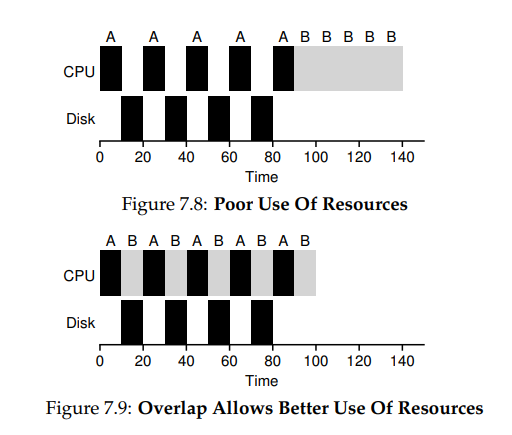
A를 실행할 때 I/O를 독립적으로 처리하고, 그 사이에 B를 선점하여 실행시키는 Overlap방식을 활용해서 효율적으로 프로세스를 운용할 수 있다.
No More Oracle
가장 처음에 한 가정중 가장 말도 안되는 가정은 5번째에 해당하는 프로세스의 실행시간(run-time)을 알 수 있다는 항목이다.
그렇다면 이런 가정없이 어떤 정책을 어떻게 써야할까...?
Multi-Level Feedback Queue
Multi-Level Feedback Queue로 해결할 문제는 2가지이다.
- turnaround time을 최적화하고자 한다.
하지만 우리는 프로그램이 얼마동안 실행될지 알 수 없다. - response time을 최소화하고자 한다.
하지만 response time을 최소화할 수 있는 RR같은 경우 turnaround time은 최악이다.
Basic Rule
MLFQ는 우선 순위를 갖는 여러개의 queue를 갖고있다.
특정한 시간에 어떤 하나의 queue에는 실행 준비가 완료된 프로세스가 있다.
그래서 MLFQ는 우선순위를 고려하여 그 시간에 어떤 프로세스를 실행해야할지 결정할 수 있다.
같은 우선순위를 갖는 프로세스가 동시에 큐에 존재할 수 있기 때문에 이 경우에는 Round Robin 방법을 통해서 프로세스를 실행한다.
MLFQ sheduling의 핵심은 우선순위를 어떻게 두는가에 달려있다.
Observed behavior에 기반하여 우선순위를 매긴다.
예를들어 키보드 입력을 기다리느라 반복적으로 CPU 에 대한 control을 양보하는 프로세스는 우선순위가 높고, 오랫동안 CPU 이용률이 높은 프로세스는 우선순위가 낮다.
왜냐하면 이러한 방식이 대화형 프로세스가 동작하는 방식이기 때문이다.
How To Change Priority
우리는 CPU control을 자주 양보하는 short-running 프로세스와 CPU control을 오랫동안 갖고있는 longer-running 프로세스 모두를 다뤄야 한다.
아래는 우선순위 적용 알고리즘의 규칙이다.
- 프로세스가 시스템에 도착하면 가장 높은 우선순위를 부여한다.
- 프로세스가 실행되는 동안 모든 작업에 대해time slice가 이루어진다면 우선순위를 하나 낮춘다.
- time slice가 끝나기 전에 CPU control을 양도한다면 같은 우선순위를 유지한다.
A Single Long-Running Job
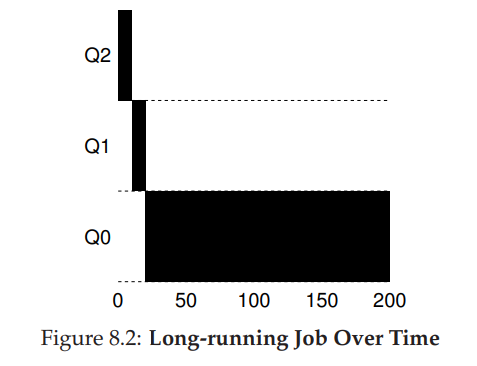
위의 그림에서 볼 수 있듯이 하나의 Long-Running Process가 있을 경우 처음에 Q2에 위치하고 time slice를 한 이후에 우선순위를 하나씩 내린다.
Along Came A Short Job
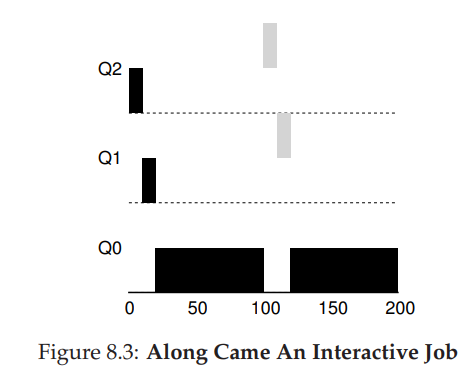
검은색인 A는 long-running process, 회색인 B는 short-running process이다.
A는 실행이후 Q2, Q1을 거쳐 가장 낮은 우선순위인 Q0에서 실행되고 있고, t=100일 때 B가 최상위 우선순위에 도착해서 실행된다.
이 알고리즘에서 우리가 알아야할 것은 처음에 시스템에 들어오는 프로세스가 short-running process인지 long-running process인지 알 수 없기 때문에 short-running process라고 가정하고 높은 우선순위를 부여하는 것이다.
만약 실제로 short-running process라면 실행되고 빠르게 종료될 것이고 아니라면 time slice를 통해서 queue의 아래로 점점 내려갈 것이다. 그래서 MLFQ가 SJF로 근사될 수 있게된다.
Problem With Our Current MLFQ
이제 기본적인 MLFQ에 대해서는 알게되었는데 현재 MLFQ에는 큰 문제가 있다.
- Starvation에 관한 문제이다. 너무 많은 interative한 작업이 계속된다면 long-running process는 절대 CPU control을 가질 수 없다.
- Gaming the scheduler에 대한 문제이다.
똑똑한 프로그래머는 time slicing이 끝나기 전에 I/O를 요청해서 계속해서 프로세스가 우선순위의 상단에 위치하게 할 수 있다. (rule 3을 악용하는 경우이다.)
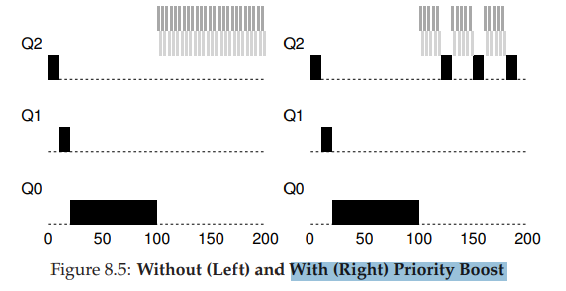
1번 문제에 대한 해결을 어떻게 할 수 있을까?
Priority Boost라고 하는 방법인데
- 주기적인 시간마다 모든 process의 우선순위를 최상단으로 높여주는 방법이다.
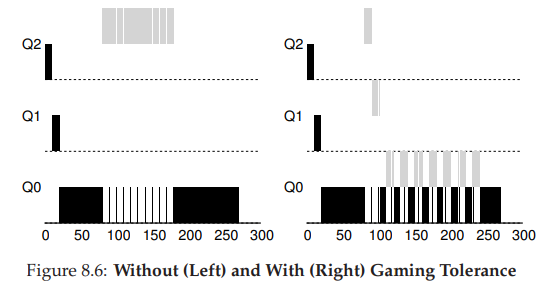
그렇다면 2번 문제에 대한 해결은 어떻게 할 수 있을까?
Better Accounting이라고 부르는 방법을 활용한다.
- process가 해당 queue에서 할당된 시간을 다 활용했다면 강제로 priority를 낮춘다.
Tuning MLFQ And Other Issues
몇가지 MLFQ에 대한 질문들이 남아있다.
- sheduler의 parameter는 어떻게 할 것인가?
- 몇개의 queue가 필요한가?
- queue당 time slice는 몇번을 해야하는가?
- priority boost는 얼마나 자주 일어나야 하는가?
무엇하나 쉬운 질문이 없다.
3에 대한 예를 들면 여러가지 queue에서는 여러가지 time slice length가 활용된다.
priority가 높은 queue에서는 interative한 작업이 주로 이루어지므로 short time slice를 하고, priority가 낮은 queue에서는 long-running process가 주로 동작하므로 long time slice가 적합하다.
운영체제마다 어떠한 규칙을 적용시킬 것인가에 대한 내용이 모두 다르다.
출처 : OSTEP
