운영체제
1.프로세스
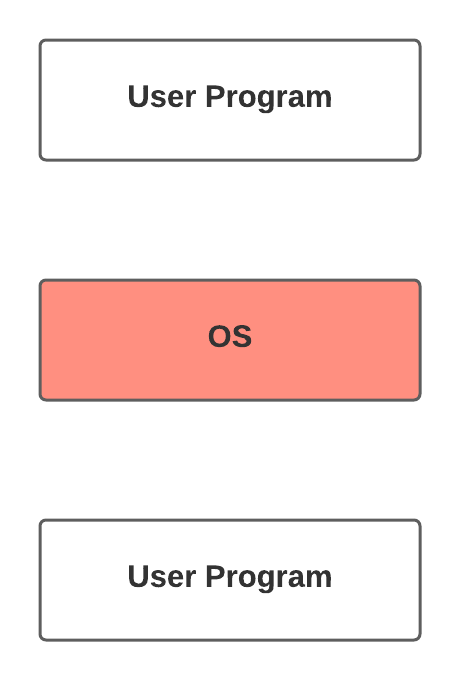
OSTEP을 공부하는 내용입니다.운영체제란 하드웨어와 유저 프로그램의 중간층에 위치한다.이 운영체제가 하드웨어를 관리한다. CPU, memory, IO devices(disk, network card, mouse, keyborad...)프로그램을 컴퓨터에서 실행할 때
2.Limited Direct Execution

OS는 동시에 진행되는 것 처럼 보이는 프로세스들을 하나의 물리적인 CPU에서 공유해야 한다.time sharing을 통해서 이러한 가상화를 달성 할 수 있다.하지만 2가지 중요한 쟁점이 남아있다.추가적인 시스템의 overhead없이 어떻게 가상화를 달성할 것인가?CP
3.CPU Scheduling
low-level mechanism (context switch)은 알게되었고.좀더 high-level의 OS scheduling policies에 대해서 알아보자Wokrload란 실행중인 프로세스에 대한 가정이다.아래의 가정들을 할 것이다.각각의 프로세스는 같은 시간
4.Scheduling: Proportional Share
이번에는 Proportional-share 또는 fair-share sheduler라고 알려진 scheduler에 대해서 알아볼 것이다.Proportional-share scheduler는 turnaround time, response time을 최적화하는 것이 아닌
5.Multiprocessor Scheduling

작성 예정
6.Interlude: Memory API
메모리 사용이 다 끝나지 않았는데 해제를 해버린 경우를 일컬어 dangling pointer라고 부른다.어떤 짧은 프로그램을 작성하고, 메모리 할당을 한 후 종료전에 해제를 해야하는가?해제를 안하는 것이 이상하겠지만, 해제를 하지 않아도 실제로는 메모리 누수가 없다.그
7.Address Translation
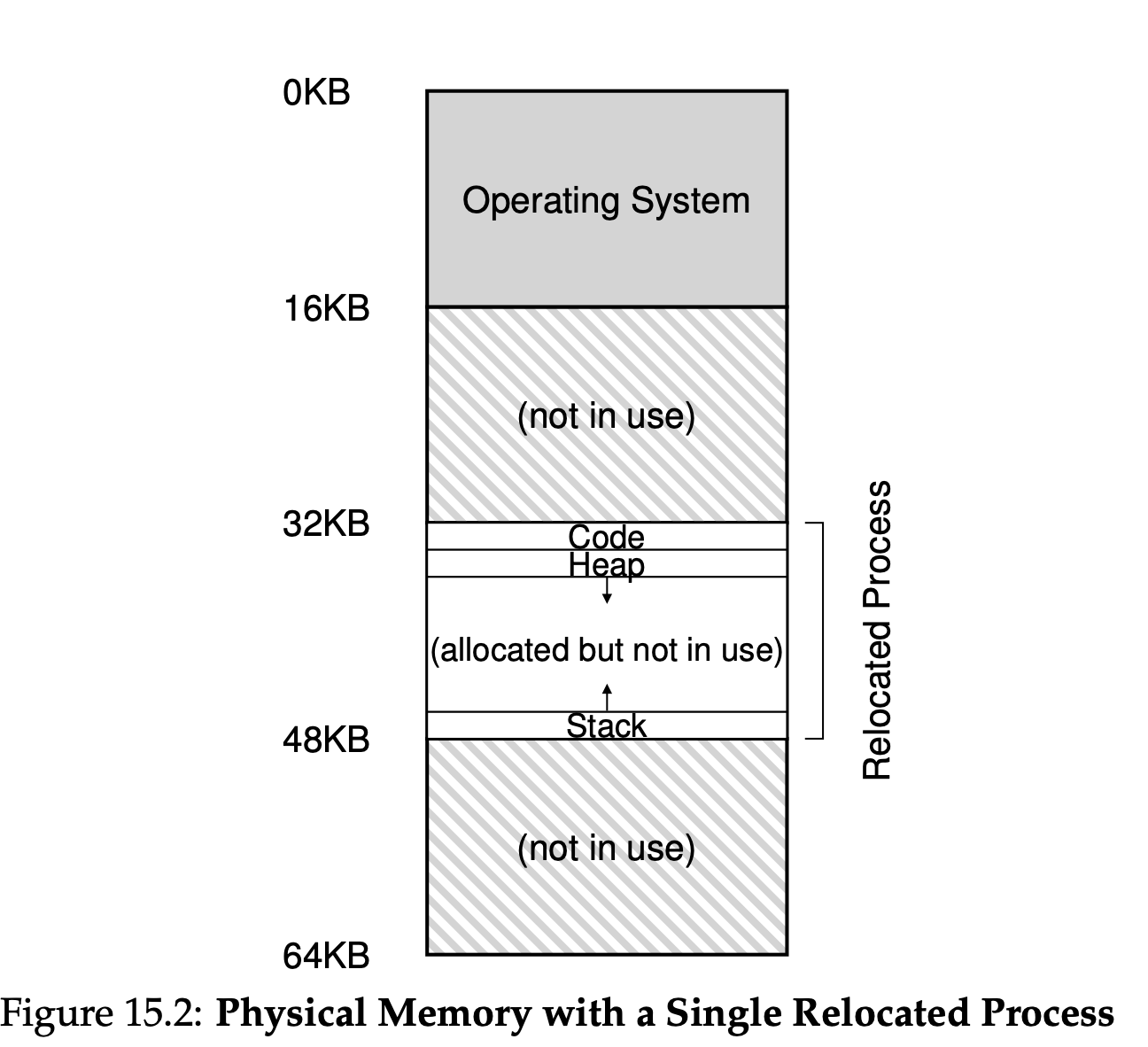
CPU를 가상화 하기위해서는 Limited Direct Execution을 활용했다. 메모리 가상화를 제공할 때도 효율성과 통제권(Efficiency and Control)을 얻기위해서 비슷한 방법이 필요하다. 효율성을 위해서는 분명히 하드웨어가 뒷받침되어야 하고,
8.Segmentation
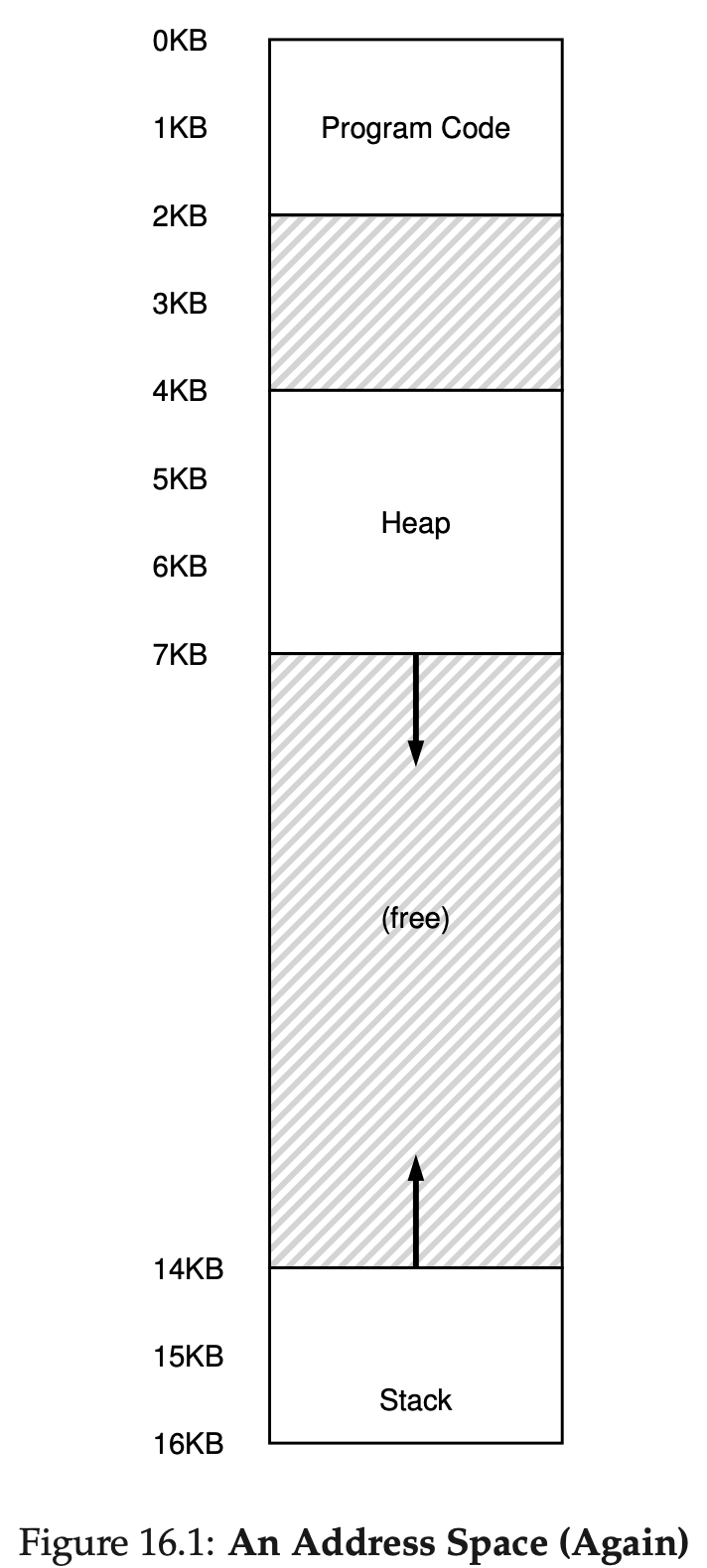
위 그림에서 보면 알 수 있듯이 address space를 구성할 때 실제 물리적 메모리에는 free space가 있기 때문에 base and bound 방법은 우리가 생각하는 것 만큼 유용하지 않을 수 있다.이러한 문제를 해결하기 위해 segmentation이라는 방
9.Free-space Management
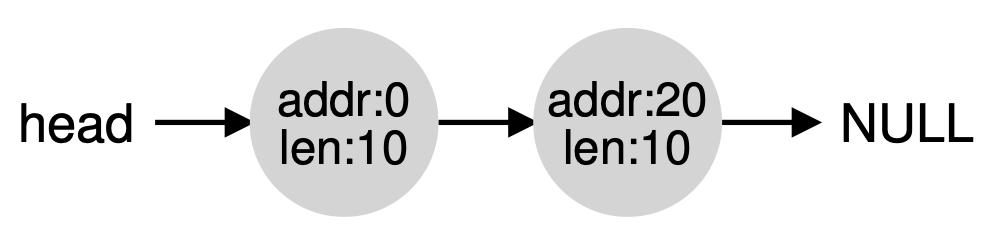
이번 장에서는 근본적인 메모리 관리, 특히 free-space management에 대한 내용을 중점적으로 살펴볼 것이다. 관리하는 메모리 공간을 고정된 크기(fixed-size unit)로 나누면 쉽다. 고정된 크기의 메모리 리스트를 갖고있다가 요청이 오면 리스트의
10.Paging: Introduction

sfd
11.Paging: Faster Translations (TLBs)

가상 메모리를 지원하는 핵심 mechanism으로 paging을 활용하면 고성능 오버헤드가 발생할 수 있다.address space를 고정된 크기로 작게 나누는 paging은 거대한 mapping information을 필요로 한다. 이런 mapping informat
12.Paging: Smaller Tables
page table의 두번째 문제점인 너무 커서 메모리를 많이 잡아먹는다는 문제점을 살펴보자. 이러한 array-based page table(linear page table)의 문제를 해결하기위한 page table을 더 작게 만들 수 있는 방법은 무엇이며, 더 작아졌을 때 발생하는 비효율은 무엇일까...? Simple Solution: Bigger ...
13.Swapping: Policy
물리적 메모리에 free space가 아주 많다면 새로운 page를 메모리에 담는 작업이 어렵지 않다. 하지만 물리적 메모리에 free space가 없다면 어떻게 해야할까?기존의 page를 메모리에서 제거할 때 어떤 기준으로 page를 메모리에서 제거하는걸까?page
14.Swapping: Mechanism
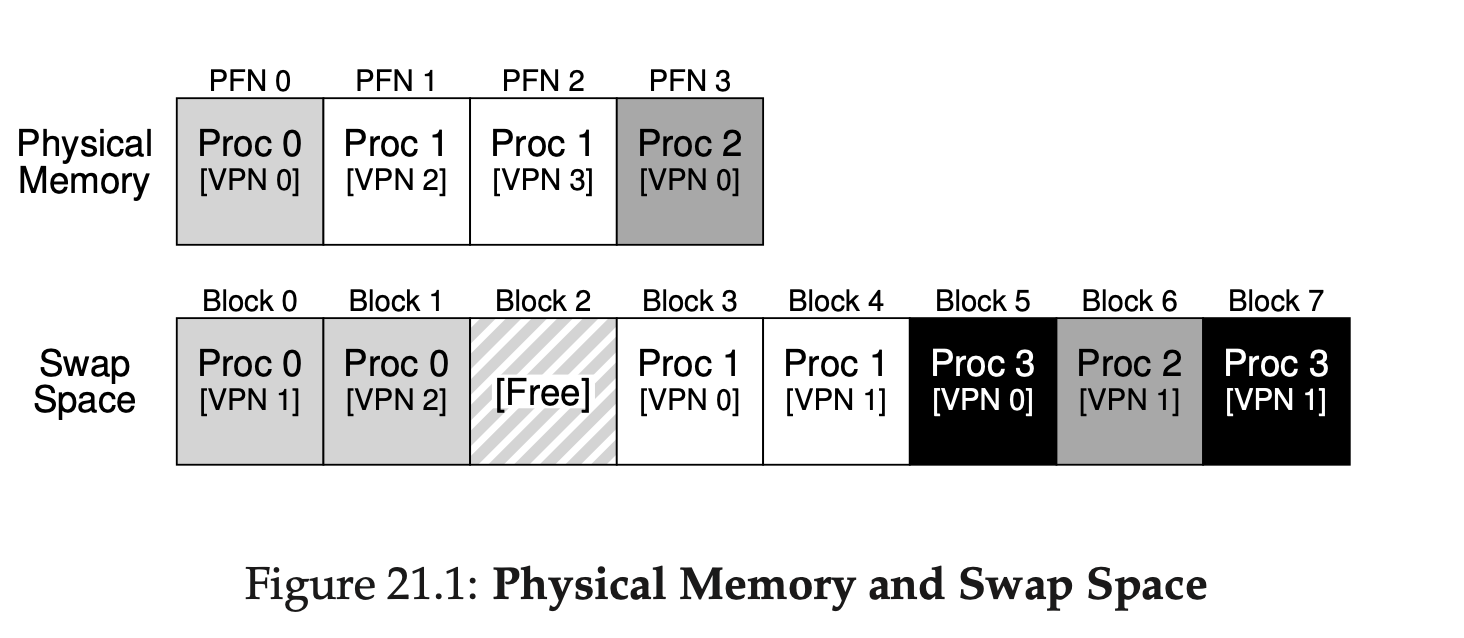
이전까지의 내용에서는 모든 address space가 물리적 메모리에 정확하게 들어맞는다고 가정하고 이론을 알아보았다. 그리고 모든 pages가 메모리에 위치해 있다고 알고 공부하였다.하지만 크기가 큰 address space를 사용하기 위해서는 당장 필요하지 않은 a
15.Lock

lock의 목적은 crital section이 atomic하게 동작하는 것을 보장하기 위함이다.lock variable이 lock의 상태를 지니고 있다.available 아무런 thread도 lock되지 않았음acquired critical section에서 한개의
16.Lock-based Concurrent Data Structures
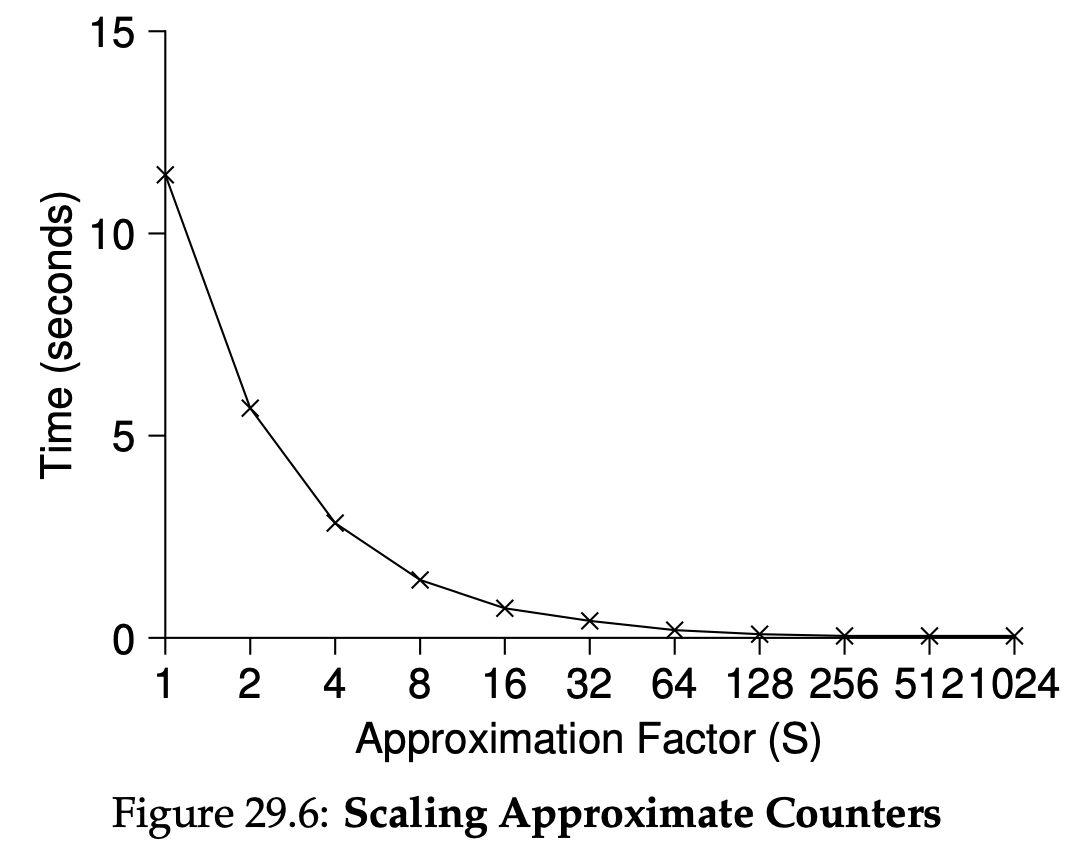
자료구조에 lock을 추가하여 thread에서 사용할 수 있도록 하면 thread 구조에 안정성을 추가할 수 있다. 따라서 lock이 정확하게 어떻게 추가되는지가 데이터 구조의 정확성과 성능을 결정한다. 결론적으로 특정한 자료구조에 lock을 추가할 때 정확하게 동작
17.Condition Variables
concurrent program을 위한 유일한 요소는 lock뿐만이 아니다.thread들이 실행을 계속할지의 여부를 결정하기 위해서는 condition을 확인해야한다.위의 코드처럼 부모 thread가 자식 thread의 종료를 기다리는 상황에서 단순하게 spin-ba
18.Semaphore

semaphore란 sem_wait()과 sem_post()로 우리가 조작할 수 있는 정수값을 갖는 object이다.위처럼 semaphore는 초기화를 해야만 한다.sem_init()으로 초기화를 수행하는데 s라는 semaphore를 1로 초기화 하고, 2번째 인자인
19.Common Concurrency Problems

위와같은 어플리케이션에서 deadlock은 총 31개 deadlock이 아닌 버그는 74개이다.첫번째 non deadlock 버그는 MySQL에서 발견한 atomicity-violation bug이다.이 버그는 다른 2개의 thread가 proc-info라는 같은 데이
20.Event-based Concurrency (Advanced)

node.js같은 server-side framework에서 자주 쓰이는 concurrency 방법이다.Event-based Concurrency는 2가지 부분을 다루게 된다.multi-threaded application에서 concurrency를 정확하게 다루는 것