자료구조에 lock을 추가하여 thread에서 사용할 수 있도록 하면 thread 구조에 안정성을 추가할 수 있다.
따라서 lock이 정확하게 어떻게 추가되는지가 데이터 구조의 정확성과 성능을 결정한다.
결론적으로 특정한 자료구조에 lock을 추가할 때 정확하게 동작하도록 만들기 위해서 무엇을 할 것인가?, concurrent를 위해서 어떻게 데이터구조에 lock을 추가할 것인가?를 생각해야한다.
Concurrent counter
counter라고 불리는 자료구조를 활용할 것이다. 위의 lock이 없는 구조는 단순하지만 확장성이 없다. thread가 늘어나면 lock이 안되기 때문이다. 그렇다면 이를 어떻게 thread safe하게 만들 수 있을까?
위의 lock이 없는 구조는 단순하지만 확장성이 없다. thread가 늘어나면 lock이 안되기 때문이다. 그렇다면 이를 어떻게 thread safe하게 만들 수 있을까? 단순하게 single lock을 추가하였다. 이 방법은 쉽고 잘동작하지만 thread가 증가할 수록 성능이 낮아진다는 단점이 있다.
단순하게 single lock을 추가하였다. 이 방법은 쉽고 잘동작하지만 thread가 증가할 수록 성능이 낮아진다는 단점이 있다.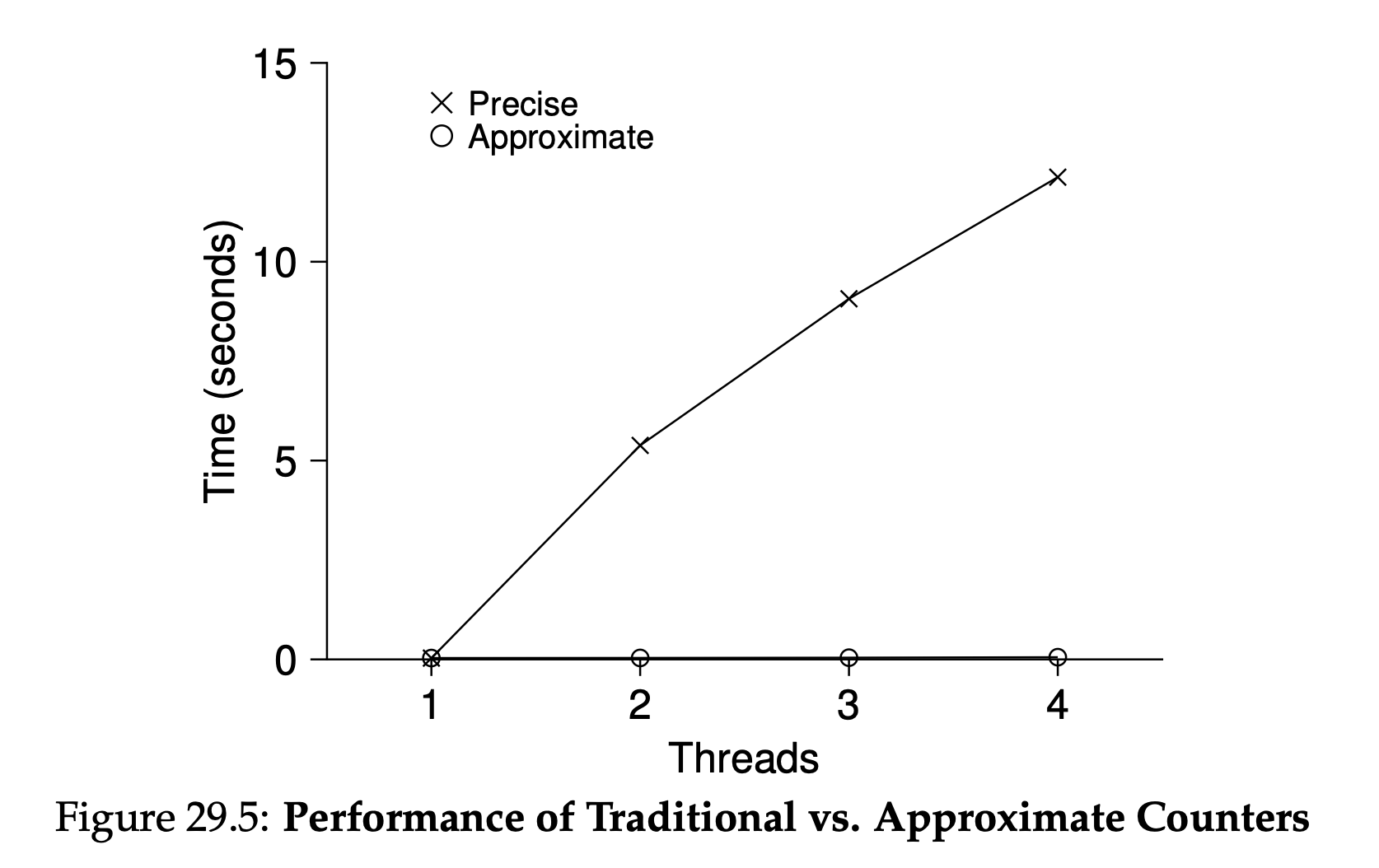 위의 그림에서 precise 방법이 counter에 단순하게 lock을 추가하는 경우인데 thread가 많아질 수록 성능이 낮아짐을 알 수 있다. 즉, 확장성이 매우 떨어진다.
위의 그림에서 precise 방법이 counter에 단순하게 lock을 추가하는 경우인데 thread가 많아질 수록 성능이 낮아짐을 알 수 있다. 즉, 확장성이 매우 떨어진다.
Scalable Counting

이 문제를 해결하기 위한 scalable한 counter중에 하나인 approximate counter에 대해서 알아보자.
approximate counter는 CPU core마다 여러개의 local 물리적 카운터들 중에 하나로 표현된 논리적 카운터와 하나의 global counter로 동작한다.
 예를들어서 4개의 CPU가 장착된 기계에 4개의 local counter와 1개의 global counter가 있다. 그리고 local counter하나마다 lock이 존재하고, global counter에도 lock이 존재한다.
예를들어서 4개의 CPU가 장착된 기계에 4개의 local counter와 1개의 global counter가 있다. 그리고 local counter하나마다 lock이 존재하고, global counter에도 lock이 존재한다.
thread가 counter를 증가시켜야 할 때는 자신의 local counter를 증가시킨다. 각각의 CPU는 자신의 local counter를 가지고 있으므로 각각의 CPU에서 thread는 간섭없이 counter를 증가시킬 수 있다. 따라서 counter update가 확장성을 갖는다.
하지만 주기적으로 global counter에게 local counter의 값을 전달해주어야한다. global counter를 local counter의 값 만큼 증가시키고, 다시 local counter를 0으로 초기화한다.
따라서 얼마나 local-to-global transfer가 발생하느냐에 따라서 counter의 상한선인 S(sloppiness)가 결정된다.
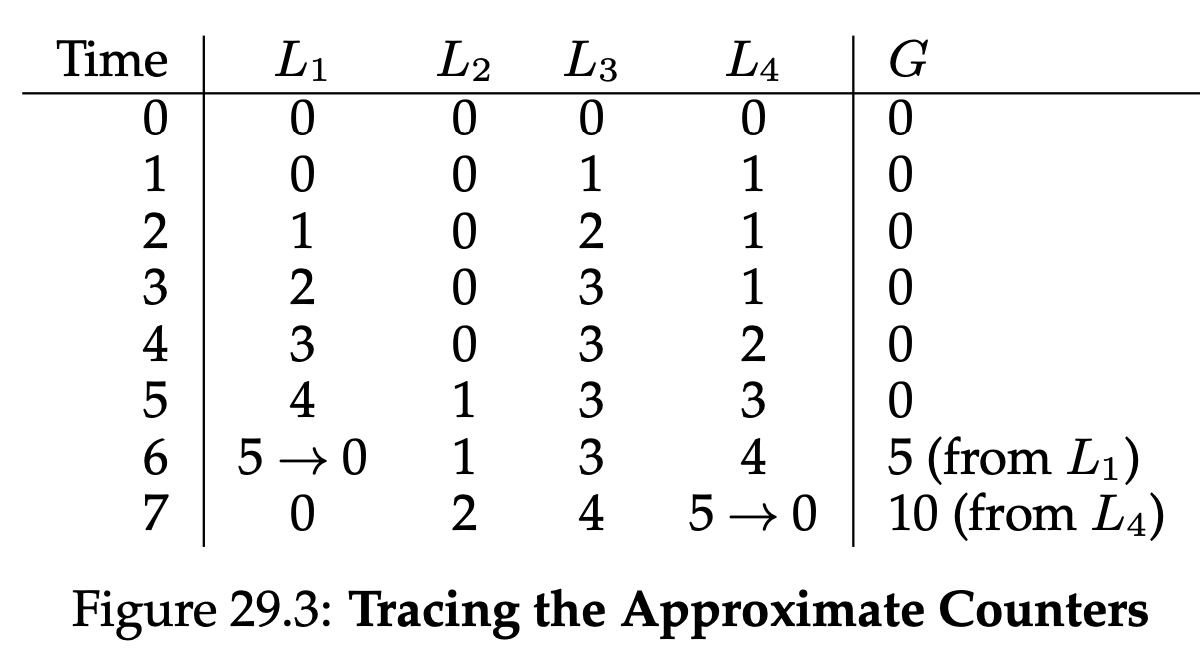
예를들어 위의 29.3을 보면 S가 5로 설정되어있다. 따라서 각각의 local counter가 상한선인 S에 도달하면 그 값을 global counter에게 전달해준다.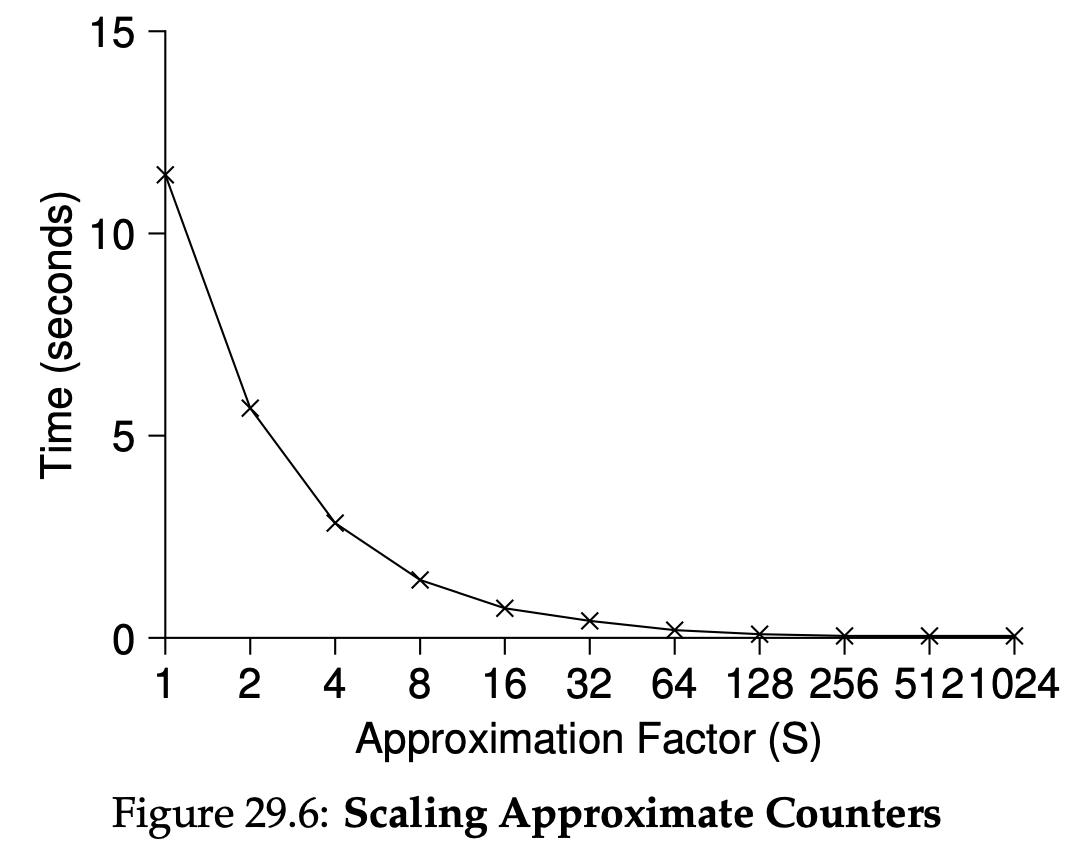 위의 그림처럼 S가 클 수록 성능이 좋아지는 것을 확인할 수 있다. 하지만 S가 작을수록 local-global의 차이는 작고, S가 커질수록 local-global의 차이가 크다.
위의 그림처럼 S가 클 수록 성능이 좋아지는 것을 확인할 수 있다. 하지만 S가 작을수록 local-global의 차이는 작고, S가 커질수록 local-global의 차이가 크다.
Concurrent Linked Lists


좀 더 복잡한 자료구조인 linked list와 lock을 결합하면 위와 같은 코드로 작성할 수 있다.
counter방식과 마찬가지로 가장 단순한 버전의 linked list도 확장성이 떨어지는 문제가 있다.
Scaling Linked Lists
이 문제를 해결하기 위한 방법으로 hand-over-hand locking (lock coupling)이라는 방법이 있다.
전체 리스트에서 하나의 lock을 활용하는 것이 아니라 각각의 node마다 하나의 lock을 지니고 있다.
리스트를 순회할 때 다음 노드에 대해서 lock을 걸고 현재 노드의 lock을 해제한다.
매우 높은 수준의 동시성을 지닐 수 있다. 하지만 매번 노드마다 lock을 얻고 해제하는데 드는 overhead 때문에 이 방법은 사용되진 않는다.
Concurrent Queues
이쯤되면 기본적으로 자료구조에 lock을 결합하는 방식이 전체 자료구조에 lock을 하나 생성한다는 것임을 알것이다.
그래서 이번에는 가장 쉬운 방법은 충분히 생각해볼 수 있으므로 넘어가고 Michael and Scott이 만든 queue (이후 concurrent queue)에 대해서 알아볼 것이다.
concurrent queue에는 queue의 head, tail에 2개의 lock이 있다.
이 2개 lock의 목표는 enqueue(queue에 데이터 생성시)에 tail에 lock을 거는 것과, dequeue(queue에서 데이터 출력시)에 head에 lock을 거는 것이다. 그래서 이를 위해 dummy node를 하나 생성하여 head, tail이 항상 나눠질 수 있도록 만든다.
그래서 이를 위해 dummy node를 하나 생성하여 head, tail이 항상 나눠질 수 있도록 만든다.
Concurrent hash table
 리스트에서 활용되던 것 처럼 hash bucket마다 lock이 존재한다.
리스트에서 활용되던 것 처럼 hash bucket마다 lock이 존재한다.
출처: OSTEP
