물리적 메모리에 free space가 아주 많다면 새로운 page를 메모리에 담는 작업이 어렵지 않다. 하지만 물리적 메모리에 free space가 없다면 어떻게 해야할까?
기존의 page를 메모리에서 제거할 때 어떤 기준으로 page를 메모리에서 제거하는걸까?
Cache Management
page를 디스크로부터 가져올 때 cache miss가 최소화되도록 cache를 management한다.
cache hit, miss의 횟수를 통해 average memory access time(AMAT)를 알 수 있다.
AMAT = (메모리에 접근하는데 걸리는 시간 * cache hit의 확률) + (디스크에 접근하는데 걸리는 시간 * cache miss의 확률)Optimal Replacement Policy
전체적인 cache miss의 수를 최대한으로 줄이는 것을 목적으로 한다.
이를 위해 지금으로부터 가장 나중에 접근할 page를 메모리에서 내보낸다. 가장 멀리있는 page를 참조하기 이전에 가까운 page들부터 참조할테니 총 cache miss의 수가 줄어든 것은 당연하다.
하지만 scheduling policy에서 봤듯이, 지금으로부터 가장 나중에 접근할 page를 알 수 있는 방법은 없다. 따라서 Optimal replacement policy는 우리가 완벽에 얼마나 가까운지를 결정하는 비교지표로써 사용된다.
Simple Policy: FIFO
page가 메모리에 적재될 때 queue에 올라가게 된다. 이후 page를 메모리에서 내보낼 때 queue에 가장 첫번째 page (first in)을 내보낸다.
하지만 FIFO 방식은 어떤 page block이 중요한지 알 수 없다. 예를들어 여러번 접근하는 page block이 queue의 첫번째에 있는 경우에 FIFO는 그 page의 중요성을 판단하지 못하고 내보낸다.
Simple Policy: Random
이름 그대로 random한 page를 내보내는 것이다.
random 방식은 내보낼 page를 고르는데 특별한 방법이 필요하지 않고, 무작위로 고를 뿐이다.
그럼에도 불구하고 성능이 매우 좋을 수 있다!
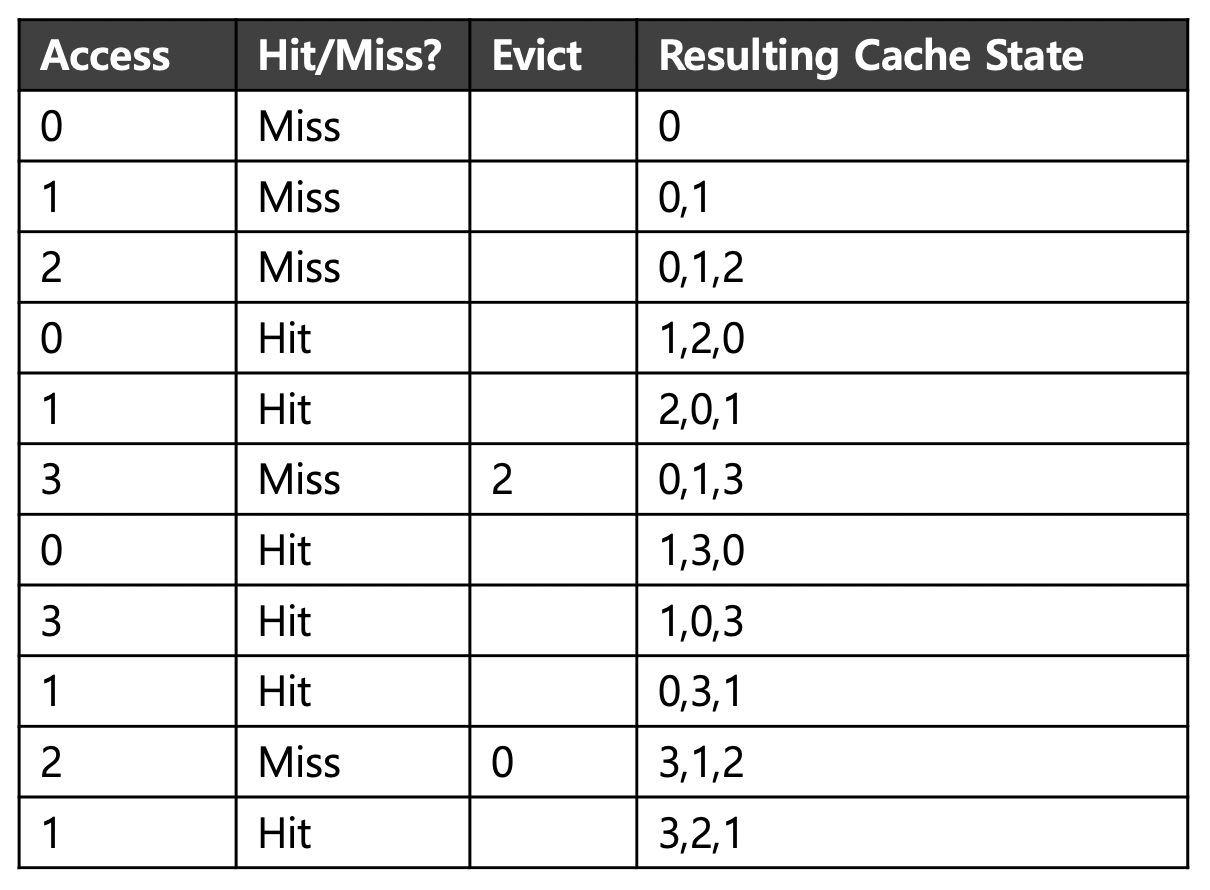
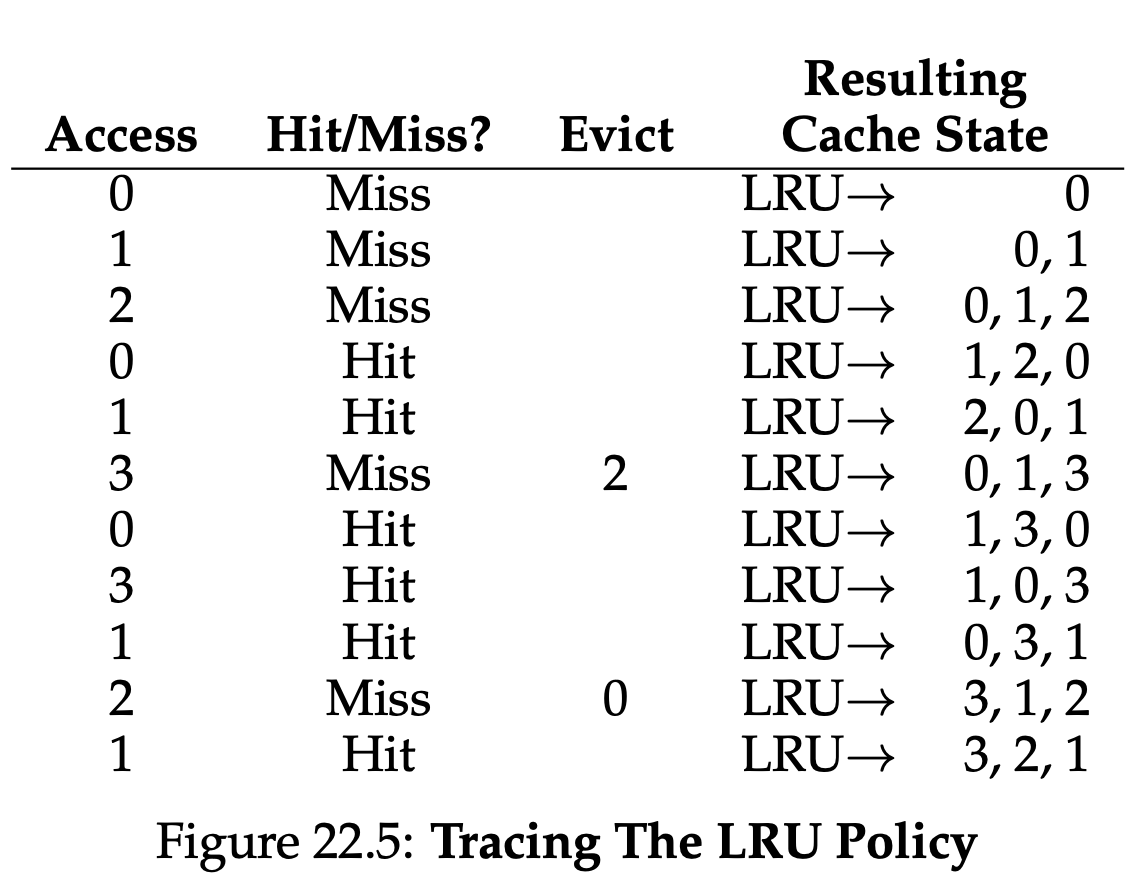
Using History: LRU (Least-Recently- Used)
최근에 page에 접근했을 수록 다시 그 page에 접근할 가능성이 높다.
Using History: LFU (Least-Frequetly--Used)
만약 page에 여러번 접근했다면, 중요한 page이므로 대체해서는 안된다.
Workload Example
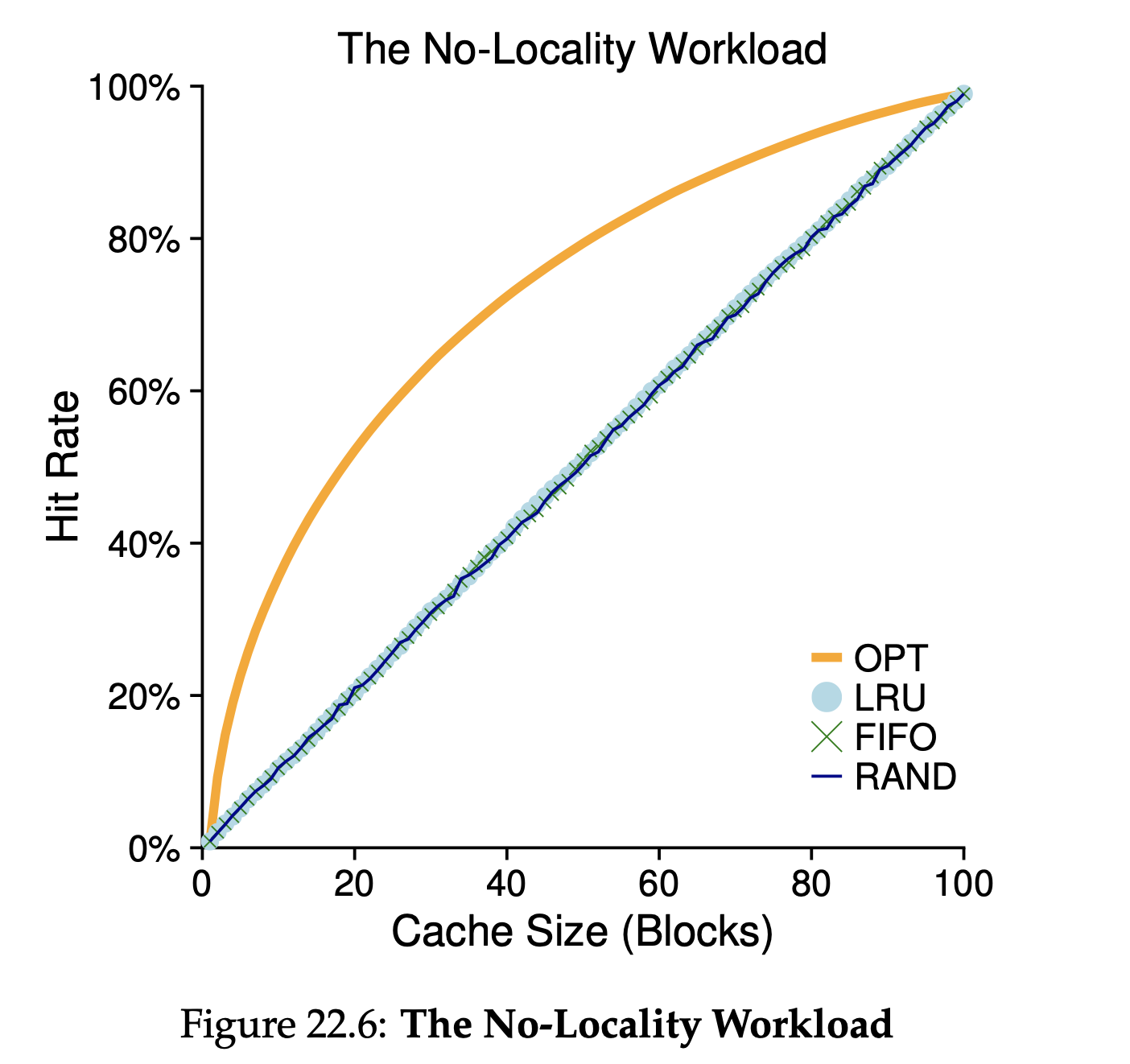 만약 전체 workload를 담을 만큼 cache가 크다면 어떤 방법을 사용해도 좋은 결과를 얻을 수 있다.
만약 전체 workload를 담을 만큼 cache가 크다면 어떤 방법을 사용해도 좋은 결과를 얻을 수 있다.
Workload Example (80-20)
20%의 page가 전체 reference의 80%이고 (hot pages), 나머지 80%의 page가 남은 20%의 reference를 담당한다 (cold pages).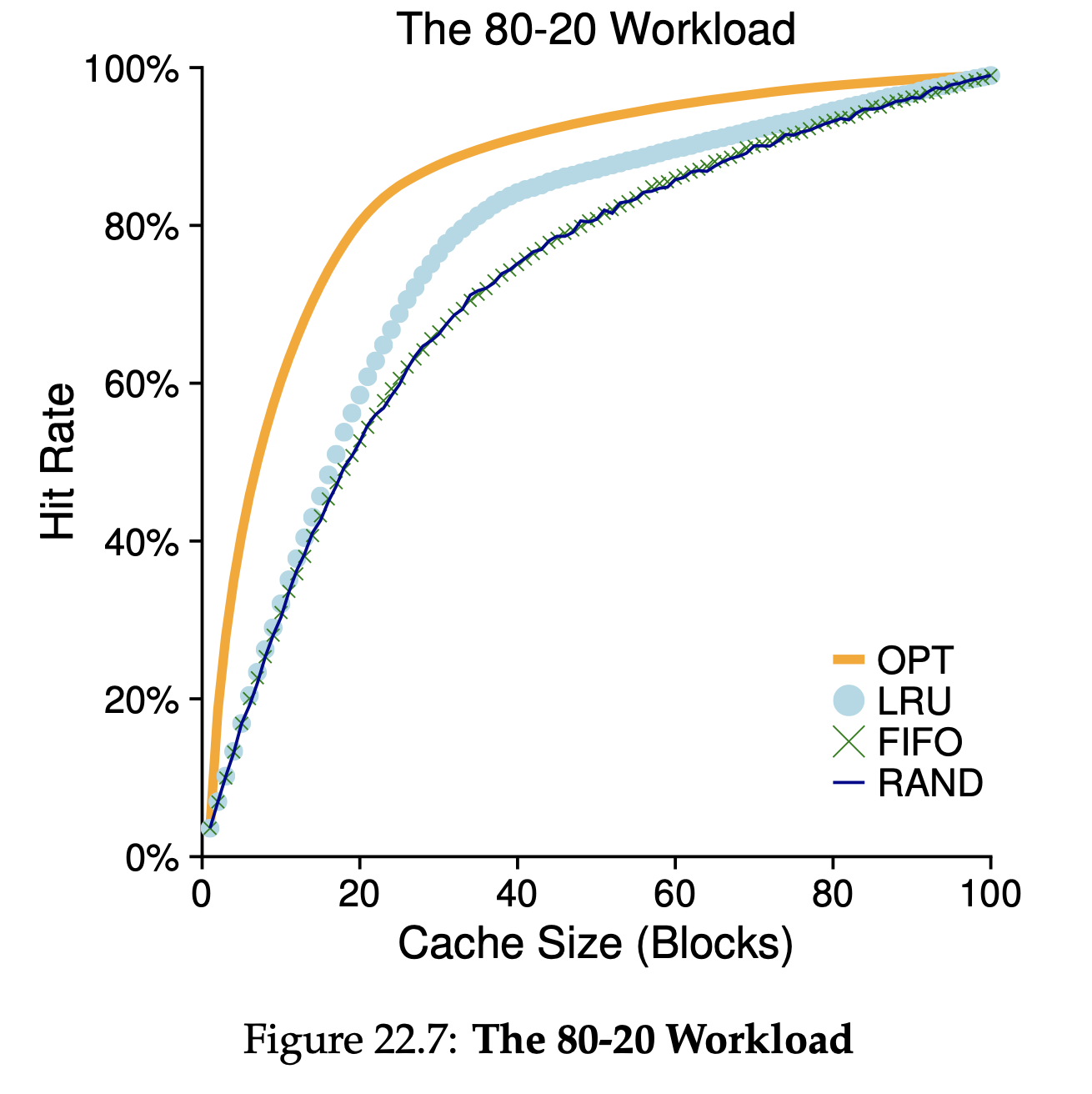 이 경우에는 LRU 방식이 가장 우수함을 알 수 있다.
이 경우에는 LRU 방식이 가장 우수함을 알 수 있다.
Workload Example : The Looping Sequential
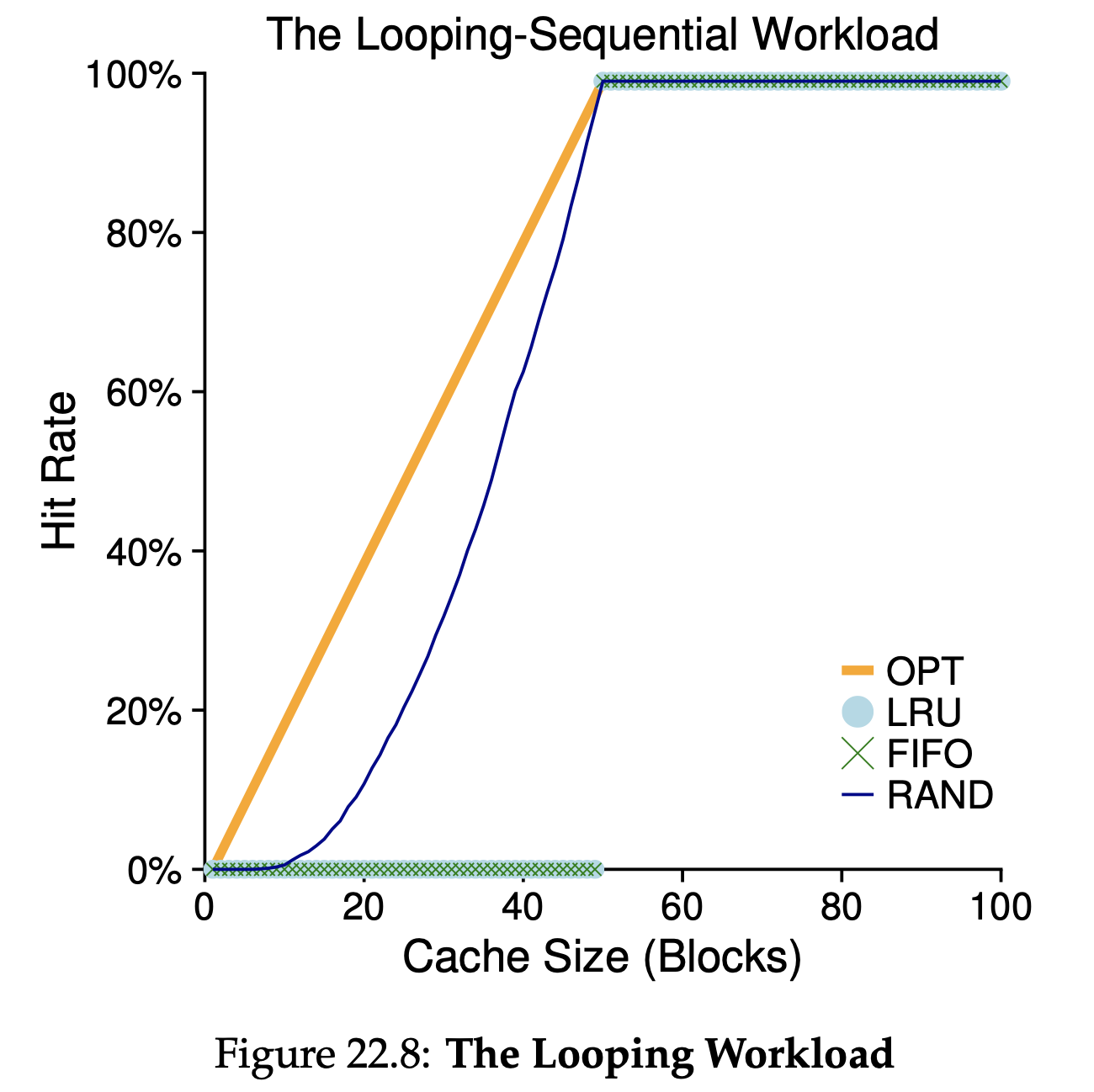 예를들어 50개의 page sequence에 대한 10000번의 reference가 있다고 하자.
예를들어 50개의 page sequence에 대한 10000번의 reference가 있다고 하자.
이 경우에는 LRU, FIFO가 가장 성능이 낮다.
Approximating LRU
LRU에 근사적으로 replacement를 활용하는 것이 많은 현대의 운영체제들이 수행하는 방법이다.
page가 reference될 때마다 하드웨어에 의해서 use bit가 1로 설정된다. 이 use bit는 하드웨어가 없앨 수 없고, OS만이 1에서 0으로 변경할 수 있다.
Clock Algorithm
모든 page들이 circular list의 형태로 존재한다. clock point가 특정한 page를 가리키면서 시작해서 use bit가 0인 page를 찾는다.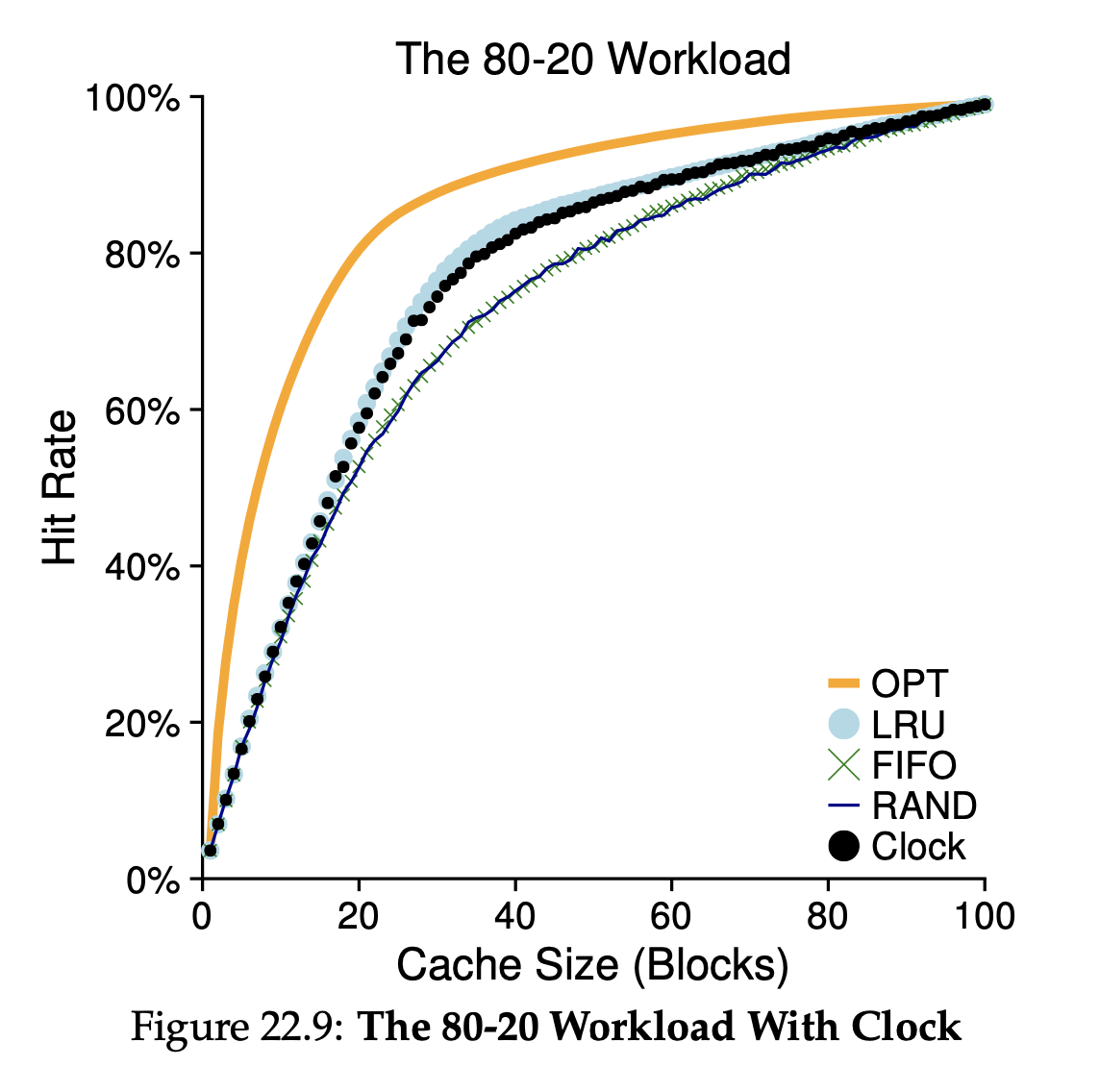
Considering Dirty Pages
하드웨어에는 modified bit (dirty bit)이 존재한다.
만약 page가 수정되었다면 해당 page를 디스크로 내보낼 때 다시 수정된 page를 디스크에 작성(write)해주어야 한다. 그래서 이 작업에 도움을 주기위해 modified (dirty) bit가 활용된다.
Other VM Policies
Prefetching
OS가 곧 사용될 page를 미리 가져오는 방법을 말한다. 예를들어 page 1번이 swap disk에서 메모리로 옮겨질 때 page 2번도 곧 쓰일 것으로 예측하고 같이 메모리로 옮기는 방법을 말한다.
Clustring, Grouping
매번 write요청이 있을 때마다 disk에 작성을 하는 것이아니라, 이 요청들을 모아서 한번에 처리하는 방법을 말한다. 따라서 작은 요청 여러개를 하나의 큰 요청으로 모아서 작업하는 방식이다.
Thrashing
실제 메모리 크기보다 더 많은 실행중인 프로세스의 요청이 들어온다면 어떻게해야할까?
이러한 문제를 thrashing이라고 부른다.
그래서 몇몇 프로세스 중 일부를 동작시키지 않게 함으로써 실제 메모리 크기에 맞출 수 있도록하여 thrashing을 해결하곤 했다.
이는 우리가 작업을 할 때 모든 작업을 안좋게 하기보다 더 적은 작업을 잘 하는 것이 낫다는 것을 시사한다.
좀 더 엄격하게 memory oversubscribed문제를 해결하기 위해서 out-of-memory killer라는 것을 동작시켜서 메모리를 많이 잡아먹는 프로세스를 감지하고 종료시킨다.
출처: OSTEP
