isinstance
파이썬 내장 함수로, 특정 값이 지정한 타입(또는 타입들의 집합)에 속하는지를 확인해주는 함수예요.
예시:
isinstance(10, int) # 10은 int 타입이므로 True
isinstance(3.14, float) # 3.14는 float 타입이므로 True
isinstance("hello", int) # "hello"는 int 타입이 아니므로 False
if not isinstance(value, (int, float)): 구문은,
value가 int나 float 타입이 아니라면(즉, 숫자가 아니라면)
if 문 안의 코드를 실행하라는 의미예요.
즉, if not isinstance는 "만약 value가 int나 float 타입이 아니라면" 이라는 조건을 확인하는 코드입니다.Counter
- collections 모듈에 포함된 클래스
- 리스트나 다른 반복 가능한(iterable) 객체에 들어 있는 항목들의 빈도수를 쉽게 계산할 수 있게 해줍니다.
- ex) Counter(all_values)를 호출하면 all_values에 들어 있는 각 값이 몇 번 나타나는지 자동으로 계산하여 딕셔너리와 유사한 형태(각 값이 key, 그 빈도수가 value)가 됩니다.
Frequency_dict
- counter 객체에서 얻은 결과를 바탕으로 만든 또 다른 딕셔너리
- 빈도수 = key
- 빈도수를 가진 값들의 목록(list) = value
<frequency_dict는 다음과 같은 딕셔너리 구조>
{
빈도수1: [값1, 값2, ...],
빈도수2: [값3, 값4, ...],
...
}
random.uniform(a,b)
- a,b 인자를 통해 a보다 크거나 같고, b보다 작거나 같은 a,b사이의 소수를 반환
ex) monte_carlo_simulation
x= np.random.random([N,2])
==
X= np.random.uniform(0,1,[N,2])-
np.random.random(size)는 고정된 범위 [0, 1) 내의 난수를 생성합니다.
-
np.random.uniform(low, high, size)는 사용자가 지정한 범위 [low, high) 내에서 난수를 생성할 수 있습니다.
np.random.uniform(low, high, size)
-
low: 생성할 난수의 최소값 (포함됨)
-
high: 생성할 난수의 최대값 (포함되지 않음)
-
size: 생성할 배열의 형태(shape)
np.random.random
np.random.random(size) 함수는 0.0 이상 1.0 미만의 균등 분포(uniform distribution)를 따르는 난수를 생성
import numpy as np
# 3개의 무작위 실수를 생성 (0과 1사이)
a = np.random.random(3)
print(a) # 예: [0.5488135 0.71518937 0.60276338]
# 2차원 배열 (3행 4열) 생성
b = np.random.random((3, 4))
print(b)
- 기본범위 : 항상 0이상 1미만 (범위 지정 옵션 따로 x)
거듭제곱 연산자(**)
x ** 2.0 => x의 거듭제곱
x ** 3.0 => x의 세제곱
ex) 3 ** 3 => 27axis
axis=1일 경우, 각 행(row)의 모든 요소를 더해서 행 단위의 합을 구합니다.
예를 들어, 아래와 같은 2차원 배열이 있다고 할 때:
lua
Copy
[[1, 2, 3],
[4, 5, 6]]
axis=1로 합을 구하면:
1행 (첫 번째 행)의 합: 1 + 2 + 3 = 6
2행 (두 번째 행)의 합: 4 + 5 + 6 = 15
결과는 [6, 15]가 됩니다.
axis=0일 경우, 각 열(column)의 모든 요소를 더해서 열 단위의 합을 구합니다.
같은 배열에서 axis=0로 합을 구하면:
첫 번째 열의 합: 1 + 4 = 5
두 번째 열의 합: 2 + 5 = 7
세 번째 열의 합: 3 + 6 = 9
결과는 [5, 7, 9]가 됩니다.
.strip()
- java의 trim과 비슷한 역할
- 문자열의 양쪽 끝에서 공백(스페이스, 탭 등)을 제거
- 추가적으로, 특정 문자 집합을 인자로 전달하면 해당 문자들도 제거할 수 있습니다. 예: strip("abc")는 문자열 양쪽 끝에서 'a', 'b', 'c'를 제거
import re
def hyphens(text:str) -> str :
lines = text.strip().split("\n")
updated =[]
for line in lines :
stripped = line.strip()
# 1. "숫자."로 시작 -> 그대로 문장 출력
if re.match(r'^\d+\.', stripped):
updated.append(stripped)
# 2. 빈 줄이면 추가하지 않음
elif stripped == "" :
updated.append("")
# 3. 그 외 (문자열, 기호) 시작 -> (-) 하이픈 붙이고 출력
else :
updated.append(f"- {stripped}")
return "\n".join(updated)
copied_text = """
AI 기초 이해 학습노트
1. 인공지능, 머신러닝, 딥러닝, 생성형 AI
[인공지능 (AI)]
인간처럼 학습, 추론, 문제 해결을 할 수 있는 기술
약한 AI vs 강한 AI
[머신러닝 (ML)]
데이터를 기반으로 학습해 예측/분류를 수행
지도학습, 비지도학습, 강화학습으로 분류됨
[딥러닝 (DL)]
인공신경망을 기반으로 한 머신러닝 기술
CNN, RNN, LSTM 등 구조가 있음
[생성형 AI (Generative AI)]
학습한 데이터에서 새로운 콘텐츠를 생성
예: GPT, DALL·E, Stable Diffusion 등
비유로 이해하기
AI는 뇌를 가진 로봇 전체
ML은 배우는 능력
DL은 복잡한 뇌 구조
Generative AI는 창작 능력
"""
print(hyphens(copied_text))
import re
- 파이썬의
re모듈을 불러오는 코드 - regular expression(정규 표현식)의 줄임말로 -> 문자열에서 패턴을 검색하거나 검사할 때 사용
=> 정규표현식 패턴을 검색 or 검사하려고 import하는 모듈
python 정규표현식
re.match()
- 문자열의 시작부터 패턴이 일치하는지 검사
- 맨 앞만 검사하므로, 중간에 있는 것은 못찾음
re.search()
- 문자열 전체에서 패턴을 찾아서 일치 여부 검사
- 중간에 있는 것도 검사하려면 search 사용
re.findall()
- 일치하는 모든 결과를 리스트로 반환
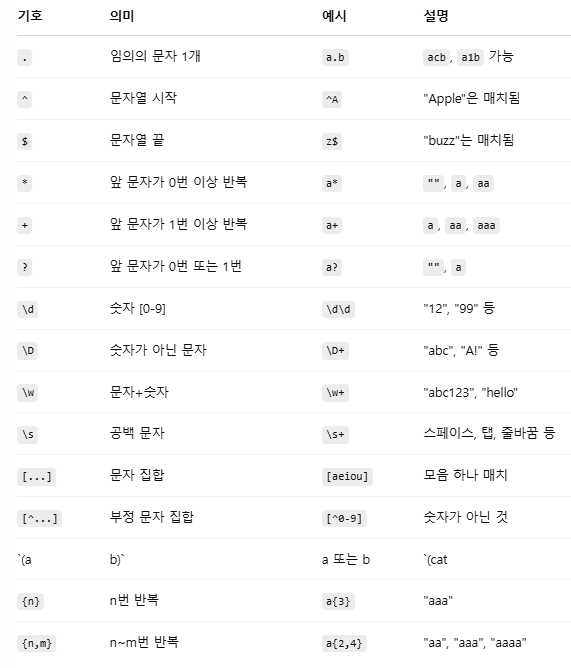
if re.match(r'^\d+\.', stripped):정규표현식 기호 정리
문자열.isdigit()
- 전체 문장이 숫자로만 이루어져있을 때
- 가장 첫번째 문자열 text[0].isdigit() == True이면, 첫 문자가 숫자
- false면 첫 문자가 숫자를 제외한 나머지(문자, 기호, ..)
<자주하는 실수>
"4. 요약 정리".isdigit() # ❌ False
"4.".isdigit() # ❌ False
"Ⅳ".isdigit() # ✅ True (주의! 로마 숫자도 인식함)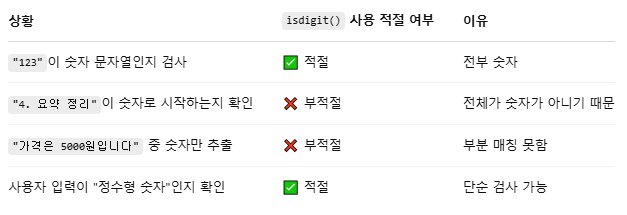
upper(), lower(), swapcase(), capitalize() Method
upper()
- 문자열의 모든 문자를 대문자로 변환
lower()
- 문자열의 모든 문자를 소문자로 변환시켜줌
swapcase() Method
- 대문자 -> 소문자
- 소문자 -> 대문자
capitalize() Method
- 문자열의 첫 글자를 대문자로 변환시켜줌
- 문자열에 첫 문자가 이미 대문자인 경우는 변환되지 x
for _ in range()
- 변수 이름
_: 변수를 사용하지 않겠다는 관용적인 표시 - 반복 횟수를 나타내기 위한 변수 역할을 하지만, 그 값을 코드 안에서 사용하지 않겠다는 의미
final_values = [simulate_investment(scale, days) for _ in range(simulations)]
return np.array(final_values)리스트 컴프리헨션
[simulate_investment(scale, days) for _ in range(simulations)]는 simulate_investment(scale, days) 함수를 simulations 횟수만큼 실행하여 그 결과들을 리스트로 모으는 역할을 합니다.
-
range(simulations)는 숫자 0부터 simulations - 1까지 반복합니다.
-
반복 과정에서 각 인덱스 값은 사용되지 않으므로 변수 이름으로 _를 사용합니다.
-
각 반복마다 simulate_investment(scale, days)의 실행 결과가 리스트에 추가됩니다.
