시각화 심화
상관성 분석
# 주요 패키지 임포트
import seaborn as sns
import matplotlib.pyplot as plt # tab (자동완성)
import numpy as np
import pandas as pd
# 소수점 표시 옵션
pd.options.display.float_format = '{:,.2f}'.format # 소수 둘째자리까지 판다스 표에서 표시
# https://www.kaggle.com/datasets/priyanshusahu23/winequality
# Kaggle > 검색 창 -> 키워드 > Datasets, Competitions
# 데이터 불러오기
df = pd.read_csv("https://github.com/bigdata-young/230207_viz_practice/raw/main/wine-quality.csv")
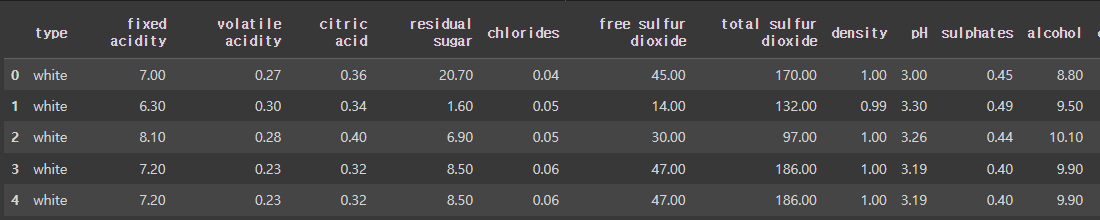
# 데이터 샘플 확인
df.head()
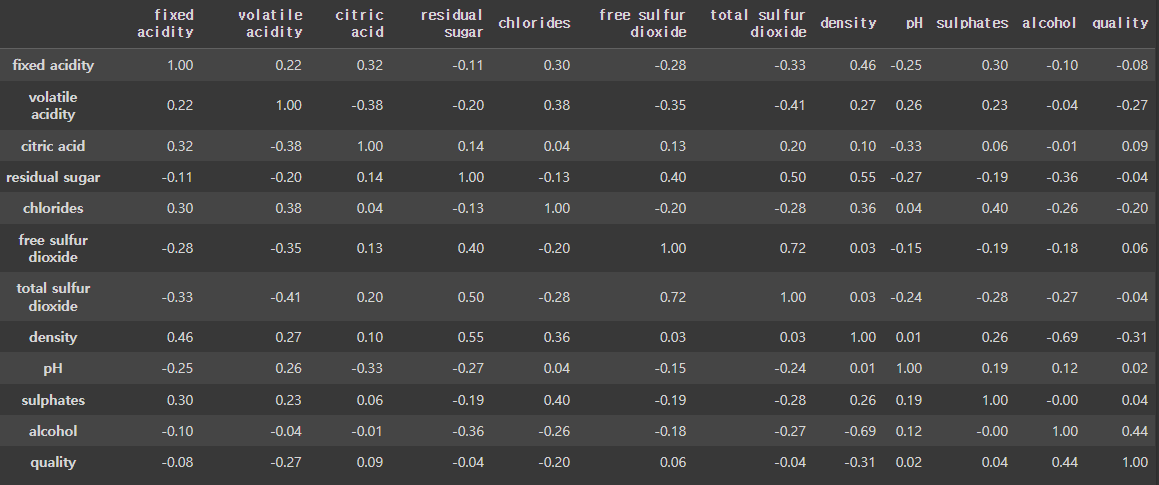
# 피어슨 상관계수
df.corr() # 각 열들을 행과 열로 배치시키고, 각 열들간의 상관관계
# -1, 1, 0 / # 0.6~0.7 이면 강한 상관관계
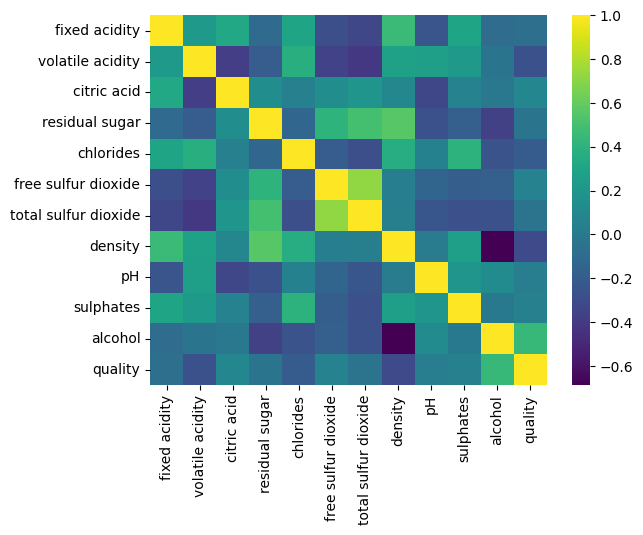
히트맵 시각화
sns.heatmap(df.corr(), cmap='viridis')
# 각각의 상관계수 수치 표시
sns.heatmap(df.corr(), cmap='viridis', annot=True); # anootation 주석 : 설명
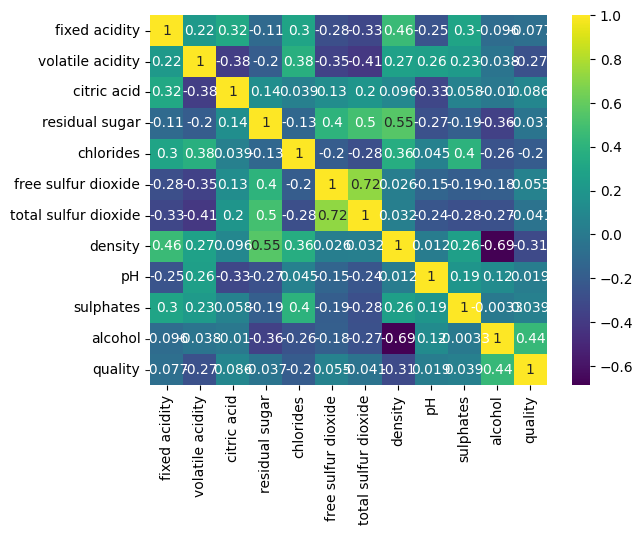
# 값의 최소/최대 표시를 설정 (상관계수는 -1~1)
plt.figure(figsize=(15, 10))
sns.heatmap(df.corr(), cmap='viridis', annot=True, vmax=1, vmin=-1)
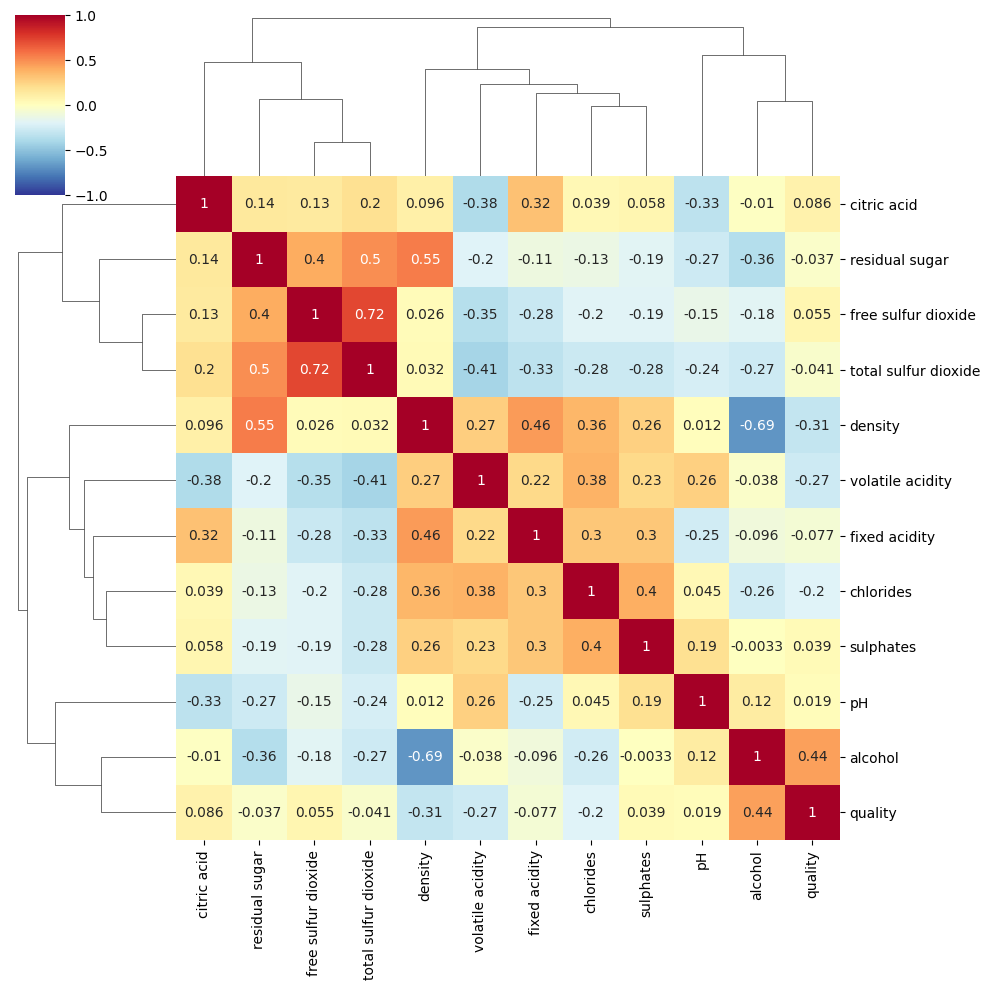
# 클러스터맵 시각화 -> 기존 히트맵에 상관성이 강한 변수들끼리 묶어서 표현
plt.figure(figsize=(15, 10))
# sns.heatmap(df.corr(), cmap='RdYlBu_r', annot=True, vmax=1, vmin=-1)
sns.clustermap(df.corr(), cmap='RdYlBu_r', annot=True, vmax=1, vmin=-1)
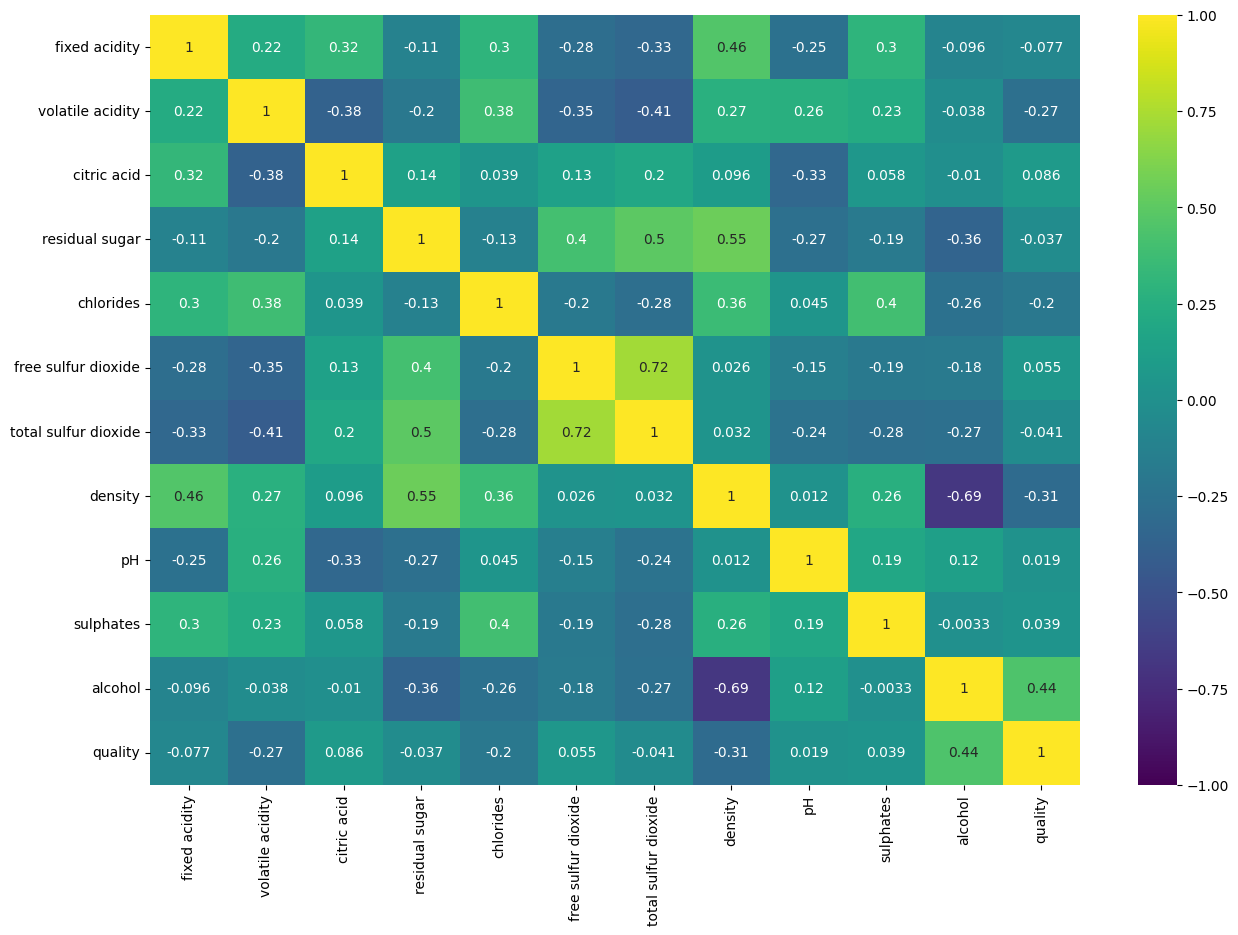
# 중복 제거 히트맵 시각화
# 중복되는 부분을 제외(동일한 변수 조합이 두번씩 나오는)하여 가독성 높이기
# 매트릭스의 우측 상단을 모두 True인 1로, 하단을 False인 0으로 변환.
np.triu(np.ones_like(df.corr()))
# True/False mask 배열로 변환.
mask = np.triu(np.ones_like(df.corr(), dtype=bool))
# 히트맵 그래프 생성
fig, ax = plt.subplots(figsize=(15, 10))
sns.heatmap(df.corr(),
mask=mask,
vmin=-1, vmax=1,
annot=True, cmap="RdYlBu_r", cbar=True
)
ax.set_title('Wine Quality Correlation', pad = 15)
plt.show()

분포 시각화
- 트리맵 차트 : 구성 요소가 복잡한 질적 척도를 표현
- 하나의 큰 사각형을 구성 요소의 비율에 따라 작은 사각형으로 쪼개어 분포를 표현
- 트리맵 차트의 장점은 사각형 안에 더 작은 사각형을 포함시켜서 위계구조를 표현할 수 있다는 것
- 예를 들어 의류 매장의 품목별 판매량 분포를 트리맵 차트로 표현한다면, '바지' 영역이 긴 바지와 반바지로 분리하여 구성
- 이처럼 한정된 공간 안에서 많은 구성 요소들의 분포를 체계적으로 표현할 수 있음
- 하지만 구성 요소들 간의 규모 차이가 크면 표현이 어려울 수 있다는 단점이 있음
- 와플 차트 : 와플처럼 일정한 네모난 조각들로 분포를 표현
- 하지만 트리맵 차트처럼 위계구조를 표현하지는 못함
# 필요한 패키지 설치 및 임포트
!pip install plotly -q # -q : 메시지 없이 설치할 수 있는 옵션
!pip install pywaffle -q
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import numpy as np
import plotly.express as px
from pywaffle import Waffle
plt.rcParams['figure.dpi'] = 300
트리맵 차트 시각화
# 트리맵 차트용 데이터셋 전처리
# df_ = df[['country', 'sex', 'height_cm']]
# 국가, 성별 단위 신장 175cm 이상 카운팅
# df_ = df_[df.height_cm >= 175]
# df_ = df.loc[df.height_cm >= 175,['country', 'sex', 'height_cm']].groupby(['country', 'sex']).count().reset_index()
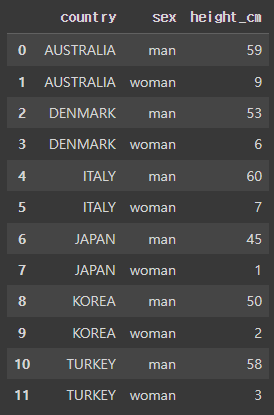
df_tree1 = df.loc[df.height_cm >= 175, ['country', 'sex', 'height_cm']]
# df_tree1
df_tree2 = df_tree1.groupby(['country', 'sex']).count()
df_tree2
df_tree3 = df_tree2.reset_index()
df_tree3
# 위계구조를 표현하고 싶은 범주형 변수들을 남기고, 그것에 기준이 되는 실수형(연속형) 변수 열만 남겨서
# groupby()로 그룹 묶은 후 -> count() 함수 -> reset_index() 인덱스를 리셋해야함
# import plotly.express as px
# https://plotly.com/python/getting-started/
fig = px.treemap(df_tree3,
path=['sex', 'country'],
values='height_cm', # 사각형의 크기
color='height_cm', # 사각형의 색상의 농도
color_continuous_scale='viridis')
# 트리맵 차트는 위계구조를 표현하기 때문에 path 옵션으로 위계구조 순서별 칼럼을 넣어줌
# 우선 성별로 구분하고 그 안에서 국가별 분포를 표현하기 위해 sex, country 칼럼을 입력해줌
# 시각화된 트리맵 차트에서는 신장 175cm 이상 샘플의 비율을 나타내므로 남성-이탈리아의 비중에 가장 높고,
# 여성-일본의 비중이 가장 낮게 나온 것을 확인할 수 있음
fig.show()

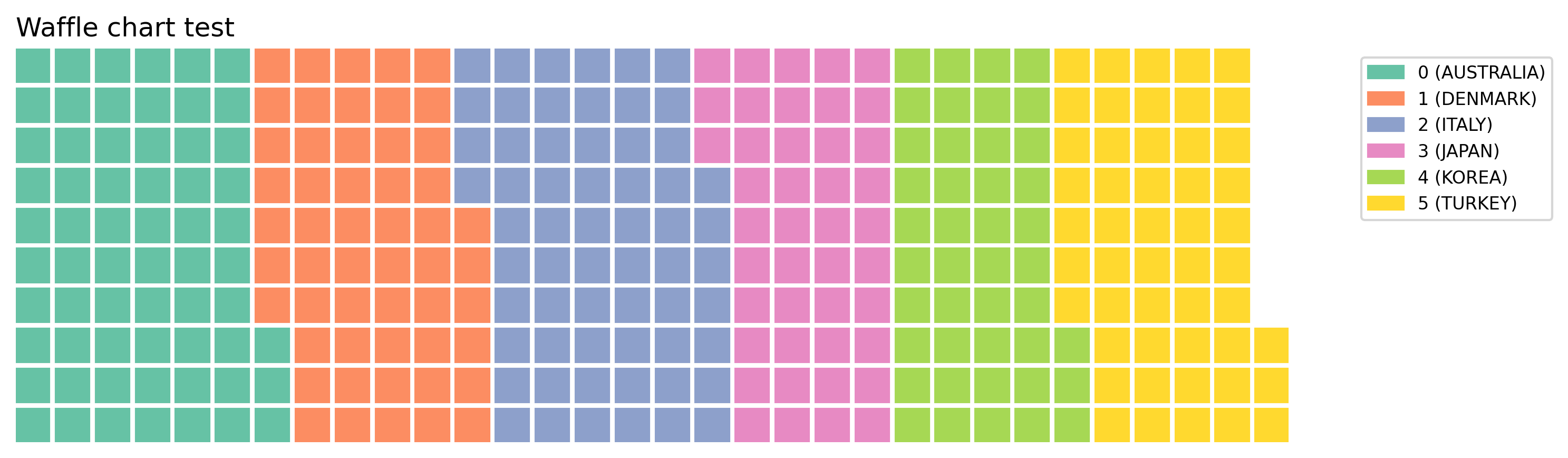
와플차트 시각화
# 와플차트 시각화를 위한 데이터 전처리
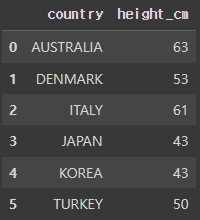
df_waffle = df.loc[df.height_cm > 175, ['country', 'height_cm']].copy().groupby('country').count().reset_index()
df_waffle
# !pip install pywaffle -q
# from pywaffle import Waffle
# https://pywaffle.readthedocs.io/en/latest/
fig = plt.figure(
FigureClass=Waffle,
plots={
111: {
'values': df_waffle['height_cm'],
'labels': ["{0} ({1})".format(n, v) for n, v in df_waffle['country'].items()],
'legend': {'loc': 'upper left', 'bbox_to_anchor': (1.05, 1), 'fontsize': 8},
'title': {'label': 'Waffle chart test', 'loc': 'left'}
}
},
rows=10,
figsize=(10, 10),
font_size=18,
# icons='star'
)
# 각 국가의 비중이 작은 정사각형으로 표현
# rows 옵션을 통해 차트 형태를 조정 가능
# https://pypi.org/project/pywaffle/
# https://pywaffle.readthedocs.io/en/latest/
# https://pywaffle.readthedocs.io/en/latest/examples/plot_with_characters_or_icons.html
plt.show()