
들어가며
링크를 통해 이 글을 요약한 AI 팟캐스트를 들어볼 수 있습니다.
본 시리즈에서는 상향식 접근을 토대로 코루틴의 동작 방식을 알아봅니다.
1편을 읽고 오는 것을 권장드립니다.
(코틀린 코루틴 간 협력에 활용되는 기본적인 운영체제 지식을 설명합니다.)
이번 편에서는 동시성을 구현하는 방식의 발전 과정을 살펴보며, 관련 개념들을 더욱 자세히 탐구해보겠습니다.
동시성을 구현하는 방식은 시간이 지나면서 점점 더 효율적으로 발전해왔습니다. 프로세스에서 시작해 스레드를 거쳐 코루틴에 이르기까지 각 방식이 어떻게 동작하는지, 어떤 장점과 한계를 가지는지 살펴보겠습니다. 추가적으로 비선점형(협력적) 멀티태스킹 개념이 적용된 코루틴을 사용했을 때 어떻게 스레드보다 더 가볍고 효율적인 방식으로 동시성을 실현할 수 있는 것인지 살펴보겠습니다.
선행 지식
본 편에서 나오는 개념들로, 알아두면 이 글을 이해하는 데 도움이 됩니다.
- 프로세스와 스레드
- 멀티스레딩의 필요성
- 스레드 풀
- JVM에서의 스레드(풀) 구현
- Thread, Runnable/Callable, Executors
- 동시성과 병렬성 (1편)
- Process Control Block(PCB), Thread Control Block(TCB)
- Blocking & Non-Blocking
이전 편 요약
동시성의 필요성
만약 CPU가 하나의 프로그램만을 실행할 수 있다면, I/O 작업이 발생할 때 CPU는 유휴 상태가 됩니다. 이는 컴퓨팅 자원 활용의 효율성을 떨어뜨리게 됩니다. 이를 해결하기 위해 동시성 개념이 필요합니다.
코어와 스레드
코어는 물리적인 처리 장치로, 여러 코어가 있는 경우 각각 병렬적으로 작업을 수행할 수 있습니다. (하드웨어로서) 스레드는 코어 내부의 논리적인 실행 단위로, 하나의 코어에 여러 스레드를 둘 수 있습니다.
동시성과 병렬성
동시성은 여러 프로그램을 실행할 수 있는 시스템의 특성으로, 병렬성과 병행 처리를 통해 달성할 수 있습니다.
병렬성은 여러 작업이 같은 시점에 실행되는 방식으로, 멀티 코어가 필요합니다. 병행 처리는 여러 작업이 짧은 시간 간격으로 번갈아 실행되어 동시에 진행되는 것처럼 보이는 방식으로, 싱글 코어에서도 여러 개의 스레드를 두면 달성 가능합니다. 병렬성을 달성하였다는 것은 곧 동시성을 달성한 것이지만, 그 역은 항상 성립하는 것은 아닙니다.
멀티태스킹
동시성의 원리에 따라 멀티태스킹을 구현할 수 있는데, 이는 여러 프로그램이 짧은 시간 간격으로 번갈아 실행되도록 하는 기법입니다.
선점형 멀티태스킹은 운영체제가 각 작업에 시간 슬라이스를 할당하여 직접 각 작업의 실행을 관리합니다. 반면 비선점형(협력적) 멀티태스킹은 각 작업이 자발적으로 제어권을 양보해 가며 동시성을 달성하는데, 코루틴에서 이 원리를 활용하고 있습니다.
프로세스
프로세스는 실행 중인 프로그램이다.
프로그램을 실행하기 위해서는 CPU와 메모리가 필요하다.
자원의 독립성
각 프로세스는 독립적인 메모리 공간을 할당받는다.
프로세스끼리는 자원의 독립성이 보장됩니다.
각 프로세스는 자신의 메모리 공간과 시스템 자원을 독립적으로 사용하며, 한 프로세스는 다른 프로세스의 메모리 자원에 직접 접근할 수 없습니다. 이러한 독립성 덕분에 프로세스는 다른 프로세스의 실행에 영향을 받지 않으며, 다른 프로세스에도 영향을 미치지 않습니다.
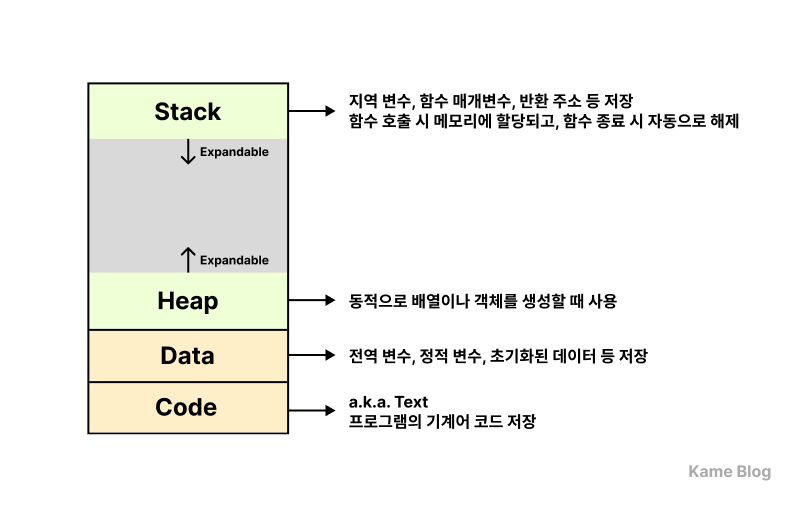
각 프로세스는 코드(Code), 데이터(Data), 힙(Heap), 스택(Stack)의 네 가지 주요 영역으로 구성된 독립적인 메모리 공간을 할당받습니다.
프로세스끼리 어떻게 동시성을 구현하는가?
운영체제 차원에서 프로세스의 메타데이터를 관리하기 위해 프로세스 별로 PCB(Process Control Block)를 둔다.
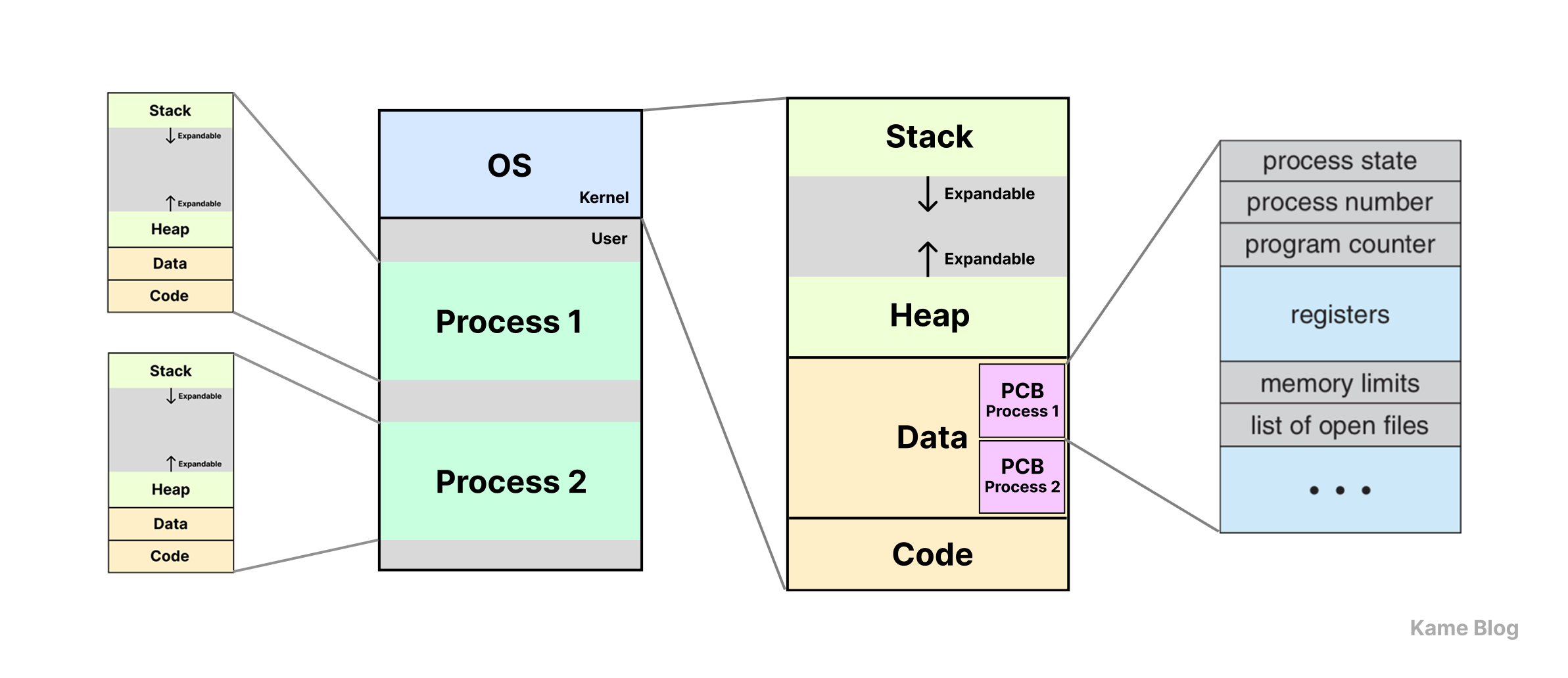
운영체제는 프로세스의 메타데이터를 관리하기 위해 각 프로세스마다 PCB(Process Control Block)를 만들어 사용합니다. PCB는 프로세스의 상태, ID, 우선순위, 메모리 관리 정보, 프로그램 카운터 (Program Counter) 등 중요한 정보를 포함합니다.
동시성을 달성하기 위해서는 여러 프로세스가 CPU에서 실행될 수 있도록 운영체제의 스케줄링이 필요합니다. 운영체제는 프로세스 간의 스케줄링을 통해 CPU를 할당하고, 각 프로세스의 실행 맥락을 보존합니다. 운영체제에서 PCB가 이러한 맥락을 저장하는 역할을 합니다.
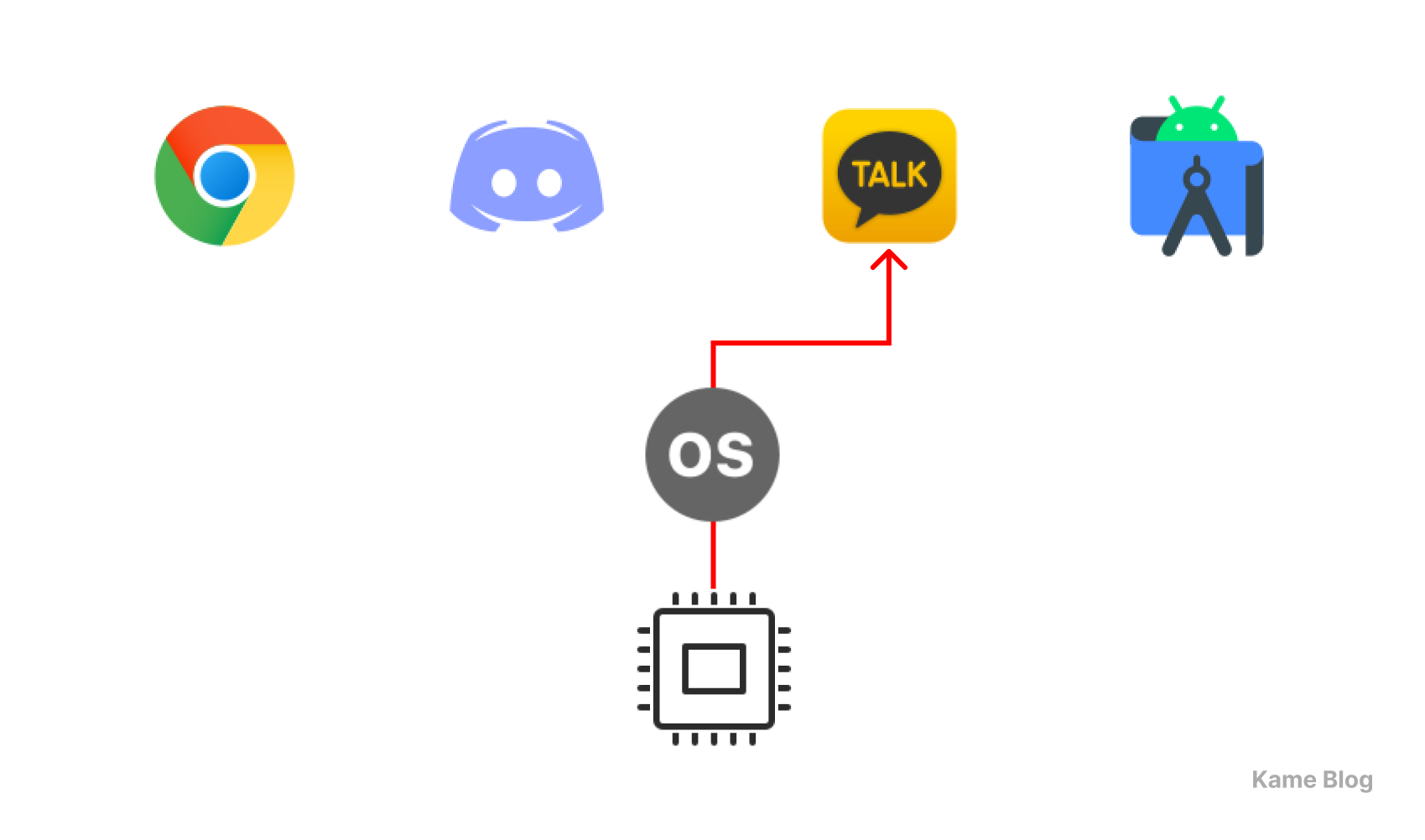
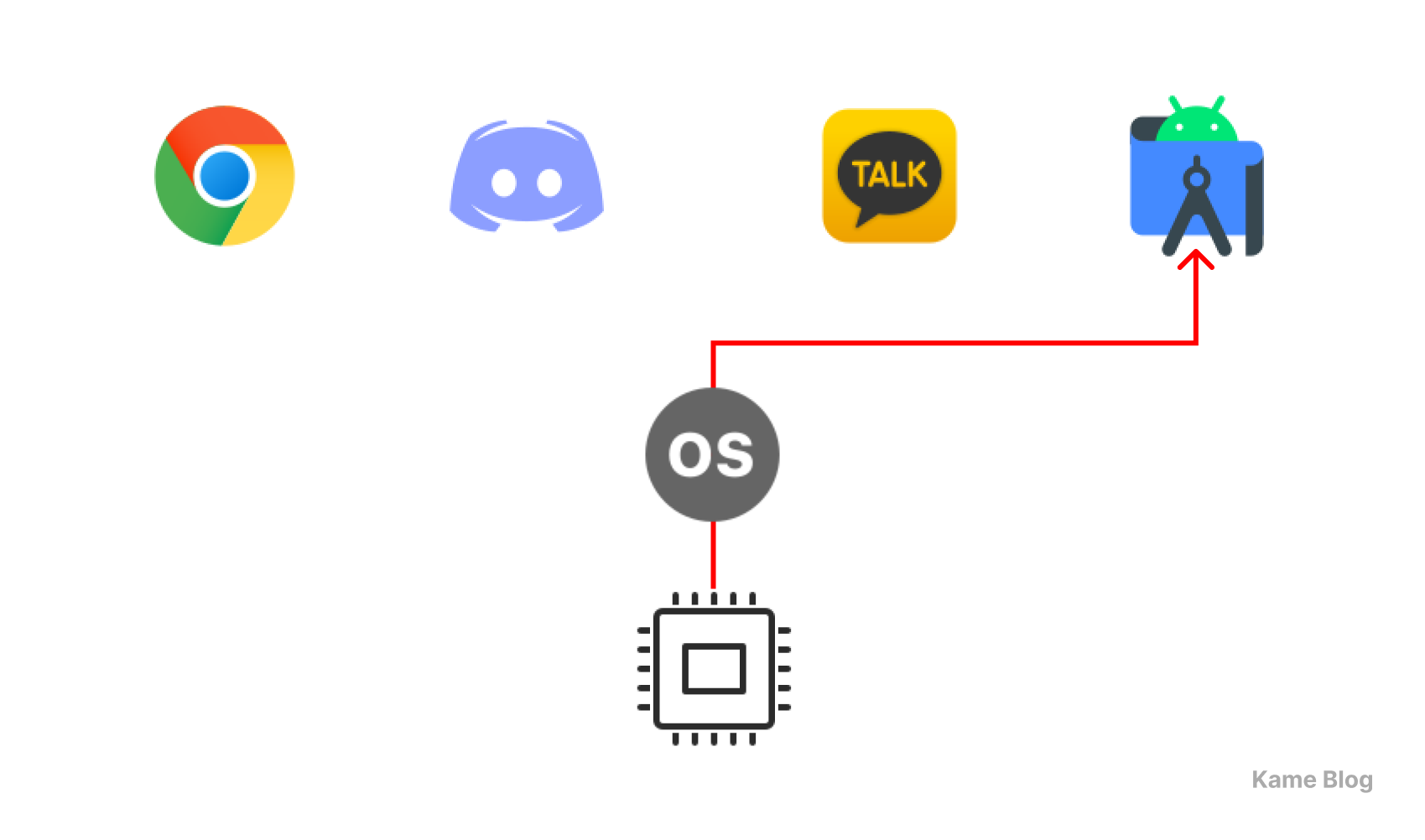
PCB에서 보유하는 여러 실행 맥락 정보들 중, 프로그램 카운터 (Program Counter)는 다음으로 실행되어야 할 명령어의 주소를 저장합니다. 이것이 동시성을 이룰 수 있도록 하는 핵심 요소입니다. 여러 프로세스를 하나의 CPU에 병행 처리하는 과정에서 프로세스가 중단되었다가 다시 실행될 때, 중단 지점에서부터 다시 시작할 수 있도록 하기 때문입니다.
이러한 원리에 따라, 아래 그림과 같은 모습으로 하나의 CPU를 활용해(코어 수에 상관 없이) 여러 프로그램을 실행할 수 있는 것입니다.
 |
 |
 |
 |
이 과정이 빠르게 진행되면 아래와 같이 동시에 네 작업이 실행되는 것처럼 보이게 될 것입니다.
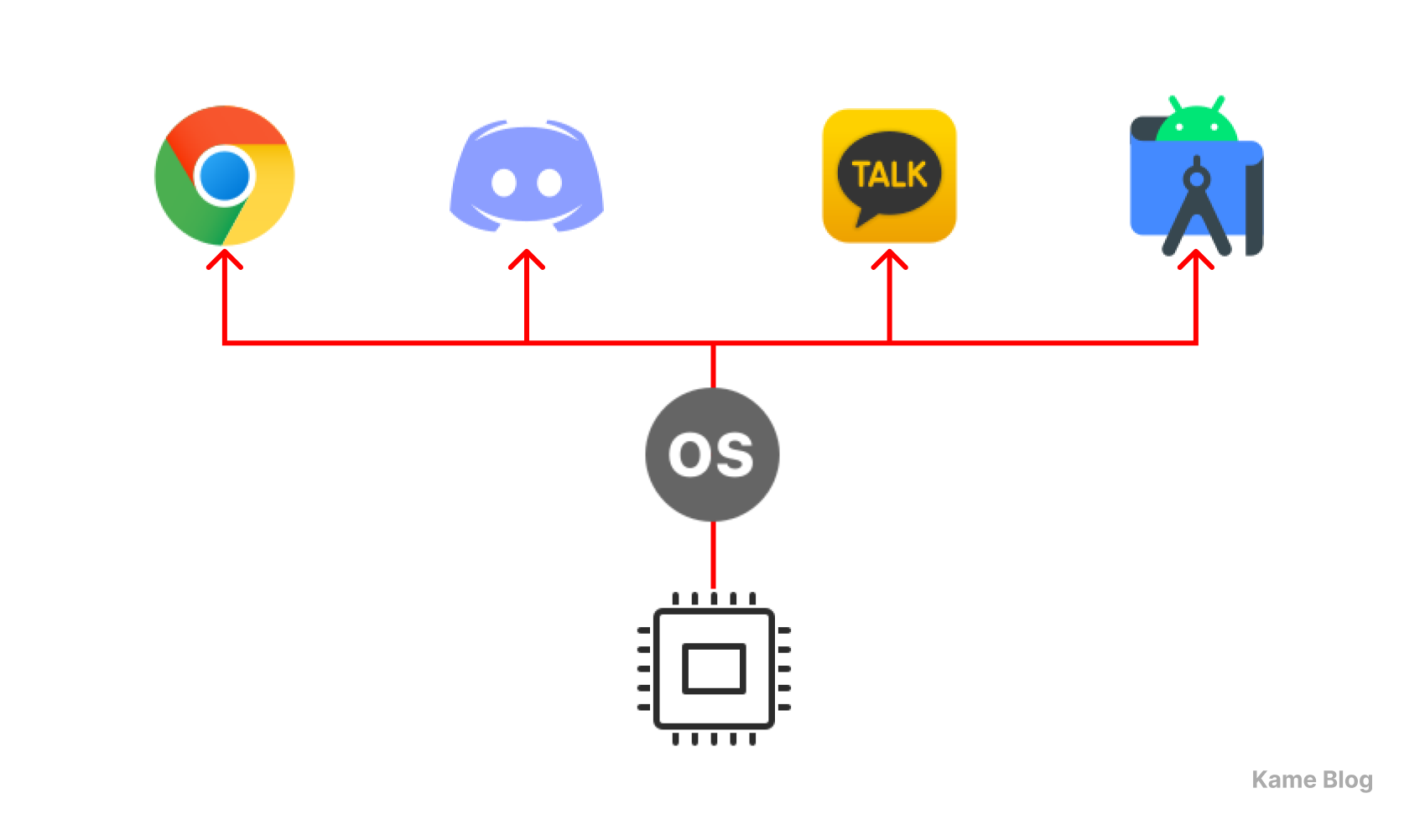
전통적인 프로세스는 하나의 실행 흐름(작업 단위)을 가지고 있습니다. 프로세스 내부 차원에서는 하나의 작업만을 수행할 수 있습니다. 이러한 프로세스에서 I/O 작업을 수행 시 프로세스가 대기 상태로 전환되며, 프로세스 차원에서 다른 작업을 수행할 수 없습니다.
스레드
⚠️ 본 편에서는 코어의 스레드가 아니라, 프로세스에 속해 있는 소프트웨어 스레드를 설명합니다.
스레드의 필요성
한 개의 프로세스 내부에서도 동시성을 구현하려면?
스레드는 프로세스(프로그램) 내의 실행 단위
지난 글과 앞선 내용을 통해, 동시성을 활용하면 하나의 CPU만으로 여러 프로세스를 실행할 수 있음을 확인했습니다. 여기서 더 나아가 컴퓨팅 자원을 더 효율적으로 다룰 수 있는 방법을 알아보도록 하겠습니다.
예를 들어, Melon 같은 음원 공유 프로그램을 만든다고 가정해 보겠습니다.
특정 음원에 접근하면, 일반적으로 앨범 커버 사진을 확인하고 음악을 재생할 수 있습니다. 이 데이터들을 받아오는 기능들을 코드로 구현하면 다음과 같습니다.
fun loadMusic() {
println("🎵 음악 로딩 중...")
// n초 동안 음악 로딩
println("🎵 음악 로딩 완료")
}
fun loadImage() {
println("🖼️ 이미지 로딩 중...")
// m초 동안 이미지 로딩
println("🖼️ 이미지 로딩 완료")
}일반적으로 사용자들은 이러한 작업들이 동시에 이뤄지길 기대합니다. 즉 여러 다른 프로세스들을 동시에 실행시키는 것처럼, 하나의 프로세스 내부에서도 여러 실행 단위를 동시에 실행하고 싶은 경우가 많을 것입니다.
하지만 아래의 프로그램를 실행하면, 이 작업들은 순차적으로 수행될 것입니다.
fun main() {
loadMusic()
loadImage()
println("✅ 모든 작업 완료")
}🎵 음악 로딩 중...
(...n초 대기...)
🎵 음악 로딩 완료🖼️ 이미지 로딩 중...
(...m초 대기...)
🖼️ 이미지 로딩 완료✅ 모든 작업 완료
이 프로세스가 전통적인 단일 실행 흐름만을 가진 프로세스라고 가정해 보겠습니다. 한 프로세스는 하나의 Program Counter만 활용하므로, 해당 프로세스가 CPU를 점유할 때는 하나의 실행 흐름(작업)만 진행할 수 있습니다.
즉, 위 코드에서는 loadMusic()이 실행되는 동안 다음 명령어는 실행될 수 없으며, 음악 로딩이 완료된 후에야 loadImage()가 실행됩니다.
현재 조건에서, 하나의 프로그램 내부에서는 기능들이 순차적으로 실행될 수밖에 없습니다. 따라서 한 프로그램이 특정 작업을 수행하는 동안에는 다른 작업을 처리하지 못하는 문제가 존재합니다.
이를 해결할 수 있는 방법이 스레드(Thread)를 활용하는 것입니다.
❓ 여러 프로세스로 만들면 안 되나?
여러 기능들을 서로 다른 프로세스로 실행시키고, 그것들끼리 데이터를 주고 받도록 하면 어떨까?
각각의 실행 단위를 독립적인 프로세스로 실행하는 방식으로도 동시성을 구현할 수는 있습니다.
이 과정에서 프로세스 간 데이터 교환을 위해, IPC(Inter-Process Communication, 프로세스 간 통신)를 활용할 수 있습니다. IPC를 구현하기 위해, 파이프, 공유 메모리, 메시지 큐, 소켓 등을 활용할 수 있습니다. (각 구현 수단은 자세히 다루지 않겠습니다.)
앞선 예시의 음원 로딩 기능과 이미지 로딩 기능을 각각 독립적인 프로세스로 분리하고, 메인 프로세스가 두 프로세스와 데이터를 주고받도록 시스템을 변경해 보겠습니다.
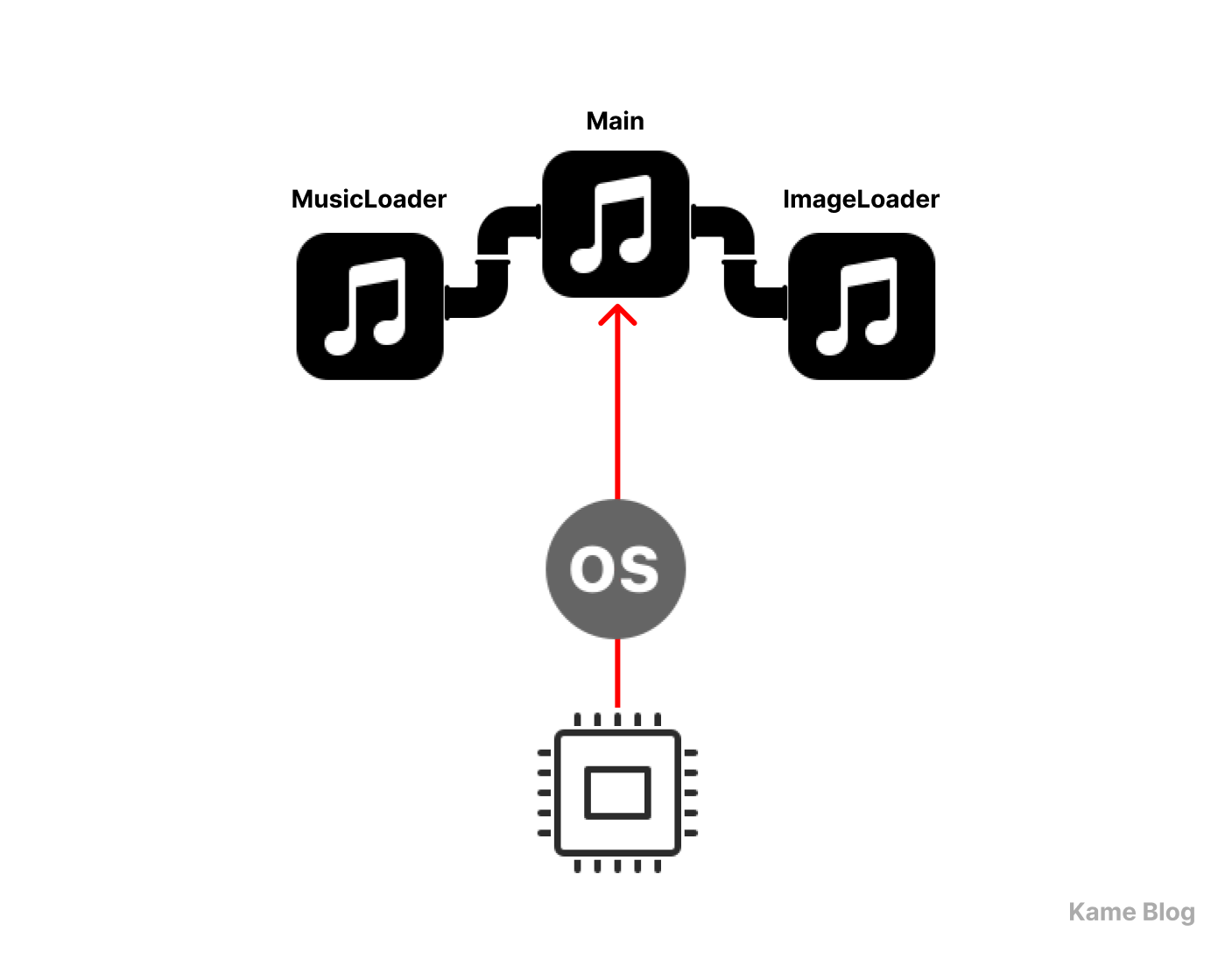
💡 IPC를 활용한 예시
표준 입출력을 활용해 파이프 방식의 IPC를 구현해보도록 하겠습니다.
 |
 |
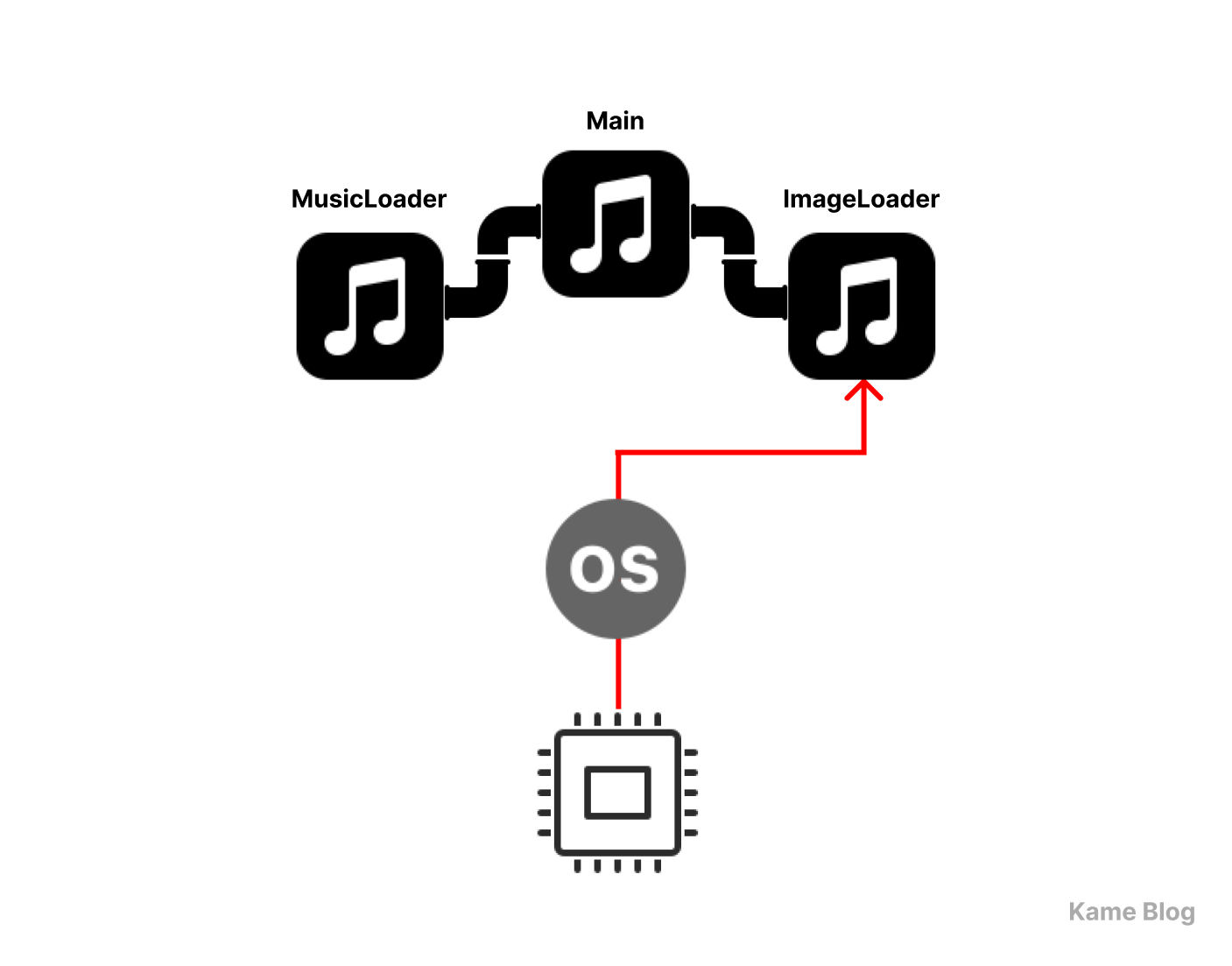 |
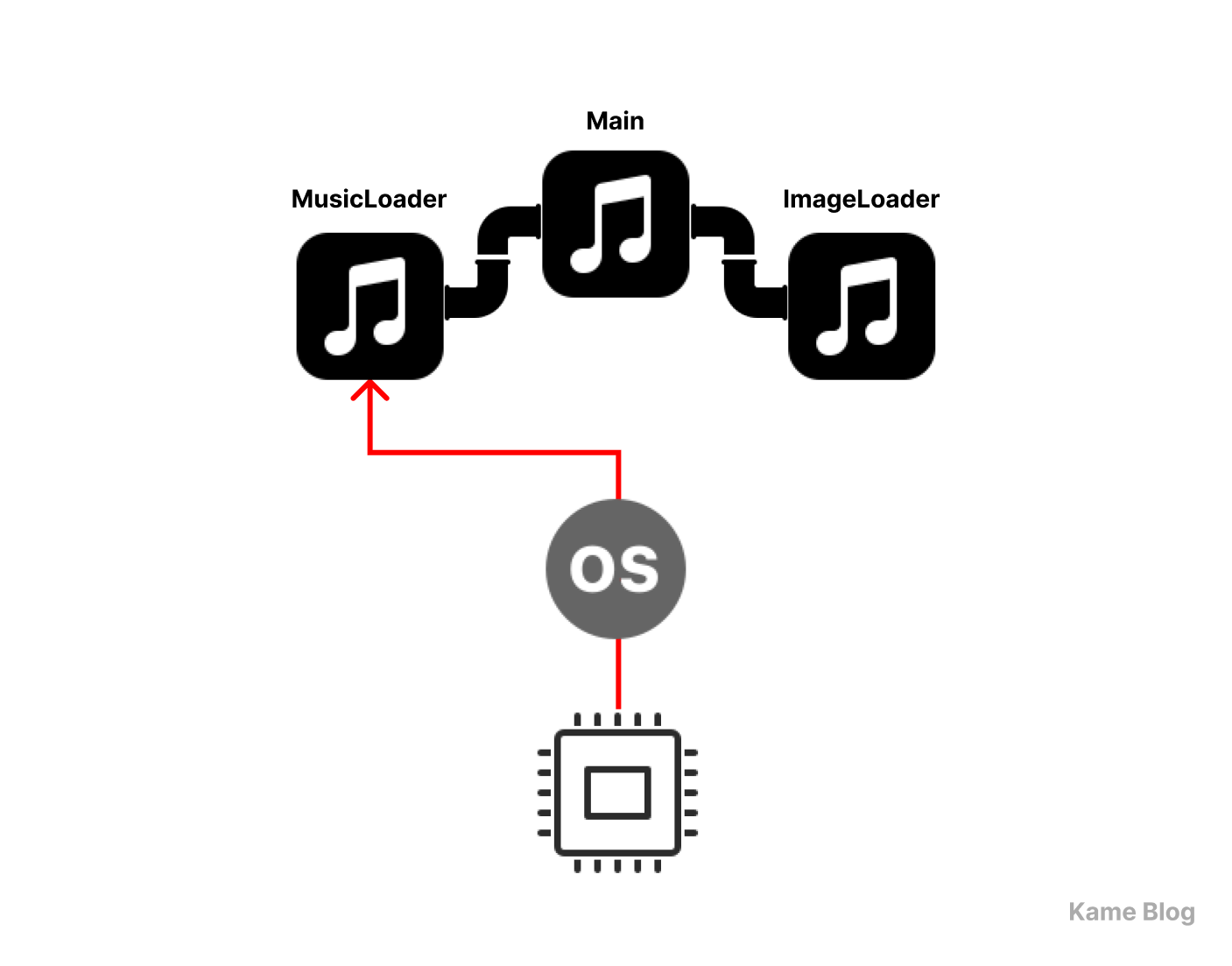
1️⃣ 메인 프로세스가 음악 로딩 프로세스와 이미지 로딩 프로세스를 생성하여 실행
2️⃣ 각 프로세스는 독립적으로 실행되며, 완료되면 메인 프로세스에 결과를 전달
src > musicplayer > MusicLoader.kt : 음악 로딩 전용 프로세스
package musicplayer
fun main() {
println("🎵 음악 로딩 중...")
// 로딩
Thread.sleep(5000)
println("🎵 음악 로딩 완료")
}src > musicplayer > ImageLoader.kt : 앨범 커버 로딩 전용 프로세스
package musicplayer
fun main() {
println("🖼️ 이미지 로딩 중...")
// 로딩
Thread.sleep(3000)
println("🖼️ 이미지 로딩 완료")
}src > musicplayer > Main.kt : 메인 프로세스
package musicplayer
fun main() {
// 별도의 프로세스로 분리
val musicProcess = ProcessBuilder("java", "-cp", "out/production/프로젝트명", "musicplayer.MusicLoaderKt")
.redirectOutput(ProcessBuilder.Redirect.INHERIT) // 표준 출력 상속 (즉시 출력)
.start()
val imageProcess = ProcessBuilder("java", "-cp", "out/production/프로젝트명", "musicplayer.ImageLoaderKt")
.redirectOutput(ProcessBuilder.Redirect.INHERIT)
.start()
// 모든 프로세스 종료 대기
musicProcess.waitFor()
imageProcess.waitFor()
println("✅ 모든 작업 완료")
}실행 결과
멀티 프로세스 환경에서 채택할 수 있는 동시성을 활용하여, 여러 기능들을 동시에 실행할 수 있었습니다.
🎵 음악 로딩 중...
🖼️ 이미지 로딩 중...(...약 3초...)
🖼️ 이미지 로딩 완료(...약 5초...)
🎵 음악 재생 완료✅ 모든 작업 완료
😕 한계점
현재 예시에서, IPC를 적용하는 것이 바람직한가?
다른 기능들이 추가될 때마다 프로세스를 추가하는 것이 괜찮은 선택인가?
앞선 설명에서, 프로세스는 자원의 독립성이 보장된다고 하였습니다.
따라서 한 서비스에서 사용될 여러 작업들을 여러 프로세스로 분리하면, 한 프로세스가 다른 프로세스의 실행에 영향을 미치지 않음을 보장할 수 있습니다. 그러나 이러한 방식에는 아래와 같은 비효율적인 요소들도 존재합니다.
-
프로세스 생성 비용
운영체제에서 프로세스를 생성할 때는 새로운 주소 공간을 할당하고, 프로세스 제어 블록(PCB, Process Control Block)을 초기화하는 등의 작업이 필요
-
프로세스 간 상태 동기화
각 프로세스는 독립적인 메모리 공간을 가지기 때문에, 데이터를 공유하기 위해 IPC를 사용하는 과정에서 추가적인 동기화 비용과 데이터 전송 오버헤드 발생 -
컨텍스트 스위칭(Context Switching) 비용
동시성을 실현하는 과정에서 CPU는 현재 실행 중인 프로세스의 상태를 저장하고 새로운 프로세스의 상태를 로드하는 작업을 반복
이 단점들을 고려했을 때, 현재 예시처럼 한 프로그램 내에서 음원과 이미지 로딩을 동시에 실행하기 위해 각 기능들을 프로세스로 분리하여 생성하고 IPC를 적용하는 것은 과도한 방법이라 할 수 있습니다.
🥸 생각해보기
어떤 상황에서 IPC를 적용하는 것이 좋을까?
❗️ 프로세스 내에 스레드를 두자!
코어에 스레드를 두는 것처럼, 프로세스에도 자원을 공유하는 여러 실행 단위를 두어 효율적으로 활용하는 것은 어떨까?
스레드는 프로세스 내부에서 실행되는 작업 단위입니다. 코어에 여러 스레드를 두어 더 효율적인 처리를 진행할 수 있듯, 프로세스에서도 여러 스레드를 활용하여 자원을 보다 효율적으로 활용하며 여러 작업을 동시에 수행할 수 있습니다.
🤔 왜 스레드가 더 효율적인가?
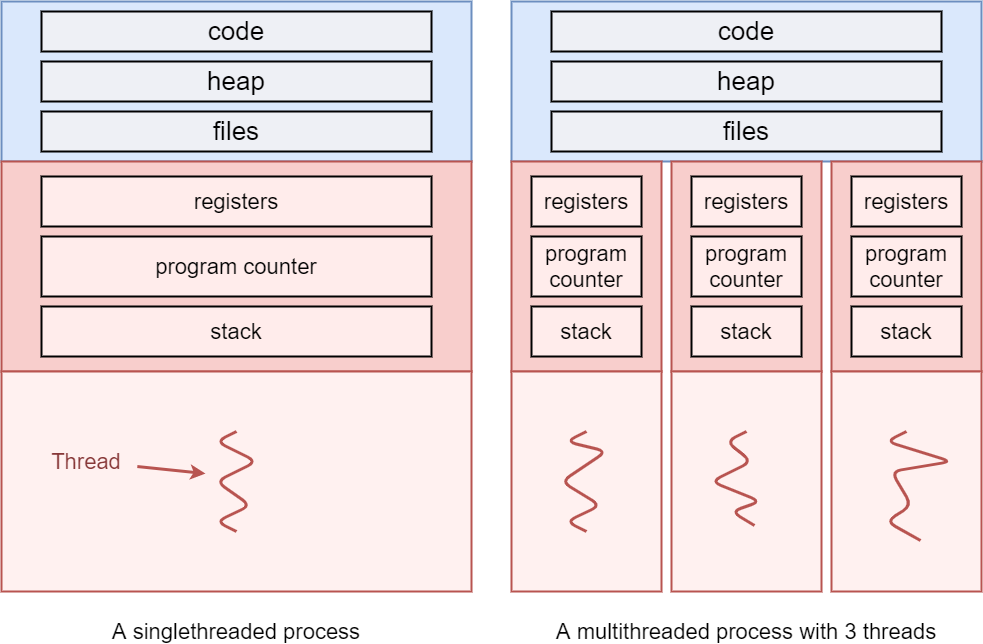
스레드끼리 프로세스의 가용 자원을 공유하기 때문입니다.
-
프로세스
자신만의 메모리 공간을 할당받으며, 독립적인 리소스 관리 필요 -
스레드
같은 프로세스 내에서 실행되면서 프로세스의 메모리 공간(코드, 데이터, 힙 영역)을 공유하되, 스택은 각 스레드 별로 보유
따라서 프로세스를 여러 개 만들어 동시성을 구현했을 때의 오버헤드를 극복할 수 있습니다.
프로세스보다 상대적으로 용이한 데이터 공유, 빠른 실행 및 문맥 교환 가능!
위의 예시에서는 2개의 기능만이 존재하여 실행 시간에 큰 차이가 존재하지 않습니다. 하지만 수많은 프로세스를 생성하는 것과 스레드를 생성하는 것에는 큰 차이가 존재합니다.
아래 예시에서는 100개의 프로세스와 100개의 스레드를 실행시켰을 때의 소요 시간 차이를 계산하고 있습니다. 동시에 실행하고자 하는 작업의 수가 많아지면 확연한 차이가 존재함을 확인할 수 있습니다.
프로세스 100개 생성 시
HeavyTask.kt
package musicplayer
fun main() {
val sum = (1..1_000_000).sum()
}Main.kt
package musicplayer
fun main() {
val startTime = System.currentTimeMillis()
val processes = List(100) {
ProcessBuilder("java", "-cp", "out/production/프로젝트명", "musicplayer.HeavyTaskKt")
.redirectOutput(ProcessBuilder.Redirect.INHERIT) // 표준 출력 상속 (즉시 출력)
.start()
}
processes.forEach { it.waitFor() }
val endTime = System.currentTimeMillis()
println("✅ 프로세스 방식 실행 완료")
println("⏱ 실행 시간: ${endTime - startTime} ms")
}스레드 100개 생성 시
Main.kt
package musicplayer
fun main() {
val startTime = System.currentTimeMillis()
val threads = List(100) {
thread {
heavyTask() // 동일한 연산 수행
}
}
threads.forEach { it.join() } // 모든 스레드가 끝날 때까지 대기
val endTime = System.currentTimeMillis()
println("✅ 스레드 방식 실행 완료")
println("⏱ 실행 시간: ${endTime - startTime} ms")
}
fun heavyTask() {
val sum = (1..1_000_000).sum()
}✅ 프로세스 방식 실행 완료
⏱ 실행 시간: 4443 ms
✅ 스레드 방식 실행 완료
⏱ 실행 시간: 536 ms
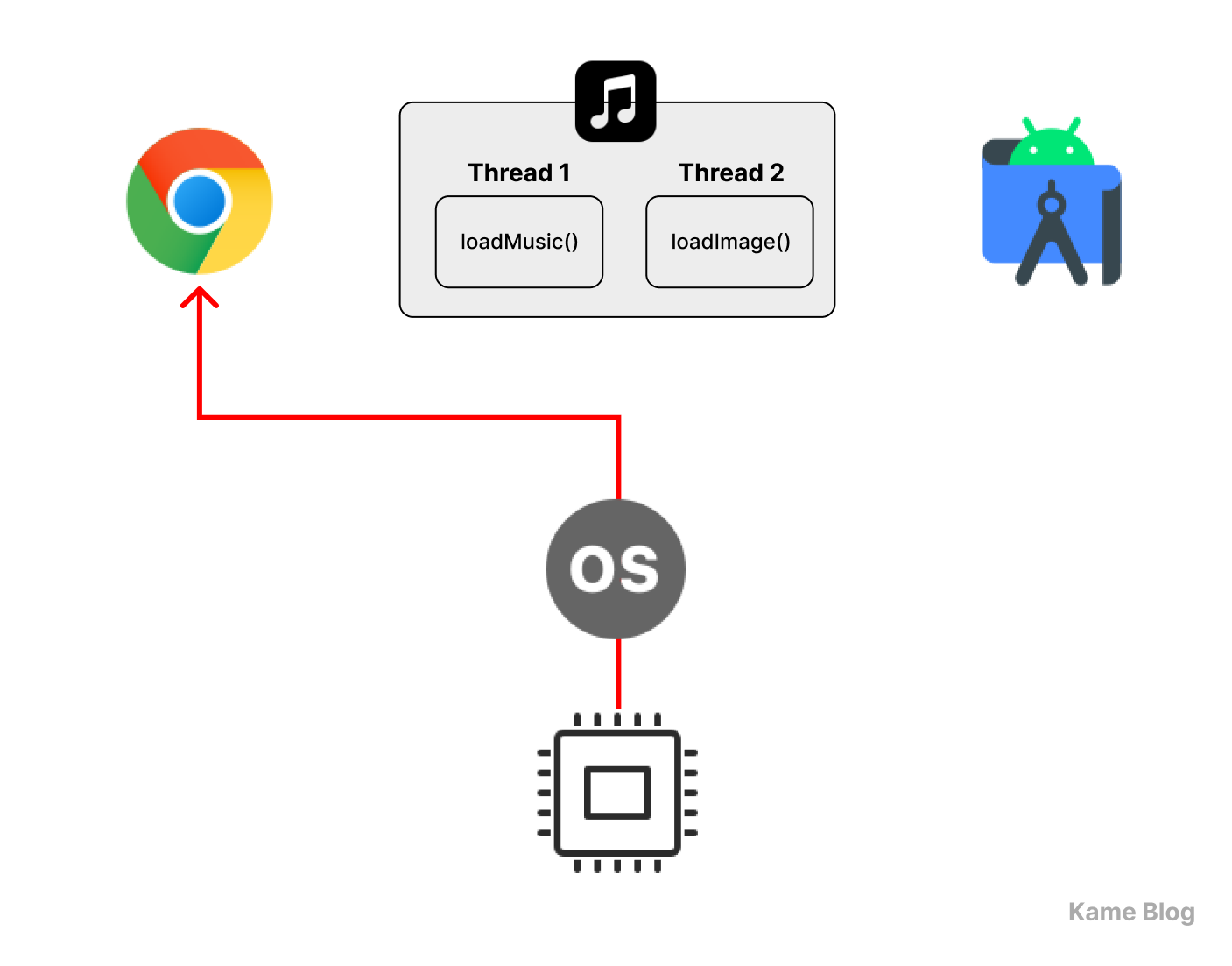
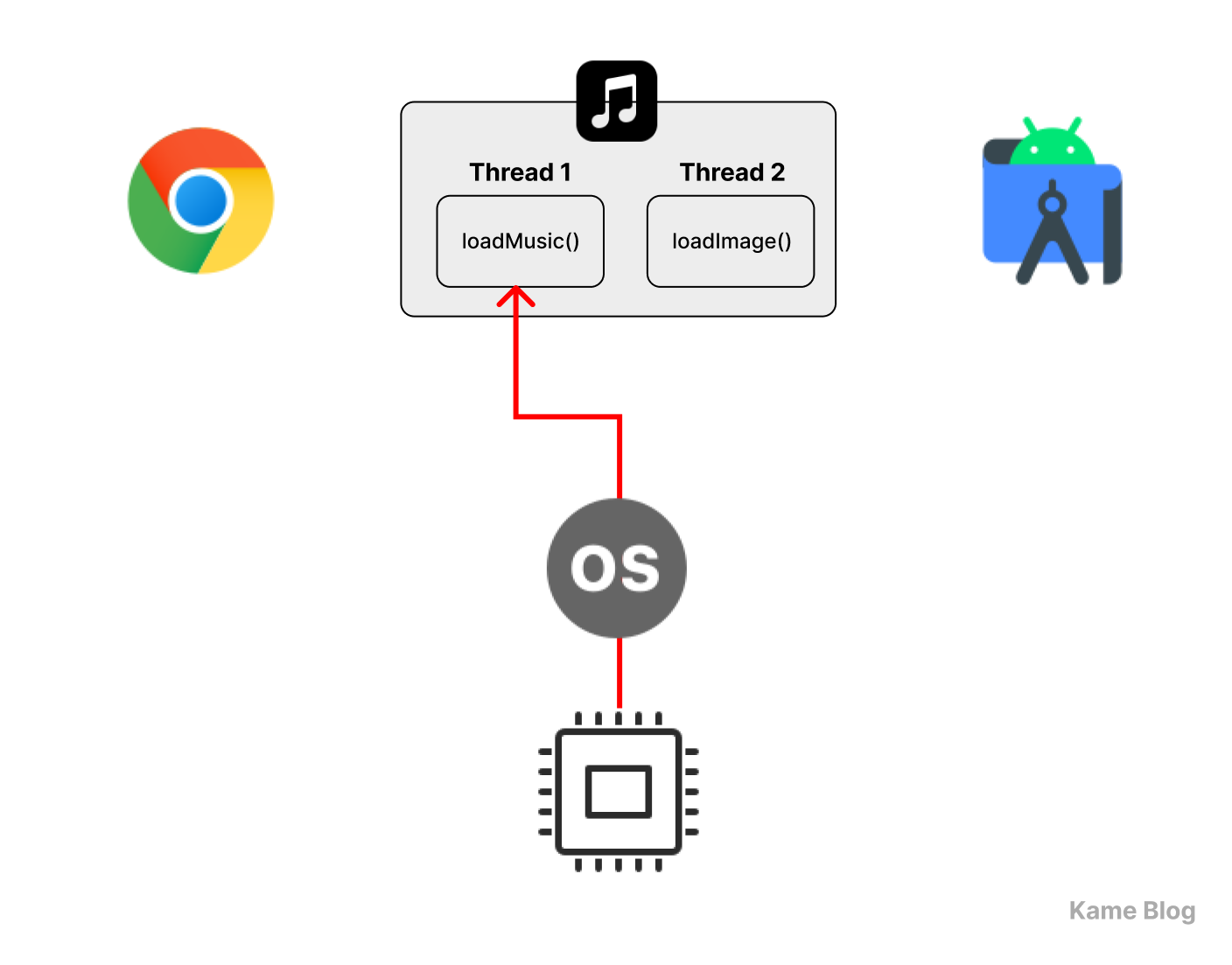
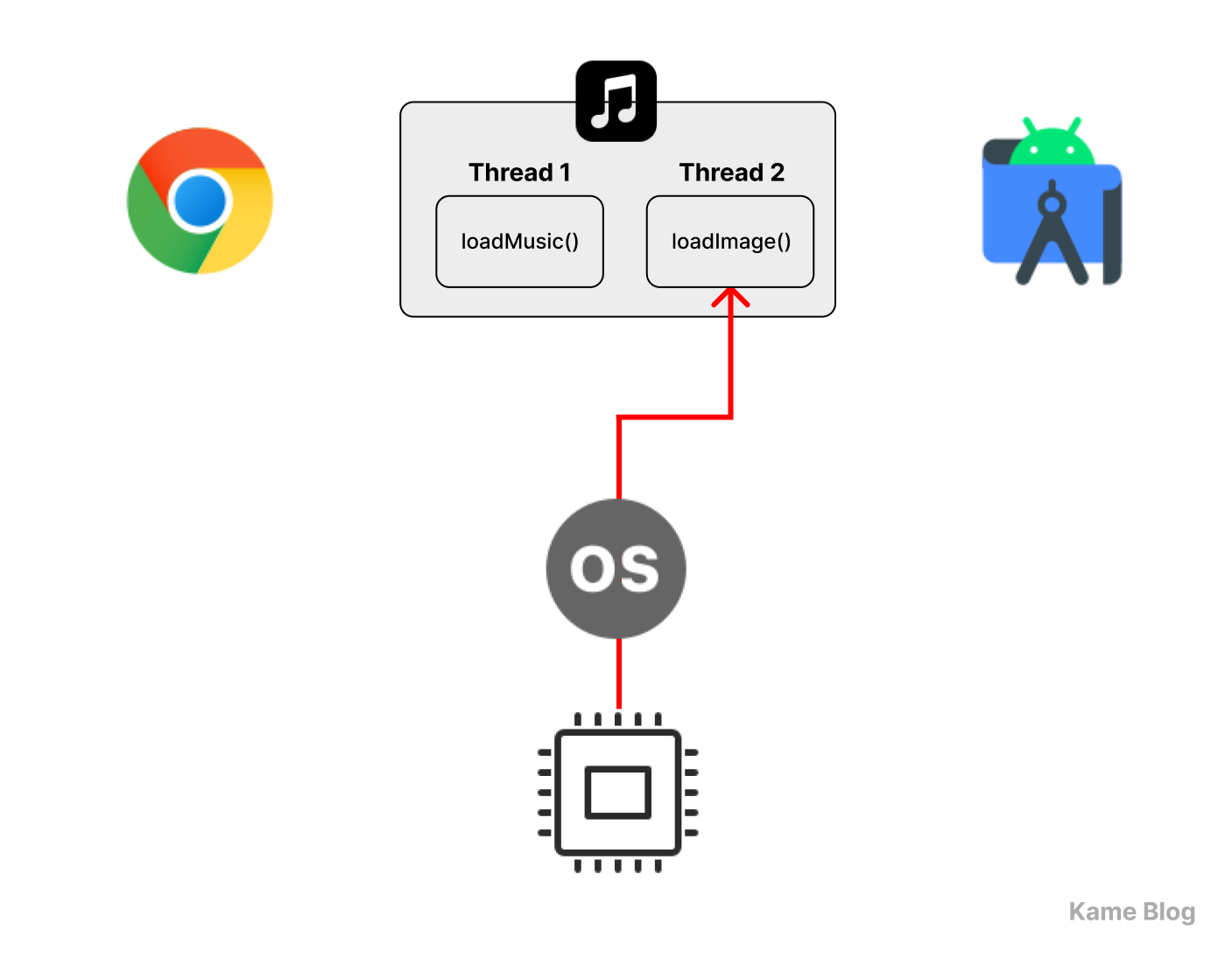
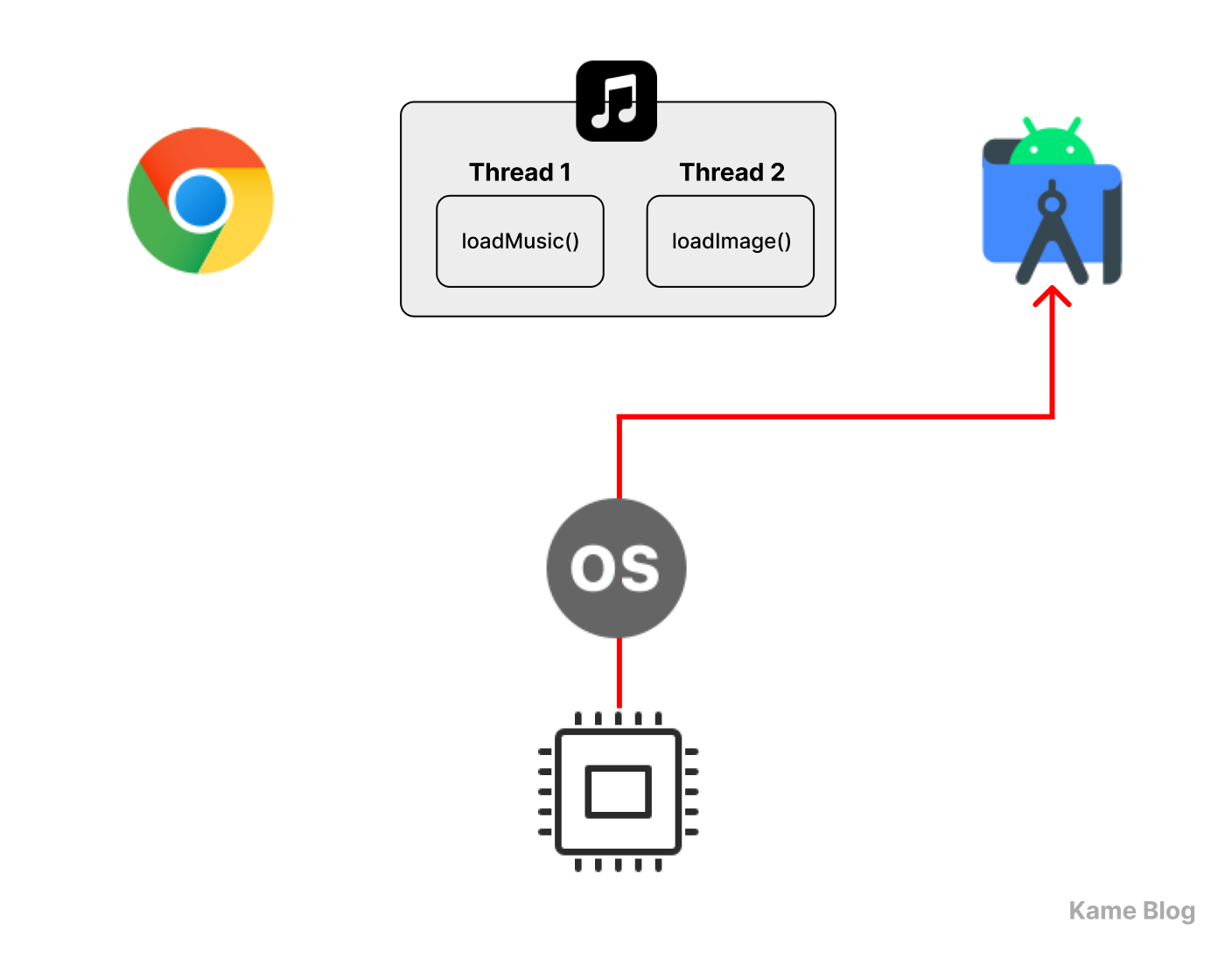
스레드끼리 어떻게 동시성을 구현하는가?
스레드는 각자 스택을 가지며, 각자 Program Counter(PC)를 관리한다!
다중 스레드를 적용하면, 하나의 스레드 상에서 동작하는 작업이 중지되더라도, 프로세스를 멈추지 않고 다른 작업을 실행할 수 있다!
스레드가 각자의 스택을 가진다는 것은 동시성 구현에 중요한 요소입니다.
스택은 함수 호출 시 지역 변수, 매개변수, 리턴 주소 등을 저장하는 역할을 합니다. 만약 스레드 간 스택이 공유된다면, 하나의 스레드가 다른 스레드의 데이터를 덮어쓰는 문제가 발생할 것입니다.
스레드는 각자의 스택을 가지고 있기에, 프로세스에 여러 스레드가 실행된다고 하더라도 실행 흐름이 독립적으로 유지될 수 있습니다. 또한 특정 스레드의 실행이 멈추더라도, 프로세스가 종료되지 않았다면 스택 정보는 메모리에 그대로 보존됩니다.
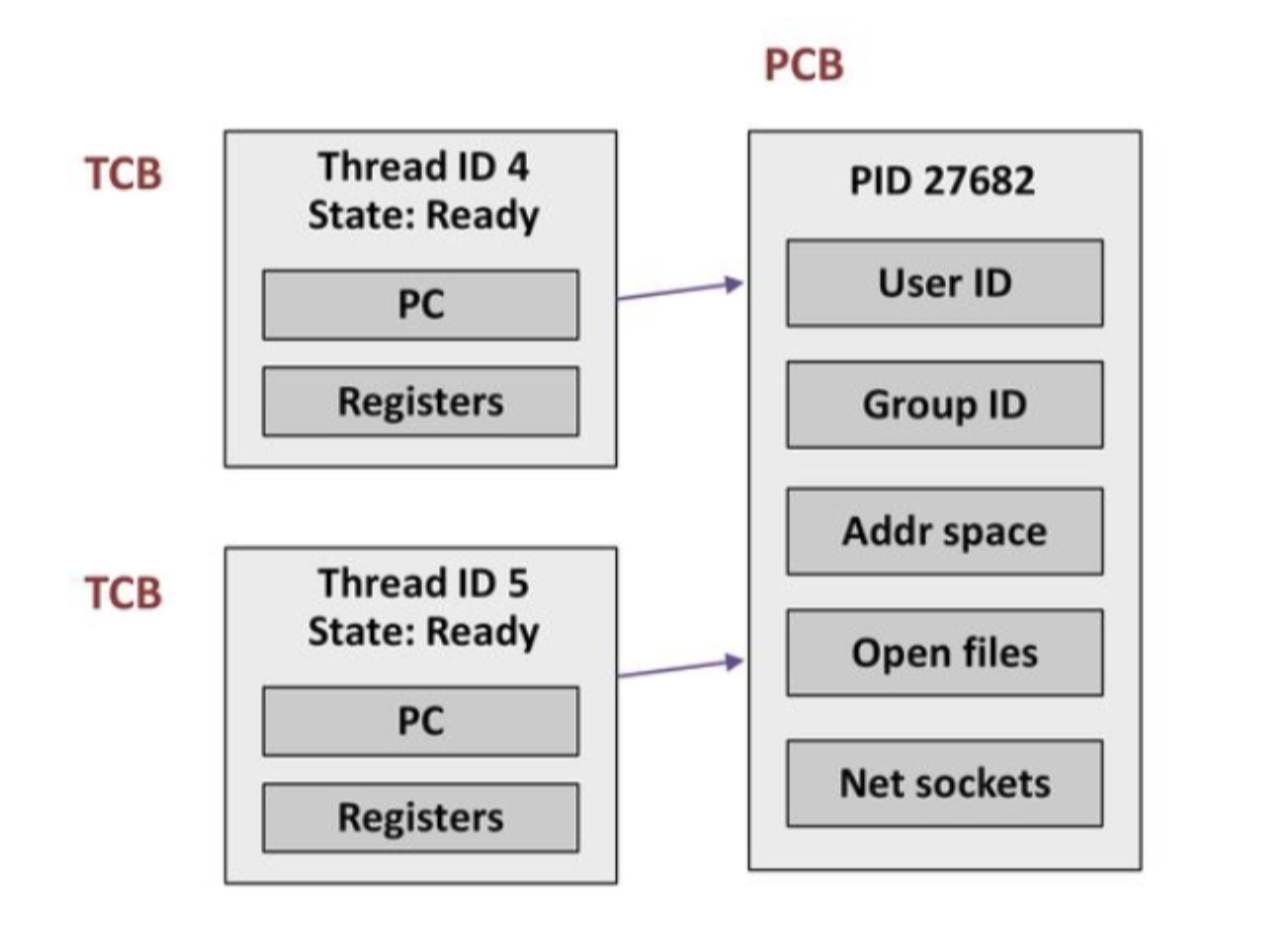
또한 프로세스가 PCB를 가지듯, 스레드도 TCB(Thread Control Block, 스레드 제어 블록)을 가집니다. TCB에는 해당 스레드의 실행 정보가 저장되는데, 그 중 하나가 PC(Program Counter)입니다. 따라서 각 스레드는 실행을 멈추더라도, 스레드가 재개될 때 자신의 실행 흐름을 그대로 이어갈 수 있습니다.
이러한 특성들 덕분에 멀티스레드 환경에서는 한 스레드가 블로킹되더라도, 다른 스레드는 계속 실행될 수 있는 것입니다. 이 원리를 통해 스레드를 활용하여 동시성을 달성할 수 있습니다.
 |
 |
 |
 |
💡 스레드를 활용한 예시
앞선 예시를 스레드를 활용하여 구현하겠습니다.
두 작업 단위를 별도의 스레드에서 동작하도록 하였습니다.
fun loadMusic() {
println("🎵 음악 로딩 중...")
Thread.sleep(5000) // 5초 동안 음악 로딩
println("🎵 음악 로딩 완료")
}
fun loadImage() {
println("🖼️ 이미지 로딩 중...")
Thread.sleep(3000) // 3초 동안 이미지 로딩
println("🖼️ 이미지 로딩 완료")
}
fun main() {
// 스레드 생성 + 실행
val musicThread = thread { loadMusic() }
val imageThread = thread { loadImage() }
// 모든 스레드가 종료될 때까지 대기
musicThread.join()
imageThread.join()
println("✅ 모든 작업 완료")
}결과는 앞선 프로세스 예시와 유사합니다. 하지만 별도의 프로세스를 생성할 때보다 훨씬 적은 오버헤드로 같은 목적을 달성했습니다.
🎵 음악 로딩 중...
🖼️ 이미지 로딩 중...(...약 3초...)
🖼️ 이미지 로딩 완료(...약 5초...)
🎵 음악 재생 완료✅ 모든 작업 완료
스레드 풀(Thread Pool)
스레드를 필요할 때마다 계속 만들기 보다, 재사용하는 것이 좋지 않을까?
앞선 예시에서는, 음원을 불러오는 기능과 앨범 커버 이미지를 불러오는 기능을 동시에 수행하기 위해 각각 thread 빌더 함수를 호출하여 두 개의 새로운 스레드를 생성했습니다.
val musicThread = thread { loadMusic() }
val imageThread = thread { loadImage() }이처럼 요청이 들어올 때마다 새로운 스레드를 생성하여 실행하는 방식을 Thread-Per-Request 방식이라고 합니다.
스레드는 프로세스보다 가벼운 실행 단위이지만, 사실 새로운 스레드를 생성하는 데도 많은 컴퓨팅 자원이 소모됩니다. 만약 많은 작업을 동시에 실행해야 한다면, 요청마다 스레드를 생성하는 시간과 비용이 추가로 발생하게 됩니다.
특히 처리 속도보다 요청이 더 빠르게 들어오는 상황에서는 다음과 같은 문제들이 발생할 수 있습니다.
-
CPU 오버헤드 증가
스레드 생성과 제거가 반복되면서 불필요한 CPU 자원 소모
너무 많은 스레드가 실행되면 CPU가 작업을 전환하는 데 오버헤드 발생 -
메모리 사용량 급증
많은 스레드가 동시에 실행되면서 메모리 자원 고갈
이 문제를 해결할 수 있는 방법이 스레드 풀(Thread Pool)을 도입하는 것입니다.
필요한 만큼 스레드를 미리 생성하여 재사용하는 방식으로, 스레드 생성 및 소멸에 따른 오버헤드를 줄일 수 있습니다.
아래 그림과 같이 6개의 스레드로 이뤄진 스레드 풀이 존재한다고 가정해 보겠습니다.
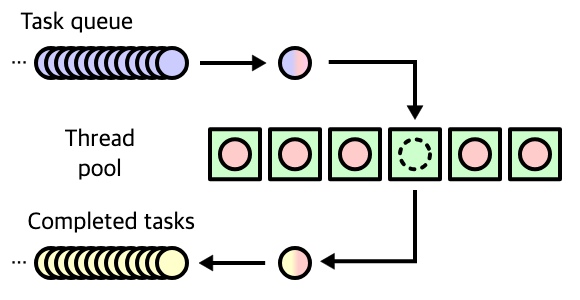
스레드 풀에 작업 요청이 들어오면 작업을 수행하고 있지 않는 특정 스레드가 해당 작업을 할당받게 됩니다. 만약 작업 요청이 사용 가능한 스레드 수를 초과하면 대기열(Queue)에 저장되며, 기존 작업이 완료된 후에야 새로운 작업이 실행될 수 있습니다.
따라서 작업 유형과 소요 시간을 고려하여, 대기 시간을 최소화할 수 있도록 최적의 스레드 풀 크기를 설정하는 것이 중요합니다. 일반적으로는 CPU 바운드 작업(예 : 복잡한 연산)과 I/O 바운드 작업(예 : 네트워크 통신, 데이터베이스 처리, 파일 읽기)을 위한 별도의 스레드 풀을 두며, 필요에 따라 다른 유형의 스레드 풀을 생성하여 사용할 수도 있습니다.
참고) CPU 바운드 작업을 위한 풀의 경우,
코어 수 또는 코어 수 + 1개 정도의 스레드 수가 적절합니다(하이퍼 스레딩이 적용된 경우 소프트웨어 스레드의 수 적용). 동시에 실행될 수 있는 작업의 수는 코어 수에 의해 제한되므로, 과도한 스레드를 생성하는 것은 오히려 성능 저하를 유발할 수 있습니다. 반면 보통 입출력 작업은 대기 시간이 길기에, I/O 작업 전용 풀에서는코어 수보다 훨씬 많은 스레드를 둡니다. 최적의 개수는 직접 경험해보며 찾아가야 합니다.
JVM에서 스레드 풀 사용하기
직접 Thread를 만들어 사용하는 대신, Executors / ExecutorService를 활용해 만들어진 스레드 풀에 작업만 전달한다.
JVM 환경에서 스레드 풀을 생성하는 대표적인 방법은 ExecutorService를 사용하는 것입니다.
ExecutorService는 Executor를 확장한 인터페이스로, 스레드 풀을 관리하고 실행된 작업의 종료, 결과 반환, 작업 스케줄링 등의 추가 기능을 제공합니다. 이를 통해 스레드 생성을 직접 다룰 필요 없이, 풀 내부에서 효율적으로 스레드를 재사용할 수 있습니다.
ExecutorService를 통해 스레드로 보낼 수 있는 작업이 될 수 있는 것들로 Runnable과 Callable이 있습니다. 이 글에서는 'Runnable은 반환값을 가질 수 없는 작업이고, Callable은 반환값을 가질 수 있는 작업이다' 정도로만 알아도 충분합니다.
public interface ExecutorService extends Executor {
// ...
void shutdown();
<T> Future<T> submit(Callable<T> task);
Future<?> submit(Runnable task);
// ...
}submit 함수를 통하여 작업을 실행할 수 있고, shutdown 함수를 통하여 새로운 작업을 받지 않고 기존 작업들이 완료되면 스레드 풀을 종료할 수 있습니다.
Executors 측에서는 스레드 풀을 생성하기 위한 여러 함수들을 제공하는데, 만약 고정된 크기의 스레드 풀을 만들고 싶다면 newFixedThreadPool에 스레드 개수를 매개변수로 넘겨 호출하면 됩니다.
// 사용 가능한 논리 코어 수
val cpuThreadPool = Executors
.newFixedThreadPool(Runtime.getRuntime().availableProcessors())
// 넉넉하게
val ioThreadPool = Executors.newFixedThreadPool(64) 아래 코드를 실행해보면, 스레드를 필요할 때마다 동적으로 생성하는 방식과는 다른 결과를 확인할 수 있습니다.
fun main() {
// 스레드 수가 6개인 스레드 풀
val ioThreadPool = Executors.newFixedThreadPool(6)
// 작업(Runnable) 12개를 큐에 전달
repeat(12) { index ->
ioThreadPool.submit { loadData(index + 1) }
}
// 모든 작업이 끝나고 더 받을 것이 없으면 스레드 풀 종료
ioThreadPool.shutdown()
}<데이터 1 ~ 6 무작위 순서> 로딩 중...
<데이터 1 ~ 6 무작위 순서> 로딩 완료
<데이터 7 ~ 12 무작위 순서> 로딩 중...
<데이터 7 ~ 12 무작위 순서> 로딩 완료
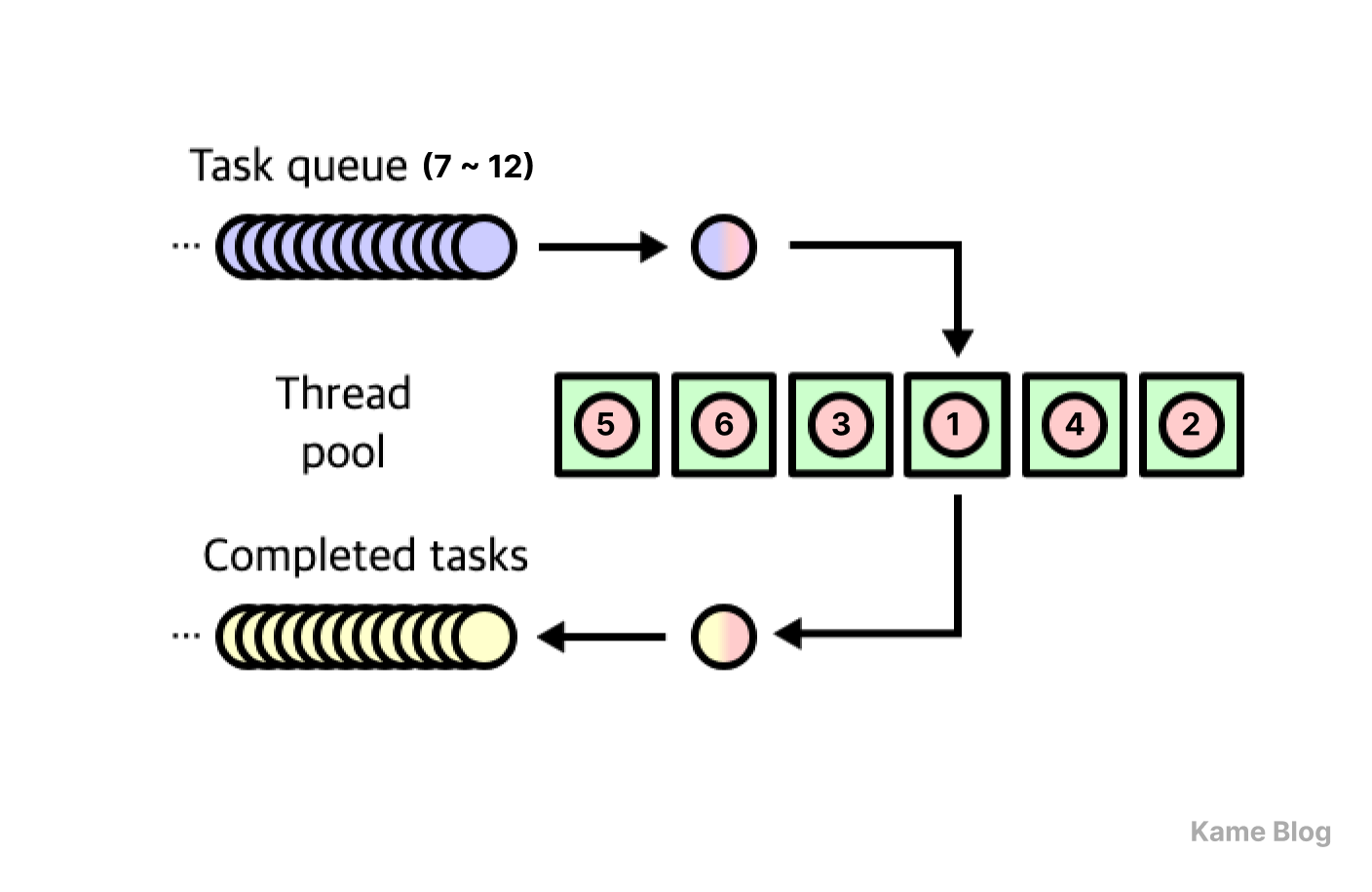
스레드 풀의 크기가 6으로 고정되어 있으므로, 초기에 6개의 작업만 실행되고 나머지 작업들은 대기열(여기서는 Blocking Queue)에 쌓였습니다. 먼저 실행된 6개의 작업이 하나씩 완료될 때마다 대기 중이던 나머지 6개의 작업이 하나씩 스레드 풀에 들어가 실행될 수 있었습니다.
이는 스레드 풀을 사용함으로써 스레드 생성 및 제거에 대한 오버헤드를 줄이는 대신, 작업이 즉시 실행되지 않고 대기해야 할 수도 있다는 점을 보여줍니다. 결국 스레드 풀을 사용할 때는 스레드의 수를 적절하게 결정하는 것이 중요합니다.
코루틴
이전 편의 내용을 토대로 코루틴의 특성을 되짚고 넘어가보겠습니다.
코루틴은 중단과 재개가 가능한 함수이며, 중단되더라도 실행 상태와 관련된 컨텍스트가 유지된다.
또한, 코루틴은 운영체제의 개입 없이 스스로 제어권을 넘긴다는 특징을 갖고 있다.
이러한 특성들 덕분에, 코루틴을 활용해 협력적 멀티태스킹(cooperative multitasking)을 구현할 수 있다.
이어질 내용에서는 '코루틴이 어떻게 만들어졌길래 서로 협력적으로 동작하며 동시성을 달성할 수 있는 것인지' 알아보도록 하겠습니다.
스레드와의 관계
코틀린 코루틴과 JVM의 스레드와의 관계를 중점적으로 살펴보며, 코루틴으로 어떻게 동시성을 구현하는지 살펴보도록 하겠습니다.
스레드 : 코루틴 = 실행할 곳 : 실행할 내용
코루틴은 스레드에서 실행되며, 실행 도중 다른 스레드로 옮겨다닐 수도 있다. 코루틴의 실행이 멈춘다고 해서 해당 스레드가 블록되는 것은 아니다.
코루틴은 스레드에서 실행된다
코'루틴'도 결국 함수다. 고로 코루틴은 스레드에서 실행된다.
코루틴에서 '루틴'은 쉽게 말해 '함수'와 같은 개념입니다.
루틴(Routine): 프로그램에서 특정 기능을 수행하는 코드 블록, 즉 함수서브루틴(Subroutine): 다른 함수(루틴)에 의해 호출당하는 함수- 코루틴끼리는 서로가 서로를 호출할 수 있는 상호 대칭적인 관계로, 코루틴은 서브루틴이 아님!
모든 루틴은 특정 스레드에서 동작합니다.
fun main() {
println("실행 스레드: ${Thread.currentThread().name}")
} 실행 스레드: main
그리고 코루틴도 결국 루틴이기 때문에 어느 스레드에선가 실행됩니다.
fun main() = runBlocking {
launch(Dispatchers.Default) {
println("실행 스레드: ${Thread.currentThread().name}")
}
}실행 스레드: DefaultDispatcher-worker-1
특정 시점에 하나의 스레드에서는 하나의 코루틴만 활성화될 수 있습니다. 즉, 코루틴을 활용한 동시성은 스레드 내부에서 여러 코루틴이 협력하며 실행을 양보(yield)하는 방식으로 이루어집니다. 이어질 내용에서 그 원리를 자세히 살펴보겠습니다.
코루틴은 특정 스레드에서만 실행되지 않는다
일반적인 루틴은 특정 스레드에서 실행되며, 실행이 끝날 때까지 같은 스레드에서 유지됩니다.
반면 코루틴은 실행을 일시 중단한 후, 실행 맥락을 유지한 채로 다른 스레드에서 재개될 수도 있습니다.
이러한 특성 덕분에 코루틴은 스레드 간 전환을 유연하게 처리할 수 있으며, 필요할 때 적절한 스레드에서 실행시킬 수 있습니다.
그렇다면, 특정 코루틴이 어떤 스레드 풀 혹은 어떤 스레드에서 실행되도록 할지 결정해주는 것이 필요할 것입니다.
스레드 풀과 디스패처
코틀린 코루틴에는 디스패처(Dispatcher)가 존재합니다.
디스패처는 코루틴이 어떤 스레드나 스레드 풀에서 실행될지 결정하는 역할을 합니다. 디스패처에 따라 스레드 풀을 내부적으로 관리할 수도 있고, 관리하지 않을 수도 있습니다.
스레드 풀을 관리하는 디스패처라면, 코루틴이 해당 디스패처 내부 스레드 풀의 유휴 스레드에서 실행되도록 합니다. 여기에 해당되는 대표적인 디스패처들은 다음과 같습니다.
- Dispatchers.Default : CPU 바운드 작업 전용 스레드 풀 관리
- Dispatchers.IO : IO 바운드 작업 전용 스레드 풀 관리
아래 코드에서는 서버로부터 음악 데이터를 가져오는 I/O 바운드 작업을 Dispatchers.IO에서 실행하고, 이후 복잡한 계산을 수행하는 CPU 바운드 작업을 Dispatchers.Default에서 실행합니다. 코틀린에서는 디스패처를 전환하기 위해 withContext() 메서드를 활용합니다.
fun loadMusic() =
CoroutineScope(Dispatchers.IO).launch {
// I/O 바운드 작업
val musicData = fetchMusicFromServer()
println(Thread.currentThread().name)
withContext(Dispatchers.Default) {
// CPU 바운드 작업
calculateMusicData(musicData)
println(Thread.currentThread().name)
}
}
private fun fetchMusicFromServer(): ByteArray {
return ByteArray(0)
}
private fun calculateMusicData(musicData: ByteArray) {
// calcaulate data
}디스패처는 스레드 풀을 관리하지 않을 수도 있습니다. 여기에 해당되는 디스패처들로는 다음과 같습니다.
- Dispatchers.Main : 안드로이드 프로그램 등의 UI 작업을 실행하기 위한 단일 스레드로 구성 (작업이
MainLooper로 전달되어 UI 스레드에서 실행되도록 예약되는 방식) - Dispatchers.Unconfined : 기본적으로 현재 스레드에서 실행되지만, 중지 후 재개될 때 컨텍스트에 따라 다른 스레드에서 실행될 수도 있음 (일반적으로 특정 스레드 (풀)에서 고정적으로 실행되는 것을 보장하지 않기 때문에, 예상치 못한 스레드에서 재개될 수 있음)
참고로, 개발자가 디스패처를 커스텀할 수도 있습니다.
코루틴에서 직접적으로 제공하는 기능을 사용하는 방식, ExecutorService를 통해 만든 스레드 풀을 코루틴 디스패처로 전환하는 방식을 활용할 수 있습니다.
-
코루틴에서 직접 제공하는 API 활용하기
-
newFixedThreadPoolContext(n, name)→ 디스패처가 지정된 스레드 개수로 이뤄진 스레드 풀을 가지도록 함Dispatchers.IO,Dispatchers.Default처럼 코루틴 라이브러리 측에서 제공하는 기본 공유 스레드 풀을 활용하지 않고, 별도의 스레드 풀을 만들어 사용newSingleThreadContext()→ 디스패처가 단일 스레드만 관리하도록 함
-
limitedParallelism(n)→ 디스패처의 최대 동시 실행 스레드 개수를 제한-
Dispatchers.IO.limitedParallelism(n)→ Dispatchers.IO는 기본적으로 최대 64개까지 스레드를 사용할 수 있지만, 필요하면 무제한 확장 가능. 따라서 limitedParallelism(n)을 적용하면 64개보다 많아질 수도 있고, 적어질 수도 있음 -
Dispatchers.Default.limitedParallelism(n)→ 기본적으로 CPU 코어 수만큼의 스레드를 유지하며, 이 개수를 초과할 수 없음. 따라서 limitedParallelism(n)을 적용하면 기본 개수보다 줄이는 것은 가능하지만, 늘리는 것은 불가능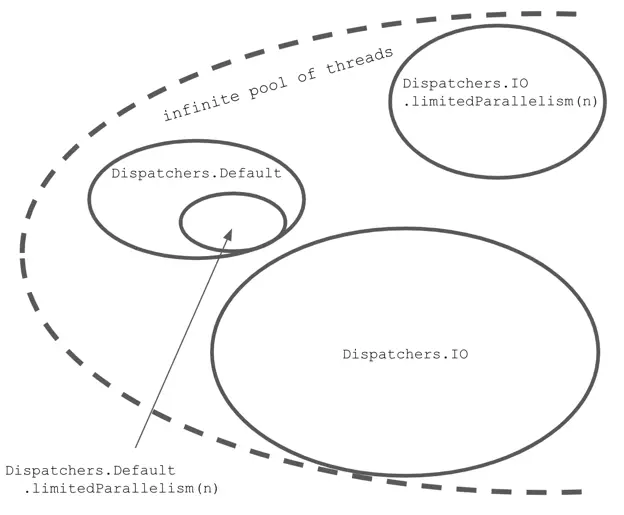
-
-
- ExecutorService를 활용하여 스레드 풀을 생성 후, 코루틴 디스패처로 변환
Executors.newFixedThreadPool(n),Executors.newCachedThreadPool()등으로 만든 스레드 풀을 asCoroutineDispatcher()를 활용해 변환Executors.newFixedThreadPool(3).asCoroutineDispatcher()
코루틴의 중지는 스레드의 Blocking을 의미하지 않는다
아래 코드는 3초 동안 블로킹되는 작업을 실행하는데, 이 시간 동안 현재 코루틴이 실행되고 있는 스레드(= 메인 스레드)는 다른 작업을 수행할 수 없습니다.
fun main() {
println("작업 시작")
// 3초 걸리는 작업 진행
longRunningTask(second = 3)
println("작업 완료")
}
fun longRunningTask(second: Int) {
Thread.sleep(n * 1000) // block
}😏 : 블로킹 되는 동안 기다리면 되지 않나?
🧑💻 : 기다릴 수 있겠니?안드로이드 앱 개발을 예시로 들어보겠습니다. 안드로이드 앱에서는 사용자와 상호작용하는 UI과 관련된 작업을
메인 스레드라는 곳에서 수행합니다. 그렇다면, 그 곳에서 오랜 시간이 걸리는 작업을 수행하면 UI가 멈출 것입니다.네트워크 요청을 보내 데이터를 받아오는 상황을 가정해보겠습니다. 이 작업을 메인 스레드에서 그대로 실행하면, 네트워크 응답이 올 때까지 메인 스레드에서는 어떠한 작업도 수행할 수 없습니다. 그 시간 동안, 사용자는 앱이 멈춘 것처럼 느낄 것입니다. 이것이 오래 지속되면, 안드로이드 측에서 ANR(Application Not Responding) 경고를 띄우고 앱을 강제 종료할 수도 있습니다.
따라서 블로킹 방식은 사용자 경험에 악영향을 미칠 수 있습니다.
반면 코루틴은 다른 작업을 할 수 있도록 양보(yield)하는 특성을 가지고 있습니다. 따라서 특정 코루틴이 잠시 멈추더라도 해당 스레드에서는 다른 코루틴이 실행될 수 있습니다. 즉, 코루틴은 스레드를 차단(blocking)하는 것이 아니라, 해당 코루틴 자체의 실행을 중단(suspend)하는 것일 뿐입니다.
이 특성을 보여주는 코드를 살펴보겠습니다. 단일 스레드(SpecialThread) 환경에서 두 개의 코루틴을 실행시킬 때, 한 코루틴이 중단 상태가 되면 같은 스레드에서 다른 코루틴이 실행될 수 있음을 보여줍니다.
// 단일 스레드로만 이뤄진 디스패처 생성
val myDispatcher = newSingleThreadContext("SpecialThread")
fun main() {
val startTime = System.currentTimeMillis()
runBlocking {
launch(myDispatcher) {
println("IO 작업 시작 - ${Thread.currentThread().name}")
delay(2000) // suspend
println("IO 작업 완료 - ${Thread.currentThread().name}")
}
launch(myDispatcher) {
println("CPU 작업 시작 - ${Thread.currentThread().name}")
delay(1000) // suspend
println("CPU 작업 완료 - ${Thread.currentThread().name}")
}
}
val endTime = System.currentTimeMillis()
println("소요 시간 : ${endTime - startTime}")
} IO 작업 시작 - SpecialThread @coroutine#2
CPU 작업 시작 - SpecialThread @coroutine#3
CPU 작업 완료 - SpecialThread @coroutine#3
IO 작업 완료 - SpecialThread @coroutine#2
소요 시간 : 2096
프로그램을 실행하면 종료까지 약 2초가 소요되며, 모든 코루틴이 같은 스레드(SpecialThread) 에서 실행됩니다. 즉 한 코루틴의 중단이 SpecialThread의 블로킹으로 이어지지 않았습니다. 이러한 방식으로 코루틴은 같은 스레드 내에서도 동시성을 달성할 수 있는 것입니다.
참고) 코루틴은 원칙적으로 스레드를 차단하지 않지만, 예외적으로
runBlocking과runTest(테스트 전용)를 활용해 코루틴을 생성하면, 코루틴 중단 시(suspend) 실행되고 있는 스레드를 블로킹합니다. 일반적인 애플리케이션 코드에서는 이 빌더들의 활용을 지양하고, 스레드를 차단하지 않는 방식으로 코루틴을 사용하는 것이 좋습니다.
그냥 스레드로 동시성 구현하면 안되나?
멀티스레딩도 동시성을 달성하는 대표적인 방법입니다. 그런데 프로세스보다는 효율적인 방법일지라도, 스레드 활용 역시 리소스의 비효율적 사용, 오버헤드의 문제가 있습니다. 따라서, 스레드를 활용하는 방식만으로는 최적의 동시성 구현을 기대하기 어렵습니다.
스레드 생성에 많은 자원이 소요된다
스레드는 프로세스보다 가벼운 실행 단위이지만, 하나의 스레드를 생성할 때도 상당한 메모리와 CPU 자원이 소요됩니다. 일반적으로 스레드 하나당 수백 KB에서 수 MB의 스택 메모리가 필요하며, 실행 중인 스레드가 많아질수록 운영체제가 이를 관리하는 비용도 증가합니다.
예를 들어, 다음 코드는 100만 개의 스레드를 생성하는 코드입니다.
fun main() {
repeat(1_000_000) {
thread {
Thread.sleep(5000)
print(".")
}
}
}OutOfMemoryError: unable to create new native thread
이 코드를 실행하면, 일정 개수를 초과한 시점에서 위와 같은 예외가 발생하며 프로그램이 비정상 종료됩니다. 이는 운영체제가 관리할 수 있는 스레드 개수에 한계가 있기 때문입니다.
반면 코루틴은 실제로 새로운 스레드를 생성하지 않고, 기존의 스레드 위에서 생성되고 실행됩니다. 각 코루틴은 독립적인 스택 메모리를 할당받지 않고, 최소한의 컨텍스트 정보만 유지하므로 스레드보다 훨씬 적은 메모리 자원을 사용합니다. 따라서 코루틴을 100만 개, 혹은 그 이상 만들더라도 프로그램이 정상적으로 동작할 수 있습니다.
fun main() = runBlocking {
repeat(1_000_000) {
launch {
delay(5000)
print(".")
}
}
}스레드는 문맥 교환 과정에서 오버헤드가 발생한다
스레드는 운영체제 차원에서 관리되지만, 코루틴은 그렇지 않다!
스레드는 운영체제가 직접 관리하며, 여러 스레드를 동시에 실행하는 것처럼 보이게 하기 위해 컨텍스트 스위칭(Context Switching)을 수행합니다.
이 때, 운영체제에서 스레드의 상태를 저장하고 복원하기 위해 CPU 레지스터 저장/복원, 캐시 무효화(Cache Invalidation) 등의 연산을 진행합니다. 당연히 스레드의 수가 많아질수록 이러한 작업이 빈번해지고, 오버헤드는 커질 것입니다.
반면, 코루틴은 운영체제에서 직접 관리되지 않고 협력적으로 실행되기 때문에 컨텍스트 스위칭이 발생하지 않습니다. 따라서 스레드보다 더욱 효율적으로 실행할 수 있습니다.
앞서 살펴본 프로세스와 스레드의 비교와 마찬가지로, 스레드를 여러 개 생성했을 때의 실행 시간과 코루틴을 여러 개 생성했을 때의 실행 시간을 비교해 보겠습니다.
스레드 100개 생성 시
fun main() {
val startTime = System.currentTimeMillis()
val threads = List(100) {
thread {
heavyTask() // 동일한 연산 수행
}
}
threads.forEach { it.join() } // 모든 스레드가 끝날 때까지 대기
val endTime = System.currentTimeMillis()
println("✅ 스레드 방식 실행 완료")
println("⏱ 실행 시간: ${endTime - startTime} ms")
}
fun heavyTask() {
val sum = (1..1_000_000).sum()
}코루틴 100개 생성 시
fun main() = runBlocking {
val startTime = System.currentTimeMillis()
val jobs = List(100) {
launch {
heavyTask()
}
}
jobs.forEach { it.join() } // 모든 코루틴 종료 대기
val endTime = System.currentTimeMillis()
println("✅ 코루틴 방식 실행 완료")
println("⏱ 실행 시간: ${endTime - startTime} ms")
}
fun heavyTask() {
val sum = (1..1_000_000).sum()
}두 프로세스를 실행해본 결과, 다음과 같이 코루틴을 사용했을 때 더 적은 시간이 소요되었습니다. (실행 환경에 따라 소요 시간은 다를 수 있습니다.)
✅ 스레드 방식 실행 완료
⏱ 실행 시간: 536 ms
✅ 코루틴 방식 실행 완료
⏱ 실행 시간: 136 ms
결론적으로 코루틴을 활용하면 스레드보다 적은 메모리를 사용하며, 컨텍스트 스위칭 오버헤드 없이 동시성을 구현할 수 있습니다. 따라서 동시성을 구현할 경우(특히 대량의 동시 작업이 필요한 경우), 스레드보다 코루틴을 사용하는 것이 훨씬 유리합니다.
🤯 프로세스 → 스레드 → 코루틴 → ???
이러다가 코루틴 안에서 동작하는 더 작은 단위가 나오는 것 아닌가 모르겠습니다.
😎 생각해보기
코루틴은 스레드와 엄연히 다름에도, 누군가는 '경량 스레드'라고도 부르는 이유가 무엇일까?
다음 편에 계속
다음 편에서는 코루틴에서 동시성을 가능하도록 하는 또 다른 원리를 살펴보겠습니다.
참고 자료
https://youtu.be/M9HHWFp84f0?feature=shared
https://pages.cs.wisc.edu/~bart/537/lecturenotes/processes-threads.html
https://dev.to/vivekyadav200988/multithreading-vs-multiprocessing-11o9
https://youtu.be/B4Of4UgLfWc?feature=shared
